
关注公众号【高性能架构探索】,第一时间获取干货;回复【pdf】,免费获取计算机经典书籍。
你好,我是雨乐!
在上篇文章中,我们分析了线上coredump产生的原因,其中用到了coredump分析工具gdb,这几天一直有读者在问,能不能写一篇关于gdb调试方面的文章,今天借助此文,分享一些工作中的调试经验,希望能够帮到大家。
写在前面
在我的工作经历中,前几年在Windows上进行开发,使用Visual Studio进行调试,简直是利器,各种断点等用鼠标点点点就能设置;大概从12年开始转Linux开发了,所以调试都是基于GDB的。本来这篇文章也想写写Windows下调试相关,奈何好多年没用了,再加上工作太忙,所以本文就只写了Linux下GDB调试相关,对于Windows开发人员,实在对不住了😃。
这篇文章,涉及的比较全面,总结了这些年的gdb调试经验(都是小儿科😁),经常用到的一些调试技巧,希望能够对从事Linux开发的相关人员有所帮助

背景
作为C/C++开发人员,保证程序正常运行是最基本也是最主要的目的。而为了保证程序正常运行,调试则是最基本的手段,熟悉这些调试方式,可以方便我们更快的定位程序问题所在,提高开发效率。
在开发过程,如果程序的运行结果不符合预期,第一时间就是打开GDB进行调试,在对应的地方设置断点,然后分析原因;当线上服务出了问题,第一时间查看进程在不在,如果不在的话,是否生成了coredump文件,如果有,则使用gdb调试coredump文件,否则通过dmesg来分析内核日志来查找原因。
概念
GDB是一个由GNU开源组织发布的、UNIX/LINUX操作系统下的、基于命令行的、功能强大的程序调试工具。
GDB支持断点、单步执行、打印变量、观察变量、查看寄存器、查看堆栈等调试手段。在Linux环境软件开发中,GDB是主要的调试工具,用来调试C和 C++程序(也支持go等其他语言)。
常用命令
断点
断点是我们在调试中经常用的一个功能,我们在指定位置设置断点之后,程序运行到该位置将会暂停,这个时候我们就可以对程序进行更多的操作,比如查看变量内容,堆栈情况等等,以帮助我们调试程序。
以设置断点的命令分为以下几类:
- breakpoint
- watchpoint
- catchpoint
breakpoint
可以根据行号、函数、条件生成断点,下面是相关命令以及对应的作用说明:
| 命令 | 作用 |
|---|---|
| break [file]:function | 在文件file的function函数入口设置断点 |
| break [file]:line | 在文件file的第line行设置断点 |
| info breakpoints | 查看断点列表 |
| break [+-]offset | 在当前位置偏移量为[+-]offset处设置断点 |
| break *addr | 在地址addr处设置断点 |
| break ... if expr | 设置条件断点,仅仅在条件满足时 |
| ignore n count | 接下来对于编号为n的断点忽略count次 |
| clear | 删除所有断点 |
| clear function | 删除所有位于function内的断点 |
| delete n | 删除指定编号的断点 |
| enable n | 启用指定编号的断点 |
| disable n | 禁用指定编号的断点 |
| save breakpoints file | 保存断点信息到指定文件 |
| source file | 导入文件中保存的断点信息 |
| break | 在下一个指令处设置断点 |
| clear [file:]line | 删除第line行的断点 |
watchpoint
watchpoint是一种特殊类型的断点,类似于正常断点,是要求GDB暂停程序执行的命令。区别在于watchpoint没有驻留某一行源代码中,而是指示GDB每当某个表达式改变了值就暂停执行的命令。
watchpoint分为硬件实现和软件实现两种。前者需要硬件系统的支持;后者的原理就是每步执行后都检查变量的值是否改变。GDB在新建数据断点时会优先尝试硬件方式,如果失败再尝试软件实现。
| 命令 | 作用 |
|---|---|
| watch variable | 设置变量数据断点 |
| watch var1 + var2 | 设置表达式数据断点 |
| rwatch variable | 设置读断点,仅支持硬件实现 |
| awatch variable | 设置读写断点,仅支持硬件实现 |
| info watchpoints | 查看数据断点列表 |
| set can-use-hw-watchpoints 0 | 强制基于软件方式实现 |
使用数据断点时,需要注意:
- 当监控变量为局部变量时,一旦局部变量失效,数据断点也会失效
- 如果监控的是指针变量
p,则watch *p监控的是p所指内存数据的变化情况,而watch p监控的是p指针本身有没有改变指向
最常见的数据断点应用场景:定位堆上的结构体内部成员何时被修改。由于指针一般为局部变量,为了解决断点失效,一般有两种方法。
| 命令 | 作用 |
|---|---|
| print &variable | 查看变量的内存地址 |
| watch (type )address | 通过内存地址间接设置断点 |
| watch -l variable | 指定location参数 |
| watch variable thread 1 | 仅编号为1的线程修改变量var值时会中断 |
catchpoint
从字面意思理解,是捕获断点,其主要监测信号的产生。例如c++的throw,或者加载库的时候,产生断点行为。
| 命令 | 含义 |
|---|---|
| catch fork | 程序调用fork时中断 |
| tcatch fork | 设置的断点只触发一次,之后被自动删除 |
| catch syscall ptrace | 为ptrace系统调用设置断点 |
在
command命令后加断点编号,可以定义断点触发后想要执行的操作。在一些高级的自动化调试场景中可能会用到。
命令行
| 命令 | 作用 |
|---|---|
| run arglist | 以arglist为参数列表运行程序 |
| set args arglist | 指定启动命令行参数 |
| set args | 指定空的参数列表 |
| show args | 打印命令行列表 |
程序栈
| 命令 | 作用 |
|---|---|
| backtrace [n] | 打印栈帧 |
| frame [n] | 选择第n个栈帧,如果不存在,则打印当前栈帧 |
| up n | 选择当前栈帧编号+n的栈帧 |
| down n | 选择当前栈帧编号-n的栈帧 |
| info frame [addr] | 描述当前选择的栈帧 |
| info args | 当前栈帧的参数列表 |
| info locals | 当前栈帧的局部变量 |
多进程、多线程
多进程
GDB在调试多进程程序(程序含fork调用)时,默认只追踪父进程。可以通过命令设置,实现只追踪父进程或子进程,或者同时调试父进程和子进程。
| 命令 | 作用 |
|---|---|
| info inferiors | 查看进程列表 |
| attach pid | 绑定进程id |
| inferior num | 切换到指定进程上进行调试 |
| print $_exitcode | 显示程序退出时的返回值 |
| set follow-fork-mode child | 追踪子进程 |
| set follow-fork-mode parent | 追踪父进程 |
| set detach-on-fork on | fork调用时只追踪其中一个进程 |
| set detach-on-fork off | fork调用时会同时追踪父子进程 |
在调试多进程程序时候,默认情况下,除了当前调试的进程,其他进程都处于挂起状态,所以,如果需要在调试当前进程的时候,其他进程也能正常执行,那么通过设置set schedule-multiple on即可。
多线程
多线程开发在日常开发工作中很常见,所以多线程的调试技巧非常有必要掌握。
默认调试多线程时,一旦程序中断,所有线程都将暂停。如果此时再继续执行当前线程,其他线程也会同时执行。
| 命令 | 作用 |
|---|---|
| info threads | 查看线程列表 |
| print $_thread | 显示当前正在调试的线程编号 |
| set scheduler-locking on | 调试一个线程时,其他线程暂停执行 |
| set scheduler-locking off | 调试一个线程时,其他线程同步执行 |
| set scheduler-locking step | 仅用step调试线程时其他线程不执行,用其他命令如next调试时仍执行 |
如果只关心当前线程,建议临时设置 scheduler-locking 为 on,避免其他线程同时运行,导致命中其他断点分散注意力。
打印输出
通常情况下,在调试的过程中,我们需要查看某个变量的值,以分析其是否符合预期,这个时候就需要打印输出变量值。
| 命令 | 作用 |
|---|---|
| whatis variable | 查看变量的类型 |
| ptype variable | 查看变量详细的类型信息 |
| info variables var | 查看定义该变量的文件,不支持局部变量 |
打印字符串
使用x/s命令打印ASCII字符串,如果是宽字符字符串,需要先看宽字符的长度 print sizeof(str)。
如果长度为2,则使用x/hs打印;如果长度为4,则使用x/ws打印。
| 命令 | 作用 |
|---|---|
| x/s str | 打印字符串 |
| set print elements 0 | 打印不限制字符串长度/或不限制数组长度 |
| call printf("%s\n",xxx) | 这时打印出的字符串不会含有多余的转义符 |
| printf "%s\n",xxx | 同上 |
打印数组
| 命令 | 作用 |
|---|---|
| print *array@10 | 打印从数组开头连续10个元素的值 |
| print array[60]@10 | 打印array数组下标从60开始的10个元素,即第60~69个元素 |
| set print array-indexes on | 打印数组元素时,同时打印数组的下标 |
打印指针
| 命令 | 作用 |
|---|---|
| print ptr | 查看该指针指向的类型及指针地址 |
| print (struct xxx )ptr | 查看指向的结构体的内容 |
打印指定内存地址的值
使用x命令来打印内存的值,格式为x/nfu addr,以f格式打印从addr开始的n个长度单元为u的内存值。
n:输出单元的个数f:输出格式,如x表示以16进制输出,o表示以8进制输出,默认为xu:一个单元的长度,b表示1个byte,h表示2个byte(half word),w表示4个byte,g表示8个byte(giant word)
| 命令 | 作用 |
|---|---|
| x/8xb array | 以16进制打印数组array的前8个byte的值 |
| x/8xw array | 以16进制打印数组array的前16个word的值 |
打印局部变量
| 命令 | 作用 |
|---|---|
| info locals | 打印当前函数局部变量的值 |
| backtrace full | 打印当前栈帧各个函数的局部变量值,命令可缩写为bt |
| bt full n | 从内到外显示n个栈帧及其局部变量 |
| bt full -n | 从外向内显示n个栈帧及其局部变量 |
打印结构体
| 命令 | 作用 |
|---|---|
| set print pretty on | 每行只显示结构体的一名成员 |
| set print null-stop | 不显示'\000' |
函数跳转
| 命令 | 作用 |
|---|---|
| set step-mode on | 不跳过不含调试信息的函数,可以显示和调试汇编代码 |
| finish | 执行完当前函数并打印返回值,然后触发中断 |
| return 0 | 不再执行后面的指令,直接返回,可以指定返回值 |
| call printf("%s\n", str) | 调用printf函数,打印字符串(可以使用call或者print调用函数) |
| print func() | 调用func函数(可以使用call或者print调用函数) |
| set var variable=xxx | 设置变量variable的值为xxx |
| set {type}address = xxx | 给存储地址为address,类型为type的变量赋值 |
| info frame | 显示函数堆栈的信息(堆栈帧地址、指令寄存器的值等) |
其它
图形化
tui为terminal user interface的缩写,在启动时候指定-tui参数,或者调试时使用ctrl+x+a组合键,可进入或退出图形化界面。
| 命令 | 含义 |
|---|---|
| layout src | 显示源码窗口 |
| layout asm | 显示汇编窗口 |
| layout split | 显示源码 + 汇编窗口 |
| layout regs | 显示寄存器 + 源码或汇编窗口 |
| winheight src +5 | 源码窗口高度增加5行 |
| winheight asm -5 | 汇编窗口高度减小5行 |
| winheight cmd +5 | 控制台窗口高度增加5行 |
| winheight regs -5 | 寄存器窗口高度减小5行 |
汇编
| 命令 | 含义 |
|---|---|
| disassemble function | 查看函数的汇编代码 |
| disassemble /mr function | 同时比较函数源代码和汇编代码 |
调试和保存core文件
| 命令 | 含义 |
|---|---|
| file exec_file # | 加载可执行文件的符号表信息 |
| core core_file | 加载core-dump文件 |
| gcore core_file | 生成core-dump文件,记录当前进程的状态 |
启动方式
使用gdb调试,一般有以下几种启动方式:
- gdb filename: 调试可执行程序
- gdb attach pid: 通过”绑定“进程ID来调试正在运行的进程
- gdb filename -c coredump_file: 调试可执行文件
在下面的几节中,将分别对上述几种调试方式进行讲解,从例子的角度出发,使得大家能够更好的掌握调试技巧。
调试
可执行文件
单线程
首先,我们先看一段代码:
#include<stdio.h>
void print(int xx, int *xxptr) {
printf("In print():\n");
printf(" xx is %d and is stored at %p.\n", xx, &xx);
printf(" ptr points to %p which holds %d.\n", xxptr, *xxptr);
}
int main(void) {
int x = 10;
int *ptr = &x;
printf("In main():\n");
printf(" x is %d and is stored at %p.\n", x, &x);
printf(" ptr points to %p which holds %d.\n", ptr, *ptr);
print(x, ptr);
return 0;
}这个代码比较简单,下面我们开始进入调试:
gdb ./test_main
GNU gdb (GDB) Red Hat Enterprise Linux 7.6.1-114.el7
Copyright (C) 2013 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-redhat-linux-gnu".
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>...
Reading symbols from /root/test_main...done.
(gdb) r
Starting program: /root/./test_main
In main():
x is 10 and is stored at 0x7fffffffe424.
ptr points to 0x7fffffffe424 which holds 10.
In print():
xx is 10 and is stored at 0x7fffffffe40c.
xxptr points to 0x7fffffffe424 which holds 10.
[Inferior 1 (process 31518) exited normally]
Missing separate debuginfos, use: debuginfo-install glibc-2.17-260.el7.x86_64在上述命令中,我们通过gdb test命令启动调试,然后通过执行r(run命令的缩写)执行程序,直至退出,换句话说,上述命令是一个完整的使用gdb运行可执行程序的完整过程(只使用了r命令),接下来,我们将以此为例子,介绍几种比较常见的命令。
断点
(gdb) b 15
Breakpoint 1 at 0x400601: file test_main.cc, line 15.
(gdb) info b
Num Type Disp Enb Address What
1 breakpoint keep y 0x0000000000400601 in main() at test_main.cc:15
(gdb) r
Starting program: /root/./test_main
In main():
x is 10 and is stored at 0x7fffffffe424.
ptr points to 0x7fffffffe424 which holds 10.
Breakpoint 1, main () at test_main.cc:15
15 print(xx, xxptr);
Missing separate debuginfos, use: debuginfo-install glibc-2.17-260.el7.x86_64
(gdb)backtrace
(gdb) backtrace
#0 main () at test_main.cc:15
(gdb)backtrace命令是列出当前堆栈中的所有帧。在上面的例子中,栈上只有一帧,编号为0,属于main函数。
(gdb) step
print (xx=10, xxptr=0x7fffffffe424) at test_main.cc:4
4 printf("In print():\n");
(gdb)接着,我们执行了step命令,即进入函数内。下面我们继续通过backtrace命令来查看栈帧信息。
(gdb) backtrace
#0 print (xx=10, xxptr=0x7fffffffe424) at test_main.cc:4
#1 0x0000000000400612 in main () at test_main.cc:15
(gdb)从上面输出结果,我们能够看出,有两个栈帧,第1帧属于main函数,第0帧属于print函数。
每个栈帧都列出了该函数的参数列表。从上面我们可以看出,main函数没有参数,而print函数有参数,并且显示了其参数的值。
有一点我们可能比较迷惑,在第一次执行backtrace的时候,main函数所在的栈帧编号为0,而第二次执行的时候,main函数的栈帧为1,而print函数的栈帧为0,这是因为_与栈的向下增长_规律一致,我们只需要记住编号最小帧号就是最近一次调用的函数。
frame
栈帧用来存储函数的变量值等信息,默认情况下,GDB总是位于当前正在执行函数对应栈帧的上下文中。
在前面的例子中,由于当前正在print()函数中执行,GDB位于第0帧的上下文中。可以通过frame命令来获取当前正在执行的上下文所在的帧。
(gdb) frame
#0 print (xx=10, xxptr=0x7fffffffe424) at test_main.cc:4
4 printf("In print():\n");
(gdb)下面,我们尝试使用print命令打印下当前栈帧的值,如下:
(gdb) print xx
$1 = 10
(gdb) print xxptr
$2 = (int *) 0x7fffffffe424
(gdb)如果我们想看其他栈帧的内容呢?比如main函数中x和ptr的信息呢?假如直接打印这俩值的话,那么就会得到如下:
(gdb) print x
No symbol "x" in current context.
(gdb) print xxptr
No symbol "ptr" in current context.
(gdb)在此,我们可以通过_frame num_来切换栈帧,如下:
(gdb) frame 1
#1 0x0000000000400612 in main () at test_main.cc:15
15 print(x, ptr);
(gdb) print x
$3 = 10
(gdb) print ptr
$4 = (int *) 0x7fffffffe424
(gdb)多线程
为了方便进行演示,我们创建一个简单的例子,代码如下:
#include <chrono>
#include <iostream>
#include <string>
#include <thread>
#include <vector>
int fun_int(int n) {
std::this_thread::sleep_for(std::chrono::seconds(10));
std::cout << "in fun_int n = " << n << std::endl;
return 0;
}
int fun_string(const std::string &s) {
std::this_thread::sleep_for(std::chrono::seconds(10));
std::cout << "in fun_string s = " << s << std::endl;
return 0;
}
int main() {
std::vector<int> v;
v.emplace_back(1);
v.emplace_back(2);
v.emplace_back(3);
std::cout << v.size() << std::endl;
std::thread t1(fun_int, 1);
std::thread t2(fun_string, "test");
std::cout << "after thread create" << std::endl;
t1.join();
t2.join();
return 0;
}上述代码比较简单:
- 函数fun_int的功能是休眠10s,然后打印其参数
- 函数fun_string功能是休眠10s,然后打印其参数
- main函数中,创建两个线程,分别执行上述两个函数
下面是一个完整的调试过程:
(gdb) b 27
Breakpoint 1 at 0x4013d5: file test.cc, line 27.
(gdb) b test.cc:32
Breakpoint 2 at 0x40142d: file test.cc, line 32.
(gdb) info b
Num Type Disp Enb Address What
1 breakpoint keep y 0x00000000004013d5 in main() at test.cc:27
2 breakpoint keep y 0x000000000040142d in main() at test.cc:32
(gdb) r
Starting program: /root/test
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib64/libthread_db.so.1".
Breakpoint 1, main () at test.cc:27
(gdb) c
Continuing.
3
[New Thread 0x7ffff6fd2700 (LWP 44996)]
in fun_int n = 1
[New Thread 0x7ffff67d1700 (LWP 44997)]
Breakpoint 2, main () at test.cc:32
32 std::cout << "after thread create" << std::endl;
(gdb) info threads
Id Target Id Frame
3 Thread 0x7ffff67d1700 (LWP 44997) "test" 0x00007ffff7051fc3 in new_heap () from /lib64/libc.so.6
2 Thread 0x7ffff6fd2700 (LWP 44996) "test" 0x00007ffff7097e2d in nanosleep () from /lib64/libc.so.6
* 1 Thread 0x7ffff7fe7740 (LWP 44987) "test" main () at test.cc:32
(gdb) thread 2
[Switching to thread 2 (Thread 0x7ffff6fd2700 (LWP 44996))]
#0 0x00007ffff7097e2d in nanosleep () from /lib64/libc.so.6
(gdb) bt
#0 0x00007ffff7097e2d in nanosleep () from /lib64/libc.so.6
#1 0x00007ffff7097cc4 in sleep () from /lib64/libc.so.6
#2 0x00007ffff796ceb9 in std::this_thread::__sleep_for(std::chrono::duration<long, std::ratio<1l, 1l> >, std::chrono::duration<long, std::ratio<1l, 1000000000l> >) () from /lib64/libstdc++.so.6
#3 0x00000000004018cc in std::this_thread::sleep_for<long, std::ratio<1l, 1l> > (__rtime=...) at /usr/include/c++/4.8.2/thread:281
#4 0x0000000000401307 in fun_int (n=1) at test.cc:9
#5 0x0000000000404696 in std::_Bind_simple<int (*(int))(int)>::_M_invoke<0ul>(std::_Index_tuple<0ul>) (this=0x609080)
at /usr/include/c++/4.8.2/functional:1732
#6 0x000000000040443d in std::_Bind_simple<int (*(int))(int)>::operator()() (this=0x609080) at /usr/include/c++/4.8.2/functional:1720
#7 0x000000000040436e in std::thread::_Impl<std::_Bind_simple<int (*(int))(int)> >::_M_run() (this=0x609068) at /usr/include/c++/4.8.2/thread:115
#8 0x00007ffff796d070 in ?? () from /lib64/libstdc++.so.6
#9 0x00007ffff7bc6dd5 in start_thread () from /lib64/libpthread.so.0
#10 0x00007ffff70d0ead in clone () from /lib64/libc.so.6
(gdb) c
Continuing.
after thread create
in fun_int n = 1
[Thread 0x7ffff6fd2700 (LWP 45234) exited]
in fun_string s = test
[Thread 0x7ffff67d1700 (LWP 45235) exited]
[Inferior 1 (process 45230) exited normally]
(gdb) q在上述调试过程中:
-
b 27 在第27行加上断点
-
b test.cc:32 在第32行加上断点(效果与b 32一致)
-
info b 输出所有的断点信息
-
r 程序开始运行,并在第一个断点处暂停
-
c 执行c命令,在第二个断点处暂停,在第一个断点和第二个断点之间,创建了两个线程t1和t2
-
info threads 输出所有的线程信息,从输出上可以看出,总共有3个线程,分别为main线程、t1和t2
-
thread 2 切换至线程2
-
bt 输出线程2的堆栈信息
-
c 直至程序结束
-
q 退出gdb
多进程
同上面一样,我们仍然以一个例子进行模拟多进程调试,代码如下:
#include <stdio.h>
#include <unistd.h>
int main()
{
pid_t pid = fork();
if (pid == -1) {
perror("fork error\n");
return -1;
}
if(pid == 0) { // 子进程
int num = 1;
while(num == 1){
sleep(10);
}
printf("this is child,pid = %d\n", getpid());
} else { // 父进程
printf("this is parent,pid = %d\n", getpid());
wait(NULL); // 等待子进程退出
}
return 0;
}在上面代码中,包含两个进程,一个是父进程(也就是main进程),另外一个是由fork()函数创建的子进程。
在默认情况下,在多进程程序中,GDB只调试main进程,也就是说无论程序调用了多少次fork()函数创建了多少个子进程,GDB在默认情况下,只调试父进程。为了支持多进程调试,从GDB版本7.0开始支持单独调试(调试父进程或者子进程)和同时调试多个进程。
那么,我们该如何调试子进程呢?我们可以使用如下几种方式进行子进程调试。
attach
首先,无论是父进程还是子进程,都可以通过attach命令启动gdb进行调试。我们都知道,对于每个正在运行的程序,操作系统都会为其分配一个唯一ID号,也就是进程ID。如果我们知道了进程ID,就可以使用attach命令对其进行调试了。
在上面代码中,fork()函数创建的子进程内部,首先会进入while循环sleep,然后在while循环之后调用printf函数。这样做的目的有如下:
- 帮助attach捕获要调试的进程id
- 在使用gdb进行调试的时候,真正的代码(即print函数)没有被执行,这样就可以从头开始对子进程进行调试
可能会有疑惑,上面代码以及进入while循环,无论如何是不会执行到下面printf函数。其实,这就是gdb的厉害之处,可以通过gdb命令修改num的值,以便其跳出while循环
使用如下命令编译生成可执行文件test_process
g++ -g test_process.cc -o test_process现在,我们开始尝试启动调试。
gdb -q ./test_process
Reading symbols from /root/test_process...done.
(gdb)这里需要说明下,之所以加-q选项,是想去掉其他不必要的输出,q为quite的缩写。
(gdb) r
Starting program: /root/./test_process
Detaching after fork from child process 37482.
this is parent,pid = 37478
[Inferior 1 (process 37478) exited normally]
Missing separate debuginfos, use: debuginfo-install glibc-2.17-260.el7.x86_64 libgcc-4.8.5-36.el7.x86_64 libstdc++-4.8.5-36.el7.x86_64
(gdb) attach 37482
//符号类输出,此处略去
(gdb) n
Single stepping until exit from function __nanosleep_nocancel,
which has no line number information.
0x00007ffff72b3cc4 in sleep () from /lib64/libc.so.6
(gdb)
Single stepping until exit from function sleep,
which has no line number information.
main () at test_process.cc:8
8 while(num==10){
(gdb)在上述命令中,我们执行了n(next的缩写),使其重新对while循环的判断体进行判断。
(gdb) set num = 1
(gdb) n
12 printf("this is child,pid = %d\n",getpid());
(gdb) c
Continuing.
this is child,pid = 37482
[Inferior 1 (process 37482) exited normally]
(gdb)为了退出while循环,我们使用set命令设置了num的值为1,这样条件就会失效退出while循环,进而执行下面的printf()函数;在最后我们执行了c(continue的缩写)命令,支持程序退出。
如果程序正在正常运行,出现了死锁等现象,则可以通过ps获取进程ID,然后根据gdb attach pid进行绑定,进而查看堆栈信息
指定进程
默认情况下,GDB调试多进程程序时候,只调试父进程。GDB提供了两个命令,可以通过follow-fork-mode和detach-on-fork来指定调试父进程还是子进程。
follow-fork-mode
该命令的使用方式为:
(gdb) set follow-fork-mode mode其中,mode有以下两个选项:
- parent:父进程,mode的默认选项
- child:子进程,其目的是告诉 gdb 在目标应用调用fork之后接着调试子进程而不是父进程,因为在Linux系统中fork()系统调用成功会返回两次,一次在父进程,一次在子进程
(gdb) show follow-fork-mode
Debugger response to a program call of fork or vfork is "parent".
(gdb) set follow-fork-mode child
(gdb) r
Starting program: /root/./test_process
[New process 37830]
this is parent,pid = 37826
^C
Program received signal SIGINT, Interrupt.
[Switching to process 37830]
0x00007ffff72b3e10 in __nanosleep_nocancel () from /lib64/libc.so.6
Missing separate debuginfos, use: debuginfo-install glibc-2.17-260.el7.x86_64 libgcc-4.8.5-36.el7.x86_64 libstdc++-4.8.5-36.el7.x86_64
(gdb) n
Single stepping until exit from function __nanosleep_nocancel,
which has no line number information.
0x00007ffff72b3cc4 in sleep () from /lib64/libc.so.6
(gdb) n
Single stepping until exit from function sleep,
which has no line number information.
main () at test_process.cc:8
8 while(num==10){
(gdb) show follow-fork-mode
Debugger response to a program call of fork or vfork is "child".
(gdb)在上述命令中,我们做了如下操作:
- show follow-fork-mode:通过该命令来查看当前处于什么模式下,通过输出可以看出,处于parent即父进程模式
- set follow-fork-mode child:指定调试子进程模式
- r:运行程序,直接运行程序,此时会进入子进程,然后执行while循环
- ctrl + c:通过该命令,可以使得GDB收到SIGINT命令,从而暂停执行while循环
- n(next):继续执行,进而进入到while循环的条件判断处
- show follow-fork-mode:再次执行该命令,通过输出可以看出,当前处于child模式下
detach-on-fork
如果一开始指定要调试子进程还是父进程,那么使用follow-fork-mode命令完全可以满足需求;但是如果想在调试过程中,想根据实际情况在父进程和子进程之间来回切换调试呢?
GDB提供了另外一个命令:
(gdb) set detach-on-fork mode其中mode有如下两个值:
on:默认值,即表明只调试一个进程,可以是子进程,也可以是父进程
off:程序中的每个进程都会被记录,进而我们可以对所有的进程进行调试
如果选择关闭detach-on-fork模式(mode为off),那么GDB将保留对所有被fork出来的进程控制,即可用调试所有被fork出来的进程。可用 使用info forks命令列出所有的可被GDB调试的fork进程,并可用使用fork命令从一个fork进程切换到另一个fork进程。
- info forks: 打印DGB控制下的所有被fork出来的进程列表。该列表包括fork id、进程id和当前进程的位置
- fork fork-id: 参数fork-id是GDB分配的内部fork编号,该编号可用通过上面的命令
info forks获取
coredump
当我们开发或者使用一个程序时候,最怕的莫过于程序莫名其妙崩溃。为了分析崩溃产生的原因,操作系统的内存内容(包括程序崩溃时候的堆栈等信息)会在程序崩溃的时候dump出来(默认情况下,这个文件名为core.pid,其中pid为进程id),这个dump操作叫做coredump(核心转储),然后我们可以用调试器调试此文件,以还原程序崩溃时候的场景。
在我们分析如果用gdb调试coredump文件之前,先需要生成一个coredump,为了简单起见,我们就用如下例子来生成:
#include <stdio.h>
void print(int *v, int size) {
for (int i = 0; i < size; ++i) {
printf("elem[%d] = %d\n", i, v[i]);
}
}
int main() {
int v[] = {0, 1, 2, 3, 4};
print(v, 1000);
return 0;
}编译并运行该程序:
g++ -g test_core.cc -o test_core
./test_core输出如下:
elem[775] = 1702113070
elem[776] = 1667200115
elem[777] = 6648431
elem[778] = 0
elem[779] = 0
段错误(吐核)如我们预期,程序产生了异常,但是却没有生成coredump文件,这是因为在系统默认情况下,coredump生成是关闭的,所以需要设置对应的选项以打开coredump生成。
针对多线程程序产生的coredump,有时候其堆栈信息并不能完整的去分析原因,这就使得我们得有其他方式。
18年有一次线上故障,在测试环境一切正常,但是在线上的时候,就会coredump,根据gdb调试coredump,只能定位到了libcurl里面,但却定位不出原因,用了大概两天的时间,发现只有在超时的时候,才会coredump,而测试环境因为配置比较差超时设置的是20ms,而线上是5ms,知道coredump原因后,采用逐步定位缩小范围法,逐步缩小代码范围,最终定位到是libcurl一个bug导致。所以,很多时候,定位线上问题需要结合实际情况,采取合适的方法来定位问题。
配置
配置coredump生成,有临时配置(退出终端后,配置失效)和永久配置两种。
临时
通过ulimit -a可以判断当前有没有配置coredump生成:
ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0从上面输出可以看出core file size后面的数为0,即不生成coredump文件,我们可以通过如下命令进行设置
ulimit -c size其中size为允许生成的coredump大小,这个一般尽量设置大点,以防止生成的coredump信息不全,笔者一般设置为不限。
ulimit -c unlimited需要说明的是,临时配置的coredump选项,其默认生成路径为执行该命令时候的路径,可以通过修改配置来进行路径修改。
永久
上面的设置只是使能了core dump功能,缺省情况下,内核在coredump时所产生的core文件放在与该程序相同的目录中,并且文件名固定为core。很显然,如果有多个程序产生core文件,或者同一个程序多次崩溃,就会重复覆盖同一个core文件。
过修改kernel的参数,可以指定内核所生成的coredump文件的文件名。使用下面命令,可以实现coredump永久配置、存放路径以及生成coredump名称等。
mkdir -p /www/coredump/
chmod 777 /www/coredump/
/etc/profile
ulimit -c unlimited
/etc/security/limits.conf
* soft core unlimited
echo "/www/coredump/core-%e-%p-%h-%t" > /proc/sys/kernel/core_pattern调试
现在,我们重新执行如下命令,按照预期产生coredump文件:
./test_coredump
elem[955] = 1702113070
elem[956] = 1667200115
elem[957] = 6648431
elem[958] = 0
elem[959] = 0
段错误(吐核)然后使用下面的命令进行coredump调试:
gdb ./test_core -c /www/coredump/core_test_core_1640765384_38924 -q输出如下:
#0 0x0000000000400569 in print (v=0x7fff3293c100, size=1000) at test_core.cc:5
5 printf("elem[%d] = %d\n", i, v[i]);
Missing separate debuginfos, use: debuginfo-install glibc-2.17-260.el7.x86_64 libgcc-4.8.5-36.el7.x86_64 libstdc++-4.8.5-36.el7.x86_64
(gdb)可以看出,程序core在了第5行,此时,我们可以通过where命令来查看堆栈回溯信息。
在gdb中输入where命令,可以获取堆栈调用信息。当进行coredump调试时候,这个是最基本且最有用处的命令。where命令输出的结果包含程序中 的函数名称和相关参数值。
通过where命令,我们能够发现程序core在了第5行,那么根据分析源码基本就能定位原因。
需要注意的是,在多线程运行的时候,core不一定在当前线程,这就需要我们对代码有一定的了解,能够保证哪块代码是安全的,然后通过thread num切换线程,然后再通过bt或者where命令查看堆栈信息,进而定位coredump原因。
原理
在前面几节,我们讲了gdb的命令,以及这些命令在调试时候的作用,并以例子进行了演示。作为C/C++ coder,要知其然,更要知其所以然。所以,借助本节,我们大概讲下GDB调试的原理。
gdb 通过系统调用 ptrace 来接管一个进程的执行。ptrace 系统调用提供了一种方法使得父进程可以观察和控制其它进程的执行,检查和改变其核心映像以及寄存器。它主要用来实现断点调试和系统调用跟踪。
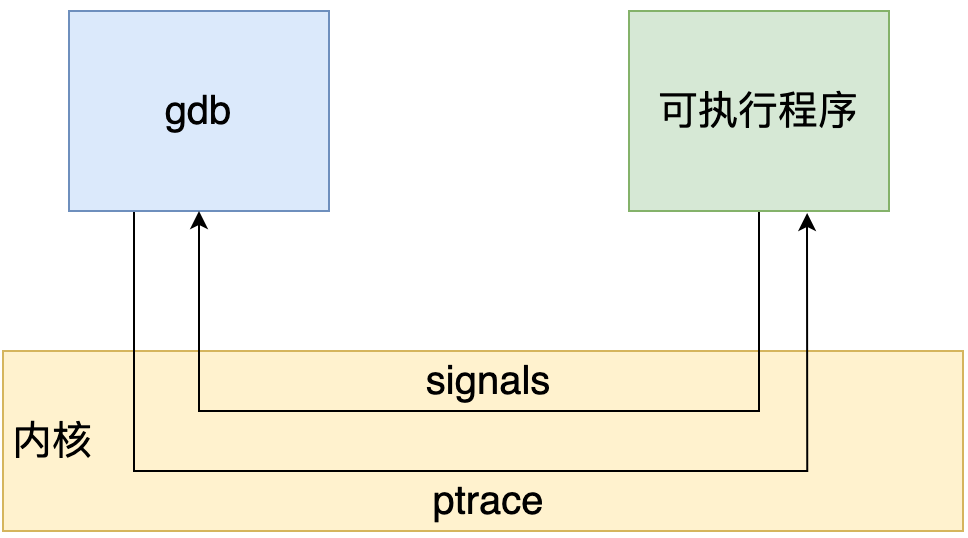
ptrace系统调用定义如下:
#include <sys/ptrace.h>
long ptrace(enum __ptrace_request request, pid_t pid, void *addr, void *data)- pid_t pid:指示 ptrace 要跟踪的进程
- void *addr:指示要监控的内存地址
- enum __ptrace_request request:决定了系统调用的功能,几个主要的选项:
- PTRACE_TRACEME:表示此进程将被父进程跟踪,任何信号(除了
SIGKILL)都会暂停子进程,接着阻塞于wait()等待的父进程被唤醒。子进程内部对exec()的调用将发出SIGTRAP信号,这可以让父进程在子进程新程序开始运行之前就完全控制它 - PTRACE_ATTACH:attach 到一个指定的进程,使其成为当前进程跟踪的子进程,而子进程的行为等同于它进行了一次 PTRACE_TRACEME 操作。但需要注意的是,虽然当前进程成为被跟踪进程的父进程,但是子进程使用
getppid()的到的仍将是其原始父进程的pid - PTRACE_CONT:继续运行之前停止的子进程。可同时向子进程交付指定的信号
- PTRACE_TRACEME:表示此进程将被父进程跟踪,任何信号(除了
调试原理
运行并调试新进程
运行并调试新进程,步骤如下:
- 运行gdb exe
- 输入run命令,gdb执行以下操作:
- 通过fork()系统调用创建一个新进程
- 在新创建的子进程中执行ptrace(PTRACE_TRACEME, 0, 0, 0)操作
- 在子进程中通过execv()系统调用加载指定的可执行文件
attach运行的进程
可以通过gdb attach pid来调试一个运行的进程,gdb将对指定进程执行ptrace(PTRACE_ATTACH, pid, 0, 0)操作。
需要注意的是,当我们attach一个进程id时候,可能会报如下错误:
Attaching to process 28849
ptrace: Operation not permitted.这是因为没有权限进行操作,可以根据启动该进程用户下或者root下进行操作。
断点原理
实现原理
当我们通过b或者break设置断点时候,就是在指定位置插入断点指令,当被调试的程序运行到断点的时候,产生SIGTRAP信号。该信号被gdb捕获并 进行断点命中判断。
设置原理
在程序中设置断点,就是先在该位置保存原指令,然后在该位置写入int 3。当执行到int 3时,发生软中断,内核会向子进程发送SIGTRAP信号。当然,这个信号会转发给父进程。然后用保存的指令替换int 3并等待操作恢复。
命中判断
gdb将所有断点位置存储在一个链表中。命中判定将被调试程序的当前停止位置与链表中的断点位置进行比较,以查看断点产生的信号。
条件判断
在断点处恢复指令后,增加了一个条件判断。如果表达式为真,则触发断点。由于需要判断一次,添加条件断点后,是否触发条件断点,都会影响性能。在 x86 平台上,部分硬件支持硬件断点。不是在条件断点处插入 int 3,而是插入另一条指令。当程序到达这个地址时,不是发出int 3信号,而是进行比较。特定寄存器的内容和某个地址,然后决定是否发送int 3。因此,当你的断点位置被程序频繁“通过”时,尽量使用硬件断点,这将有助于提高性能。
单步原理
这个ptrace函数本身就支持,可以通过ptrace(PTRACE_SINGLESTEP, pid,...)调用来实现单步。
printf("attaching to PID %d\n", pid);
if (ptrace(PTRACE_ATTACH, pid, 0, 0) != 0)
{
perror("attach failed");
}
int waitStat = 0;
int waitRes = waitpid(pid, &waitStat, WUNTRACED);
if (waitRes != pid || !WIFSTOPPED(waitStat))
{
printf("unexpected waitpid result!\n");
exit(1);
}
int64_t numSteps = 0;
while (true) {
auto res = ptrace(PTRACE_SINGLESTEP, pid, 0, 0);
}上述代码,首先接收一个pid,然后对其进行attach,最后调用ptrace进行单步调试。
其它
借助本文,简单介绍下笔者工作过程中使用的一些其他命令或者工具。
pstack
此命令可显示每个进程的栈跟踪。pstack 命令必须由相应进程的属主或 root 运行。可以使用 pstack 来确定进程挂起的位置。此命令允许使用的唯一选项是要检查的进程的 PID。
这个命令在排查进程问题时非常有用,比如我们发现一个服务一直处于work状态(如假死状态,好似死循环),使用这个命令就能轻松定位问题所在;可以在一段时间内,多执行几次pstack,若发现代码栈总是停在同一个位置,那个位置就需要重点关注,很可能就是出问题的地方;
以前面的多线程代码为例,其进程ID是4507(在笔者本地),那么通过
pstack 4507输出结果如下:
Thread 3 (Thread 0x7f07aaa69700 (LWP 45708)):
#0 0x00007f07aab2ee2d in nanosleep () from /lib64/libc.so.6
#1 0x00007f07aab2ecc4 in sleep () from /lib64/libc.so.6
#2 0x00007f07ab403eb9 in std::this_thread::__sleep_for(std::chrono::duration<long, std::ratio<1l, 1l> >, std::chrono::duration<long, std::ratio<1l, 1000000000l> >) () from /lib64/libstdc++.so.6
#3 0x00000000004018cc in void std::this_thread::sleep_for<long, std::ratio<1l, 1l> >(std::chrono::duration<long, std::ratio<1l, 1l> > const&) ()
#4 0x00000000004012de in fun_int(int) ()
#5 0x0000000000404696 in int std::_Bind_simple<int (*(int))(int)>::_M_invoke<0ul>(std::_Index_tuple<0ul>) ()
#6 0x000000000040443d in std::_Bind_simple<int (*(int))(int)>::operator()() ()
#7 0x000000000040436e in std::thread::_Impl<std::_Bind_simple<int (*(int))(int)> >::_M_run() ()
#8 0x00007f07ab404070 in ?? () from /lib64/libstdc++.so.6
#9 0x00007f07ab65ddd5 in start_thread () from /lib64/libpthread.so.0
#10 0x00007f07aab67ead in clone () from /lib64/libc.so.6
Thread 2 (Thread 0x7f07aa268700 (LWP 45709)):
#0 0x00007f07aab2ee2d in nanosleep () from /lib64/libc.so.6
#1 0x00007f07aab2ecc4 in sleep () from /lib64/libc.so.6
#2 0x00007f07ab403eb9 in std::this_thread::__sleep_for(std::chrono::duration<long, std::ratio<1l, 1l> >, std::chrono::duration<long, std::ratio<1l, 1000000000l> >) () from /lib64/libstdc++.so.6
#3 0x00000000004018cc in void std::this_thread::sleep_for<long, std::ratio<1l, 1l> >(std::chrono::duration<long, std::ratio<1l, 1l> > const&) ()
#4 0x0000000000401340 in fun_string(std::string const&) ()
#5 0x000000000040459f in int std::_Bind_simple<int (*(char const*))(std::string const&)>::_M_invoke<0ul>(std::_Index_tuple<0ul>) ()
#6 0x000000000040441f in std::_Bind_simple<int (*(char const*))(std::string const&)>::operator()() ()
#7 0x0000000000404350 in std::thread::_Impl<std::_Bind_simple<int (*(char const*))(std::string const&)> >::_M_run() ()
#8 0x00007f07ab404070 in ?? () from /lib64/libstdc++.so.6
#9 0x00007f07ab65ddd5 in start_thread () from /lib64/libpthread.so.0
#10 0x00007f07aab67ead in clone () from /lib64/libc.so.6
Thread 1 (Thread 0x7f07aba80740 (LWP 45707)):
#0 0x00007f07ab65ef47 in pthread_join () from /lib64/libpthread.so.0
#1 0x00007f07ab403e37 in std::thread::join() () from /lib64/libstdc++.so.6
#2 0x0000000000401455 in main ()在上述输出结果中,将进程内部的详细信息都输出在终端,以方便分析问题。
ldd
在我们编译过程中通常会提示编译失败,通过输出错误信息发现是找不到函数定义,再或者编译成功了,但是运行时候失败(往往是因为依赖了非正常版本的lib库导致),这个时候,我们就可以通过ldd来分析该可执行文件依赖了哪些库以及这些库所在的路径。
用来查看程式运行所需的共享库,常用来解决程式因缺少某个库文件而不能运行的一些问题。
仍然查看可执行程序test_thread的依赖库,输出如下:
ldd -r ./test_thread
linux-vdso.so.1 => (0x00007ffde43bc000)
libpthread.so.0 => /lib64/libpthread.so.0 (0x00007f8c5e310000)
libstdc++.so.6 => /lib64/libstdc++.so.6 (0x00007f8c5e009000)
libm.so.6 => /lib64/libm.so.6 (0x00007f8c5dd07000)
libgcc_s.so.1 => /lib64/libgcc_s.so.1 (0x00007f8c5daf1000)
libc.so.6 => /lib64/libc.so.6 (0x00007f8c5d724000)
/lib64/ld-linux-x86-64.so.2 (0x00007f8c5e52c000)在上述输出中:
- 第一列:程序需要依赖什么库
- 第二列:系统提供的与程序需要的库所对应的库
- 第三列:库加载的开始地址
在有时候,我们通过ldd查看依赖库的时候,会提示找不到库,如下:
ldd -r test_process
linux-vdso.so.1 => (0x00007ffc71b80000)
libstdc++.so.6 => /lib64/libstdc++.so.6 (0x00007fe4badd5000)
libm.so.6 => /lib64/libm.so.6 (0x00007fe4baad3000)
libgcc_s.so.1 => /lib64/libgcc_s.so.1 (0x00007fe4ba8bd000)
libc.so.6 => /lib64/libc.so.6 (0x00007fe4ba4f0000)
/lib64/ld-linux-x86-64.so.2 (0x00007fe4bb0dc000)
liba.so => not found比如上面最后一句提示,liba.so找不到,这个时候,需要我们知道liba.so的路径,比如在/path/to/liba.so,那么可以有下面两种方式:
LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/path/to/这样在通过ldd查看,就能找到对应的lib库,但是这个缺点是临时的,即退出终端后,再执行ldd,仍然会提示找不到该库,所以就有了另外一种方式,即通过修改/etc/ld.so.conf,在该文件的后面加上需要的路径,即
include ld.so.conf.d/*.conf
/path/to/然后通过如下命令,即可永久生效
/sbin/ldconfigc++filter
因为c++支持重载,也就引出了编译器的name mangling机制,对函数进行重命名。
我们通过strings命令查看test_thread中的函数信息(仅输出fun等相关)
strings test_thread | grep fun_
in fun_int n =
in fun_string s =
_GLOBAL__sub_I__Z7fun_inti
_Z10fun_stringRKSs可以看到_Z10fun_stringRKSs这个函数,如果想知道这个函数定义的话,可以使用c++filt命令,如下:
c++filt _Z10fun_stringRKSs
fun_string(std::basic_string<char, std::char_traits<char>, std::allocator<char> > const&)通过上述输出,我们可以将编译器生成的函数名还原到我们代码中的函数名即fun_string。
结语
GDB是一个在Linux上进行开发的一个必不可少的调试工具,使用场景依赖于具体的需求或者遇到的具体问题。在我们的日常开发工作中,熟练使用GDB加以辅助,能够使得开发过程事半功倍。
本文从一些简单的命令出发,通过举例调试可执行程序(单线程、多线程以及多进程场景)、coredump文件等各个场景,使得大家能够更加直观的了解GDB的使用。GDB功能非常强大,笔者工作中使用的都是非常基本的一些功能,如果想深入理解GDB,则需要去官网进行阅读了解。
本文从构思到完成,大概用了三周时间,写作过程是痛苦的(需要整理资料以及构建各种场景,以及将各种现场还原),同时又是收获满满的。通过本文,进一步加深了对GDB的底层原理理解。
参考
(https://www.codetd.com/en/article/13107993)
https://users.ece.utexas.edu/~adnan/gdb-refcard.pdf
https://www.cloudsavvyit.com/10921/debugging-with-gdb-getting-started/
https://blog.birost.com/a?ID=00650-b03e2257-94bf-41f3-b0fc-d352d5b02431
https://www.cnblogs.com/xsln/p/ptrace.html
原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/197
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!