
本来周末想搞一下scapy呢,一个python写的交互式数据包编辑注入框架,功能异常强大。然而由于python水平太水,对库的掌握程度完全达不到信手拈来的水平,再加上前些天pending的关于OpenVPN的事情,还有一系列关于虚拟网卡的事情,使我注意到了一个很好用的packetdrill,可以完成本应该由scapy完成的事,恰巧这个东西跟我最近的工作也有关系,就抛弃scapy了,稍微研究了一下它的基本框架,写下本文。
packetdrill的框架概览
喜欢packetdrill是因为它让我想起了2010年5月份刚开始接触OpenVPN的时候,那时我的预研进度一度阻塞在一个叫做TUN虚拟网卡的驱动上,后来当我玩转它以后,发现TUN几乎可以做所有的事情,每当我面临一些诸如数据包注入,劫取,重放等需求的时候,只要我想到了TUN,它就一定可以帮我实现理想。当然,后来我在OpenVPN收获颇丰,要不是编程水平不佳,我几乎重构了它,也得意于我对TUN设备的深度喜爱。现在,packetdrill也是使用了TUN,因此我知道,我可以快速使用它做比我想做的更多的事情了。TUN有这么神奇?是的!
TUN的神奇之处就在于它非常简单,简单到就像0和1那样,不过它做的事情可不简单,本质上说,TUN的作用在于“导包”,它可以模拟一条网线,将数据包输出到一个字符设备,至于字符设备被谁读取以及数据包作何处理,就完全依赖用户态程序编写者的想象力了。packetdrill正是利用了这一点,才让它可以成为一个自封闭的协议测试系统,完全不需要外部的支持就可以测试整个协议栈,如果你是一个网络协议的初学者,利用packetdrill也可以让你快速理解网络协议的动态行为,除此之外,它本身包含了很多的test case,几乎涵盖了你想要的所有,如果某个点没有被涵盖,你可以快速依葫芦画瓢写一个脚本,然后,就可以跑起来了。
和当初OpenVPN的预研阶段一样,关于packetdrill的框架,我还是以一幅图开始吧,这个图让我想起2010年低做关于OpenVPN培训的时候画的那个图,可是去年,我把那个OpenVPN的框图完善了。所以本文中这个packetdrill的框图也只是个开始,也可能包括一些疏漏,后续会不断勘误,完善之。图示如下:
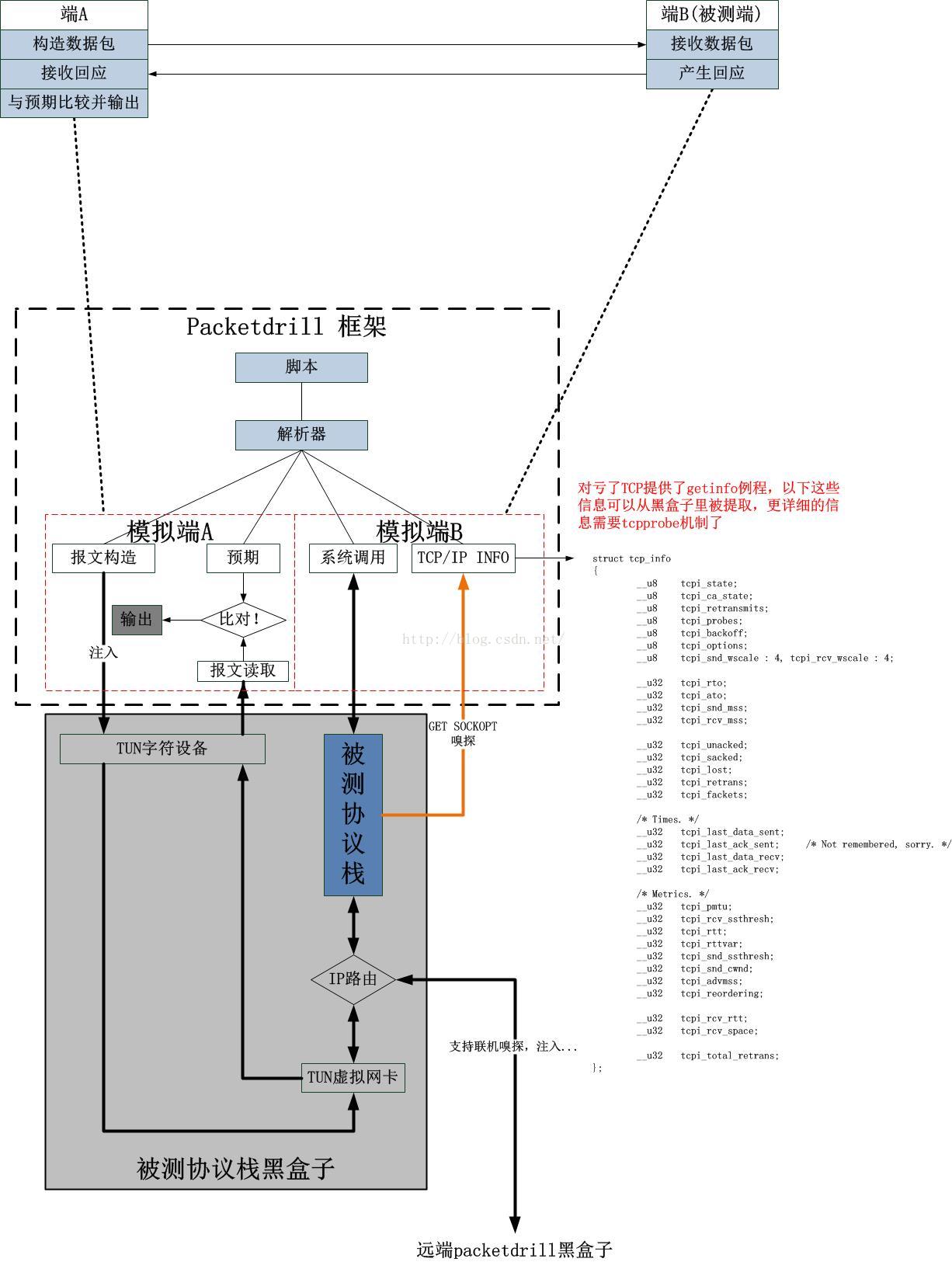

你看,scapy做不到这些,完全做不到,scapy必须依赖另一台机器,或者在本机启用另外一些程序。但是从另一个角度,scapy+TUN+prog+...岂不是完爆packetdrill吗?并且后者完全遵循UNIX的KISS小程序组合的原则,而packetdrill看起来有点像一个Windows风格的“大程序”!然而,以实用主义角度看问题,你觉得哪个更好用呢?哪个更方便呢?要知道,我只是想知道我的协议是否按照预期工作,我的目标并不是想炫耀我懂得那么多Linux工具以及精通其每一个的用法,所以用packetdrill我花最多10分钟下载源码并编译,然后花5分钟跑一遍test case,最后我几乎可以瞬间写一个我自己想要的case,整个过程也就不到半个小时,如果用scapy组合呢?...如果旁边外行的人看着我,我起码还是会炫下去,显得自己很强,要是就我自己一人,我折腾这些就像个傻逼。事实如此,我昨天真的想用scapy组合的,结果两个多小时没有搞定,期间没有一个人欣赏观摩,用packetdrill,除了遇到了一个编译时-lpthread的问题外,一切超级顺利。最终,我决定,舍scapy而取packetdrill者也!昨晚用它搞定了我的新版OpenVPN协议(还记得我去年那鬼魅的残缺吗?有了packetdrill,我得到了一个OpenVPN在内核中的一个稳定版本,而且支持快速重连,这个请看我本文的最后),也算是值得欣慰。
packetdrill哪哪都好,缺点在于出了问题不好分析。
万一输出不符合预期怎么办?以TCP为例,如果你不懂TCP的每一个细节,那么在你认为要重传,然而对端没有重传的时候,你该怎么办?此时你能得到的信息只是TCP_INFO这种信息,你得到的就是一些值,这些值是你显式调用getsockopt的时候得到的,你无法知道某个值是如何演化的,比如拥塞窗口如何随着协议栈函数的执行而变化。我以一例以叙之。
一个TCP快速重传的细节
在《通过packetdrill构造的包序列理解TCP快速重传机制》中,我列举了两个脚本,这里讲述后一个脚本的一个细节,我再次把后一个脚本贴如下:
// 建立连接
0 socket(..., SOCK_STREAM, IPPROTO_TCP) = 3
+0 setsockopt(3, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0
+0 bind(3, ..., ...) = 0
+0 listen(3, 1) = 0
// 完成握手
+0 < S 0:0(0) win 65535 <mss 1000,sackOK,nop,nop,nop,wscale 7>
+0 > S. 0:0(0) ack 1 <...>
+.1 < . 1:1(0) ack 1 win 65535
+0 accept(3, ..., ...) = 4
// 发送1个段,不会诱发拥塞窗口增加
+0 write(4, ..., 1000) = 1000
+.1 < . 1:1(0) ack 1001 win 65535
// 再发送1个段,拥塞窗口还是初始值10!
+0 write(4, ..., 1000) = 1000
+.1 < . 1:1(0) ack 2001 win 65535
// .....
+0 write(4, ..., 1000) = 1000
+.1 < . 1:1(0) ack 3001 win 65535
// 不管怎么发,只要是每次发送不超过init_cwnd-reordering,拥塞窗口就不会增加,详见上述的tcp_is_cwnd_limited函数
+0 write(4, ..., 1000) = 1000
+.1 < . 1:1(0) ack 4001 win 65535
// 多发一点,结果呢?自己用tcpprobe确认吧
+0 write(4, ..., 6000) = 6000
+.1 < . 1:1(0) ack 10001 win 65535
// 好吧,我们发送10个段,可以用tcpprobe确认,在收到ACK后拥塞窗口会增加1,这正是慢启动的效果!
+0 write(4, ..., 10000) = 10000
+.1 < . 1:1(0) ack 20001 win 65535
// 该步入正题了。为了触发快速重传,我们发送足够多的数据,一下子发送8个段吧,注意,此时的拥塞窗口为11!
+0 write(4, ..., 8000) = 8000
// 在这里,可以用以下的Assert来确认:
0.0 %{
assert tcpi_reordering == 3
assert tcpi_cwnd == 11
}%
// 以下为收到的SACK序列。由于我假设你已经通过上面那个简单的packetdrill脚本理解了SACK和FACK的区别,因此这里我们默认开启FACK!
// sack 1的效果:确认了27001-28001,此处距离ACK字段20001为8个段,超过了reordering 3,会立即触发重传。
+.1 < . 1:1(0) ack 20001 win 257 <sack 27001:28001,nop,nop> // ----(sack 1)
+0 < . 1:1(0) ack 20001 win 257 <sack 22001:23001 27001:28001,nop,nop> // ----(sack 2)
+0 < . 1:1(0) ack 20001 win 257 <sack 23001:24001 22001:23001 27001:28001,nop,nop> // ----(sack 3)
+0 < . 1:1(0) ack 20001 win 257 <sack 24001:25001 23001:24001 22001:23001 27001:28001,nop,nop> // ----(sack 4)
// 收到了28001的ACK,注意,此时的reordering已经被更新为6了,另外,这个ACK也会尝试触发reordering的更新,但是并不成功,为什么呢?详情见下面的分析。
+.1 < . 1:1(0) ack 28001 win 65535
// 由于经历了上述的快速重传/快速恢复,拥塞窗口已经下降到了5,为了确认reordering已经更新,我们需要将拥塞窗口增加到10或者11
+0 write(4, ..., 5000) = 5000
+.1 < . 1:1(0) ack 33001 win 65535
// 由于此时拥塞窗口的值为5,我们连续写入几个等于拥塞窗口大小的数据,诱发拥塞窗口增加到10.
+0 write(4, ..., 5000) = 5000
+.1 < . 1:1(0) ack 38001 win 65535
+0 write(4, ..., 5000) = 5000
+.1 < . 1:1(0) ack 43001 win 65535
+0 write(4, ..., 5000) = 5000
+.1 < . 1:1(0) ack 48001 win 65535
+0 write(4, ..., 5000) = 5000
+.1 < . 1:1(0) ack 53001 win 65535
+0 write(4, ..., 5000) = 5000
+.1 < . 1:1(0) ack 58001 win 65535
+0 write(4, ..., 5000) = 5000
+.1 < . 1:1(0) ack 63001 win 65535
// 好吧!此时重复上面发生SACK的序列,写入8个段,我们来看看同样的SACK序列还会不会诱发快速重传!
+0 write(4, ..., 8000) = 8000
// 依然可以通过python来确认reordering此时已经不再是3了
// 我们构造同上面sack 1/2/3/4一样的SACK序列,然而等待我们的不是重传被触发,而是...
// 什么?没有触发重传?这不可能吧!你看,70001-71001这个段距离63001为8个段,而此时reordering被更新为6,8>6,依然符合触发条件啊,为什么没有触发呢?
// 答案在于,在于8>6触发快速重传有个前提,那就是开启FACK,然而在reordering被更新的时候,已经禁用了FACK,此后就是要数SACK的段数而不是数最高被SACK的段值了,以下4个SACK只是选择确认了4个段,而4<6,不会触发快速重传。
+.1 < . 1:1(0) ack 63001 win 257 <sack 70001:71001,nop,nop>
+0 < . 1:1(0) ack 63001 win 257 <sack 65001:66001 70001:71001,nop,nop>
+0 < . 1:1(0) ack 63001 win 257 <sack 67001:68001 65001:66001 70001:71001,nop,nop>
+0 < . 1:1(0) ack 63001 win 257 <sack 68001:69001 67001:68001 65001:66001 70001:71001,nop,nop>
// 这里,这里到底会不会触发超时重传呢?取决于packetdrill注入下面这个ACK的时机
// 如果没有发生超时重传,下面这个ACK将会再次把reordering从6更新到8
+.1 < . 1:1(0) ack 71001 win 65535
//从这里往后,属于神的世界...且听我下面的论述以提出问题。在收到第一个SACK的时候,FACK的值是8,reordering的值是3,标记为LOST的段数为FACK-reordering=5个。在收到SACK之前,拥塞窗口的值为11,内核版本为2.6.32,因此如果真的是用2.6.32内核的话,我可以确定降窗算法不是PRR而是Rate halving。因此我知道,虽然此时拥塞窗口的大小为11,但是最终的拥塞窗口取的是:
tp->snd_cwnd = min(tp->snd_cwnd, tcp_packets_in_flight(tp) + 1);来吧,我们依次来算,此时tp->snd_cwnd的值为11,问题是tcp_packets_in_flight是多少?
static inline unsigned int tcp_left_out(const struct tcp_sock *tp)
{
return tp->sacked_out + tp->lost_out;
}
static inline unsigned int tcp_packets_in_flight(const struct tcp_sock *tp)
{
return tp->packets_out - tcp_left_out(tp) + tp->retrans_out;
}此时:
tp->packets_out:等于8
tp->sacked_out:等于1(记得吗?段70001-71001)
tp->lost_out:等于5(它等于FACK-reordering)
tp->retrans_out:等于0(因为还没有任何重传)
in_flight:8-(1+5)+0=2个段
所以根据2.6.32代码的tcp_cwnd_down降窗函数,在降窗完成后,拥塞窗口的大小为in_flight+1=3个段。现在你应该质疑为什么第一次收到70001-71001的SACK后,重传了2个段而不是1个段!!我们看tcp_xmit_retransmit_queue函数:
tcp_for_write_queue_from(skb, sk) {
...
if (tcp_packets_in_flight(tp) >= tp->snd_cwnd)
return;
transmit_skb(skb);
tp->retrans_out++;
}第一次进入tcp_for_write_queue_from时,tp->snd_cwnd为3,不满足退出条件,故重传1个数据段,待重传后tp->retrans_out递增1,in_flight递增1,cwnd维持不变,因此第二次经过循环逻辑时会break退出,然而抓包发现确实重传了2个数据段而不是1个!这是怎么回事?!答案在于一个内核patch或者说一个实现细节!其实这里重传多少并不是重要的问题,重要的问题是,我们已经得到了足够的通知,知道了丢包或者乱序,仅此足矣。至于说要不要重传,重传多少,这就是各种TCP实现的区别,我个人是很鄙视这种区别的,也不感兴趣,因此,不予讨论。为了解除经理以及质疑者的武装,我把事实简单说一下。RedHat系统使用的并不一定是社区的发布内核,RH特别喜欢移植上游的patch到使用低版本内核的long term发行版,也就是说,当你看到社区的2.6.32内核的降窗算法是由tcp_cwnd_down实现的时候,RH已经移植了PRR算法!
其实,我TMD的也是个爱较真儿的,这么大热的天,老婆带着孩子去游泳了,我跟个傻逼一样在家里下载RH的kernel patch!无奈深圳这边的网速真无法跟上海比,CTMD!好吧,我们继续讨论为什么重传的是2个段而不是1个段!
如果使用tcp_cwnd_down来实现降窗,最后的一个平滑操作是:
tp->snd_cwnd = min(tp->snd_cwnd, tcp_packets_in_flight(tp) + 1);这是为了不往早已无能为力的网络上再添堵,也就是说,当你确定in_flight肯定比当前Rate Halving降窗操作之后的窗口值小的时候,拥塞窗口的值一定是in_flight加1!这也就是传说中的数据包守恒,大多数情况都是如此,Rate Halving(它是一个本地作用)的效用远远不比in_flight表征的实际网络情况(这是一个综合作用)。因此你会发现,大多数情况下,在TCP快速恢复阶段,都是一个一个段重传的。然而RH移植了上游patch后,它使用的是PRR降窗算法,下面我们来算一下PRR算法下,应该重传几个段。
我们先看符合本例的精简版PRR的代码:
static void tcp_cwnd_reduction(struct sock *sk, int newly_acked_sacked, int fast_rexmit)
{
struct tcp_sock *tp = tcp_sk(sk);
int sndcnt = 0;
int delta = tp->snd_ssthresh - tcp_packets_in_flight(tp);
tp->prr_delivered += newly_acked_sacked;
if (tcp_packets_in_flight(tp) > tp->snd_ssthresh) {
... // in_flight此为2,而ssthresh的值却是5(我使用了Reno,其实Cubic也一样,11*0.7=?)
} else {
sndcnt = min(delta, max(tp->prr_delivered - tp->prr_out, newly_acked_sacked) + 1);
}
tp->snd_cwnd = tcp_packets_in_flight(tp) + sndcnt;
}我们看下newly_acked_sacked,prr_out,prr_delivered,delta分别是多少?
newly_acked_sacked:等于1。被SACK了1个段。
prr_out:等于0,自发现ACK为dubious,还没有传输一个段。
prr_delivered:等于1。
delta:等于3。很简单的(5-2)。
我们算一下sndcnt吧,min(delta,max(prr_delivered-prr_out, newly_acked_sacked)+1),它等于min(3,max(1-0,1)+1)=2!最终的结果呢?拥塞窗口的值为in_flight+sndcnt!即in_flight+2!也就是说,可以额外多发送2个段!这就是我们抓包的结果。
额外的,我们可以看到PRR优于Rate Halving的地方,它可以动态算出来适合发多少段,而不仅仅是遵循数据守恒以及Rate Halving之间的较保守者。
我们接着进行下去,进入重传逻辑的时候,in_flight为2,而拥塞窗口为4,当它发送了1个段后,in_flight为3,而拥塞窗口依然是4,然后可以再发送一个段,in_flight为4,拥塞窗口为4,退出!因此只是发送了两个段!而不是发送了标记为LOST的5个段!
是吗?是的!我对这种玩意儿不感兴趣,太TMD无聊!人活着,难道不该为一些有意思的事情付出多点时间吗?我不明白为何大多数人总是会对显而易见的事实产生质疑,但这种质疑浪费的不只是我的生命,更多的是经理的!
好吧,这个周末太TMD假,我为了我的OpenVPN,扯出了packetdrill,进而又是TCP,...本想写一篇软文来催泪的,看来也算了吧,不管怎样,我只要一想起OpenVPN,思绪就会延展两年半...
附:为什么我又重启了将OpenVPN放入内核的“妄想”?
我去年离开了OpenVPN项目,后续的一切关于OpenVPN的问题我也不再跟进,然而这并不代表我对其不闻不问,我对OpenVPN项目还是感情很深的。当我得知我的多线程OpenVPN会有各种各样的问题时,我想到了他们会用多进程来解决,用不用nf_conntrack我不知道,起码多线程是无力解bug了,本来OpenVPN代码就够乱,经我多线程化,乱上加乱!
然而如果使用多进程,将会有一个很猛的特性无法使用,这就是快速重连。参见我之前的文章,你会知道,快速重连机制不再使用协议栈可识别的五元组来识别客户端,而是使用一个应用层的Session ID来识别客户端,如果使用多进程的话,就需要在多个进程之间同步这些Session ID信息,而OpenVPN的代码框架让这一切变得很难!其实,理论上,共享内存可以快速搞定这个问题,但是OpenVPN的混乱垃圾代码不适合你去用共享内存,当前我听到的一个最大快人心的消息就是,我的前同事和朋友已经决定用Nigix重构OpenVPN了,据我所知,进度还挺顺利,V0.1已经可以跑起来了,这是一件多么令人欣慰的事情,爆炸。
但是对于我而言,我还有另一套方案,其实我在去年已经步入了解决这个问题的边缘,那就是内核态的OpenVPN协议的实现!为什么?因为内核态可以访问所有的内存,内存完全共享,我只要实现一张hash表就好了吧,是的,而且我搞定了。虽然在纯技术方面,我觉得自己的做法还挺好,但是很难实施,因为很多的系统,并不允许你去任意动内核的。所以说,请不要联系我索要代码,我依然只是自己玩玩。
如果你因为不精通一系列的框架而不能写应用程序乱搞,那么你就必须有能力在内核里面胡来!
原文链接: https://blog.csdn.net/dog250/article/details/51934338
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍;
也有高质量的技术群,里面有嵌入式、搜广推等BAT大佬

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/407994
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!