
http://www.jizhuomi.com/software/281.html
C/C++作为偏底层的语言,我们往往可以使用其对内存进行直接操作,相对来说比较灵活,但任何事情都有两面性,对内存的操作简便也经常导致程序出现内存bug。所以我们在编程时要特别重视内存和指针等概念,尽量避免bug,而这均取决于我们对内存的理解。
本文就从C/C++的内存基础知识讲起,让我们对内存有一个更深入的理解。
一、对内的分配
32位操作系统支持4GB内存的连续访问,但通常把内存分为两个2GB的空间,每个进程在运行时最大可以使用2GB的私有内存(0x00000000—0x7FFFFFFF)。即理论上支持如下的大数组:
- char szBuffer[2*1024*1024*1024];
当然,由于在实际运行时,程序还有代码段、临时变量段、动态内存申请等,实际上是不可能用到上述那么大的数组的。
至于高端的2GB内存地址(0x80000000—0xFFFFFFFF),操作系统一般内部保留使用,即供操作系统内核代码使用。在Windows和Linux平台上,一些动态链接库(Windows的dll,Linux的so)以及ocx控件等,由于是跨进程服务的,因此一般也在高2GB内存空间运行。
可以看到,每个进程都能看到自己的2GB内存以及系统的2GB内存,但是不同进程之间是无法彼此看到对方的。当然,操作系统在底层做了很多工作,比如磁盘上的虚拟内存交换(请看下以标题),不同的内存块动态映射等等。
二、虚拟内存
虚拟内存的基本思想是:用廉价但缓慢的磁盘来扩充快速却昂贵的内存。在一定时刻,程序实际需要使用的虚拟内存区段的内容就被载入物理内存中。当物理内存中的数据有一段时间未被使用,它们就可能被转移到硬盘中,节省下来的物理内存空间用于载入需要使用的其他数据。
在进程执行过程中,操作系统负责具体细节,使每个进程都以为自己拥有整个地址空间的独家访问权。这个幻觉是通过“虚拟内存”实现的。所有进程共享机器的物理内存,当内存使用完时就用磁盘保存数据。在进程运行时,数据在磁盘和内存之间来回移动。内存管理硬件负责把虚拟地址翻译为物理地址,并让一个进程始终运行于系统的真正内存中,应用程序员只看到虚拟地址,并不知道自己的进程在磁盘与内存之间来回切换。
从潜在的可能性上说,与进程有关的所有内存都将被系统所使用,如果该进程可能不会马上运行(可能它的优先级低,也可能是它处于睡眠状态),操作系统可以暂时取回所有分配给它的物理内存资源,将该进程的所有相关信息都备份到磁盘上。
进程只能操作位于物理内存中的页面。当进程引用一个不在物理内存中的页面时,MMU就会产生一个页错误。内存对此事做出响应,并判断该引用是否有效。如果无效,内核向进程发出一个“segmentation violation(段违规)”的信号,内核从磁盘取回该页,换入内存中,一旦页面进入内存,进程便被解锁,可以重新运行--进程本身并不知道它曾经因为页面换入事件等待了一会。
三、内存的使用
对于程序员,我们最重要的是能理解不同进程间私有内存空间的含义。C和C++的编译器把私有内存分为3块:基栈、浮动栈和堆。如下图:
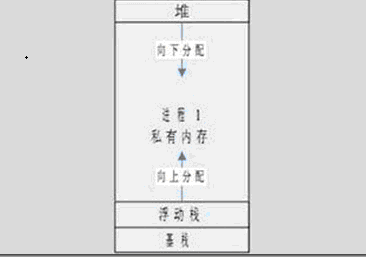

(1)基栈:也叫静态存储区,这是编译器在编译期间就已经固定下来必须要使用的内存,如程序的代码段、静态变量、全局变量、const常量等。
(2)浮动栈:很多书上称为“栈”,就是程序开始运行,随着函数、对象的一段执行,函数内部变量、对象的内部成员变量开始动态占用内存,浮动栈一般都有生命周期,函数结束或者对象析构,其对应的浮动栈空间的就拆除了,这部分内容总是变来变去,内存占用也不是固定,因此叫浮动栈。
(3)堆:C和C++语言都支持动态内存申请,即程序运行期可以自由申请内存,这部分内存就是在堆空间申请的。堆位于2GB的最顶端,自上向下分配,这是避免和浮动栈混到一起,不好管理。我们用到malloc和new都是从堆空间申请的内存,new比malloc多了对象的支持,可以自动调用构造函数。另外,new创建对象,其成员变量位于堆里面。
我们来看一个例子:
- const int n = 100;
- void Func(void)
- {
- char ch = 0;
- char* pBuff = (char*)malloc(10);
- //…
- }
这个函数如果运行,其中n由于是全局静态变量,位于基栈,ch和pBuff这两个函数内部变量,ch位于浮动栈,而pBuff指向的由malloc分配的内存区,则位于堆栈。
在内存理解上,最著名的例子就是线程启动时的参数传递。
函数启动一个线程,很多时候需要向线程传参数,但是线程是异步启动的,即很可能启动函数已经退出了,而线程函数都还没有正式开始运行,因此,绝不能用启动函数的内部变量给线程传参。道理很简单,函数的内部变量在浮动栈,但函数退出时,浮动栈自动拆除,内存空间已经被释放了。当线程启动时,按照给的参数指针去查询变量,实际上是在读一块无效的内存区域,程序会因此而崩溃。
那怎么办呢?我们应该直接用malloc函数给需要传递的参数分配一块内存区域,将指针传入线程,线程收到后使用,最后线程退出时,free释放。
我们来看例子:
- //这个结构体就是参数表
- typedef struct _CListen_ListenAcceptTask_Param_
- {
- Linux_Win_SOCKET m_nSocket;
- //其他参量… …
- }SCListenAcceptTaskParam;
- //习惯性写法,设置结构体后,立即声明结构体的尺寸,为后续malloc提供方便
- const ULONG SCListenAcceptTaskParamSize = sizeof(SCListenAcceptTaskParam);
- //这里接收到连接请求,申请参数区域,将关键信息带入参数区域,帮助后续线程工作。
- bool CListen::ListenTaskCallback(void* pCallParam,int& nStatus)
- {
- //正常的函数逻辑… …
- //假定s是accept到的socket,需要传入后续线程工作
- //在此准备一块参数区域,从远堆上申请
- SCListenAcceptTaskParam* pParam = (SCListenAcceptTaskParam*) malloc(SCListenAcceptTaskParamSize);
- //给参数区域赋值
- pParam->m_nSocket = s;
- //此处启动线程,将pParam传递给线程… …
- //正常的函数逻辑… …
- }
- //这是线程函数,负责处理上文accept到的socket
- bool CListen::ListenAcceptTask(void* pCallParam,int& nStatus)
- {
- //第一句话就是强制指针类型转换,获得外界传入的参数区域
- SCListenAcceptTaskParam* pParam= (SCListenAcceptTaskParam*)pCallParam;
- //正常的函数逻辑… …
- //退出前,必须要做的工作,确保资源不被泄露
- close(pParam->m_nSocket); //关闭socket
- free(pCallParam); // free传入的参数区域
- //… …
- }
四、内存bug
无规则的滥用内存和指针会导致大量的bug,程序员应该对内存的使用保持高度的敏感性和警惕性,谨慎地使用内存资源。
使用内存时最容易出现的bug是:
(1)坏指针值错误:在指针赋值之前就用它来引用内存,或者向库函数传送一个坏指针,第三种可能导致坏指针的原因是对指针进行释放之后再访问它的内容。可以修改free语句,在指针释放之后再将它置为空值。
- free(p);
- p = NULL;
这样,如果在指针释放之后继续使用该指针,至少程序能在终止之前进行信息转储。
(2)改写(overwrite)错误:越过数组边界写入数据,在动态分配的内存两端之外写入数据,或改写一些堆管理数据结构(在动态分配内存之前的区域写入数据就很容易发生这种情况)
- p = malloc(256);
- p[-1] = 0;
- p[256] = 0;
(3)指针释放引起的错误:释放同一个内存块两次,或释放一块未曾使用malloc分配的内存,或释放仍在使用中的内存,或释放一个无效的指针。一个极为常见的与释放内存有关的错误就像下面这样:
- struct node *p, *tart, *temp;
- for(p = start; p ; p = p->next)
- {
- free(p);
- }
上面的代码会在第二次迭代时对已经释放的指针再次进行释放,这样就会导致不可预料的错误。
正确的迭代方法:
- struct node *p, *tart, *temp;
- for(p = start; p ; p = temp)
- {
- temp = p->next;
- free(p);
- }
from:http://www.jizhuomi.com/software/281.html
C++友元类不占用空间
虚拟内存的最大量
Maximum Amount of Virtual Memory
在 32 位版本的 Windows 中,进程最多可以访问 4GB 的虚拟内存。其中,应用程序最多可以访问 2GB。剩余的 2GB 是为操作系统保留的。
In 32-bit versions of Windows, a process has access to at most 4GB of virtual memory. Of this, an application can access at most 2GB. The remaining 2GB is reserved for the operating system.

4GB 限制来自 32 位单词用作内存中的地址,导致最多 4,294,967,296 字节或 4GB。
在 64 位版本的 Windows (x64) 中,我们获得 64 位地址空间, 导致 18,446,744,073,709,551,616 个可能的内存位置,或 16 个 EB(相当于 16,777,216 TB,或 17,179,869,184 GB)。但是,在 64 位 Windows 上运行的应用程序只能访问可用总数的一小部分。每个应用程序可以解决最多 8TB(或 8,192GB,它仍然是 4,096 倍于 32 位应用程序有权访问)。
The 4GB limit comes from the fact that 32-bit words are used as addresses into memory, resulting in a maximum of 4,294,967,296 bytes–or 4GB.
In 64-bit versions of Windows (x64), we get a 64-bit address space, resulting in 18,446,744,073,709,551,616 possible memory locations, or 16 exabytes (equivalent to 16,777,216 terabytes, or 17,179,869,184 GB). An application running on 64-bit Windows, however, only gets access to a tiny fraction of the available total. Each application can address a maximum of 8TB (or 8,192GB, which is still 4,096 times what a 32-bit app has access to).

C语言中的static 详细分析
google了近三页的关于C语言中static的内容,发现可用的信息很少,要么长篇大论不知所云要么在关键之处几个字略过,对于想挖掘底层原理的初学者来说参考性不是很大。所以,我这篇博文博采众家之长,把互联网上的资料整合归类,并亲手编写程序验证之。
C语言代码是以文件为单位来组织的,在一个源程序的所有源文件中,一个外部变量(注意不是局部变量)或者函数只能在一个源程序中定义一次,如果有重复定义的话编译器就会报错。伴随着不同源文件变量和函数之间的相互引用以及相互独立的关系,产生了extern和static关键字。
下面,详细分析一下static关键字在编写程序时有的三大类用法:
一,static全局变量
我们知道,一个进程在内存中的布局如图1所示:

其中.text段保存进程所执行的程序二进制文件,.data段保存进程所有的已初始化的全局变量,.bss段保存进程未初始化的全局变量(其他段中还有很多乱七八糟的段,暂且不表)。在进程的整个生命周期中,.data段和.bss段内的数据时跟整个进程同生共死的,也就是在进程结束之后这些数据才会寿终就寝。
当一个进程的全局变量被声明为static之后,它的中文名叫静态全局变量。静态全局变量和其他的全局变量的存储地点并没有区别,都是在.data段(已初始化)或者.bss段(未初始化)内,但是它只在定义它的源文件内有效,其他源文件无法访问它。所以,普通全局变量穿上static外衣后,它就变成了新娘,已心有所属,只能被定义它的源文件(新郎)中的变量或函数访问。
以下是一些示例程序
file1.h如下:
-
-
-
void printStr();
我们在file1.c中定义一个静态全局变量hello, 供file1.c中的函数printStr访问.
-
-
-
static char* hello = "hello cobing!";
-
-
void printStr()
-
{
-
printf("%sn", hello);
-
}
file2.c是我们的主程序所在文件,file2.c中如果引用hello会编译出错
-
-
-
int main()
-
{
-
printStr();
-
printf("%sn", hello);
-
return 0;
-
}
报错如下:
[liujx@server235 static]$ gcc -Wall file2.c file1.c -o file2
file2.c: In function ‘main’:
file2.c:6: 错误:‘hello’ 未声明 (在此函数内第一次使用)
file2.c:6: 错误:(即使在一个函数内多次出现,每个未声明的标识符在其
file2.c:6: 错误:所在的函数内只报告一次。)
如果我们将file2.c改为下面的形式:
-
-
-
int main()
-
{
-
printStr();
-
return 0;
-
}
则会顺利编译连接。
运行程序后的结果如下:
[liujx@server235 static]$ gcc -Wall file2.c file1.c -o file2
[liujx@server235 static]$ ./file2
hello cobing!
上面的例子中,file1.c中的hello就是一个静态全局变量,它可以被同一文件中的printStr调用,但是不能被不同源文件中的file2.c调用。
二,static局部变量
普通的局部变量在栈空间上分配,这个局部变量所在的函数被多次调用时,每次调用这个局部变量在栈上的位置都不一定相同。局部变量也可以在堆上动态分配,但是记得使用完这个堆空间后要释放之。
static局部变量中文名叫静态局部变量。它与普通的局部变量比起来有如下几个区别:
1)位置:静态局部变量被编译器放在全局存储区.data(注意:不在.bss段内,原因见3)),所以它虽然是局部的,但是在程序的整个生命周期中存在。
2)访问权限:静态局部变量只能被其作用域内的变量或函数访问。也就是说虽然它会在程序的整个生命周期中存在,由于它是static的,它不能被其他的函数和源文件访问。
3)值:静态局部变量如果没有被用户初始化,则会被编译器自动赋值为0,以后每次调用静态局部变量的时候都用上次调用后的值。这个比较好理解,每次函数调用静态局部变量的时候都修改它然后离开,下次读的时候从全局存储区读出的静态局部变量就是上次修改后的值。
以下是一些示例程序:
file1.h的内容和上例中的相同,file1.c的内容如下:
-
-
-
void printStr()
-
{
-
int normal = 0;
-
static int stat = 0; //this is a static local var
-
printf("normal = %d ---- stat = %dn",normal, stat);
-
normal++;
-
stat++;
-
}
为了便于比较,我定义了两个变量:普通局部变量normal和静态局部变量stat,它们都被赋予初值0;
file2.c中调用file1.h:
-
-
-
int main()
-
{
-
printStr();
-
printStr();
-
printStr();
-
printStr();
-
printf("call stat in main: %dn",stat);
-
return 0;
-
}
-
这个调用会报错,因为file2.c中引用了file1.c中的静态局部变量stat,如下:
[liujx@server235 static]$ gcc -Wall file2.c file1.c -o file2
file2.c: In function ‘main’:
file2.c:9: 错误:‘stat’ 未声明 (在此函数内第一次使用)
file2.c:9: 错误:(即使在一个函数内多次出现,每个未声明的标识符在其
file2.c:9: 错误:所在的函数内只报告一次。)
编译器说stat未声明,这是因为它看不到file1.c中的stat,下面注掉这一行:
-
-
-
int main()
-
{
-
printStr();
-
printStr();
-
printStr();
-
printStr();
-
// printf("call stat in main: %dn",stat);
-
return 0;
-
}
[liujx@server235 static]$ gcc -Wall file2.c file1.c -o file2
[liujx@server235 static]$ ./file2
normal = 0 ---- stat = 0
normal = 0 ---- stat = 1
normal = 0 ---- stat = 2
normal = 0 ---- stat = 3
运行如上所示。可以看出,函数每次被调用,普通局部变量都是重新分配,而静态局部变量保持上次调用的值不变。
需要注意的是由于static局部变量的这种特性,使得含静态局部变量的函数变得不可重入,即每次调用可能会产生不同的结果。这在多线程编程时可能会成为一种隐患。需要多加注意。
三,static函数
相信大家还记得C++面向对象编程中的private函数,私有函数只有该类的成员变量或成员函数可以访问。在C语言中,也有“private函数”,它就是接下来要说的static函数,完成面向对象编程中private函数的功能。
当你的程序中有很多个源文件的时候,你肯定会让某个源文件只提供一些外界需要的接口,其他的函数可能是为了实现这些接口而编写,这些其他的函数你可能并不希望被外界(非本源文件)所看到,这时候就可以用static修饰这些“其他的函数”。
所以static函数的作用域是本源文件,把它想象为面向对象中的private函数就可以了。
下面是一些示例:
file1.h如下:
-
-
-
static int called();
-
void printStr();
file1.c如下:
-
-
-
static int called()
-
{
-
return 6;
-
}
-
void printStr()
-
{
-
int returnVal;
-
returnVal = called();
-
printf("returnVal=%dn",returnVal);
-
}
file2.c中调用file1.h中声明的两个函数,此处我们故意调用called():
-
-
-
int main()
-
{
-
int val;
-
val = called();
-
printStr();
-
return 0;
-
}
编译时会报错:
[liujx@server235 static]$ gcc -Wall file2.c file1.c -o file2
file1.h:3: 警告:‘called’ 使用过但从未定义
/tmp/ccyLuBZU.o: In function `main':
file2.c:(.text+0x12): undefined reference to `called'
collect2: ld 返回 1
因为引用了file1.h中的static函数,所以file2.c中提示找不到这个函数:undefined reference to 'called'
下面修改file2.c:
-
-
-
int main()
-
{
-
printStr();
-
return 0;
-
}
编译运行:
[liujx@server235 static]$ gcc -Wall file2.c file1.c -o file2
[liujx@server235 static]$ ./file2
returnVal=6
static函数可以很好地解决不同原文件中函数同名的问题,因为一个源文件对于其他源文件中的static函数是不可见的。
TLB原理
TLB是translation lookaside buffer的简称。首先,我们知道MMU的作用是把虚拟地址转换成物理地址。虚拟地址和物理地址的映射关系存储在页表中,而现在页表又是分级的。64位系统一般都是3~5级。常见的配置是4级页表,就以4级页表为例说明。分别是PGD、PUD、PMD、PTE四级页表。在硬件上会有一个叫做页表基地址寄存器,它存储PGD页表的首地址。MMU就是根据页表基地址寄存器从PGD页表一路查到PTE,最终找到物理地址(PTE页表中存储物理地址)。这就像在地图上显示你的家在哪一样,我为了找到你家的地址,先确定你是中国,再确定你是某个省,继续往下某个市,最后找到你家是一样的原理。一级一级找下去。这个过程你也看到了,非常繁琐。如果第一次查到你家的具体位置,我如果记下来你的姓名和你家的地址。下次查找时,是不是只需要跟我说你的姓名是什么,我就直接能够告诉你地址,而不需要一级一级查找。四级页表查找过程需要四次内存访问。延时可想而知,非常影响性能。页表查找过程的示例如下图所示。以后有机会详细展开,这里了解下即可。
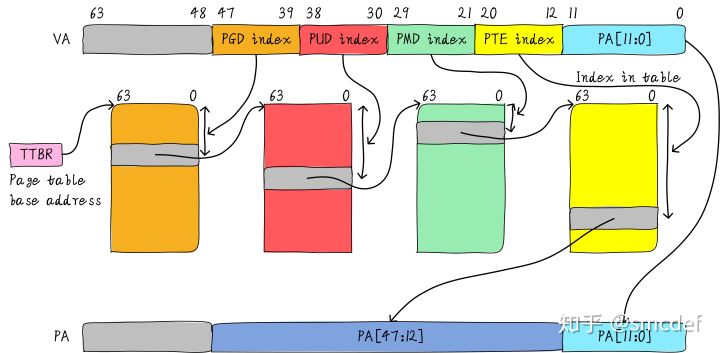 page table walk
page table walk
TLB的本质是什么
TLB其实就是一块高速缓存。数据cache缓存地址(虚拟地址或者物理地址)和数据。TLB缓存虚拟地址和其映射的物理地址。TLB根据虚拟地址查找cache,它没得选,只能根据虚拟地址查找。所以TLB是一个虚拟高速缓存。硬件存在TLB后,虚拟地址到物理地址的转换过程发生了变化。虚拟地址首先发往TLB确认是否命中cache,如果cache hit直接可以得到物理地址。否则,一级一级查找页表获取物理地址。并将虚拟地址和物理地址的映射关系缓存到TLB中。既然TLB是虚拟高速缓存(VIVT),是否存在别名和歧义问题呢?如果存在,软件和硬件是如何配合解决这些问题呢?
TLB的特殊
虚拟地址映射物理地址的最小单位是4KB。所以TLB其实不需要存储虚拟地址和物理地址的低12位(因为低12位是一样的,根本没必要存储)。另外,我们如果命中cache,肯定是一次性从cache中拿出整个数据。所以虚拟地址不需要offset域。index域是否需要呢?这取决于cache的组织形式。如果是全相连高速缓存。那么就不需要index。如果使用多路组相连高速缓存,依然需要index。下图就是一个四路组相连TLB的例子。现如今64位CPU寻址范围并没有扩大到64位。64位地址空间很大,现如今还用不到那么大。因此硬件为了设计简单或者解决成本,实际虚拟地址位数只使用了一部分。这里以48位地址总线为了例说明。
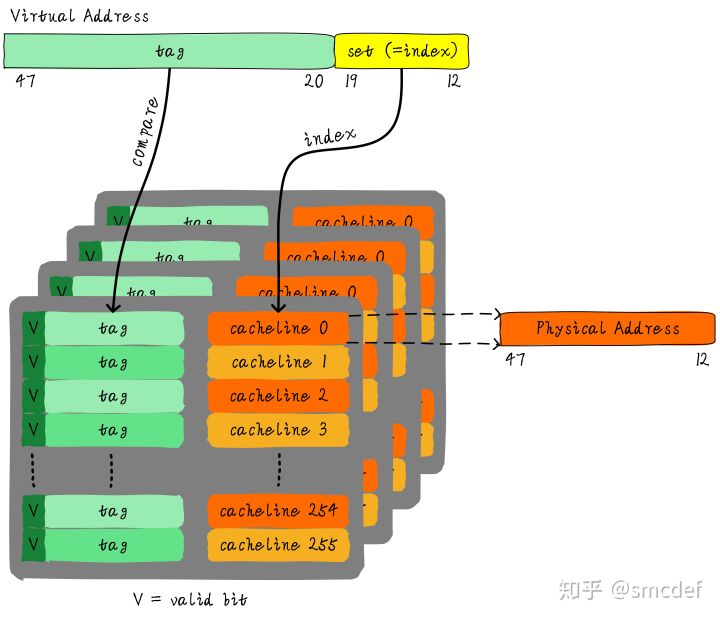
TLB的别名问题
我先来思考第一个问题,别名是否存在。我们知道PIPT的数据cache不存在别名问题。物理地址是唯一的,一个物理地址一定对应一个数据。但是不同的物理地址可能存储相同的数据。也就是说,物理地址对应数据是一对一关系,反过来是多对一关系。由于TLB的特殊性,存储的是虚拟地址和物理地址的对应关系。因此,对于单个进程来说,同一时间一个虚拟地址对应一个物理地址,一个物理地址可以被多个虚拟地址映射。将PIPT数据cache类比TLB,我们可以知道TLB不存在别名问题。而VIVT Cache存在别名问题,原因是VA需要转换成PA,PA里面才存储着数据。中间多经传一手,所以引入了些问题。
TLB的歧义问题
我们知道不同的进程之间看到的虚拟地址范围是一样的,所以多个进程下,不同进程的相同的虚拟地址可以映射不同的物理地址。这就会造成歧义问题。例如,进程A将地址0x2000映射物理地址0x4000。进程B将地址0x2000映射物理地址0x5000。当进程A执行的时候将0x2000对应0x4000的映射关系缓存到TLB中。当切换B进程的时候,B进程访问0x2000的数据,会由于命中TLB从物理地址0x4000取数据。这就造成了歧义。如何消除这种歧义,我们可以借鉴VIVT数据cache的处理方式,在进程切换时将整个TLB无效。切换后的进程都不会命中TLB,但是会导致性能损失。
如何尽可能的避免flush TLB
首先需要说明的是,这里的flush理解成使无效的意思。我们知道进程切换的时候,为了避免歧义,我们需要主动flush整个TLB。如果我们能够区分不同的进程的TLB表项就可以避免flush TLB。我们知道Linux如何区分不同的进程?每个进程拥有一个独一无二的进程ID。如果TLB在判断是否命中的时候,除了比较tag以外,再额外比较进程ID该多好呢!这样就可以区分不同进程的TLB表项。进程A和B虽然虚拟地址一样,但是进程ID不一样,自然就不会发生进程B命中进程A的TLB表项。所以,TLB添加一项ASID(Address Space ID)的匹配。ASID就类似进程ID一样,用来区分不同进程的TLB表项。这样在进程切换的时候就不需要flush TLB。但是仍然需要软件管理和分配ASID。
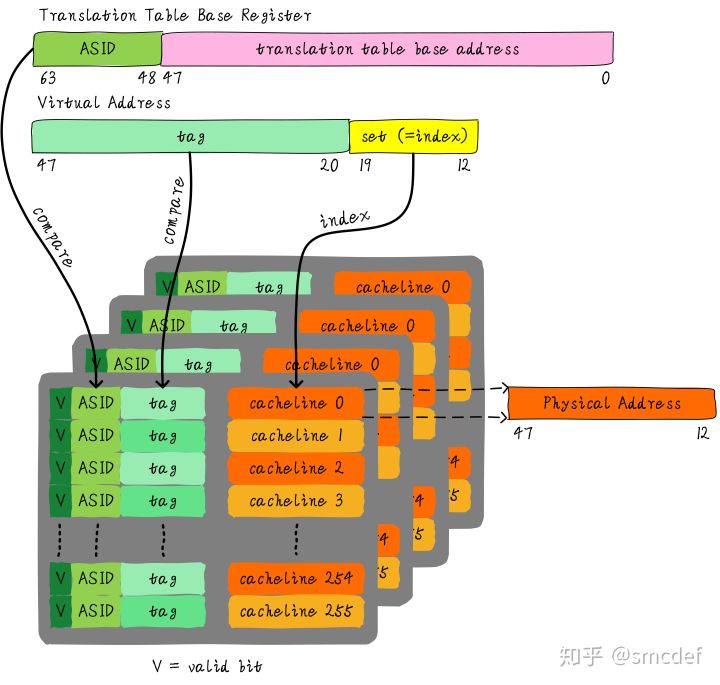
如何管理ASID
ASID和进程ID肯定是不一样的,别混淆二者。进程ID取值范围很大。但是ASID一般是8或16 bit。所以只能区分256或65536个进程。我们的例子就以8位ASID说明。所以我们不可能将进程ID和ASID一一对应,我们必须为每个进程分配一个ASID,进程ID和每个进程的ASID一般是不相等的。每创建一个新进程,就为之分配一个新的ASID。当ASID分配完后,flush所有TLB,重新分配ASID。所以,如果想完全避免flush TLB的话,理想情况下,运行的进程数目必须小于等于256。然而事实并非如此,因此管理ASID上需要软硬结合。 Linux kernel为了管理每个进程会有个task_struct结构体,我们可以把分配给当前进程的ASID存储在这里。页表基地址寄存器有空闲位也可以用来存储ASID。当进程切换时,可以将页表基地址和ASID(可以从task_struct获得)共同存储在页表基地址寄存器中。当查找TLB时,硬件可以对比tag以及ASID是否相等(对比页表基地址寄存器存储的ASID和TLB表项存储的ASID)。如果都相等,代表TLB hit。否则TLB miss。当TLB miss时,需要多级遍历页表,查找物理地址。然后缓存到TLB中,同时缓存当前的ASID。
更上一层楼
我们知道内核空间和用户空间是分开的,并且内核空间是所有进程共享。既然内核空间是共享的,进程A切换进程B的时候,如果进程B访问的地址位于内核空间,完全可以使用进程A缓存的TLB。但是现在由于ASID不一样,导致TLB miss。我们针对内核空间这种全局共享的映射关系称之为global映射。针对每个进程的映射称之为non-global映射。所以,我们在最后一级页表中引入一个bit(non-global (nG) bit)代表是不是global映射。当虚拟地址映射物理地址关系缓存到TLB时,将nG bit也存储下来。当判断是否命中TLB时,当比较tag相等时,再判断是不是global映射,如果是的话,直接判断TLB hit,无需比较ASID。当不是global映射时,最后比较ASID判断是否TLB hit。
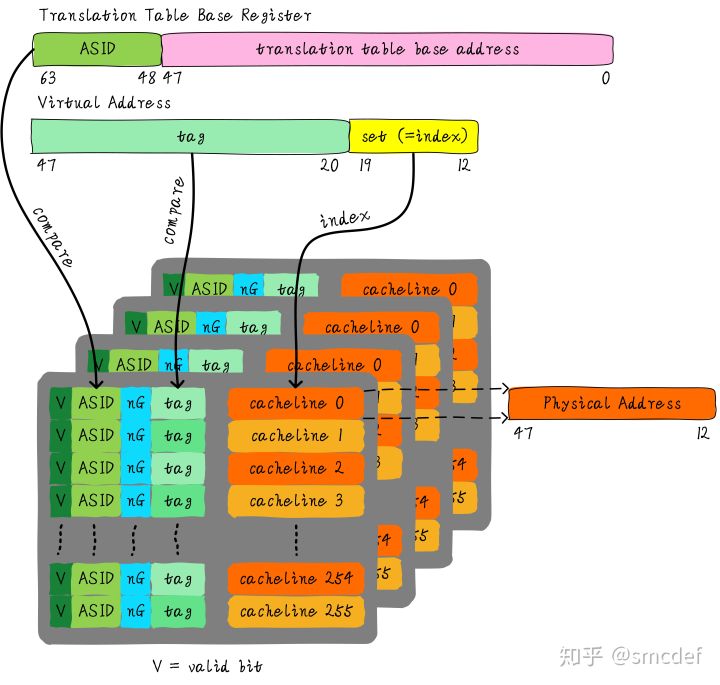
什么时候应该flush TLB
我们再来最后的总结,什么时候应该flush TLB。
- 当ASID分配完的时候,需要flush全部TLB。ASID的管理可以使用bitmap管理,flush TLB后clear整个bitmap。
- 当我们建立页表映射的时候,就需要flush虚拟地址对应的TLB表项。第一印象可能是修改页表映射的时候才需要flush TLB,但是实际情况是只要建立映射就需要flush TLB。原因是,建立映射时你并不知道之前是否存在映射。例如,建立虚拟地址A到物理地址B的映射,我们并不知道之前是否存在虚拟地址A到物理地址C的映射情况。所以就统一在建立映射关系的时候flush TLB。
原文链接: https://www.cnblogs.com/Chary/p/13606078.html
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/202256
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!