
又到了周末,生物钟准时在午夜让我恍惊起而长嗟,一想到TCP,恍如昨日,也不知怎么就千里迢迢之后心依旧茫然,算是拾起来的东西吧,就坐下来再写点关于TCP的东西。由于最近在追《龙珠超》,也是很想写点关于龙珠的随笔,也只能等到明天我被我的偶像弗利萨(目标明确,干净利索,毫不犹豫,越挫越勇,屡战屡败,屡败屡战,心狠手辣,特立独行,孤独但不寂寞)拍醒的时候吧。
乱序和丢包
TCP的数据包是严格按照序列号递增的顺序发送的,如果不考虑网络传输,数据包是按序到达接收端的,接收端对按序数据包的ACK也应该按序返回,然而由于数据包并非直接到达接收端,而是经由一个以无状态无连接的IP协议为核心的逐跳路由的分组交换网到达接收端的,事情就会变得复杂。比如以下图所示的数据包乱序的情形:
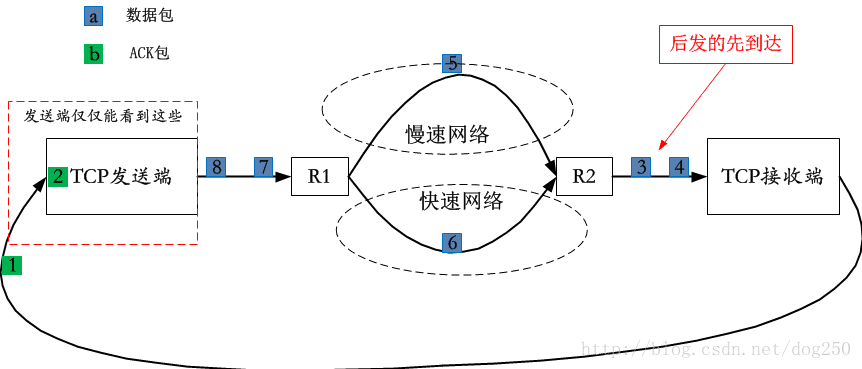

与此同时,由于网络并非是物理上可靠的,所以还会出现丢包情形:

TCP是个瞎子协议(它的行为更像是臭名昭著的蝙蝠),对于TCP发送端而言,两种情况下,它看到的是同样的反馈,如何区分它们就是一个现实问题。如何区分呢?
答案是TCP发送端根本无法区分。那么必然需要一个算法,来让TCP发送端在两难之中猜其一,在大多数的TCP实现中,reorder算法(我自己取的名字)正是做这个的。reorder算法虽然并不确保精确,但却非常合理。在工程上,不精确但合理的方案就是可用的方案。接下来我就描述一下reorder算法的核心。
关于空洞
由于存在两种可能性会造成空洞,因此就会有两种关于空洞的定义,是为丢包空洞和乱序空洞,其中,乱序空洞是一种可以靠时间来弥补的空洞,而丢包空洞只能重传数据包来弥补。
由于乱序可以靠时间来弥补,比如稍微等待一下,乱序掉队的数据包的ACK或者SACK就会返回,因此TCP在将一个数据包标记为LOST之前,首先会给它一个机会,也就是说,TCP首先会认为这个数据包是迟到了或者乱序了而不是丢失了,空洞是由暂时的ACK迟到或者乱序造成的而不是丢包造成的。
让我们分别看一下。
乱序空洞
还是用图来解释比较方便:
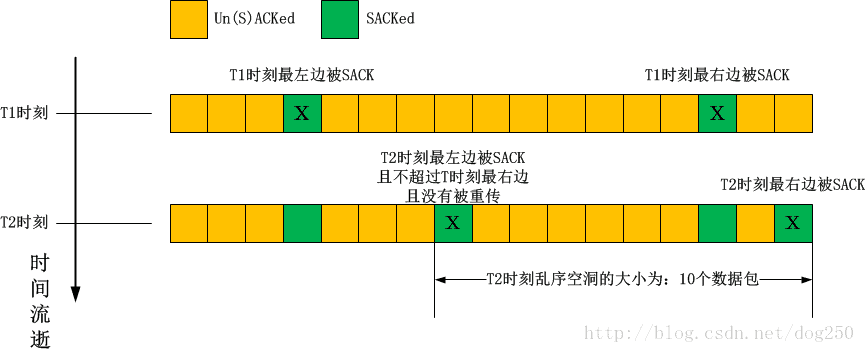
我们发现对于乱序空洞而言,其左右两个边缘是在一个时间序列中被定义的,在每次收到ACK或者SACK的时候被定义,定义如下:
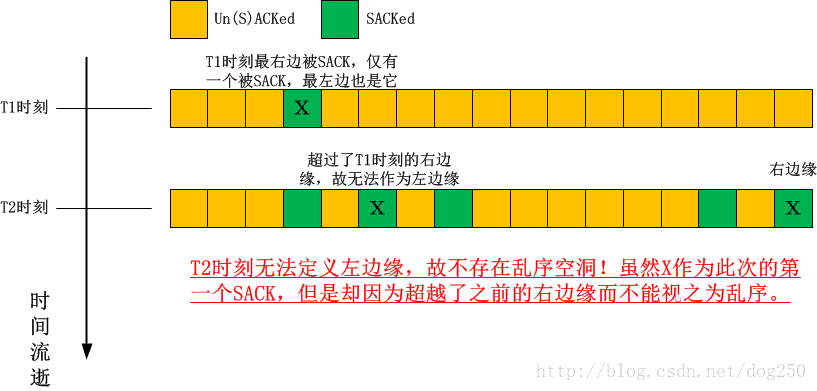
乱序空洞右边缘
这次收到ACK或者SACK时(包括之前的这次),已经被SACK的最右边的数据包。
乱序空洞左边缘(这个比较复杂)
这次收到ACK或者SACK时(特指这次),所携带ACK或者SACK确认的最左边的没有被重传的(这一点很重要,避免了二义性:重传的一定是判定为丢失的,没有重传的才能是乱序的)但又不超过之前右边缘[注意:不包括这次新的右边缘]的数据包。
值得注意的是,乱序空洞包括其左边缘和右边缘这两个被SACK的数据包!
我们来看3个例子(重申,如果觉得不过瘾,就看我下一篇文章TCP的乱序和丢包判断(附Reordering更新算法)-实例case):
- 例子1:单独收到一个包含两个SACK段的ACK包
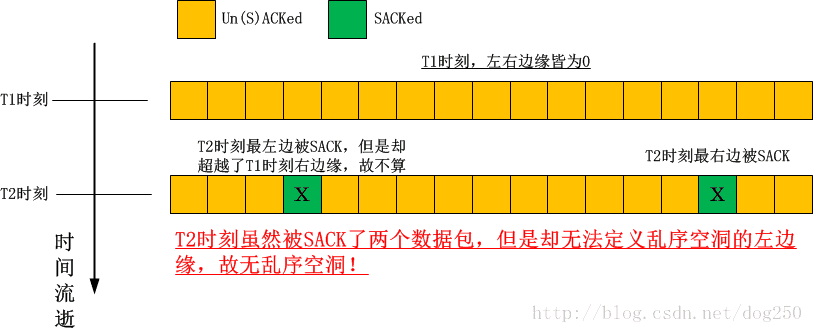
- 例子2:连续两次收到携带SACK的ACK包
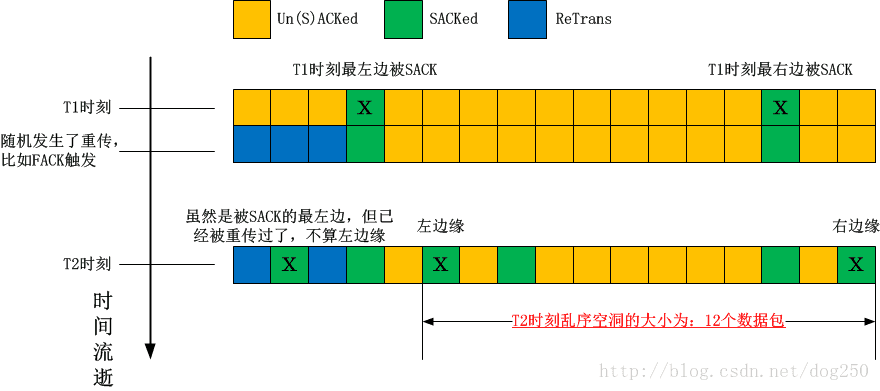
- 例子3:理解一下什么叫做“定义左边缘时不能超过之前的右边缘”
这个左右边缘的确定实在是复杂,特别是左边缘的确定。我很难用文字把它描述得非常清楚,如果实在是觉得太绕,不妨看下我的下一篇文章TCP的乱序和丢包判断(附Reordering更新算法)-实例case,我准备了几个实际的用例来解释,通过
例子来解释我觉得要比原理性的解释容易理解得多。在实际阅读调试这些例子之前,我给出SACK遍历时确定左右边缘的例程:
for each skb in write-queue
if thisSACK contains skb && skb.SACKed == FALSE && skb.RETRANS == FALSE && skb < Hr
Hl = skb
if thisSACK contains skb
Hr = skb
skb.SACKed = TRUE
if Hr > Hl && (Hr - Hl + 1 > reordering)
reordering = Hr - Hl + 1本节的最后,给出内核中更新Hl的注释,希望能帮助理解,它来自tcp_sacktag_one函数:
/* New sack for not retransmitted frame,
* which was in hole. It is reordering.
*/
if (before(start_seq, tcp_highest_sack_seq(tp)))
state->reord = min(fack_count, state->reord);丢包空洞
如果TCP发现乱序已经无法容忍了(判断条件有两类,基于时间的RACK和基于空间的SACK数量),那么便要标记某些数据包丢失了,被标记为LOST的数据包区域就是丢包空洞,接下来便要重传丢包空洞中的所有数据包。具体如何重传,这是另一个话题。
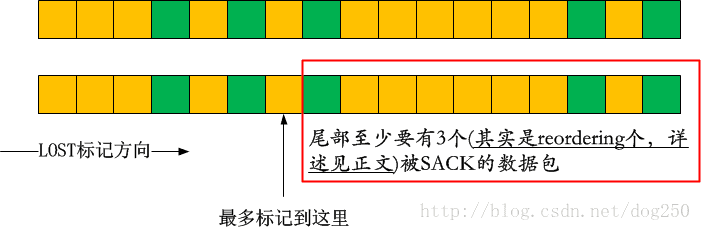
TCP在标记LOST数据包的时候,要求避开乱序空洞。
在基于时间序的RACK尚未引入TCP之前,默认情况下,乱序空洞的长度为3,即允许出现不超过3个数据包的乱序。3这个数字,你除了可以理解为乱序空洞的长度之外,还可以理解为弥补这个空洞所需要的最多的数据包的数量,一旦超过这个阈值,就要开始标记丢包,即便如此,3这个乱序阈值还是保留给了乱序空洞,即在最后一个被标记为LOST的数据包之后,要保证至少有3个被SACK的数据包:
如果其乱序配额还没有用尽,那么可能只需要标记一个包为LOST即可。详情可以参见我的另一篇文章:关于TCP快速重传的细节-重传优先级与重传触发条件
这里谈一个问题,先看下面的序列:

姑且不管这个序列是如何得到的,极端点说,它可以在一次ACK中被带回,那么问题是,明显后面的空洞更加稀疏,如果按照承让3次机会给乱序,后面保留3个SACK数据包的话,显然只有一个数据包会被标记为LOST,这合理吗?
乱序和丢包之间的自适应
标记数据包为LOST的过程是从传输队列的UNA向后进行的。从这个过程(详见关于TCP快速重传的细节-重传优先级与重传触发条件中的问题1)中可以看出,被SACK的数据的聚集特征会影响LOST数据包被标记的数量。仍然以默认乱序空洞长度3为例,我们来分别看一下:
- SACK大量聚集于传输队列前部,即左边的情形

- SACK大量聚集于传输队列后部,即右边的情形

我们可以看到这里存在一种自适应特征,即SACK聚集于前部时,在遍历队列的时候,SACK数据包被大量跨越,留给标记为LOST的空间就少了,因此TCP在这种情况下更倾向于乱序而不是丢包,反之,当SACK大量聚集于后部时,TCP则更倾向于前面的数据包都丢了。这是非常合理的。因为后面的数据包是后发送的,它们首先被SACK,已经预示了丢包的可能性,并且大量的被SACK,更加减少了乱序的可能,毕竟为什么只有前面的部分乱序呢,后面的这部分不是整整齐齐地聚集被SACK了吗?
反之,如果是前面的部分被聚集SACK,这恰恰说明网络可能仅仅出现了卡顿和乱序,很大概率并没有丢包,再等等,会来的,毕竟先发送的数据包不是已经被密集SACK了么。
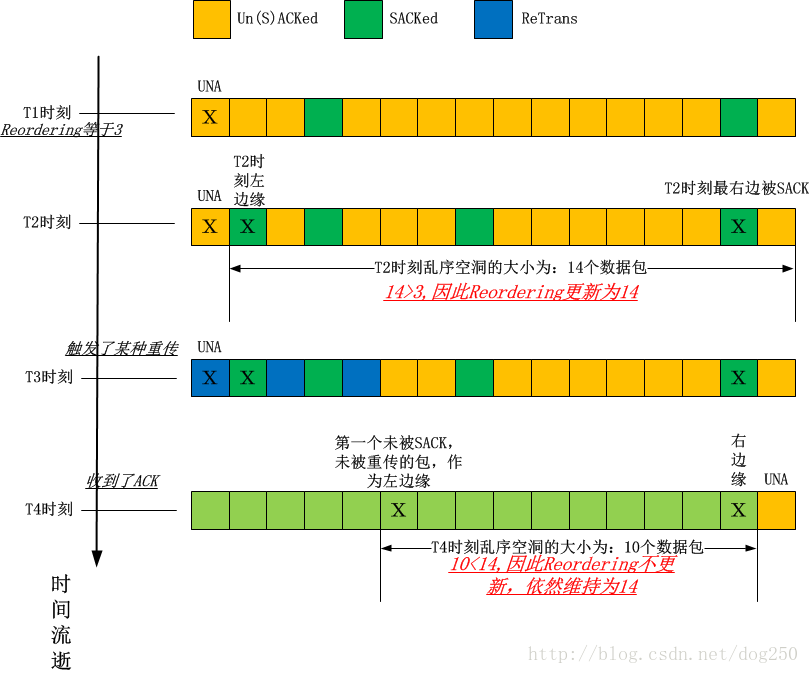
reordering更新算法
reordering更新算法的核心包括以下的组成:
-
reorder更新算法的数据结构
- reordering值
TCP发送端维护一个reordering值作为所能容忍的弥补乱序空洞的数据包数量的最大值。如果接收了reordering个数据包仍然没有弥补乱序空洞,接下来TCP就要通过标记LOST数据包来
定义丢包空洞了。 - 空洞最左端Hl
即乱序空洞的左边缘。按照数据包在TCP传输队列中从左到右的发送顺序,未被连续确认(包括ACK以及SACK)的部分最左边的数据包被标记为Hl。Hl再左边的数据包都是已经被
ACK的数据包。 - 空洞最右端Hr
即乱序空洞的右边缘。按照数据包在TCP传输队列中从左到右的发送顺序,未被连续确认(包括ACK以及SACK)的部分最右边的数据包被标记为Hr。Hr再右边的数据包都是尚未被
SACK的数据包。
- reordering值
-
reordering更新算法的行为
一旦发现针对已发送数据的(S)ACK空洞长度(即Hl和Hr之间的间隔)大于reordering值,则需要单调递增地更新reordering值,则新的reordering值为该空洞长度的大小。
上面的叙述可见下图:
为什么reordering值的更新是单调递增的呢?这里面又是一个经验考虑(或者你认为它是哲学考虑也行)。丢包时一个激进的猜测,而乱序则是一个保守的猜测,TCP作为一种公平反馈协议,只有在协作大于对抗的情形下才能表现得共同良好,不然就是同归于尽,所以说天平自然向着保守方向倾斜!不必要的重传会损人不利己,而适当的退避则不会给自己带来太大的损失,这会给大家都带来好处。详见羚羊和猎豹的对抗,一条命还是一顿饭?这个问题很好回答。
reordering更新算法的原理就是这样,它非常简单,然而如果你试着操作一下,比如用packetdrill等工具去复现以上的原理,就会发现事情并非如上述那般单纯,这是为什么?
TCP是作为整体运作的,没有任何一个单独的机制可以独立起作用,对于reordering值的更新行为而言,它的表现之所以会比较复杂,是因为其中牵连了FACK策略以及RACK策略。
因此在实际操作中,reordering值的更新会和FACK以及RACK相互整合相互影响。这种相互影响会造成拥塞窗口发生变化,而拥塞窗口会影响可以重传的数据包的数量,进一步,位于空洞中的一个数据包是否被重传反过来会影响reordering值的更新细节。
从上述文字,也许你已经意识到了事情的复杂性,我本想说的更详细些,然而这些细节实在不是语言文字所能完美表达,因此,结合整个关于丢包和乱序的判断机制,我准备了几个用例,我用实际的例子来描述复杂行为的细节,详情如何,且见下一篇文章。
后记
请不要把本文所描述的这些机制看作是TCP拥塞控制算法的组成部分,更不要说它是什么核心。毫不夸张地说,本文所述的内容,包括丢包标记,乱序判断,以及本文没有包括的重传这些,都是给TCP拥塞控制算法擦屁股背锅的,只有严重消化不良且湿气太重的肠胃才需要不停地擦屁股,即便这样也并不意味着最终可以擦得干净!如果拥塞控制足够好,事实上很少会走入这些善后逻辑!
原文链接: https://blog.csdn.net/dog250/article/details/78692585
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍;
也有高质量的技术群,里面有嵌入式、搜广推等BAT大佬

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/407208
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!