
原型:voidmemcpy(voiddest, const void*src,unsigned int count);
功能:由src所指内存区域复制count个字节到dest所指内存区域。
说明:src和dest所指内存区域不能重叠,函数返回指向dest的指针。
看一下这个函数的解释:
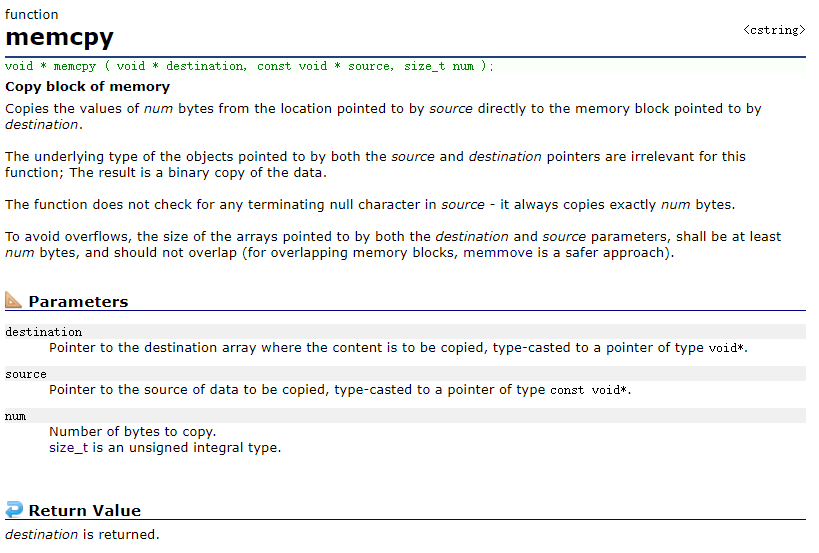

Example:
/* memcpy example */
#include <stdio.h>
#include <string.h>
struct {
char name[40];
int age;
} person, person_copy;
int main ()
{
char myname[] = "Pierre de Fermat";
/* using memcpy to copy string: */
memcpy ( person.name, myname, strlen(myname)+1 );
person.age = 46;
/* using memcpy to copy structure: */
memcpy ( &person_copy, &person, sizeof(person) );
printf ("person_copy: %s, %d n", person_copy.name, person_copy.age );
return 0;
}
Output:
person_copy: Pierre de Fermat, 46
关于 浅拷贝 和 深拷贝
在对象拷贝过程中,如果没有自定义拷贝构造函数,系统会提供一个缺省的拷贝构造函数。缺省的拷贝构造函数对于基本类型的成员变量,按字节复制;对于类类型成员变量,调用其相应类型的拷贝构造函数。
浅拷贝
位拷贝,编译器只是直接将指针的值拷贝过来。多个对象共用同一块内存资源,若同一块资源释放多次,会发生崩溃或者内存泄漏。
示例:
class A
{
public:
A() {
name = new char[20];
std::cout << "A()" << std::endl;
}
~A(){
std::cout << "~A()" << std::endl;
delete name;
name = NULL;
}
private:
int num;
char* name;
};
int main(int argc, char *argv[])
{
A a1;
A a2(a1); // 浅拷贝
return 0;
}
执行结果:程序调用一次构造函数,二次析构函数后,发生崩溃。name指针分配一次内存,该内存却被释放两次,导致程序崩溃。
原因即是上面所述,在对象拷贝过程中,系统发现我们没有自定义拷贝构造函数,会使用默认缺省构造函数进行浅拷贝。所以对name指针进行拷贝后,出现两个指针指向同一块内存。
这个时候我们就需要使用深拷贝。
深拷贝
每个对象拥有自己的资源,显式提供拷贝构造函数。
class A
{
public:
A() {
name = new char[20];
std::cout << "A()" << std::endl;
}
A(const A &a) {
name = new char[20];
memcpy(name, a.name, strlen(a.name));
}
~A(){
std::cout << "~A()" << std::endl;
delete name;
name = NULL;
}
private:
int num;
char* name;
};
int main(int argc, char *argv[])
{
A a1;
A a2(a1); // 浅拷贝
return 0;
}
执行结果:程序调用一次构造函数,一次自定义拷贝构造函数,两次析构函数。两个对象的指针成员所指内存不同。
总结:
- 浅拷贝只是对指针的拷贝,拷贝后两个指针指向同一块内存空间;
- 深拷贝不但对指针进行拷贝,而且对指针指向的内容进行拷贝,经深拷贝后的指针是指向两个不同地址的指针;
拷贝构造函数与赋值函数
这两个非常容易混淆,常导致错写、错用。拷贝构造函数是在对象被创建时调用的,而赋值函数只能被已经存在了的对象调用。
示例:
string a("hello");
string b("world");
string c = a; // 拷贝构造函数. 风格较差,最好写成string c(a);
c = b; // 赋值函数
c++11拷贝控制
1、= default
可以通过将拷贝控制成员定义为= default,显式地要求编译器生成它们的合成版本:
class A
{
public:
A() = default;
A(const A&) = default;
A &operator=(const A&);
~A() = default;
};
当我们在类体内的成员声明中指定= default时,编译器生成的合成函数是隐式内联的(就像在类体中定义的任何其他成员函数一样)。如果我们不希望合成函数是内联函数,我们可以在该函数的定义上指定= default,就像在重载=运算符的定义中那样。
注:我们只能对具有合成版本的成员函数使用= default(即默认构造函数或拷贝控制成员)。
2、= delete 阻止拷贝类对象
在新标准下,可以通过将拷贝构造函数和赋值运算符定义为已删除函数来阻止复制。已删除的函数是已声明的函数,但不能以任何其他方式使用。使用= delete跟随想要删除的函数的参数列表来将函数定义为已删除:
class A
{
public:
A();
A(const A&) = delete;
A &operator=(const A&) = delete;
~A();
};
= delete关键字既告诉编译器又告诉代码阅读者,故意没有定义这些成员。
与= default不同,= delete必须出现在已删除函数的第一个声明中。从逻辑上讲,这种差异源自这些声明的含义。默认成员只影响编译器生成的代码;因此在编译器生成代码之前不需要= default。另一方面,编译器需要知道一个函数被删除,以禁止试图使用它的操作。
与= default不同,可以在任何函数上指定= delete(可以在默认构造函数或编译器可以合成的拷贝控件成员上使用= default)。虽然删除函数的主要用途是抑制拷贝控制成员,但是当想要引导函数匹配过程时,删除函数有时也很有用。
原文链接: https://www.cnblogs.com/zzzsj/p/14582145.html
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍
原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/209052
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!