
序
在悬挂高温黄色预警的深圳的夜晚,实在是不能安眠,只能在后半夜起来找点事做。周末似乎又回来了,周末竟然不用再去加班,好陌生;周末竟然还有台风,好熟悉…
凌晨不到三点,站在阳台凝望夜空,没有星星,近看小区里对面的楼,没有灯,就连路灯都显得很昏暗,不知在这样的世界,睡梦中的好人和坏人的心灵还会不会交织,笼望这一切的时候,会冥想,感觉拥有了这整个世界…这个时候,我本应该点上一根烟的,然而早已没了这习惯,回到屋里,开始写一篇技术文章的续集。
本文是我2013年的一篇文章《探索iptables BPF模块的悲惨历程》的续集!
写这个续集,其实完全由于我上周那篇文章《iptables高性能前端优化-无压力配置1w+条规则》的惯性使然,在想写点关于bpf的东西的时候,我隐约间记得好像之前写过一点关于这么个玩意儿的文章,但印象模糊了,于是baidu关键词“bpf dog250”之后,就发现了这篇2013年的文章,既然有它在先,我只能将本文定为其续集了,没有别的意思,其实本文是独立的一篇。
iptables的bpf match
玩iptables防火墙已经很久了,一直以来我都在想,为什么不用bpf(Berkeley Packet Filter,没接触过该概念的请先熟悉概念后再阅读本文)实现Linux防火墙呢?
这个问题的答案虽然显得很没有意义,但却不是那么显然。
我们知道,Linux防火墙本质上就是一个包过滤程序,而我们常用的tcpdump工具可以过滤出来你想要抓取的数据包,tcpdump使用的过滤机制正是bpf所提供的,那么,显然的想法是,能不能直接利用bpf来实现防火墙,决定数据包的DROP or ACCEPT呢?
我曾经想过写一个Netfilter HOOK Function来实现上面的想法,直到我了解到iptables有一个match模块叫做bpf之后,我方才打消了这个想法。不过我知道,至少在iptables 1.4.7版本是不支持这个match的,而这个版本的iptables是CentOS 6.7所自带的版本,而我一直在使用这个版本,所以我没能第一时间看到iptables的Changelog,所以直到我亲自编译了iptables 1.4.21之后,我才发现了这个bpf match,至于2013年时我是怎么接触这么个技术的,可能那时用到了吧,幸亏留下了点印记(这就是写blog的好处…)。
简单说吧,iptables的bpf match非常帅,以我的体验来看,一条使用了bpf match的iptables规则可以替代多条单独的iptables规则,这一点bpf match和ipset match有异曲同工之妙处。举一个简单的例子吧,请看以下的iptables规则:
iptables -A OUTPUT -m bpf --bytecode '5,32 0 0 16,21 1 0 16909060,21 0 1 33686018,6 0 0 1,6 0 0 0' -j DROP它的含义是,如果数据包的目标IP地址是1.2.3.4或者2.2.2.2,那么阻止它们(现在不理解这个天书般bpf match没关系,后面会详述)。很显然,这是一条iptables命令,然而,它却阻止了2个IP地址,如果按照常规的iptables语法,它由于天生不支持同一个match的OR,所以就必须要配置两条iptables命令(在iptables中,同一行的不同match之间执行and,不同行的规则之间执行or):
iptables -A OUTPUT -d 1.2.3.4 -j DROP;
iptables -A OUTPUT -d 2.2.2.2 -j DROP;显然,使用单独的一个bpf match要比配置2条iptables规则简便得多。不过还有另一个选择,那就是使用ipset。首先我们将1.2.3.4和2.2.2.2加入一个set中,然后使用单一的ipset match来进行匹配,凡是目标地址在该set中的,全部DROP。
然而bpf match和ipset还是有差别的,那就是bpf实际上是执行一段程序,具体匹配哪个IP地址或者哪个别的什么字段,是由程序逻辑决定的,而ipset match则完全不同,它只是一个高效的查询结构而已,具体的逻辑依然在iptables本身,iptables会判断IP地址或者哪个别的什么字段在不在这个set中,只是判断的过程非常高效而已,其实所谓的高效也不过就是那些我们熟知的二叉树,哈希等算法,请注意,这些算法是内置的,外部的iptables只有选择权,而没有定义权,换成bpf的话,没有什么内置的算法,全凭你自己的想象。像上面的那个简单的例子,我写出的”5,32 0 0 16,21 1 0 16909060,21 0 1 33686018,6 0 0 1,6 0 0 0“是一个遍历匹配2个IP地址的算法,而在本文的以下部分,我将展示一种使用bpf程序自己定义的一个二叉树匹配算法。
看到bpf match和iptables标准match以及ipset match的差别了吗?如果大致明白了,那么我们开始本文的重点内容。
BPF的意义
极端点说,有了bpf match,iptables便仅仅成了一个框架,所有的匹配逻辑全部分离到了bpf程序中,人们再也不能说由于iptables规则的存在而执行效率低的问题在于iptables了,如果真的效率很低,那么一定是你的bpf程序写得不好!这就好比,我提供了一块CPU,然后你负责写程序,你把CPU给耗尽了还是无法满足你的计算需求,然而有的人就可以,我只能说,你的程序写的不好,而不是我的CPU不好。一样的道理。
So,bpf的意义在于,它掌控一切,它便担当一切。理想情况下,你只需要为你的防火墙写一条iptables规则:
iptables -A OUTPUT -m bpf --bytecode $prog -j DROP然后,你大量的工作将必然消耗在编写prog程序的过程中,而这将是一个比较具有挑战性但却很有意思的工作。
一个Trie二叉树实例
本文的大部分篇幅均用来描述一个实例,即如何编写一个bpf程序,实现特定多个目标IP地址的阻止功能。该bpf程序的匹配查找算法使用比较简单且显然的Trie二叉树结构,该树结构和Linux路由表的Trie树是一致的,我花了点时间构建了一棵Trie二叉树,它如下所示:
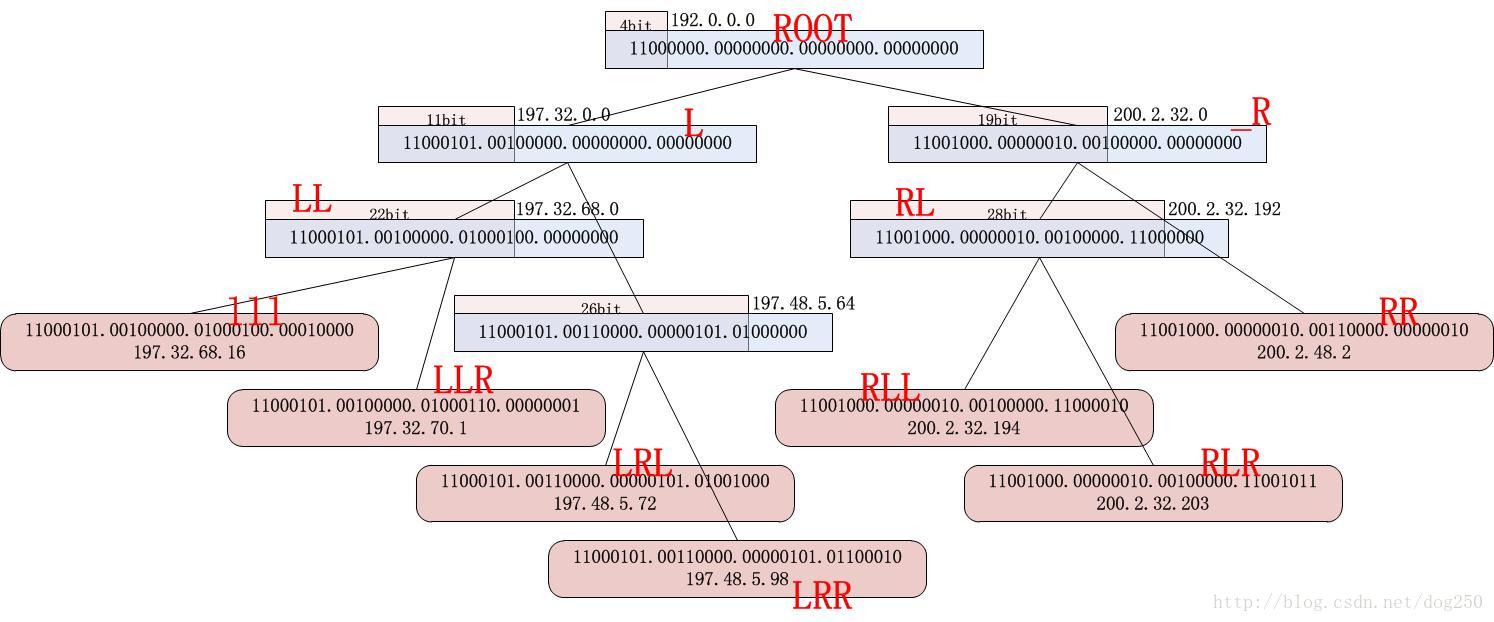

我并不是想说这棵树是如何形成的,这不是本文的内容(如果想知道,请参考Linux内核Trie路由树的插入,查找,删除算法,具体文件是:net/ipv4/fib_trie.c),我的意思是想说,一旦有了这棵树,我如何写一个bpf程序,来在该树上查找特定的IP地址。
用bpf指令手写Trie二叉树搜索程序
先说一点往事,在我刚毕业那会儿,我的第一份工作是写Java的(虽然几个月后就被带入到了Snort和iptables方面),我当时对Java虚拟机比较感兴趣,研究了一段时间时间Java字节码,还花了点钱打印了当时买不到的《Java虚拟机规范》。我觉得熟悉Java字节码的最简单方法就是用字节码手写一个Java程序,并且可以执行并打印出Hello World。
我确实成功了,而且这并不难,毕竟Class文件就跟Windows PE和Linux ELF文件一样,都是具有标准的格式的,照着格式去一行一行写,虽然辛苦,但肯定是能成功的。一转眼就10年了,现在的风格依然还是一点没变,上周想了一个iptables前端优化之后,突然觉得可以用iptables的bpf match来模拟实现这个想法,我准备先手写一个bpf程序,然后再一探究竟。
我们先看下bpf的大致结构和写法:
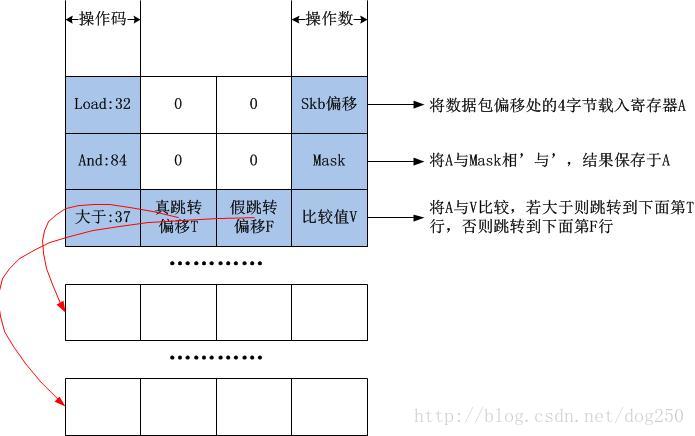
可以看出,一个bpf程序是很简单的,就是一行一行的罗列,逐行顺序执行,特殊指令可以让执行流跳转,这非常类似于汇编语言,只要我们手头有关于bpf的手册,可以查到具体指令的格式和用法,那么我就就可以手写bpf程序了,在我展示我手写的Trie二叉树查找算法之前,我先解释一下本文开始时展示的那段bpf字节码的含义,我将那段代码列如下并给出注释:
5, # 告知这段程序一共5行
32 0 0 16, # 32代表操作码,是加载的意思,16代表操作数,整行代表“加载IP头第16字节开始的4字节”
21 1 0 16909060, # 21代表操作码,是等值比较的意思
21 0 1 33686018, # 同上
6 0 0 1, # 返回1
6 0 0 0 # 返回0这段程序看似是不可解释的,然而却也不难,只要熟悉bpf文档上的那些指令描述,地址格式等,再反过来核对以上这段代码,非常之简单。那么我们该进入正文了。以下便是我手写的一个支持上述二叉树查找实例的bpf程序:
34,
32 0 0 16, # 载入IP头的目标地址字段(操作码32,16表示偏移)
84 0 0 4160749568, # 取前4bit,为了直接比较,取5bit (84操作码表示and,4160749568表示0xf8000000,即5bit的掩码)
37 13 0 3221225472, # 如图,判断是否大于 192.0.0.0(第5bit为1就大于它,37操作码表示gt,13,0为跳转偏移)
32 0 0 16,
84 0 0 4293918720, # 取前11bit,实际取到前12bit
37 5 0 3307208704, # 如图,判断是否大于 197.32.0.0(第12bit为1就大于它)
32 0 0 16,
84 0 0 4294966784, # 取前22bit,实际取前23bit
37 1 0 3307226112, # 是否大于 197.32.68.0,若大于则跳转到右孩子节点,否则继续左孩子
32 0 0 16,
21 21 0 3307226128, # 叶子节点,判断是否等于197.32.68.16,若等于返回1,否则继续判断右叶子
32 0 0 16,
21 19 20 3307226625, # 叶子节点,判断是否等于197.32.70.1,若等于返回1,否则返回0
32 0 0 16,
84 0 0 4294967264, # 取前26bit,实际取前27bit
37 1 0 3308258624, # 是否大于 197.48.5.64,若大于则跳转到右孩子节点,否则继续左孩子
32 0 0 16,
21 14 0 3308258632, # 叶子节点,判断是否等于197.48.5.72
32 0 0 16,
21 12 13 3308258658, # 叶子节点,判断是否等于197.48.5.98
32 0 0 16,
84 0 0 4294963200, # 取前19bit,实际取前20bit
37 5 0 3355582464, # 是否大于 200.2.32.0
32 0 0 16,
84 0 0 4294967288, # 28bit
37 1 0 3355582656, # gt 197.32.68.0?
32 0 0 16,
21 4 0 3355582658, # ==200.2.32.194?
32 0 0 16,
21 2 3 3355582667, # ==200.2.32.203?
32 0 0 16,
21 0 1 3355586562, # ==200.2.48.2?
6 0 0 1, # match!
6 0 0 0 # not match!将以上的代码去掉注释并合并为一行之后,就可以载入到iptables里了,我假设上述的代码合并为一行后保存在变量prog里,那么下面的命令将会将该bpf程序注入到内核并作用于iptables的包匹配过程:
iptables -A OUTPUT -m bpf --bytecode $prog -j DROP这个时候,你试试以下的IP地址还能ping不:
200.2.48.2
200.2.32.203
200.2.32.194
197.32.68.16
197.32.70.1
197.48.5.72
197.48.5.98虽然这些IP地址可能本来就不通,毕竟这是我自己构造的地址,但是如果载入bpf之后,你再ping它们的话,得到的结果是:
ping: sendmsg: Operation not permitted
而不是静默无回应!显然,这是iptables filter阻止的结果而不是不可达的回应。也许你会诘问这有什么好处吗?好处当然有,那就是用二叉树查找代替了遍历。如果不使用bpf match,你可能需要配置7条iptables规则来阻止针对这7个地址的访问,所有的数据包将会遍历这7条iptables规则,使用bpf之后,遍历的过程成了二叉树查找的过程,时间复杂度大大降低了!如果仅仅用7个IP地址举例不太明显,让我们想象一下10000个IP的例子。
遍历10000个节点的开销和二叉树查找10000个节点的开销,自己计算吧…
使用bpf助记符重写Trie二叉树搜索程序
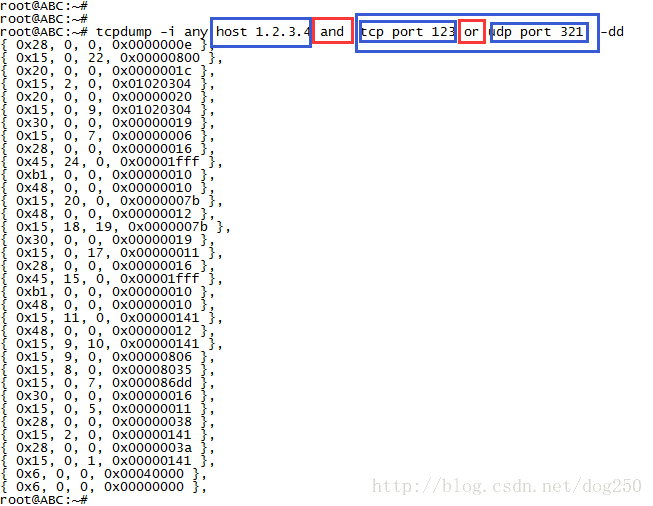
配置10000条iptables是一个体力活,手写一个包含10000个叶子节点的二叉树查找的bpf程序更是一个艰难的任务,而且即便花了一个通宵搞定了,面对这些纯粹的数字指令,一旦哪里有问题,调试将是不可能的!虽然说bpf match是一个好东西,但是难道只有一种编写它的方法吗?当然,我们不能指望tcpdump -dd这种编译,因为tcpdump的bpf编译功能太朴素了,它好像只能支持类似and,or这种简单的运算,比如下面的例子:
那么,为了支持包括跳转指令在内的操作,势必需要一种更加复杂些的写法,类似高级语言二叉树操作的那种写法。不幸的是,我目前没有发现有这样的高级语言。不管怎样,还是有一种稍微麻烦些的替代方案的,它的便利性介于手写bpf指令和高级语言之间,那就是采用bpf指令助记符来编写bpf程序。以下是一个关于助记符的例子:
ldh [12]
jeq #0x800, l2, l5
ldb [23]
jeq #0x1, l4, l5
ret #0xffff
ret #0它对应下面的bpf指令序列:
4,
40 0 0 12,
21 0 1 2054,
6 0 0 4294967295,
6 0 0 0可以看到,这种助记符与汇编语言非常相似。实际上,它的地位与汇编语言处在完全相同的位置。
如果你想快速熟练掌握bpf指令以及这套助记符的用法,最好的资料就是内核文档documentation/networking/filter.txt了,这里给出一个在线链接:
https://www.kernel.org/doc/Documentation/networking/filter.txt
假设你已经大致了解了这套东西,现在,我来用助记符将本文中的二叉树匹配IP地址的例子重写一遍(夹杂着注释),以下文件命名为BSearch.bpf:
ROOT: ; 根节点
ld [16]
; 以下两句是个优化,如果前缀不匹配,那么直接返回"not match"即可!
and #0xf0000000
jne #0xc0000000, ret_0 ;192.0.0.0
ld [16]
and #0xf8000000
jgt #0xc0000000, _R
L: ; 左节点
ld [16]
and #0xffe00000
jne #0xc5200000, ret_0 ;197.32.0.0
ld [16]
and #0xff000000
jgt #0xc5200000, LR
LL: ; 左左节点
ld [16]
and #0xfffffc00
jne #0xc5204400, ret_0 ;197.32.68.0
ld [16]
and #0xfffffe00
jgt #0xc5204400, LLR
LLL: ; 左左左节点(叶子节点)
ld [16]
jeq #0xc5204410, ret_1 ;197.32.68.16
jmp ret_0
LLR: ; 左左右节点(叶子节点)
ld [16]
jeq #0xc5204601, ret_1 ;197.32.70.1
jmp ret_0
LR: ; 左右节点
ld [16]
and #0xffffffc0
jne #0xc5300540, ret_0 ;197.48.5.64
ld [16]
and #0xffffffe0
jgt #0xc5300540, LRR
LRL: ; 左右左节点(叶子节点)
ld [16]
jeq #0xc5300548, ret_1 ;197.48.5.72
jmp ret_0
LRR: ; 左右右节点(叶子节点)
ld [16]
jeq #0xc5300562, ret_1 ;197.48.5.98
jmp ret_0
_R: ; 右节点
ld [16]
and #0xffffe000
jne #0xc8022000, ret_0 ;200.2.32.0
ld [16]
and #0xfffff000
jgt #0xc8022000, RR
RL: ; 右左节点
ld [16]
and #0xfffffff0
jne #0xc80220c0, ret_0 ;200.2.32.192
ld [16]
and #0xfffffff8
jgt #0xc80220c0, RLR
RLL: ; 右左左节点(叶子节点)
ld [16]
jeq #0xc80220c2, ret_1 ;200.2.32.194
jmp ret_0
RLR: ; 右左右节点(叶子节点)
ld [16]
jeq #0xc80220cb, ret_1 ;200.2.32.203
jmp ret_0
RR: ; 右右节点(叶子节点)
ld [16]
jeq #0xc8023002, ret_1 ;200.2.48.2
jmp ret_0
ret_1: ; 返回1,代表匹配
ret #1
ret_0: ; 返回0,代表不匹配
ret #0上面的代码充分体现了上述二叉树匹配的实现细节,本质上就是一个Trie树的查找过程,这和Linux内核中路由查找所使用的Trie树是完全一致的。这个便不细讲,只要将上述的助记符写成的代码编译一下,编译成bpf的字节码,就可以直接执行它了。
那么现在的问题是,如何编译它呢?虽然说目前还没有可以编译高级bpf语言的编译器,但是编译bpf助记符语言的编译器可是有现成的,非常容易获得,直接在Linux内核源码的tools/net目录中就可以找到,进入该目录后,直接make,便可编译出所有的工具。
Linux内核提供的这套针对bpf的工具集虽然应该足以满足大部分需求了。我们只需要输入以下的命令便可以编译BSearch.bpf了:
./bpf_asm BSearch.bpf编译好之后的输出是可以直接复制到iptables的,它已经被整理成了一行以“,”分隔的指令序列,当然,你还可以用Netfilter的nfbpf_compile来做同样的事情,这里就不赘述了。
还差些什么
还差温州皮鞋厂老板的最后一击!
我一直希望能像写高级语言一样写bpf程序,比如说,我想这么写程序:
Tree t = new Tree(192.0.0.0, 4);
Tree tl = t.add_left(197.32.0.0, 11);
Tree tr = t.add_right(200.2.32.0, 19);
...但是我缺一个编译器。
温州皮鞋厂老板懂不下10种编程语言,完全可以合并其精华,精心设计一种针对bpf的语言,专门处理各种防火墙规则,虽然我知道这样的规则早就有了,但是我还是觉得温州老板会做的更好些。
另外,即便是有了一个很好用的bpf程序编译器支持高级语言版本的bpf程序,载入iptables规则的bpf match也是无法还原成高级语言的,也就是说,当你用iptables -L或者iptables-save来查看规则的时候,你看到的是bpf最终的字节码,而不是可读的高级语言表示,这样的字节码表示对于管理员而言,等于零。
一点额外的想法
我们可以想象一下,Cisco的ACL编译后使能在一个网络接口上,它是一个什么样的存在?是类似iptables那样连续数组结构呢,还是本文中介绍的这种紧凑型的查找结构呢?我想应该是后者!
ACL规则只是管理员站在业务的角度去配置的,这个配置动作本身显然属于管理平面的操作,而ACL规则本身则属于控制平面,它将以某种形式直接作用于每一个数据包,因此在ACL规则和最终作用于数据包的规则的形式之间一定有一层预处理的中间操作,将ACK规则进行优化,使之更适合去更高效地控制数据平面。这个中间操作在Cisco的系统中,就是将ACL条目编译并加载到接口。
和上一篇《iptables高性能前端优化-无压力配置1w+条规则》的观点一致,我始终认为用户敲进系统的规则和最终执行的规则之间一定要有这么一个预处理过程。用户不可能直接敲进系统一棵二叉树,无论如何,任何操作员都是顺序地输入每一条指令的,即便是开飞机的飞行员也是如此,这是人的大脑结构决定的,也许时间维度的线性特征也起了一定的作用,使得每一件事必须是挨着上一件事开展的,没人可以预测未来。虽然计算机也是在时间维度上顺序执行指令的,但是在用户输入和计算机执行之间毕竟有个时间差,计算机便可以利用这个时间差来对指令进行某种形式的重排列或者展开,采用诸如空间换时间的策略进行优化,事实上,现实中的计算机一直都是这么做的(乱序执行,超标量处理器…),这完全是因为计算机执行的指令序列是事先便存在的,因此,完全顺序执行指令的计算机只存在于理论模型中。
那么在这个意义上,这个时间差显然就是一个缓冲区,在没有这个缓冲区的时候,只有当下是可以被处理的,因为没有人能精准预测接下来会发生什么,但是有了这个时间缓冲区,时间便可以展开成空间,传送带上不仅有当下,还有“未来”…
Linux系统上有没有这种可以利用时间差将规则重排,然后高效执行的防火墙机制呢?显然,在ipchain时代,没有这样的机制,在iptables时代,完全支持这样的机制,但是却几乎没有人去做,我在《iptables高性能前端优化-无压力配置1w+条规则》一文中提供了一种模型,就是为了支持这种机制的。
iptables的下一代,即nftables时代,则完全支持了这样的机制,正如nftables的很多介绍中提到的那样:The new engine mechanism is inspired by BPF-like systems, with a set of basic expressions, which can be combined to build complex filtering rules. 本文中提供的方案大体与此类似,只是利用了iptables的外壳框架,实现了规则集的外部优化,当这种优化真实可行并且确实做到了的时候,我可以大胆地说,Linux系统可以实现类似Cisco那种高效的ACL匹配策略了,然而这需要在用户态做太多的事情,谁来做?温州皮鞋厂老板?
后记:致小小
今天小小已经是一年级的小学生了,时间过的太快,2013年我在第一次接触bpf的时候,她还不到两岁…
能送给小小的入学礼物没有,我甚至都没有钱给她买一套文具,钱都在老婆手上,然而我会给一些更重要的东西,虽然我的年纪还没有资格谈论人生,但是我的经历至少可以给小小一些非技术上的指导,或者说仅仅是建议,所以我在这个后记中致小小一些话,首先把下面的十条送给小小:
- 学习好这件事的意义并不大;
- 学校好这件事的意义并不大;
- 考第一和考倒数第一的差别并不大;
- 学霸和学渣的差别并不大;
- 小小你是所有认识的人同龄人中眼界最宽的,没有之一!
- 除了见识,小小你是所有认识的同龄人中尝试并且热爱的事物最多的,没有之一!
- 背不下来课文无所谓,你爸我相信基因,那是你不想背而已;
- 算不出数学题无所谓,你爸我依然相信基因;
- 外语词汇量,外语水平不如别人无所谓,你爸我相信你妈的基因;
- 居无定所,没有一个长久的居留地无所谓,很多伟大的人都这样,安土重迁才是问题;
同时,我建议性地告诉小小什么才是真正重要的,有四样东西,你必须要有:
- 眼界
- 感恩
- 执着
- 勇气
然后,你会得到所有你想得到的!
你上了小学,意味着你已经开始了不能停歇的长跑,全程会一直延续到你生命的终点,期间你可以倒下,但最终你必须要爬起来,无论如何你不能主动停下来,所以,这一路一定是很艰难的,我不会告诉你这一切其实没什么,相反,在适当的时候,我会告诉你,事情很严重,人的生命并没有自带享乐基因,我会让你知道基督新教对每一个人公平的教诲,并且在你有不可逾越的困难时告诉你,然而困难并不是不可克服。
人要学会聪明地省力去做更有意义的事,我不建议愚公移山,精卫填海,铁杵磨成针,悬梁刺股这种传统,因为我曾经试过,不能说没用,但效果并不大,这些典故中蕴藏的精神是鼓励集体的,而不是个人,基督新教讲因信生义,信义全在个人,来自努力。我的建议是,于一点发力,把一件事做的比任何人都好,这就够了,人不可能真正的在所有领域全面发展,比如我自己,在自己所属的技术方面,可能连编程都编不好,但我的发力点并不是编程…
…
已经早上了,也就先这样了,就一点要求,每天都要自我总结,每天都要比前一天有所进步(当然,这个“进步”的概念依然来自基督新教伦理)。
原文链接: https://blog.csdn.net/dog250/article/details/77790504
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍;
也有高质量的技术群,里面有嵌入式、搜广推等BAT大佬

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/407297
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!