
最新的勘误已经发表,请先对照最新的勘误,如有疑问,随时联络,谢谢。
勘误链接: 《
TCP拥塞控制图解(不包括RTO,因为它太简单了) 【勘误1】》
五一假期放假,我感到莫名地轻松,因为这是一个三天无比快乐的工作时间,今天一天在家,修正了上周末的图表,终于完成了初稿。千万不要吵醒熟睡中的老婆,一旦吵醒了就什么都完了,那就必须通宵了,可是明天还要去西冲,到头来垂头丧气,还是完蛋!不管怎么说,今天总的东西希望对别的人有用(如果你觉得对你没有用的话)
1.网上有很多讲TCP拥塞控制的文章,但是几乎没有一篇能够讲清楚的,关于很多细节充其量只是描述一下代码,想必作者也没有真懂。唯一觉得比较好的两位博主:
a).CSDN的
http://blog.csdn.net/zhangskd
b).chinaunix的
http://blog.chinaunix.net/uid/28387257
其它的基本没什么可以看的了,代码解释谁都会,if解释成如果这些就是网络的垃圾,幸运的是,如今我也加入了他们,希望能成为NO.3,为大家抛砖引玉,只有大家站在同一个层面,才会有公平的PK。
2.在分析TCP拥塞控制的时候,不要动不动就摆出“拥塞状态机”,事实上这是Linux的独家奉献,如果看BSD或者其它的实现,很多根本就没有拥塞状态机的概念,只要完全按照RFC的要求或者建议去实现【有时候,也不必完全按照RFC】,你的TCP一样可以完美。
3.对于实现而言,Linux的TCP协议栈是一个很烂的实现,然而这是有理由的,Linux相比BSD或者lwIP的实现,消除了几乎所有的代码冗余,它希望在一套代码中,在一个很短的函数中,完成所有的一切,这就难免了各种if,&,||等
先上图为好。



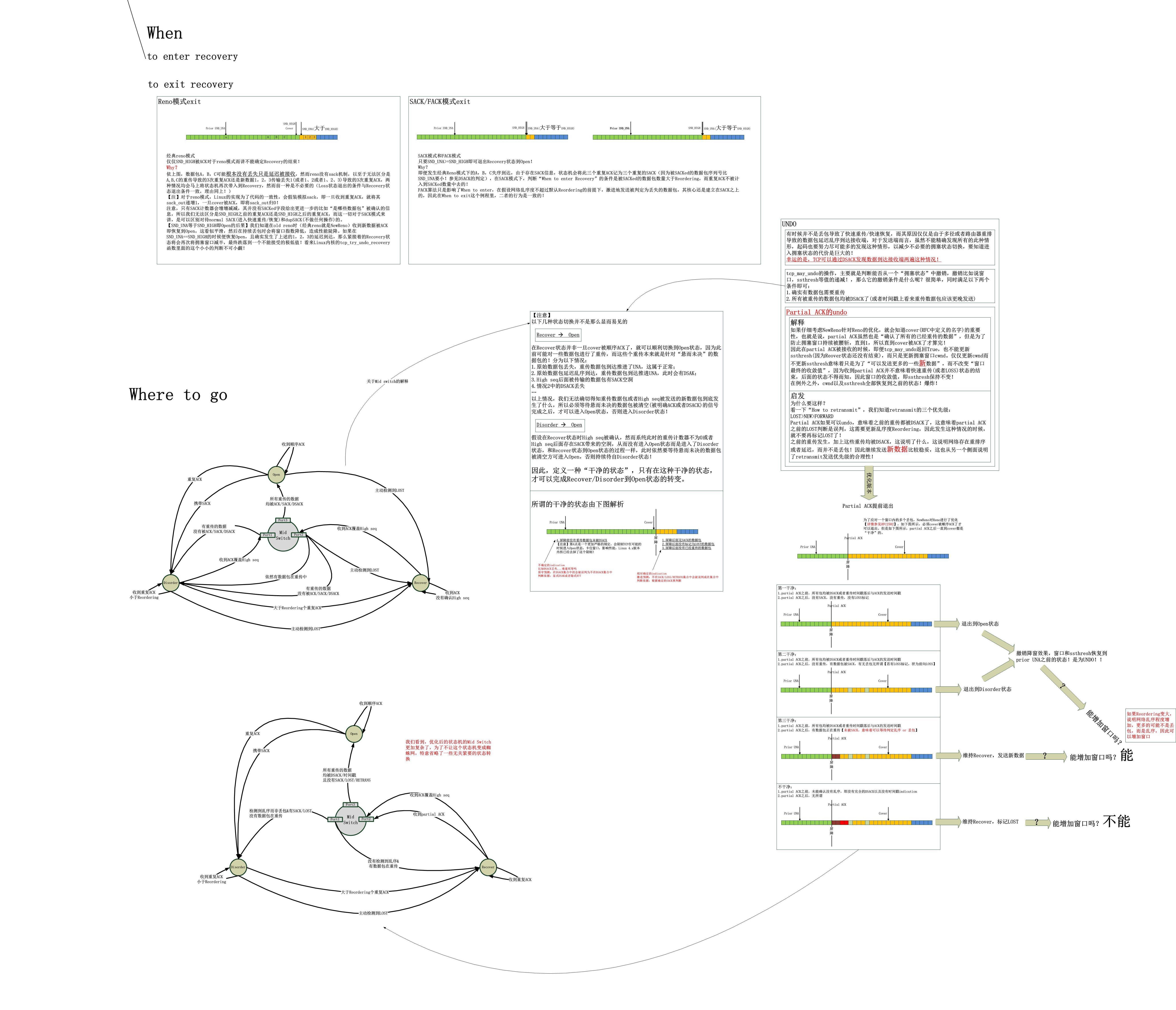

需要说明的是,这幅图的制作占用了我宝贵的时间,我白天没时间搞,因为会有无穷多的进度与会议,只能趁着夜晚老婆孩子睡了之后折腾,万一她们醒了,我就会一夜万劫不复,十分艰难,因此,只希望一点,如果有发现错误,及时告知我。另外,我想告知的是,随时随地,因为在我这里,没有时间的概念。
可是,如果你用2.6.32的内核的话,就是以上这些了,然而如果你升级到4.4,你会看到不一样的结果!
tcp_may_raise_cwnd在tcp_fastretrans_alert之后,因为在alert中可以更新reordering
在处理的时候可以在partial ACK之后的una后面没有retrans,且确认数据包的ACK不是由于重传(是由于原始数据包)导致的时候(时间戳或者DSACK判断),可以进入Disorder状态,
且,如果partial ACK的后面连sack也没有,那么可以直接进入Open。这些都在图中画出了,详见Where to go。
4.刚才还没有完,我想来一点代码分析,基于Linux 2.6.32以及Linux 4.3
以下代码来自2.6.32
static int tcp_try_undo_partial(struct sock *sk, int acked)
{
struct tcp_sock *tp = tcp_sk(sk);
/* Partial ACK arrived. Force Hoe's retransmit. */
int failed = tcp_is_reno(tp) || (tcp_fackets_out(tp) > tp->reordering);
// 确认ACK是由最初的传输产生的还是由重传产生的
if (tcp_may_undo(tp)) {
/* Plain luck! Hole if filled with delayed
* packet, rather than with a retransmit.
*/
if (tp->retrans_out == 0)
tp->retrans_stamp = 0;
// 如果可能的话,更新乱序度,可悲的是,Linux2.6.32没有对其做出积极的反应,
// 而仅仅是一些消极的反应:只有重复(或者sack)大于reordering才会标记LOST!!!
tcp_update_reordering(sk, tcp_fackets_out(tp) + acked, 1);
DBGUNDO(sk, "Hoe");
tcp_undo_cwr(sk, 0);//仅仅意味着可以多发一些数据,并不改变在快速恢复过程中由ssthresh指示的窗口收敛值
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_TCPPARTIALUNDO);
/* So... Do not make Hoe's retransmit yet.
* If the first packet was delayed, the rest
* ones are most probably delayed as well.
*/
// 这个启发在于,如果真的发生了undo,意味着网络中很可能真的发生了延迟或者乱序,而不是真正的丢包,因此不标记LOST,而是继续发送新数据或者前向重传
failed = 0;
}
return failed;
}
static void tcp_fastretrans_alert(struct sock *sk, int pkts_acked, int flag)
{
struct inet_connection_sock *icsk = inet_csk(sk);
struct tcp_sock *tp = tcp_sk(sk);
// (FLAG_DATA-接收端主动数据传输|FLAG_WIN_UPDATE-主动窗口更新|FLAG_ACKED-数据被ACK)
// 对于主动发送的携带ACK的数据包,即便ACK重复了,也不算是重复ACK
int is_dupack = !(flag & (FLAG_SND_UNA_ADVANCED | FLAG_NOT_DUP));
int do_lost = is_dupack || ((flag & FLAG_DATA_SACKED) &&
(tcp_fackets_out(tp) > tp->reordering));
int fast_rexmit = 0, mib_idx;
...
/* B. In all the states check for reneging SACKs. */
// 详见图中的SACK reneging主动检测
if (tcp_check_sack_reneging(sk, flag))
return;
/* C. Process data loss notification, provided it is valid. */
// 详见图中的LOST主动检测
if (tcp_is_fack(tp) && (flag & FLAG_DATA_LOST) &&
before(tp->snd_una, tp->high_seq) &&
icsk->icsk_ca_state != TCP_CA_Open &&
tp->fackets_out > tp->reordering) {
tcp_mark_head_lost(sk, tp->fackets_out - tp->reordering);
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_TCPLOSS);
}
...
if (icsk->icsk_ca_state == TCP_CA_Open) {
WARN_ON(tp->retrans_out != 0);
tp->retrans_stamp = 0;
// 判断当前的ACK是否覆盖了cover
} else if (!before(tp->snd_una, tp->high_seq)) {
...
case TCP_CA_Disorder:
// 如果可以可以undo dasck,代表了之前的重传都是误判。
tcp_try_undo_dsack(sk);
if (!tp->undo_marker ||
/* For SACK case do not Open to allow to undo
* catching for all duplicate ACKs. 没有必要如此严格 */
// reno无法识别DSACK,因此就不必去检查它了
tcp_is_reno(tp) || tp->snd_una != tp->high_seq) {
tp->undo_marker = 0;
tcp_set_ca_state(sk, TCP_CA_Open);
}
break;
case TCP_CA_Recovery:
if (tcp_is_reno(tp))
tcp_reset_reno_sack(tp);
// 如果是reno模式,那么为了防止不必要(此处应该用"地" )地再次进入"快速重传"状态
// 必须要ACK超越cover!详见When to exit recovery
if (tcp_try_undo_recovery(sk))
return;
tcp_complete_cwr(sk);
break;
}
}
/* F. Process state. */
switch (icsk->icsk_ca_state) {
case TCP_CA_Recovery:
if (!(flag & FLAG_SND_UNA_ADVANCED)) {
// 这是在模拟reno的sack呢
if (tcp_is_reno(tp) && is_dupack)
tcp_add_reno_sack(sk);
} else
// 高版本的内核对此处理完全不一样,请参见图中Where to go
do_lost = tcp_try_undo_partial(sk, pkts_acked);
break;
case TCP_CA_Loss:
...
default:
if (tcp_is_reno(tp)) {
if (flag & FLAG_SND_UNA_ADVANCED)
tcp_reset_reno_sack(tp);
if (is_dupack)
tcp_add_reno_sack(sk);
}
if (icsk->icsk_ca_state == TCP_CA_Disorder)
tcp_try_undo_dsack(sk);
if (!tcp_time_to_recover(sk)) {
// 仅仅在Open,CWR,Disorder状态下才会被调用
tcp_try_to_open(sk, flag);
return;
}
/* MTU probe failure: don't reduce cwnd */
if (icsk->icsk_ca_state < TCP_CA_CWR &&
icsk->icsk_mtup.probe_size &&
tp->snd_una == tp->mtu_probe.probe_seq_start) {
tcp_mtup_probe_failed(sk);
/* Restores the reduction we did in tcp_mtup_probe() */
tp->snd_cwnd++;
tcp_simple_retransmit(sk);
return;
}
/* Otherwise enter Recovery state */
if (tcp_is_reno(tp))
mib_idx = LINUX_MIB_TCPRENORECOVERY;
else
mib_idx = LINUX_MIB_TCPSACKRECOVERY;
NET_INC_STATS_BH(sock_net(sk), mib_idx);
tp->high_seq = tp->snd_nxt;
tp->prior_ssthresh = 0;
tp->undo_marker = tp->snd_una;
tp->undo_retrans = tp->retrans_out;
if (icsk->icsk_ca_state < TCP_CA_CWR) {
if (!(flag & FLAG_ECE))
tp->prior_ssthresh = tcp_current_ssthresh(sk);
tp->snd_ssthresh = icsk->icsk_ca_ops->ssthresh(sk);
TCP_ECN_queue_cwr(tp);
}
tp->bytes_acked = 0;
tp->snd_cwnd_cnt = 0;
tcp_set_ca_state(sk, TCP_CA_Recovery);
fast_rexmit = 1;
}
if (do_lost || (tcp_is_fack(tp) && tcp_head_timedout(sk)))
tcp_update_scoreboard(sk, fast_rexmit);
// 请注意,这是个可以修改的逻辑,在Linux 3.x中,其已经成了prr,然而2.6.32,并不。
tcp_cwnd_down(sk, flag);
// 按照优先级来传输,参见图中How(to retransmit)
tcp_xmit_retransmit_queue(sk);
}
我们看tcp_ack的逻辑:
if (tcp_ack_is_dubious(sk, flag)) {
/* Advance CWND, if state allows this. */
if ((flag & FLAG_DATA_ACKED) && !frto_cwnd &&
tcp_may_raise_cwnd(sk, flag))
tcp_cong_avoid(sk, ack, prior_in_flight);
tcp_fastretrans_alert(sk, prior_packets - tp->packets_out,
flag);
} else {
if ((flag & FLAG_DATA_ACKED) && !frto_cwnd)
tcp_cong_avoid(sk, ack, prior_in_flight);
}然后,我们看一下4.3的逻辑:
static bool tcp_try_undo_partial(struct sock *sk, const int acked,
const int prior_unsacked, int flag)
{
struct tcp_sock *tp = tcp_sk(sk);
if (tp->undo_marker && tcp_packet_delayed(tp)) {
/* Plain luck! Hole if filled with delayed
* packet, rather than with a retransmit.
*/
tcp_update_reordering(sk, tcp_fackets_out(tp) + acked, 1);
/* We are getting evidence that the reordering degree is higher
* than we realized. If there are no retransmits out then we
* can undo. Otherwise we clock out new packets but do not
* mark more packets lost or retransmit more.
*/
// 仅仅在第一次的时候,undo make明确为UNA的位置,然而收到第一个patial ACK的时候
// 会判断是否有数据包在重传中,如果有,就不忙着再标记LOST段了,而是什么都不做,将
// 窗口留给新数据
if (tp->retrans_out) {
tcp_cwnd_reduction(sk, prior_unsacked, 0, flag);
return true;
}
if (!tcp_any_retrans_done(sk))
tp->retrans_stamp = 0;
DBGUNDO(sk, "partial recovery");
// 从此以后,undo make为0,就完全按照sack和reordering的差值来标记LOST了
tcp_undo_cwnd_reduction(sk, true);
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_TCPPARTIALUNDO);
tcp_try_keep_open(sk);
return true;
}
return false;
}
在tcp_ack中:
if (tcp_ack_is_dubious(sk, flag)) {
// 这里不再针对dubious情形的ack也进行tcp_may_raise_cwnd的判断,
// 从而在允许的情况下依然增加拥塞窗口。
is_dupack = !(flag & (FLAG_SND_UNA_ADVANCED | FLAG_NOT_DUP));
tcp_fastretrans_alert(sk, acked, prior_unsacked,
is_dupack, flag);
}
if (tp->tlp_high_seq)
tcp_process_tlp_ack(sk, ack, flag);
/* Advance cwnd if state allows */
// 在这里进行tcp_may_raise_cwnd判断,保证在高乱序的情况下依然可以增加拥塞窗口
// 1.alert中可能会进行update reordering
// 2.alert中会在partial ACK之后进入Disorder/Open状态
if (tcp_may_raise_cwnd(sk, flag))
tcp_cong_avoid(sk, ack, acked);而且在tcp_may_raise_cwnd中,会对reordering变大的情况做出补偿,因为此时,基本已经可以判定,并不是丢包,而是乱序导致了SACK!
最后,这并不是本系列文章的终结,我本想总结一下TCP拥塞控制的各种计数器,但是觉得那无非又是一番字词句段篇章,毫无意义,如果读懂了RFC,一切都好办了。
Linux TCP实现实在太烂了,但是我不觉得它比OpenSSL更烂,也不比OpenVPN更烂,不是吗?我吐槽过OpenSSL和OpenVPN,然而最终我放弃了OpenSSL,因为我知道It is beyond my ability!如今我不再吐槽了,因为无力做没有意义的事情了。
在此,我纠正一下措辞,马上着手另外一件事去了,不管怎么说,在一件事没有彻底(起码要60%+吧)搞明白之前,最好不要去搞别的,这会产生夹生饭。然而在我们的传统中,这好像毫无必要!因为我们的四大发明(这个关于四大发明的话题我会另外写一篇文章的,敬请期待)没有一个是知道了起码60%的原理后搞出来,这倒不是要反衬西方的实践都是在理解原理的前提下做出的,比如珍妮纺纱机,比如希腊火之类的,我要说的是,我们这里拥有一种魔法,正如中学时的化学老师所说的那样,我们的先人不知道什么是“酸”,但是却可以造出醋!于是我们都深深的受到了影响,于是就出现了大量的未知酸,先有醋的东西。大量的抄袭,大量的盗版,大量的毫无创意的模仿,但始终没有原创,因为大多数人一直都在追求的是一种所谓的捷径,而不是对知识的持续努力的积累,古人说过一句比较好的话,大意就是背诵了唐诗三百首,文章自然就流露出来了(不会写,也会偷),虽然也是教人模仿,但是起码那需要硬努力,要么你花点时间研究一下平仄的规律,要么你就背诵大量的现成的诗去自己总结规律,难道还有别的路吗??如果一开始上来就动笔,拿出来的可能会是一首诗,然而绝大多数是打油诗。
如果只做服务器而不是转发,针对路由子系统的工作就显得没有意义了...
附:Linux 2.6.32和3.x在undo时的窗口处理
我们比较关注TCP在快速恢复结束后窗口会怎样,它是不是被设置成降窗开始时的ssthresh呢?我们先看2.6.32的代码
case TCP_CA_Recovery:
if (tcp_is_reno(tp))
tcp_reset_reno_sack(tp);
// 如果是reno模式,那么为了防止不必要(此处应该用"地" )地再次进入"快速重传"状态
// 必须要ACK超越cover!详见When to exit recovery
if (tcp_try_undo_recovery(sk))
return;
// 上面的undo中可能存在may undo为真的情况,意味着所有的重传均是误判,因此窗口
// 会恢复到之前的大小,然而一切都被下面的complete函数拉回来了,它无条件取当前
// 窗口和ssthresh的最小值作为新窗口
tcp_complete_cwr(sk);
break;然后再看下3.10的代码:
case TCP_CA_Recovery:
if (tcp_is_reno(tp))
tcp_reset_reno_sack(tp);
if (tcp_try_undo_recovery(sk))
return;
// 我把下列函数中的一个注释提到这里:
// "/* Reset cwnd to ssthresh in CWR or Recovery (unless it's undone) */"
// 这意味着什么?这意味着如果在undo_recovery中undo_marker变成0了,也就是说
// may_undo返回了真,那么就不必将窗口reset到ssthresh了,因为undo操作已经将
// 窗口恢复到之前的值了。
// 这是十分合理的,然而是有条件的,条件就是之前的重传都是误判,均被DSACK了,
// 这个条件并不苛刻,既然是误判,当然可以恢复拥塞之前的值了,然而,我们能否
// 激进一点呢? :-(
tcp_end_cwnd_reduction(sk);
break;其实,围绕这快速恢复结束后窗口应该在哪里这个问题,可以连续扯上一整天,但是我觉得这就好像两个势均力敌的人在扳手腕一样,状态是胶着的。
原文链接: https://blog.csdn.net/dog250/article/details/51287078
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍;
也有高质量的技术群,里面有嵌入式、搜广推等BAT大佬

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/408170
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!