
TCP 对 RTO 有个最小值限制,一般限制为 MIN_RTO = 200ms。之所以有这个限制,在于要适应 Delay ACK,而 Delay ACK 的意义,不多说,摘自 RFC1122:


MIN_RTO 应该足够大,以覆盖 Delay ACK 的影响,如果 RTO 过小将导致过多不必要的超时重传。但又不能过大,否则将导致超时重传不及时。
这个限制在广域网不存在什么问题。广域网 RTT 一般为几十 ms 量级,200ms 的最小超时时间没有任何问题。但当 TCP 运行在数据中心时,200ms 超时时间是一段相当漫长的等待。50us 是典型的 DC 网络 RTT,4000 倍于 RTT 的等待是不合理的。但又不能在 sender 轻易取消 MIN_RTO 的限制。
DC 内部,RTO 有 MIN 限制,sender 超时重传不及时,取消了该限制,万一碰到真的 Delay ACK,又会频繁虚假超时,TLP 只能解决尾丢的部分问题,一旦 RTO 兜底,还是会进入漫长等待。取消限制也不是,不取消限制也不是。
在所有 receiver 端取消 Delay ACK 是几乎不可能的,要么就在 sender 识别 Delayed ACK,Linux TCP 已经有了一种方式:
if (pkts_acked == 1 && last_in_flight < tp->mss_cache &&
last_in_flight && !prior_sacked && fully_acked &&
sack->rate->prior_delivered + 1 == tp->delivered &&
!(flag & (FLAG_CA_ALERT | FLAG_SYN_ACKED))) {
/* Conservatively mark a delayed ACK. It's typically
* from a lone runt packet over the round trip to
* a receiver w/o out-of-order or CE events.
*/
flag |= FLAG_ACK_MAYBE_DELAYED;
}
但即使识别到了,Linux TCP 也没有用这个 flag bit 做更多的事,因为有很多规范要遵守。但如果遵守这些规范,就注定要在 Delay ACK 和 RTO 的纷乱复杂的关联中纠缠。
本质在于,根据 Delay ACK 计算得到 1/8 rtt sample 以及 4*rttvar 已成了噪声,正常的做法,在计算 RTT 时应该排除掉它们,或至少限制它们,而不是限制 RTO。
为此,我建议一种更准确的 RTT 计算方法以及 RTO 的行为。
首先,我们换一种方式获取样本:
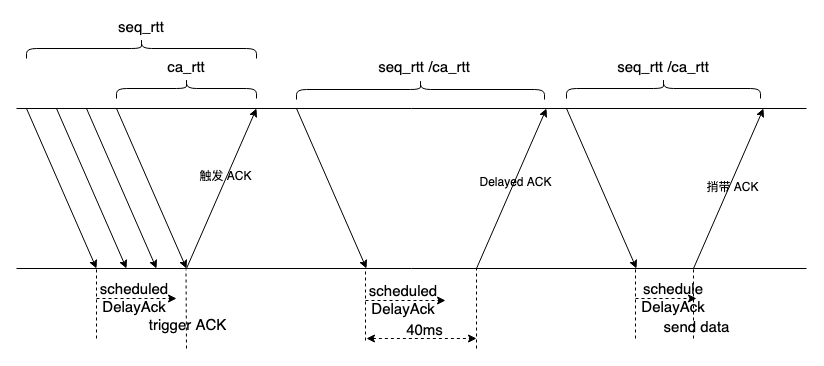
依上图解释,若要排除 Delay ACK 的影响,只有 ca_rtt 是唯一有效的样本,但当前 Linux TCP 却采用 seq_rtt,这里的逻辑要修改。同时,因为捎带 ACK 的主机时延不确定,要把捎带 ACK 排除掉,如果双向传输,我这个方法会导致 RTT 样本过少。
假设单向传输(绝大多数场景),以 ca_rtt 作为样本计算 RTT 和 RTO,取消 MIN_RTO 限制,算出来多少就是多少,注意,RTO 已经是 us 精度(在实现上可能会消耗过多 CPU 资源,具体尚未测试):
if (seq_rtt == ca_rtt >= 40ms || MAYBE_DELAYED)
drop sample
return
else if (PUREACK && seq_rtt > ca_rtt)
take ca_rtt
else if (SACK)
take ca_rtt
else if 捎带ACK
drop sample
return
else
?(可能还有一些没考虑到的...)
rtt = 7/8*rtt + 1/8*ca_rtt
rttvar = 3/4*rttvar + 1/4*|rtt - ca_rtt|
rto = rtt + 4*rttvar
其实双向传输也无所谓,照样可以舍弃 Delayed ACK 以及捎带 ACK 带来的样本,因为它们带来的是噪声,如果觉得丢掉它们造成样本过少而心里不舒服(其实还是以为违背了标准实现,和 Linux TCP 实现不一样而导致心里不舒服…),那么换个视角,宁缺毋滥!
RTO 的动作需要分两个部分,算法如下:
if inflight < 2*mss
reset_timer(RTO_MIN - rto) // 可能真的发生了 Delay ACK,回退到原本
else
lost_retransmit
至于对 cc 的影响,我认为没有影响,cc 本来就使用排除了主机时延的 ca_rtt 样本测量网络时延。
圆环闭合了,既解决了 RTO 重传不及时问题,又解决了真遇到 Delay ACK 但 RTO 过小导致的虚假超时问题。
这个 RTT/RTO 算法能否在 DC 网络上线不是取决于它有多自洽,而要基于 DC 网络 TCP 传输的统计特征。receiver 发送了多少 Delayed ACK,sender 预判了多少 Delayed ACK,如果这两个值均足够大且比值接近 1,就直接采用上述算法,若 receiver 稀有发送 Delay ACK,同时 sender 也鲜有收到 Delay ACK,则可直接去除 MIN_RTT 限制,大不了就虚假超时,频度不高影响就不大,相比增加逻辑复杂性,直接去掉限制更划算。
下面是一个简单的采集脚本,Python 简单分析下即可得统计特征,或者肉眼看也行:
#!/usr/local/bin/bpftrace
#include <net/sock.h>
#include <linux/tcp.h>
kprobe:tcp_ack_update_rtt
{
$tcps = (struct tcp_sock *)arg0;
if ($tcps->srtt_us>>3 > 500) {
}
else if (arg2 > arg4) {
printf("normal: %d %d srtt:%d\n", arg2, arg4, $tcps->srtt_us>>3)
}
else if ($tcps->srtt_us == 0) {
}
else if (arg2 < 1000) {
}
else if (arg2 == -1) {
}
else if (arg3 != -1) {
}
else if (arg1 & 0x10000) {
printf("delay: this:%d %d %d srtt:%d\n", arg2, arg4, arg3, $tcps->srtt_us>>3);
} else{
printf(" %d %d srtt:%d\n", arg2, arg4, $tcps->srtt_us>>3)
}
}
根据实际数据样本的统计特征做决策,比规划一个自洽闭环的算法更高尚。
TCP 的多个 timer 为网络不确定性提供弹性容错空间,而 DC 网络相比广域网有两个明显不同:DC 网络时延不确定性更低;DC 低时延网络使时延抖动更容易被放大。要针对这两个差异改造 DC 网络 TCP。
试想 RTT = 50ms 的广域网连接,发生了拥塞后,徒增排队时延 20ms,抖动为 0.4,但在 DC 网络,RTT = 50us 的连接,同样徒增排队时延 20ms,抖动就是 400。
如何修改 TCP 以适配这种表观差异?简单说就两点,压缩动态范围,排除固定时延。
首先要压缩弹性空间,使 RTO 的操作精度与 DC 网络的 RTT 精度同量级,从而可识别抖动,因此需要将 RTO 改为 us 级别。其次,尽可能消除除传播时延以外的其它时延,如 Delay ACK 时延,捎带 ACK 时延,这些时延取决于主机而非网络,在 DC 内,这些主机时延在整个 RTT 中占比很大,因此 ca_rtt 是更优秀的样本。
更进一步,在 DC 内网这特定场景,我想能统一重传触发了,不再区分 RTO,Fast Retransmit,TLP,全归于 RACK。当然,广域网也可以,只是没有 DC 内网这么迫切需要,现有 RTO + Fast Retransmit 工作得足够好。
针对 RACK,评述几句。
TCP 的 sender 以发送时间序对报文编号,receiver 对报文编号确认才合理,而非 sender 以字节流序列编号,receiver 对字节流序号确认。现实的 TCP 采用了后面不合理的方式,导致了不少麻烦。这个已经说了不止一遍。
RACK 对此尽力做了修正。
RACK 在 sender 端维护了一个按照发送时间序排序的队列,但它没对报文编号,因为没地方可编号,所以 receiver 自然没法针对编号进行确认。但至少 sender 有了一个发送时间序,该时间序将原始报文和重传报文都包含在内。
虽然 RACK 依旧无法区分 ACK/SACK 对针对谁的,但也只是影响 RTT 采样精度,至少 RACK 可以做到平滑重传,而不是像 dupthresh 那样只有一次重传机会。因此,RACK 可以作为一切重传的触发机制,而不仅仅应用于 fast retransmit,包括不限于 RTO,TLP。
甩开 Delay ACK 这个不确定时间后,就再也没有 RTO 过大问题,TLP 不再需要,以 RTO 界定的 “未来” 时间作为 RACK timer 的超时时间,便可对尾部传输做统一的安排,逻辑反而更简单。当然,RTO 的概念还是存在的。
你看,若不是 Delay ACK,TCP 超时重传多么直白。
当然,本文只是我的一个方法,该方法是单边方案,实现起来相对简单,十几行代码搞得定。Google 有一种更正式且中规中矩的方法,参见:TCP Options for Low Latency。
浙江温州皮鞋湿,下雨进水不会胖。
原文链接: https://blog.csdn.net/dog250/article/details/128972485
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍;
也有高质量的技术群,里面有嵌入式、搜广推等BAT大佬

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/405305
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!