
在Wireshark的tcptrace图中看清TCP拥塞控制算法的细节(CUBIC/BBR算法为例)》,收到一封邮件,说我文中的图示画错了。
确实,关于CUBIC,我只说了缠绕,关于BBR我只说了顺延,并没有说具体如何,甚至我没有提一嘴关于重传的细节,更别说在图示里展现了。这是我的错。话不能说一半,因此才写下本文,把另一半也写出来。
炒股的人喜欢看K线,并且很有用,所以我决定把TCP的“K线”描述透彻。这是因为TCP与股票几乎是一致的。它们都是不可预测的!任何声称可以预测它们的,都是傻逼!不管是股票还是TCP拥塞控制,都大量使用了移动指数平均,很多人认为移动指数平均旨在预测走势,但这样的想法错了!移动指数平均从来不是为了预测的,它这是帮助你:
1.是否要做出反应;
2.如果需要做出反应,如何第一时间做出反应!
------------------------------------------------------------------
------------------------------------------------------------------
现在开始,我将展示tcptrace图的细节!值得注意的是,我所展示的tcptrace图解,有一个前提,这些pcap文件都是在TCP发送端抓取的,否则一切将无效。我后面会写单独的文章来描述这个关系。现在开始吧!
超时丢包检测
这是TCP中经典的丢包检测方案,也是TCP在最初被设计的时候采用的方案,此后它一直被保留至今,虽然后来出现了很多针对丢包检测的优化,但对数据包的超时重传一直都是最后一道防线。其tcptrace细节如下:
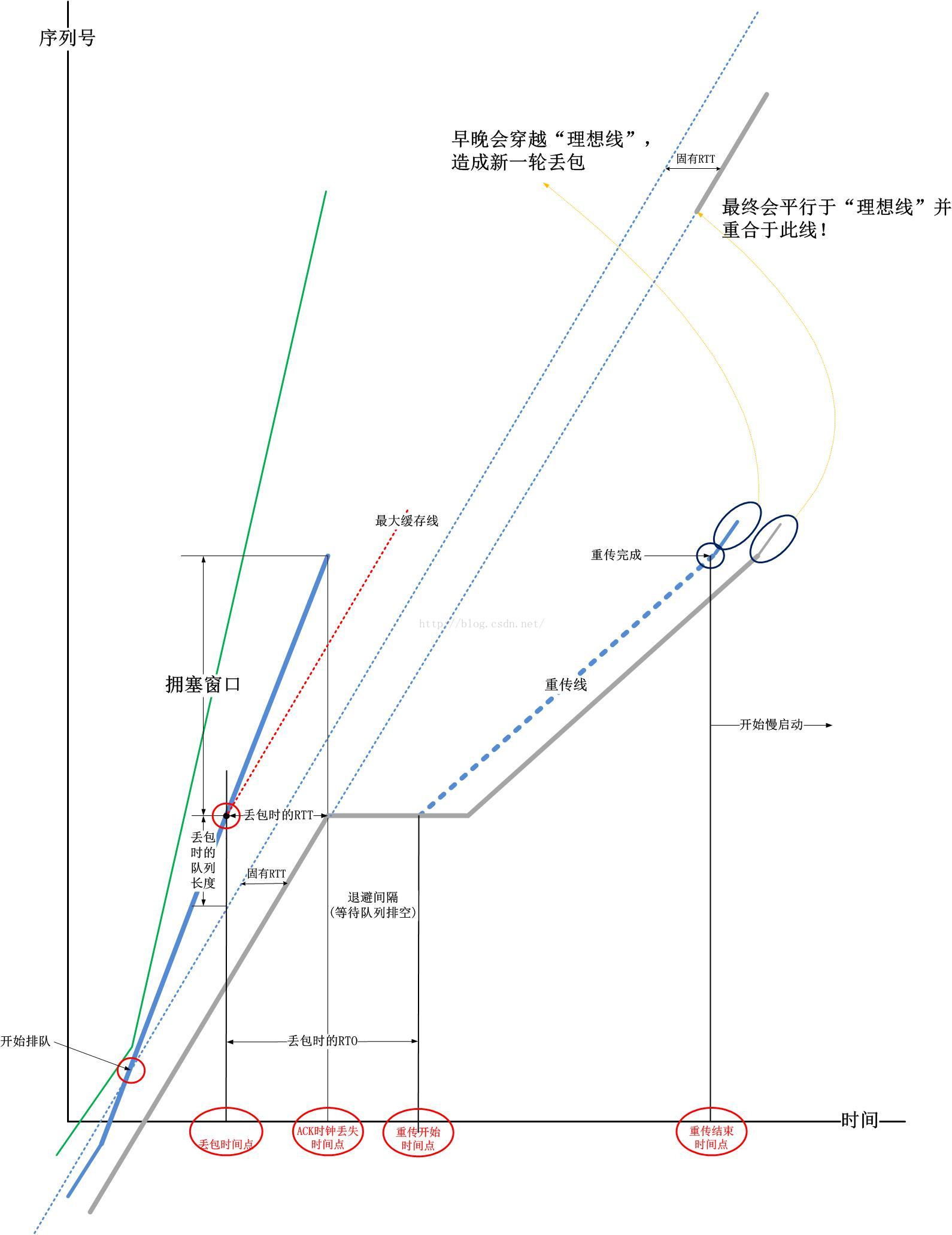

快速重传
仔细观察超时丢包时的tcptrace图,并注意到以下的阴影区域:
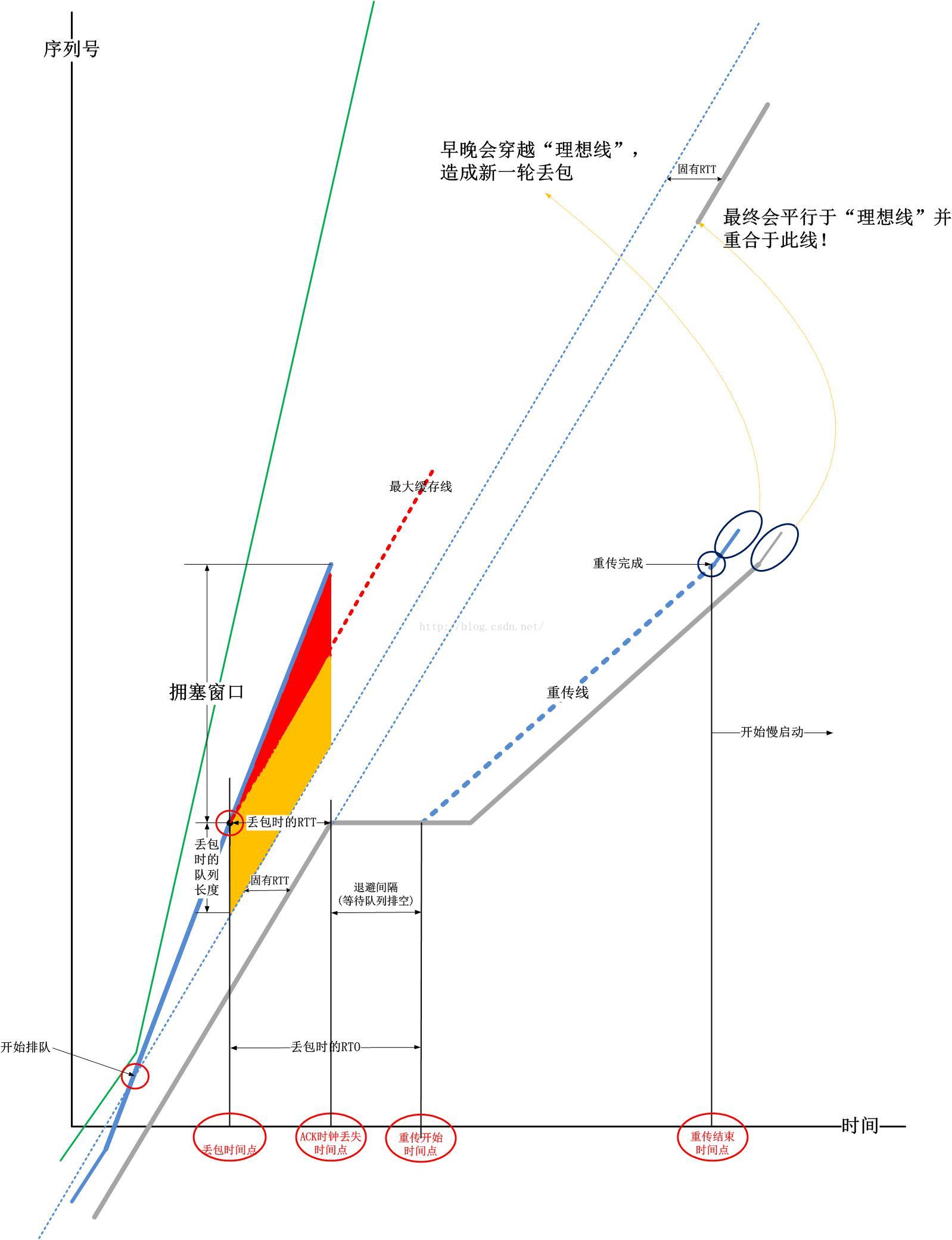
平行四边形覆盖的黄色区域表示,在交换机或者路由器由于队列满载实际丢包到TCP发送端通过超时检测到这个丢包事件的期间,还是有数据包可以被接收端收到的。把队列中的可以被正常处理的排队数据包沿着时间轴展开,就是上面这块黄色的平行四边形区域。
在路由器看来,这是可以被正常转发的数据包,在TCP看来,这也是实实在在收到的数据包,只是中间夹杂着丢包导致的空洞,即上图中的红色三角形区域。TCP利用这个事实,可以快速检测到丢包,然后进入善后处理阶段,这就是TCP的快速重传机制。所谓的“快速”是相对超时重传而言的。
按照上述解释,我把快速重传的图示列如下:
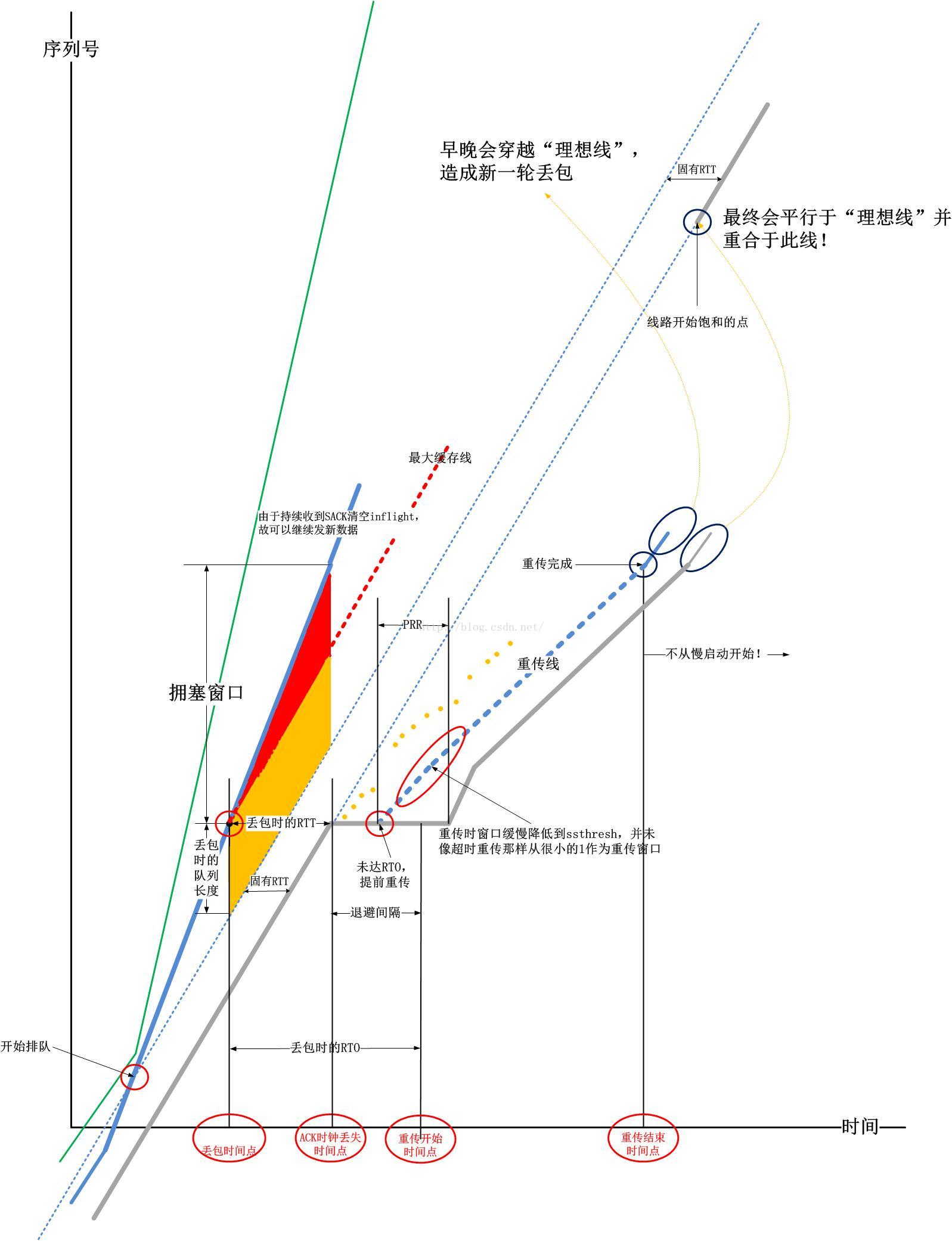
可以看出,不管是哪种重传,在tcptrace图上都是一致的。tcptrace图中的ACK线,理想线,发送线将整个发送行为分割成了几大块,下图分别从纵向inflight序列号以及横向RTT时间来分别解释tcptrace:
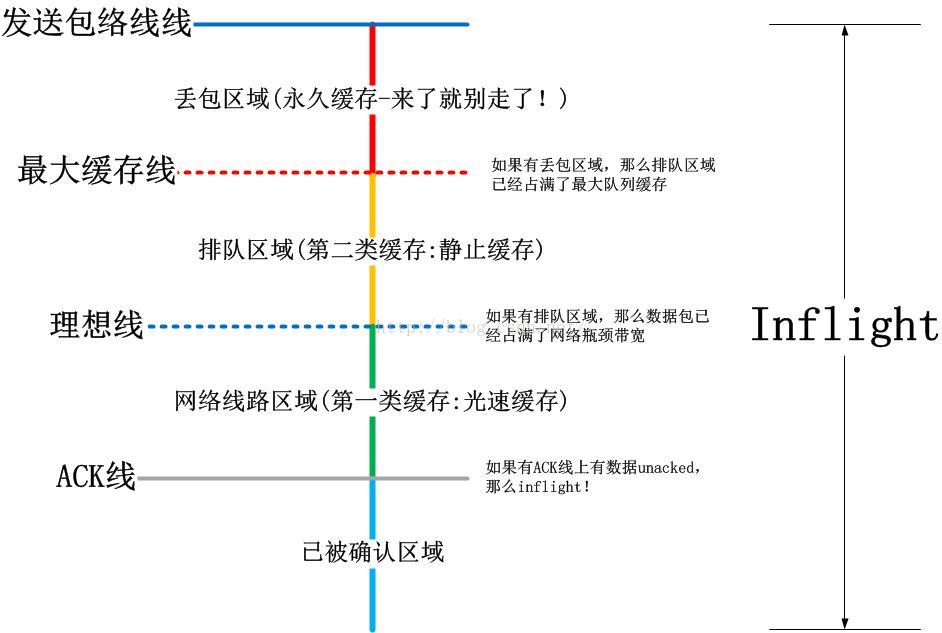
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
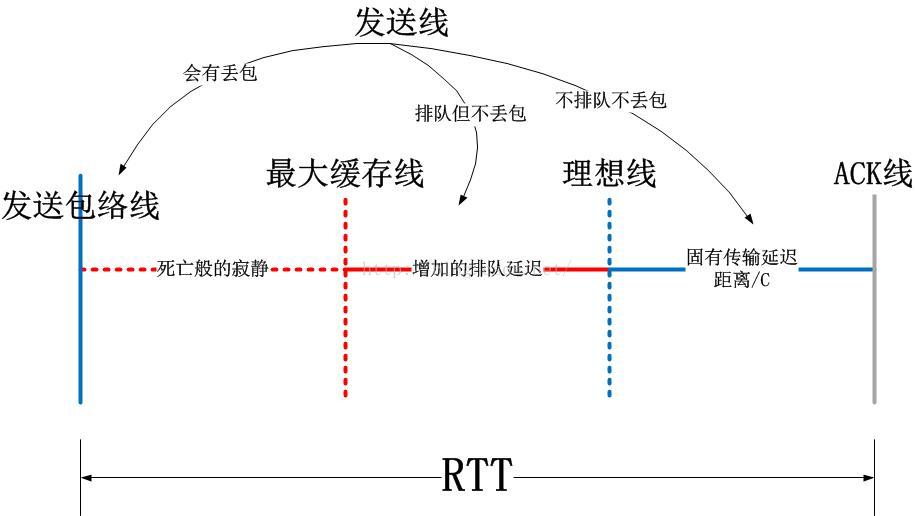
请注意,在本文开始的那两幅图关键的几个红色圈圈点的事件,就是上图中总结出来的几条线的相交处!现在要点题了啊!
不同拥塞算法的tcptrace
TCP拥塞控制算法的不同,本质上就在于其检测和应对上图中任意两条线交点的措施之不同!
一般而言,基于丢包的拥塞控制算法,都使用上述的第一幅图,检测序列号与几条线的相交点,反之基于延时的拥塞控制算法则使用上述的第二幅图,检测RTT与几条线的相交点。以下简单说一下几个经典的算法使用那个交汇点:
1.CUBIC算法:使用垂直的序列号线与最大缓存线的相交点,一旦相交,则进入快速恢复阶段,结束沿着3次曲线的前行。
2.BBR算法:检测垂直的序列号线与理想线的相交点,同时监控水平的RTT线与理想线的相交点,保证不偏离。
3.Vegas算法:检测水平的RTT线与理想线的交叉点,并基于此调节发送速率。
------------------------------------------------------------------
仔细看上面的tcptrace图示解析,或者说你自己用wireshark抓了一个包出来,你能理解为什么发送线的斜率一直都是正的(向上)而不是偶尔变成负数(向下)啊?!
首先,在TCP的标准以及其Linux实现中,所有类型的数据发送,不管是新数据发送,还是重传老数据,都是从低序列号发送到高序列号的,因此,这个tcptrace图在任意位置都不会看起来是向下走向的,但是也正因为此,一旦发生丢包,整个发送线并不是连续的:
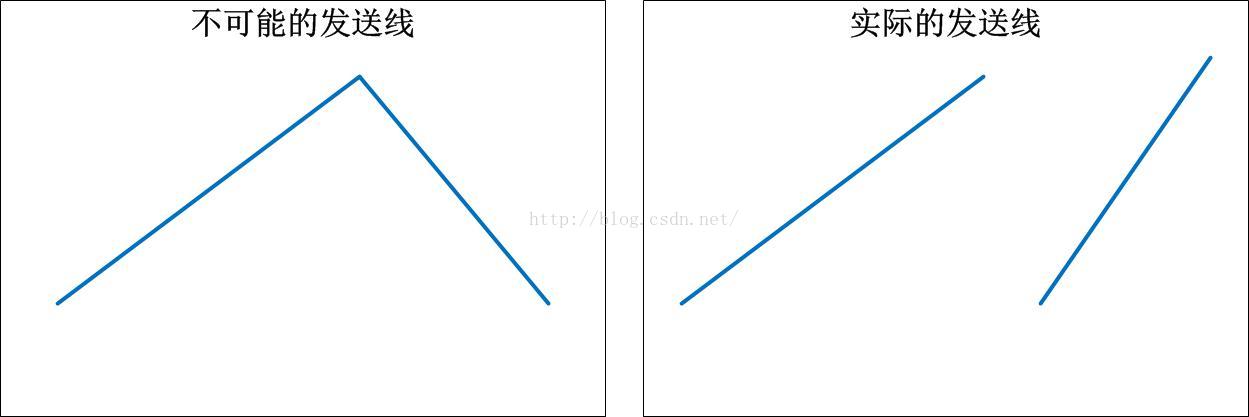
我们看到了上图左边比较好看,比较连续的线,但那是不可能的(数据不会按照序列号从高到低的顺序发送)。为了让曲线更加直观些,为什么不能直接使用速率线呢?
这是另外一个图,不是tcptrace图,本文不谈,后面会写专门的文章。
------------------------------------------------------------------
通过本文,你可能已经明白了tcptrace怎么看,但是你能用它解决问题吗?通过上面几幅图,你可以看出以下的事实:
一旦线路达到饱和,ACK线斜率不会随着你的发送速率的变大而变大,这意味着什么?这意味着数据排队了!在BBR算法看来,它可以发现这个现象主动降低发送速率,最终避免排队!然而对于CUBIC而言,它会无视这种现象,它甚至不会去采集ACK确认数据的速率。另一方面,如果你使用了CUBIC算法,且路径中存在一个深队列缓存,那么在其爆满之前,发送线在垂直方向距离理想线的距离会非常大,水平方向看,RTT增加的量也会非常大,这些不用理论分析,从图上就可以直观的看出来,如果tcptrace图在你手上,你就可以直观的看出来。此时,即便发送端主动降低了发送速率(当然对于CUBIC而言这是不可能的,但是对于Vegas或者Hybrid之类的算法而言,是可能的),采集到ACK线斜率的降低也要经过一个RTT的时间,如果此时RTT已经由于排队变得很大,那么一旦丢包将是一场悲剧。这是因为,深队列缓存中在丢包发生之前就缓存了非常多的数据包,这些大量的数据包在相当长的一段时间持续被转发并被ACK,这件事会在相当长的一段时间掩盖或者说隐瞒掉丢包的事实,从而造成旁氏骗局造成的透支的代价非常之大!
【注意,旁氏骗局被揭穿所需的时间越久,透支的代价就越大!】
另外,在tcptrace图中,我们要注意到理想线和发送线之间的夹角,它决定了丢包的时机和发现丢包的时间点,它和第一次丢包时发现的队列缓存的大小一起决定了重传率,这些也是可以非常直观的看出来的。
------------------------------------------------------------------
最后,我来说下文中“理想线”的真实含义。
毫不夸张地说,这条线决定了一切!
然而,这条线并不可见!
Oh!Shit!
TCP的拥塞控制算法就是要找到这条线,并且让发送线追其踪迹!至于说是缠绕它前行还是紧贴它前行,无非只是不同的追随方式罢了。这里必须要注意的是,发送线的前进是滞后于理想线的。你可以把发送线看作是理想线的反馈!那么这里就出现了两个必须回答的问题:
1.如果带宽有空余,理想线斜率增加了,发送线有什么机制可以发现并跟着把斜率陡上去?
2.如果带宽吃紧了,理想线斜率变缓了,发送线有什么机制可以发现并跟着把斜率缓下来?
这两个问题的不同答案定义了不同的拥塞控制算法。
我们再次以CUBIC和BBR为例,看它们是怎么回答这两个核心问题的。
CUBIC的答案:
问题1的答案
CUBIC不监控带宽,它只是单纯地从理想线下面一个斜率很低的起点开始按照一条固定的3次曲线方式不断增加斜率,最终一定会与理想线相交,这意味着它“追上了”理想线!
问题2的答案
CUBIC在回答问题1的时候,显然以追上理想线为目标,然而它并不知道自己是否已经追上理想线,没有任何标志性事件,所以只能有一个“你已经过头了”的警示来劝其止步!此时CUBIC的发送线将下穿理想线,直到掉到理想线以下,一次不行就多次,因为如果发送线依然在理想线上面,那个“你已经过头了”的警告会一直存在。
所以说,对于CUBIC而言,它采用缠绕的方式螺旋状追着那根它看不到的理想线前行。
BBR的答案:
问题1的答案
BBR会时不时的定期用更大的斜率的发送线去探测一下,如果带来的ACK线斜率也跟着变陡,根据tcptrace图可以看出,固有RTT不变的情况下,说明理想线也变抖了,BBR会继续,直到ACK线不再继续变抖。然后贴着理想线往前走。采用这种方式,BBR是大的时间尺度上,不会掉队。如果说CUBIC采取了一条本来就是螺旋状的3次曲线来缠绕理想线,那么BBR就是借助了ACK线的反馈来紧贴理想线。
问题2的答案
BBR算法会监控RTT,我们从tcptrace图中可以看到RTT在排队的时候会怎样,BBR算法可以检测到排队这件事。当其发现这件事,从图中我们可以看出,这意味着本来平行于理想线的发送线与理想线相交了!这意味着理想线变缓了,紧随着理想线的节奏,发送线会主动变缓。
------------------------------------------------------------------
任何回答不准上面两个问题的那些个拥塞控制算法,都是扯淡!
------------------------------------------------------------------
在此,我借用一句安全领域加密算法选型方面的名言,来自Bruce Schneier:
Anyone can invent an encryption algorithm they themselves can't break; it's much harder to invent one that no one else can break!
在你充分“证明‘自己会被证明是正确的’”之前,慎用自己发明的方案!可能有点绕,一句歌词可能更加明了些:我是一个瓦斯行老板之子,在证明自己有独立赚钱的本事以前,我的父亲要我在家里帮忙送瓦斯。
------------------------------------------------------------------
布雷斯悖论是个真理,增加资源,只会加重拥塞而不是缓解!虽然你用Linux tc工具模拟的延时看上去好像把你自己PC上的两台虚拟机模拟成了深圳到乌鲁木齐之间的链路,但是tcptrace会揭穿这一切的。你永远都无法消解真实网络与TC模拟之间的差异,你知道原因吗?
原因很简单!你模拟的延时是基于缓存的,它是可以Bloat的,而实际的网络,如果只是距离和光速带来的BDP,是不会被Bloat的。换句话说,你模拟的管道是可以膨胀的,然而真实的管道是不会膨胀的,懂了吗?如果还是不懂,请理解以下事实,第二类缓存是共享的,第一类缓存是独占的,你只能模拟第二类缓存!
原文链接: https://blog.csdn.net/dog250/article/details/53310937
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍;
也有高质量的技术群,里面有嵌入式、搜广推等BAT大佬

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/407721
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!