
Introduction
C++ is a strongly typed compiler language. Though not as strongly typed as ADA, a C++ compiler will complain if you try to assign an object of one type to an object of another type (if there is no acceptable conversion). Obviously, this requires that the compiler knows all available types. More specifically, all classes must be known at compile-time1. But sometimes, it would be quite handy to add new classes at runtime. And in some application domains, this is absolutely necessary.
A simple story
Let's look at a simple example: Susan, the manager of a local bookstore, wants to expand into the Internet. So she asks you to write a simple program for an Internet bookshop. No problem for you. Part of your solution will probably look like the class model in Fig. 1.
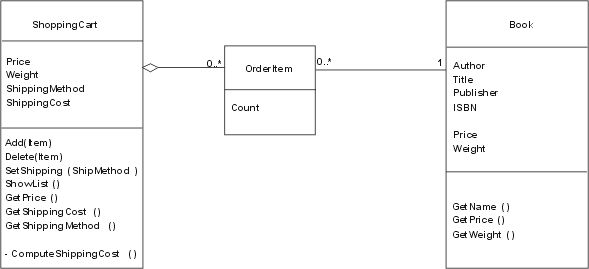

Fig. 1: Simple Shop Model
The implementation of this in C++ is straightforward. Here is the Book class:
 Book Class
Book Class
class Book
{
public:
Book(const string & author_,
const string & title_,
const string & publisher_,
double price_,
double weight_);
string getName()
{
string name;
name = author + ": " + title;
return name.substr(0, 40);
}
double getPrice();
double getWeight();
private:
string author, title, publisher;
double price, weight;
};
Your solution works, Susan is happy, and all is fine for a while...
But changes come on the Web in Internet time: the bookshop is a success and Susan decides to sell CDs as well. So you have to change your program. With object orientation, you can do this quite easily and your modified class model will look like Fig. 2.
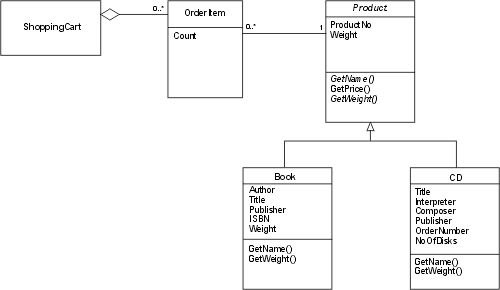
Fig. 2: Product Model
As you probably guessed, this was only the beginning. Some time later, Susan wants to sell Pop music accessories like T-shirts, posters, etc. as well.
Now it is clear that it is not acceptable to modify the source code of your program every time a new product category is introduced. So you start to think about the actual requirements, and find that you need to provide different interfaces for your Product class (Fig. 3): A simple interface for ShoppingCart providing getName(), getPrice(), and getWeight(). This is what you already have. Then you need a different interface for a general search machine2, which must provide information like:
- what is the actual class of the object
- what attributes does that class have
- what are the actual values of these attributes for the object.
This is a classic reflection interface that gives you information about the properties of classes and objects.
But you also need a third interface for product maintenance that allows you to define new product classes, specify the attributes for them, create instances of these classes, and set the attribute values of these instances. Such an interface is called a "Meta-Object Protocol (MOP)" and thoroughly discussed in [1]. The reflection protocol is a subset of such a MOP.
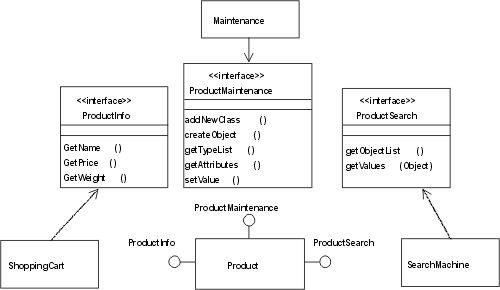
Fig. 3: A Better Model
Meta Classes for C++
What is the meaning of "Meta-Object Protocol"? Well, meta information is information about something else seen from a level beyond -- a meta level. So, information about the attribute values of an object, say someBook.author, is information on the object level. But information about the properties of the object itself, about its attributes, its structure, etc. is meta information.
In C++, this information is captured in the class definition for the object, so the class is a meta-object. And in C++, you have all the functionality of a MOP at class level -- which is at development time. But that level is not available at runtime: You cannot manipulate classes like objects, you cannot add new classes at runtime. The idea of a MOP is to collapse the meta-level (classes) and the object level (objects); i.e. make the class definitions normal objects and the object properties are normal attribute values of the class definitions that can be manipulated at runtime.
While languages like CLOS or Smalltalk provide this combined level directly, C++ as strongly typed compiler language has no such features. So, what can you do about it? The typical solution is to provide a MOP yourself, as proposed e.g. in [2] or [3].
MOP Overview
For simplicity, we ignore methods for now, so our MOP must provide:
- definition of new classes
- adding attributes to classes
- querying attributes of classes
- creating objects
- querying the class of an object
- setting attribute values of an object
- querying attribute values of an object
- deleting objects
If you use an old rule of OO design, you take all the nouns of the above requirements and make classes out of them. When you think about the "attributes" and "values" you have to decide whether they are typed. As the underlying language C++ is typed this should be mirrored in your design.
Another question is about inheritance support. For our example with the Internet shop and a product hierarchy this would probably quite useful. So, a first class model is shown in Fig 4.

Fig. 4: MOP Class Model
Type
While it is useful to go top-down for a general overview, it's easier to start with the simple basic things for the details. So we'll first look at Type.
The main purpose of Type is to distinguish different kind of Attributes. For this, a simple enum would suffice. But the idea of types is to have different kind of Values for different Types, so the Type should create new Values. So we put the enum inside the Type class, provide the newValue() method, and get the interface shown in Fig. 4.
Now for implementation. Though we don't look closer at Value for now, if we have different kind of values we probably need some base class for them. Let's call it "BaseValue", and newValue() can just return a pointer to BaseValue.
Now we know what to create, but how? While there are several patterns to implement polymorphic creation [4], the simplest one for our purpose is probably the Prototype, which can be easily implemented with a simple static vector3.
Now we have everything to implement the entire class:
Type Class
class Type
{
public:
enum TypeT {stringT, intT, doubleT, unknownT};
explicit Type(TypeT typeId_) : typeId(typeId_) {}
BaseValue * newValue() const
{
return prototypes[typeId]->clone();
}
TypeT getType() const
{
return typeId;
}
static void init();
{
prototypes[stringT] = new Value<string>("");
prototypes[intT] = new Value<int>(0);
prototypes[doubleT] = new Value<double>(0);
}
private:
TypeT typeId;
static vector<BaseValue *> prototypes;
};
vector<BaseValue *> Type::prototypes(Type::unknownT);
Attribute
As we have decided to create new Values through Type, Attribute contains only a name and type, so here is its implementation:
Attribute Class
class Attribute
{
public:
Attribute(const string & name_, Type::TypeT typeId)
: name(name_), type_(typeId)
{}
const string & getName() const
{
return name;
}
Type getType() const
{
return type_;
}
private:
string name;
Type type_;
};
Classes
We can now finish the class (meta-) level of our model by looking at Class itself. As multiple inheritance is probably not an issue for our purposes, we have just one pointer to a base class (which can be 0). The more important question is the attribute list: Should it hold only the attributes defined for this class or should it include all inherited attributes? While for the actual object value access a complete list is more useful (and much faster), for class maintenance it might be important to know which attribute was defined in which class. So we just keep both. For the complete list, the order might be significant: should the own attributes come first or the inherited ones? In most illustrations the inherited attributes come first, so we keep this order as well.
What happens if the name of an attribute is the same as the name of an inherited attribute? As C++ allows it, we can allow it as well (saving us some extra effort to check this), but in this case we must guarantee that on lookup of an attribute by name we get the most derived attribute. So, findAttribute() must do a reverse search. What shall we return from findAttribute()? The STL way would be to return an iterator, but for applications with GUIs (to create new objects and assign values to its attributes based on selection lists) an index-based access to the attributes will be more appropriate. So findAttribute() returns an index and getAttribute() takes an index and returns an Attribute. So the Attribute lists need to be an indexed containers, so we choose vectors for them.
A major purpose of Class is to create Objects from it, so it has a method newObject() which returns a pointer to an Object. Do we need to keep a repository with references to all created objects? For a full reflection interface we should do this. But for actual applications this is nearly never useful, as objects of the same class are created for completely different purposes. But do we need the repository for internal use? It depends on what we want to do with objects after they were created. This leads directly to another important decision: What do we do with already existing objects if we add a new attribute to a class? One option is to add this attribute to all existing objects and assign it a default value. The other option is to leave these existing objects and add the new attribute only to new objects. This leads to differently structured objects of the same class at the same time, and then we must add some version information to the objects. But there is a third option: To forbid the modification of a class definition once an instance of that class was created. This is the easiest option, so we adopt it for our MOP and add a flag definitionFix. With that flag, we can skip the object repository.
A last design question is when to add the attributes: At creation time of a class definition (through the constructor) or later (with a member function)? For different applications both options might be useful, so we'll provide two constructors and addAttribute().
Now you can implement this4:
ClassDef
class ClassDef
{ //typedefs Container, Iterator for attributes
public:
ClassDef(ClassDef const * base, const string & name_)
: baseClass(base), name(name_),
definitionFix(false)
{
baseInit();
effectiveAttributes.insert(effectiveAttributes.end(),
ownAttributes.begin(),
ownAttributes.end());
}
template <typename iterator>
ClassDef(ClassDef const * base, const string & name_,
iterator attribBegin, iterator attribEnd)
: baseClass(base), name(name_),
ownAttributes(attribBegin, attribEnd),
definitionFix(false)
{
baseInit();
effectiveAttributes.insert(effectiveAttributes.end(),
ownAttributes.begin(),
ownAttributes.end());
}
string getName() const;
Object * newObject() const
{
definitionFix = true;
return new Object(this);
}
AttrIterator attribBegin() const;
AttrIterator attribEnd() const;
Attribute const & getAttribute(size_t idx) const;
void addAttribute(const Attribute &);
size_t getAttributeCount() const;
size_t findAttribute(string const & name) const
{
// this does a reverse search to find the most derived
AttributeContainer::const_reverse_iterator i;
for (i = effectiveAttributes.rbegin();
i != effectiveAttributes.rend();
++i)
{
if (i->getName() == name)
{
return distance(i, effectiveAttributes.rend()) - 1;
}
}
return getAttributeCount();
}
private:
void baseInit()
{
if (baseClass)
{
baseClass->definitionFix = true;
copy(baseClass->attribBegin(), baseClass->attribEnd(),
back_inserter<AttributeContainer>(effectiveAttributes));
}
}
ClassDef const * const baseClass;
string name;
AttributeContainer ownAttributes, effectiveAttributes;
mutable bool definitionFix;
};
Values

Fig. 5: Value Model
Before we can design Object, we have to think about Value. We need a common interface to manage them, which we already called BaseValue. But what interface do we need? The whole idea of Value is to store values, so we need a set() function. What parameter? The only thing we have is BaseValue, so that's the parameter type. Pass by value, by reference, or by pointer? Definitely not by value, as BaseValue is only an interface. On the other hand, what you pass is a value, so the parameter passing should be by value to let you pass temporaries. So one option would be to pass by const reference. But though this helps for the problem at hand, it doesn't cure the fundamental problem: you should have a value, but all you have is a polymorphic interface. The real solution here is the pimpl idiom, also known as Cheshire Cat, Envelope/Letter, or more generally Handle/Body. So we add a handle class, name it Value, and look at it later again. For now we're still at BaseValue.
We now have set(Value), so what about get()? The return type of get() would be Value, and the implementation would look like:
Value BaseValue::get()
{
return *this; // calls Value(BaseValue const &)
}
But that we can do directly, so get() doesn't make much sense.
What other BaseValue functions do we need? Values must be copied, so we add clone().
That's all what we really need from a value, but we add asString() for convenience5.
BaseValue Class
class BaseValue
{
public:
virtual ~BaseValue(){}
virtual BaseValue * clone() const = 0;
virtual string asString() const = 0;
// fromString()
virtual void set(Value const & v) = 0;
// no get()!
private:
// Type info
};
RealValue
Now, as we have the interface, what about the implementation? We need values for int, double, string, .... And an int value must hold an int, a double value a double, etc. This looks like an opportunity for a template. So, let's define RealValue<T>, derive it from BaseValue, implement the inherited interface, and we're nearly done. But as RealValue<T> is just a wrapper around T with some additional functionality, but essentially still a T, we should provide conversion in both directions, by providing a converting constructor and a conversion operator
RealValue Class
template <typename PlainT>
class RealValue : public BaseValue
{
public:
RealValue(PlainT v)
: val(v) {}
RealValue * clone() const
{
return new RealValue(*this);
}
string asString() const
{
ostringstream os;
os << val;
return os.str();
}
operator PlainT() const // conversion to plain type
{
return val;
}
RealValue<PlainT>::set(Value const & v)
{
val = v.get<PlainT>();
}
private:
PlainT val;
};
A note about RealValue: As we have conversion in both directions, we can use RealValue<T> like T:
RealValue<int> i = 1;
int j = i;
RealValue<double> d = i + 5.2 / (i*2);
cout << d << endl;
Nearly: the following doesn't work:
RealValue<string> name, author = "Bjarne", title = "The C++ PL";
name = author + ": " + title;
cout << name << endl;
The reason is that the compiler only applies one user-defined conversion, but for string literals, you need two: from char const * to string, and from string to RealValue<string>. If you want to work with RealValue<string> outside the MOP, you should define a specialization:
RealValue
template <>
class RealValue<string> : public BaseValue, public string
{
public:
RealValue(string const & s) : string(s) {}
RealValue(char const * s) : string(s) {}
RealValue() {}
RealValue * clone() const
{
return new RealValue(*this);
}
string asString() const
{
return static_cast<string>(*this);
}
// no operator string(), conversion to base automatically
void set(Value const & v)
{
string::operator=(v.get<string>());
}
};
Note: Actually, its not really clean to derive RealValue<string> from std::string, but as long as you don't delete a RealValue<string> through a pointer to string, it will work.
Value handle
Now back to the handle class Value. As a handle class, it contains its body and cares for it. Its main job is to adopt/create and to delete its body. And it mirrors the interface of the body and forwards all messages. But it should also be a real value class, thus providing default and copy constructor and assignment. But how to implement the default constructor? As we don't know what type to create, we must create an empty handle without a body and check before forwarding if we actually have something to forward to. The assignment is essentially the set(), so we skip the set().
Now let's come back to the get(). Of course, to return a Value or BaseValue doesn't make sense. But what about returning the RealValue or even the wrapped underlying value? That would be really useful, but for that we have to tell get() what we want as return type. So get() becomes a member template and so can return whatever is inside the RealValue<>.
Value handle
class Value // Value handle
{
public:
Value(BaseValue const & bv)
: v(bv.clone())
{}
Value(Value const & rhs)
: v(rhs.v ? rhs.v->clone() : 0)
{}
explicit Value(BaseValue * bv = 0)
: v(bv)
{}
~Value()
{
delete v;
}
Value & operator=(const Value & rhs)
{
// this is not a typical pimpl assignment, but a set()
if (v)
{
if (rhs.v)
{ // fine, all v's exist
v->set(rhs);
}
else
{ // the other v doesn't exist, so we must delete our own :-(
BaseValue * old = v;
v = 0;
delete old;
}
}
else
{ // we don't have a v, so just copy the other
v = (rhs.v ? rhs.v->clone() : 0);
}
return *this;
}
template <typename PlainT>
PlainT get() const
{
if (v)
{
RealValue<PlainT> const & rv
= dynamic_cast<RealValue<PlainT> const &>(*v);
return rv; // uses conversion operator
}
else
{
return PlainT();
}
}
std::string asString() const
{
if (v)
{
return v->asString();
}
else
{
return string();
}
}
private:
BaseValue * v;
};
Object
Finally we come to Object. Now, as we have everything else, an Object is mainly a container for its attribute values. To ease implementation, we will structurally mirror the attribute container in the class definition, so we use a vector. As we have so much effort invested in our Value handle, it would make sense to store that in the vector. But for future extensions it will be easier to have the BaseValue pointers directly available.
The constructor will create the values through the types of the attributes, so the only constructor takes a ClassDef*.
To set and get the values for the attributes, we provide two options: to specify the attribute by name and also by index.
For reflection purposes (as well as for internal implementation) we need a pointer to the class definition, but then we have it all:
Object Class
class Object
{
public:
explicit Object(ClassDef const * class_)
: myClass(class_), values(class_->getAttributeCount())
{
buildValueList();
}
ClassDef const & instanceOf() const
{
return *myClass;
}
Value getValue(size_t attribIdx) const
{
return *values[attribIdx]; // calls Value(BaseValue &)
}
Value getValue(string const & attribName) const
{
size_t idx = instanceOf()->findAttribute(attribName);
// should check for not found
return getValue(idx);
}
void setValue(size_t idx, Value const & v)
{
values[idx]->set(v);
}
void setValue(string const & attribName, Value const &v)
{
size_t idx = instanceOf()->findAttribute(attribName);
// should check for not found
setValue(idx, v);
}
private:
typedef vector<BaseValue *> ValueContainer;
void buildValueList()
{
ClassDef::AttrIterator a;
ValueContainer::iterator i = values.begin();
for (a = instanceOf()->attribBegin();
a != instanceOf()->attribEnd();
++a, ++i)
{
*i = a->getType().newValue();
}
}
ClassDef const * const myClass;
ValueContainer values;
};
Now the MOP is complete. Let's use it:
Creating the Product class:
ClassDef * product
= new ClassDef(0, // no base class for Product
"Product"); // name of class
Adding attributes:
product->addAttribute(Attribute("Product Number", Type::intT));
product->addAttribute(Attribute("Name", Type::stringT));
product->addAttribute(Attribute("Price", Type::doubleT));
product->addAttribute(Attribute("Weight", Type::doubleT));
Creating the Bookclass with an attribute list:
list<Attribute> attrL;
attrL.push_back(Attribute("Author", Type::stringT));
attrL.push_back(Attribute("Title", Type::stringT));
attrL.push_back(Attribute("ISBN", Type::intT));
ClassDef * book
= new ClassDef(product, // base class
"Book",
attrL.begin(), attrL.end());
Creating an object:
Object * bscpp(book->newObject());
Setting the values for the objects:
Set an int value by index (don't forget that index 0 is ProductNo):
bscpp->setValue(0, RealValue<int>(12345));
Same for a string value:
bscpp->setValue(4, RealValue<string>("Bjarne Stroustrup"));
Better way: set value by name this gives the most derived attribute:
bscpp->setValue("Title",
RealValue<string>("The C++ Programming Language"));
bscpp->setValue("Weight", Value<double>(370));
Getting the values:
Display a book:
ClassDef::AttrIterator a;
size_t idx;
for (a = book->attribBegin(), idx = 0;
a != book->attribEnd();
++a, ++idx)
{
cout << a->getName() << ": "
<< bscpp->getValue(idx).asString() << endl;
}
and we get:
Product Number: 12345
Name:
Price:
Weight: 370
Author: Bjarne Stroustrup
Title: The C++ Programming Language
ISBN:
So, our MOP is complete. For our sample application, you have to add a class repository, some nice GUI to define classes and objects, creating the index for the search machine, provide an interface for ShoppingCart, but then you're done, and Susan is happy as she now can create her own new product categories at runtime.
原文链接: https://www.cnblogs.com/emotion164/archive/2012/03/05/2380293.html
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/43291
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!