
Splunk Enterprise architecture and processes
This topic discusses the internal architecture and processes of Splunk Enterprise at a high level. If you're looking for information about third-party components used in Splunk Enterprise, see the credits section in the Release notes.
Splunk Enterprise Processes
A Splunk Enterprise server installs a process on your host, splunkd.
splunkd is a distributed C/C++ server that accesses, processes and indexes streaming IT data. It also handles search requests. splunkd processes and indexes your data by streaming it through a series of pipelines, each made up of a series of processors.
- Pipelines are single threads inside the
splunkdprocess, each configured with a single snippet of XML. - Processors are individual, reusable C or C++ functions that act on the stream of IT data that passes through a pipeline. Pipelines can pass data to one another through queues.
Architecture diagram

注意:负载均衡,副本!
Splunk Architecture
A Bit About Architecture
Splunk is a high performance, scalable software server written in C/C++ and Python. It indexes and searches logs and other IT data in real time. Splunk works with data generated by any application, server or device. The Splunk Developer API is accessible via REST, SOAP or the command line. After downloading, installing and starting Splunk, you'll find two Splunk Server processes running on your host, splunkd and splunkweb.
- splunkd is a distributed C/C++ server that accesses, processes and indexes streaming IT data and also handles search requests. splunkd processes and indexes your data by streaming it through a series of pipelines, each made up of a series of processors. Pipelines are single threads inside the splunkd process, each configured with a single snippet of XML. Processors are individual, reusable C/C++ or Python functions that act on the stream of IT data passing through a pipeline. Pipelines can pass data to one another via queues. splunkd supports a command line interface for searching and viewing results.
- splunkweb is a Python-based application server providing the Splunk Web user interface. It allows users to search and navigate IT data stored by Splunk servers and to manage your Splunk deployment through the browser interface. splunkweb communicates with your web browser via REST and communicates with splunkd via SOAP.
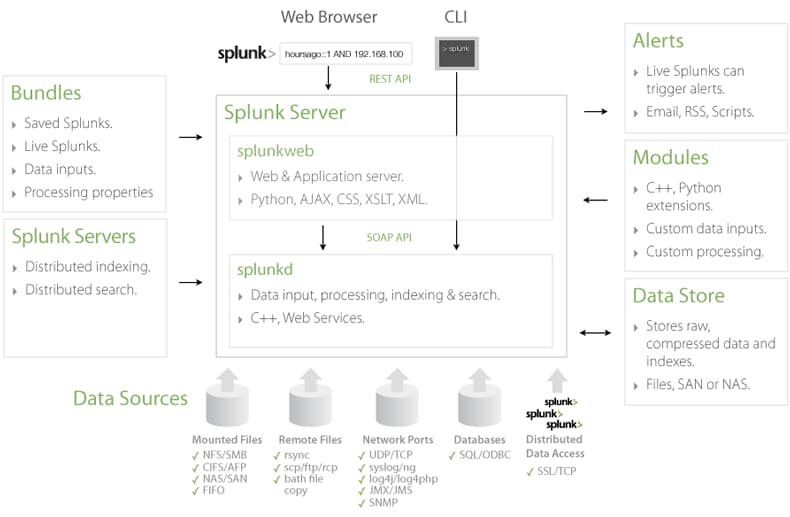

- Splunk's Data Store manages the original raw data in compressed format as well as the indexes into the data. Data can be deleted or archived based on retention period or maximum data store size.
- Splunk Servers can communicate with one another via Splunk-2-Splunk, a TCP-based protocol, to forward data from one server to another and to distribute searches across multiple servers.
- Bundles are files that contain configuration settings including, user accounts, Splunks, Live Splunks, Data Inputs and Processing Properties to easily create specific Splunk environments.
- Modules are files that add new functionality to Splunk by adding to or modifying existing processors and pipelines.
About forwarding and receiving
You can forward data from one Splunk instance to another Splunk server or even to a non-Splunk system. The Splunk instance that performs theforwarding is typically a smaller footprint version of Splunk, called a forwarder.
A Splunk instance that receives data from one or more forwarders is called a receiver. The receiver is usually a Splunk indexer, but can also be another forwarder, as described here.
This diagram shows three forwarders sending data to a single Splunk receiver (an indexer), which then indexes the data and makes it available for searching:

原文链接: https://www.cnblogs.com/bonelee/p/6150073.html
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/245474
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!