
在游戏的编写中,不可避免的出现很多应用数据结构的地方,有些简单的游戏,只是由几个数据结构的组合,所以说,数据结构在游戏编程中扮演着很重要的角色。
本文主要讲述数据结构在游戏中的应用,其中包括对链表、顺序表、栈、队列、二叉树及图的介绍。读者在阅读本文以前,应对数据结构有所了解,并且熟悉C/C++语言的各种功用。好了,现在我们由链表开始吧!
1、链表
在这一节中,我们将通过一个类似雷电的飞机射击游戏来讲解链表在游戏中的应用。在飞机游戏中,链表主要应用在发弹模块上。首先,飞机的子弹是要频繁的出现,消除,其个数也是难以预料的。链表主要的优点就是可以方便的进行插入,删除操作。我们便将链表这一数据结构引入其中。首先,分析下面的源代码,在其中我们定义了坐标结构和子弹链表。
struct CPOINT
{
int x;// X轴坐标
int y;// Y轴坐标
};
struct BULLET
{
struct BULLEnext;// 指向下一个子弹
CPOINT bulletpos;// 子弹的坐标
int m_ispeed;// 子弹的速度
};
接下来的代码清单是飞机类中关于子弹的定义:
class CMYPLANE
{
public:
void AddBullet(struct BULLET);// 加入子弹的函数,每隔一定时间加弹
void RefreshBullet();// 刷新子弹
privated:
struct BULLET st_llMyBullet;// 声明飞机的子弹链表
};
在void AddBullet(struct BULLET)中,我们要做的操作只是将一个结点插入链表中,并且每隔一段时间加入,就会产生连续发弹的效果。
这是加弹函数主要的源代码:
void AddBullet(struct BULLET)
{
struct BULLETst_llNew,st_llTemp;// 定义临时链表
st_llNew=_StrucHead;// 链表头(已初始化)
st_llNew->(BULLET st_llMyBullet)malloc(sizeof(st_llMyBullet));// 分配内存
st_llTemp= =_NewBullet;// 临时存值
st_llNew->next=st_llTemp->next; st_llTemp->next=st_llNew;
}
函数Void RefreshBullet()中,我们只要将链表历遍一次就行,将子弹的各种数据更新,其中主要的源代码如下:
while(st_llMyBullet->next!=NULL)
{
// 查找
st_llMyBullet->bulletpos.x-=m_ispeed;// 更新子弹数据
………
st_llMyBullet=st_llMyBullet->next;// 查找运算
}
经过上面的分析,在游戏中,链表主要应用在有大规模删除,添加的应用上。不过,它也有相应的缺点,就是查询是顺序查找,比较耗费时间,并且存储密度较小,对空间的需求较大。
如果通过对游戏数据的一些控制,限定大规模的添加,也就是确定了内存需求的上限,可以应用顺序表来代替链表,在某些情况下,顺序表可以弥补链表时间性能上的损失。当然,应用链表,顺序表还是主要依靠当时的具体情况。那么,现在,进入我们的下一节,游戏中应用最广的数据结构 — 顺序表。
2、顺序表
本节中,我们主要投入到RPG地图的建设中,听起来很吓人,但是在RPG地图系统中(特指砖块地图系统),却主要使用数据结构中最简单的成员 — 顺序表。
我们规定一个最简单的砖块地图系统,视角为俯视90度,并由许多个顺序连接的图块拼成,早期RPG的地图系统大概就是这样。我们这样定义每个图块:
struct TILE// 定义图块结构
{
int m_iAcesse;// 纪录此图块是否可以通过
……// 其中有每个图块的图片指针等纪录
};
当m_iAcesse=0,表示此图块不可通过,为1表示能通过。
我们生成如下地图:
TILE TheMapTile[10][5];
并且我们在其中添入此图块是否可以通过,可用循环将数值加入其中,进行地图初始化。
如图表示:
|
|||
| 图1 | |||
从上图看到这个地图用顺序表表示非常直接,当我们控制人物在其中走动时,把人物将要走到的下一个图块进行判断,看其是否能通过。比如,当人物要走到(1,0)这个图块,我们用如下代码判断这个图块是否能通过:
int IsAcesse(x,y)
{
return TheMapTile[x,y].m_iAcesse;// 返回图块是否通过的值
}
上述只是简单的地图例子,通过顺序表,我们可以表示更复杂的砖块地图,并且,现在流行的整幅地图中也要用到大量的顺序表,在整幅中进行分块。
好了,现在我们进入下一节:
3、栈和队列
栈和队列是两种特殊的线性结构,在游戏当中,一般应用在脚本引擎,操作界面,数据判定当中。在这一节中,主要通过一个简单的脚本引擎函数来介绍栈,队列和栈的用法很相似,便不再举例。
我们在设置脚本文件的时候,通常会规定一些基本语法,这就需要一个解读语法的编译程序。这里列出的是一个语法检查函数,主要功能是检查“()”是否配对。实现思想:我们规定在脚本语句中可以使用“()”嵌套,那么,便有如下的规律,左括号和右括号配对一定是先有左括号,后有右括号,并且,在嵌套使用中,左括号允许单个或连续出现,并与将要出现的有括号配对销解,左括号在等待右括号出现的过程中可以暂时保存起来。当右括号出现后,找不到左括号,则发生不配对现象。从程序实现角度讲,左括号连续出现,则后出现的左括号应与最先到来的右括号配对销解。左括号的这种保存和与右括号的配对销解的过程和栈中后进先出原则是一致的。我们可以将读到的左括号压入设定的栈中,当读到右括号时就和栈中的左括号销解,如果在栈顶弹不出左括号,则表示配对出错,或者,当括号串读完,栈中仍有左括号存在,也表示配对出错。
大致思想便是这样,请看代码片断:
struct// 定义栈结构
{
int m_iData[100];// 数据段
int m_iTop;// 通常规定栈底位置在向量低端
}SeqStack;
int Check(SeqStack stack)// 语法检查函数
{
char sz_ch;
int boolean; Push(stack,'# ');// 压栈,#为判断数据
sz_ch=getchar();// 取值
boolean=1;
while(sz_ch!='n'&&boolean)
{
if(sz_ch= ='(')
Push(stack,ch);
if(sz_ch= =')')
if(gettop(stack)= ='#')// 读栈顶
boolean=0;
else
Pop(stack);// 出栈
sz_ch=getchar();
}
if(gettop(stack)!='#') boolean=0;
if(boolean) cout<<"right";// 输出判断信息
else
cout<<"error";
这里只是介绍脚本的读取,以后,我们在图的介绍中,会对脚本结构进行深入的研究。
总之,凡在游戏中出现先进后出(栈),先进先出(队列)的情况,就可以运用这两种数据结构,例如,《帝国时代》中地表中间的过渡带。
4、二叉树*
树应用及其广泛,二叉树是树中的一个重要类型。在这里,我们主要研究二叉树的一种应用方式:判定树。其主要应用在描述分类过程和处理判定优化等方面上。
在人工智能中,通常有很多分类判断。现在有这样一个例子:设主角的生命值d,在省略其他条件后,有这样的条件判定:当怪物碰到主角后,怪物的反应遵从下规则:
|  |
| 表1 |
根据条件,我们可以用如下普通算法来判定怪物的反应:
if(d<100) state=嘲笑,单挑;
else if(d<200) state=单挑;
else if(d<300) state=嗜血魔法;
else if(d<400) state=呼唤同伴;
else state=逃跑;
上面的算法适用大多数情况,但其时间性能不高,我们可以通过判定树来提高其时间性能。首先,分析主角生命值通常的特点,即预测出每种条件占总条件的百分比,将这些比值作为权值来构造最优二叉树(哈夫曼树),作为判定树来设定算法。假设这些百分比为:
| 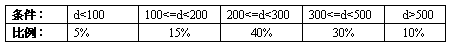 |
| 表2 |
构造好的哈夫曼树为:
| 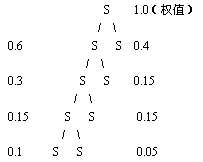 |
| 图2 |
对应算法如下:
if(d>=200)&&(d<300) state=嗜血魔法;
else if(d>=300)&&(d<500) state=呼唤同伴;
else if(d>=100)&&(d<200) state=单挑;
else if(d<100) state=嘲笑,单挑;
else state=逃跑;
通过计算,两种算法的效率大约是2:3,很明显,改进的算法在时间性能上提高不少。
一般,在即时战略游戏中,对此类判定算法会有较高的时间性能要求,大家可以对二叉树进行更深入的研究。现在,我们进入本文的最后一节:图的介绍,终于快要完事了。
5、图
在游戏中,大多数应用图的地方是路径搜索,即关于A算法的讨论。由于介绍A算法及路径搜索的文章很多,这里介绍图的另一种应用:在情节脚本中,描述各个情节之间的关系。
在一个游戏中,可能包含很多分支情节,在这些分支情节之间,会存在着一定的先决条件约束,即有些分支情节必须在其他分支情节完成后方可开始发展,而有些分支情节没有这样的约束。
通过分析,我们可以用有向图中AOV网(Activity On Vertex Network)来描述这些分支情节之间的先后关系。好了,现在假如我们手头有这样的情节:
| **情节编号** | **情节** | **先决条件** |
| C1 | 遭遇强盗 | 无 |
| C2 | 受伤 | C1 |
| C3 | 买药 | C2 |
| C4 | 看医生 | C2 |
| C5 | 治愈 | C3,C4 |
注意:在AOV网中,不应该出现有向环路,否则,顶点的先后关系就会进入死循环。即情节将不能正确发展。我们可以采取拓扑派序来检测图中是否存在环路,拓扑排序在一般介绍数据结构的书中,都有介绍,这里便不再叙述。
那么以上情节用图的形式表现为(此图为有向图,先后关系在上面表格显示):
|  |
| 图3 |
现在我们用邻接矩阵表示此有向图,请看下面代码片断:
struct MGRAPH
{
int Vexs[MaxVex];// 顶点信息
int Arcs[MaxLen][MaxLen];// 邻接矩阵
……
};
顶点信息都存储在情节文件中。
将给出的情节表示成邻接矩阵:
|
|||
| 图4 | |||
我们规定,各个情节之间有先后关系,但没有被玩家发展的,用1表示。当情节被发展的话,就用2表示,比如,我们已经发展了遭遇强盗的情节,那么,C1与C2顶点之间的关系就可以用2表示,注意,并不表示C2已经发展,只是表示C2可以被发展了。
请看下面的代码:
class CRelation
{
public:
CRelation(char filename);// 构造函数,将情节信息文件读入到缓存中
void SetRelation(int ActionRelation);// 设定此情节已经发展
BOOL SearchRelation(int ActionRelation);// 寻找此情节是否已发展
BOOL SaveBuf(charfilename);// 保存缓存到文件中
……
privated:
charbuf;// 邻接矩阵的内存缓冲
……
};
在这里,我们将表示情节先后关系的邻接矩阵放到缓冲内,通过接口函数进行情节关系的修改,在BOOL SearchRelation(int ActionRelation)函数中,我们可以利用广度优先搜索方法进行搜索,介绍这方面的书籍很多,代码也很长,在这里我就不再举例了。
我们也可以用邻接链表来表示这个图,不过,用链表表示会占用更多的内存,邻接链表主要的优点是表示动态的图,在这里并不适合。
另外,图的另一个应用是在寻路上,著名的A算法就是以此数据结构为基础,人工智能,也需要它的基础。好了,本节结束。
原文链接: https://www.cnblogs.com/maxice/archive/2010/02/24/1672424.html
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍
原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/8367
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!