
typedef struct _hdf HDF;
struct _hdf
{
int link;
int alloc_value;
char *name;
int name_len;
char *value;
struct _attr *attr;
struct _hdf *top;
struct _hdf *next;
struct _hdf *child;
/* the following fields are used to implement a cache */
struct _hdf *last_hp;
struct _hdf *last_hs;
/* the following HASH is used when we reach more than FORCE_HASH_AT
* elements */
NE_HASH *hash;
/* When using the HASH, we need to know where to append new children */
struct _hdf *last_child;
/* Should only be set on the head node, used to override the default file
* load method */
void *fileload_ctx;
HDFFILELOAD fileload;
};
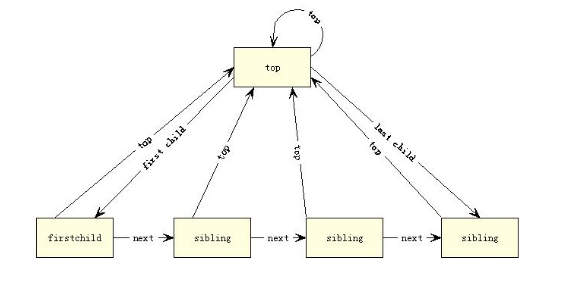
核心数据结构如图一所示:

图(一)
hdf对于数据的存储并不是采用AVL(一种平衡二叉树,linux-kernel mememory-manage一直在采用),或者R-B树
(c++中的map在采用),这两种平衡树的优点是对于查找的时间复杂度是O(logn)也就是说和树的高度成正比.
也没有采用B+树(DB中建立数据索引时会使用,但是并不是二叉的,一个节点可以有尽可能多的子节点,
但是同样要控制树的高度,因为查找的时间复杂度依旧是O(logn),一般来说都控制在3层之内)
而是采用了上面的结构,普通的树结构。
每个节点在处理和其它节点的关系时有主要的4部分
HDF.top-->指向最顶端的节点(注意不一定是父节点)
HDF.child-->指向第一个孩子节点
HDF.next-->指向他兄弟节点
HDF.last_child-->指向他的最后一个孩子节点,
一般来说用于在其右侧插入新的节点。
这样的处理我们就可以给定任何一个节点遍历他的所有孩子节点,
遍历同一层次的所有兄弟节点,甚至遍历整个树结构(通过最顶层节点).
在处理完一个树内部元素的关系之后,我们要说明一下他是如何处理数据的.
数据的储存采用最通用的方式{name,value}方式
HDF.name指明了一个元素的名字名字
HDF.name_len指明名字的长度,并且进行查找时可以快速证明两个名字不同.
HDF.value指明相应的值.
HDF.alloc_value指明在释放整个HDF的时候相应的value是否需要显示释放
现在我们看看在此数据结构上的操作集吧
static NEOERR* _set_value (HDF *hdf, const char *name, const char *value,
int dup, int wf, int link, HDF_ATTR *attr,
HDF **set_node)
在插入的时候我们会根据给定的hdf进行插入操作,首先查找相应的名字是否存在
如果存在就更新相应的值,如果不存在就分配一个HDF节点,然后把名字和值写入
并且把相应HDF节点和整个树关联起来.至此整个过程基本上就完成了,很简单不是吗?
相应的查找或者更新过程类似.
前面我们说了面对平衡二叉树和B+树,所以我们的查找,更新,删除操作没有任何优势
我们没有采用是有原因的(我们又不是傻子,不然怎么会连google和yahoo都在用呢?),
凡事都一样的,没有什么是通用的,只有适合的才是最好的.
我想第一个提出"cache"的人一定是位天才,事实上他确实是...
那么HDF为了提高性能也不会例外,cache主要采用以下两种方式:
1, HDF.last_hp用于保存上次查找时找到的HDF节点
HDF.last_hs用于保存上次找到的HDF节点的左兄弟节点.
两者皆可能为空,如果没有找到的话.
这种方式命中效率根据相应的应用类型而不同,
例如linux-kernel mm的命中率据说可以达到38%
2,建立hash索引.
根据上面的描述,我们知道HDF树在每一层上有可能有非常非常多的子节点
在这一层次上他就是一个链表,我们知道链表的查找时间复杂度是O(n),是线性增长的.
为了提高效率我们采取如下措施:
在插入一个节点的时候我们会记录相应层的节点数,当他达到一个阈值的时候
我们就会为这层根据每个节点的名字建立一个哈希表来加速查找.
具体的哈希算法是采用CRC32(以太网校验也是采用这种方式),
所以如果给定两个长度相同的名字进行哈希散列,
那么他们被散列到一个同一值的概率是1/2^32,每个bucket链表的长度还取决于分配的
hash表的大小。所以一般来说这已经非常的好了(如果没有记错的话,曾经在boost中见过CRC32的应用)。
好了,自此我们的cache机制已经建立起来了。
现在如果进行插入的话,我们首先会根据HDF.last_hs和HDF.last_hp
来定位,如果可以找到,我们就可以对相应节点进行相应的操作.
如果不明中的话,我们回查看这层是否已经建立了hash表,如果有就进行
hash匹配,如果没有建立(说明这层节点还很少,那么遍历相应链表的开销也不会很大)
那么我们就进行遍历,对于需要增加新节点操作来说我们会判断是否需要建立hash表.
数据结构描述为:
typedef struct _HASH
{
UINT32 size;
UINT32 num;
NE_HASHNODE **nodes;
NE_HASH_FUNC hash_func;
NE_COMP_FUNC comp_func;
} NE_HASH;
typedef struct _NE_HASHNODE
{
void *key;
void *value;
UINT32 hashv;
struct _NE_HASHNODE *next;
} NE_HASHNODE;
HDF.attr是根据需要可以给相应的name增加一些属性而设定的.
这个很简单,看看结构描述就ok了
typedef struct _attr
{
char *key;
char *value;
struct _attr *next;
} HDF_ATTR;
HDF.link表示这个HDF名字对应的值并不是真真正意义上的值
而是某个名字.或者说这个HDF名字是某个名字的别名,真正的名字是他的值.
对于这种情况当我找到某个名字的值时,如果发现相应的HDF.link
为真的话,我们会从树的顶端根据相应的值从新搜索,知道找到相应的
节点并且起link非真为止.为了原谅用户的失误,我们知道这样可能会
生成一个闭圈,也就是说如果遇到这种情况我们就会陷入等同于while(1);的情况.
为了避免这种情况的发生,我们会在遍历的时候添加一个计数器,
当到100(例如)的时候,会退出查找并且宣告此次查找失败。
HDF.fileload_ctx用于读取数据(默认是普通文件),支持序列化,存储的数据可以来自于
普通文件,二进制文件,zip文件,内存,等等。
在整个引擎中一种很好的体验是很多东西都是可配置的,采用的机制是注册和回调。
给了用户更多的选择:)
原文链接: https://www.cnblogs.com/wbinblog/archive/2012/02/29/2372693.html
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/42966
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!