
上周的周中,为了回答一位网友的问题,又写了一篇文章(这已经是继TCP FINWAIT2的解释之后接力而写的第四篇了…):
从TCP长肥管道的窗口打开慢的问题看TCP中继的意义:https://blog.csdn.net/dog250/article/details/81295639
其中主要提及了TCP长肥管道(长肥管道即一种BDP的特征)窗口打开慢问题以及一个优化方案。
该文在某日早上分享到了微信朋友圈,一位微信好友随即进行了回复并提出另外一个问题,我让这位朋友把问题详细描述一下然后我看看能不能帮忙分析一下,这位朋友当天晚上微信给我消息,描述了问题以及截图,无奈我看完《闪灵》后就忘记回复了,第二天到了公司做了几个实验,深入分析了一下这个问题,于是就必须将它记录下来了,成就本文。
先从问题开始吧。
经这位朋友同意,我贴出他的原帖:
我测试的时候没有中继,就两个点之间直接用iperf测试,时延500ms和时延100ms,性能差了5倍。
我的理解是tcp没有丢包就一定会跑满带宽。
但结果却不是这样。从tcptrace上看,到后面速度都很稳定

.
s=cwnd/rtt,按道理rtt虽然大,但是cwnd一直再增加,后面tcp的速度肯定会上来的,按照你今天文章讲的 T=log2(BDP)*t,即时BDP再大也不会一分钟都在tcp的慢启动中,为何RTT会影响最终的最大速度呢?一直没想明白。
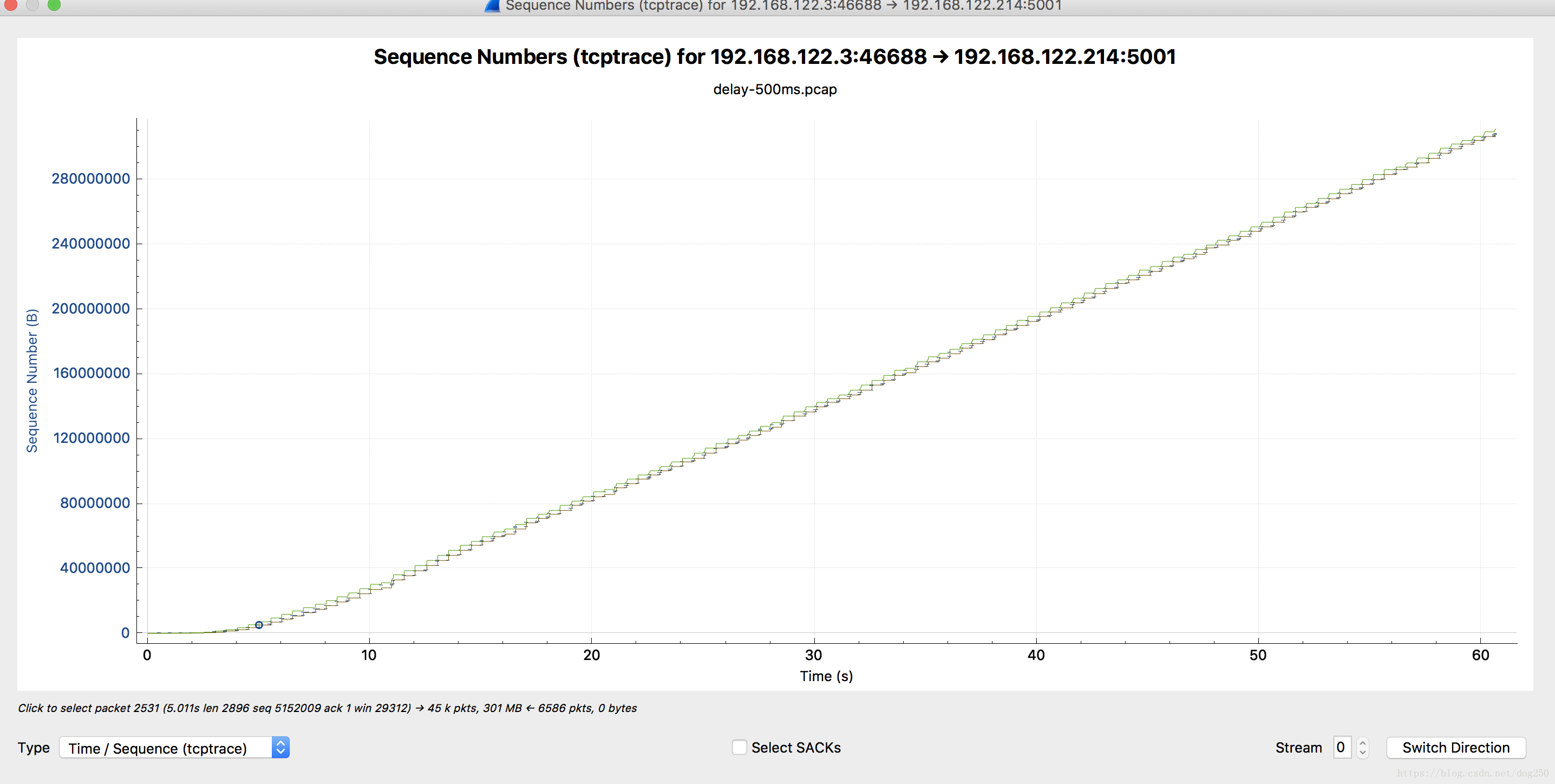
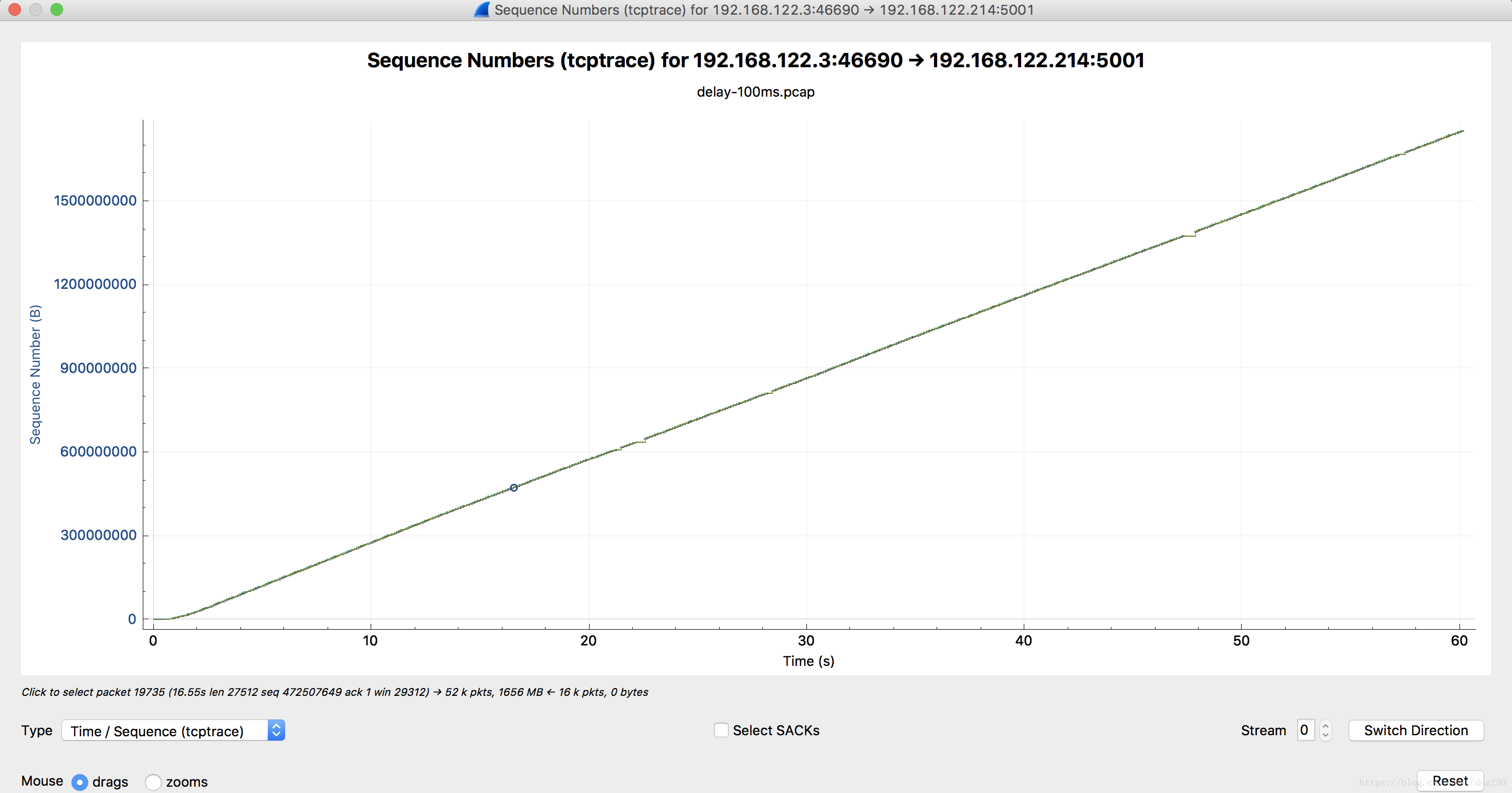
以下是测试拓扑和环境:
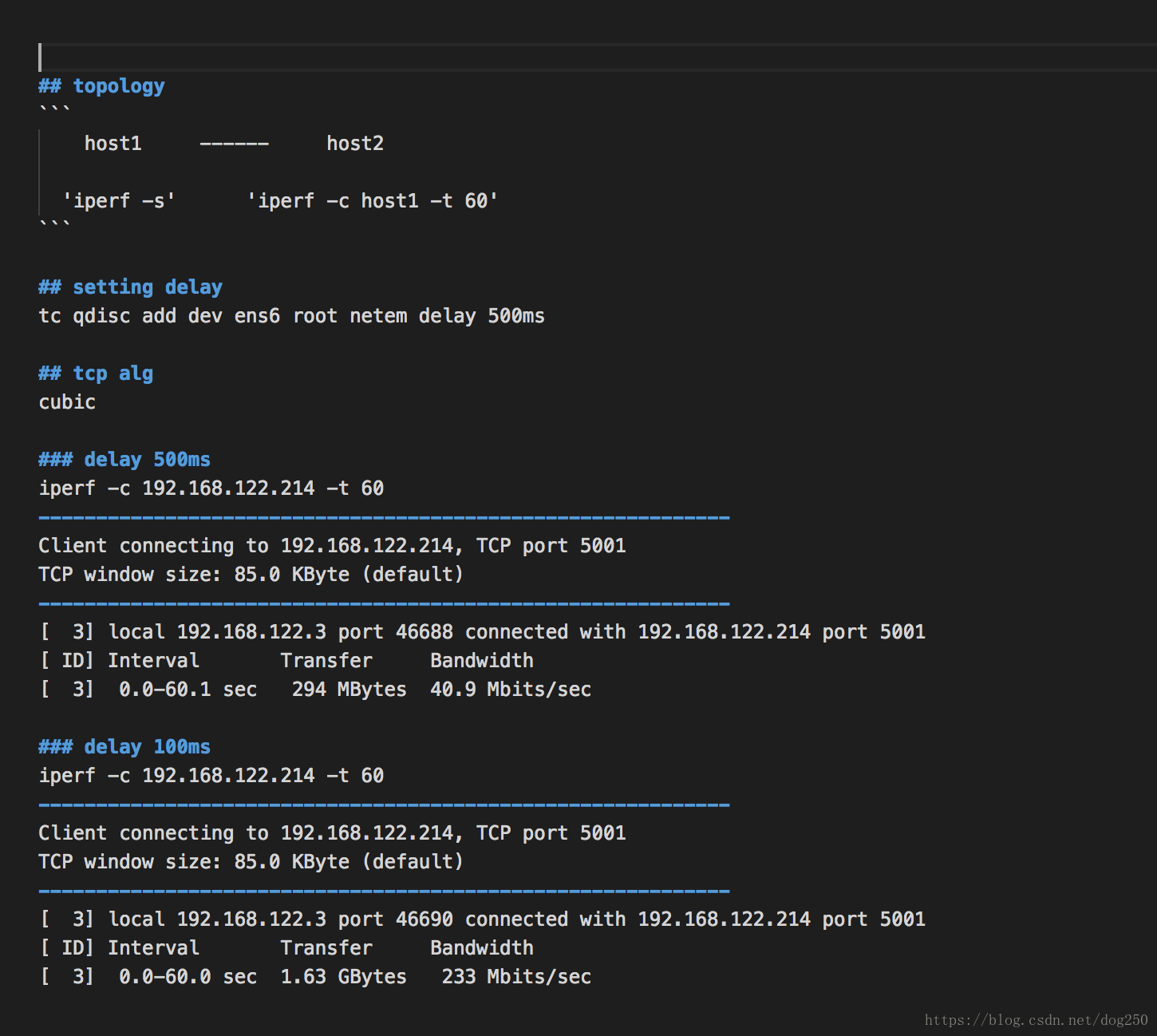
我几乎按照最后一张图的样子搭建了环境进行了测试和分析,得出了相同的结论,这是为什么?
…
这加深了我对TCP的厌恶。我用UDP协议做了相同的测试,结论比较合理,即收包速率和RTT是无关的,带宽和RTT作为正交分量独立起作用,这种结论我当然不能指望iperf3的统计,我是通过sysstat看的。
在数据接收端执行下面的命令分别观察100ms和500ms时的统计数值:
[root@localhost ~]# sar -n DEV 1其中的rxpck/s和rxkB/s,不管你将tc qdisc netem的delay配置成什么,均不会发生变化。这是显而易见的,但是为什么TCP就做不到呢??
为了找出原因,我先将环境理一下,首先要说明的是,用tc qdisc的netem delay配置出来的RTT并不是真的传播时延,而是排队时延,tc是通过排队来模拟传播时延的,即用我所谓的第二类非时间延展的缓存模拟第一类时间延展的缓存。
为什么要说明这一点,因为这会影响到我们对pcap抓包数据的分析。
假设发送端出口网卡是enp0s18(我不明白为什么用这么一个奇怪的名字替换传统的eth0,eth1之类),如果我们在该网卡上配置delay:
tc qdisc add dev enp0s18 root netem delay 100ms limit 100000在发送数据的时候,同时在该网卡上抓包:
tcpdump -i enp0s18 -s 100 -w 100.pcap这样是不妥的!为什么?因为这样你将无法看清发送端的细节,换句话说,由于qdisc作用在抓包之前,所以这样抓取的数据包是延时100ms之后的数据包。所以,为了看清楚延时之前的tcptrace细节,必须按照下面这么做:
brctl addbr br0
brctl addif br0 enp0s18
ifconfig br0 1.1.1.1/24 # 接管enp0s18本来的IP地址
ifconfig enp0s18 0.0.0.0
###
tc qdisc add dev enp0s18 root netem delay 100ms limit 100000
tcpdump -i br0 -s 100 -w 100-br.pcap # 延时之前的细节
tcpdump -i enp0s18 -s 100 -w 100-eth.pcap # 延时之后的细节由于host1和host2处于一个链路上,因此它们之间的传播时延可以忽略不计,因此在延时模拟之后的抓包,即enp0s18这个物理网卡上的抓包可以等效看作是在接收端的抓包。
除了抓包,为了找出速率上不去的原因,我们还需要实时观测TCP连接的拥塞窗口cwnd,而tcpdump所依托的packet socket是无法抓取这个变量的,所以只好用tcpprobe或者systemtap来在tcp_write_xmit之前打印cwnd以及inflight等变量。
我曾经写过一个插件,可以在tcpdump抓包后直接把cwnd这些信息保存下来:
通过tcpdump在抓包的同时获取协议栈信息快照:https://blog.csdn.net/dog250/article/details/53958701
可是用这个有点小题大做了,所以我还是选择使用tcpprobe这种。
万事俱备后,就开始了测试,首先我导出tcpprobe的结果,不管是100ms的延时还是500ms的延时,都有一个偶然的发现:
[80959.419039] ## inflight:959 cwnd:1021 wnd:43171840
[80959.419046] ## inflight:960 cwnd:1021 wnd:43171840
[80959.419052] ## inflight:961 cwnd:1021 wnd:43171840
[80959.419058] ## inflight:962 cwnd:1021 wnd:43171840
[80959.419064] ## inflight:963 cwnd:1021 wnd:43171840 # 止于963
# 上下两行的时间戳,有一个相对比较大的间隔
[80959.502050] ## inflight:633 cwnd:1021 wnd:43450368 # 重新开始
[80959.502087] ## inflight:634 cwnd:1021 wnd:43450368
[80959.502096] ## inflight:635 cwnd:1021 wnd:43450368
...
[80959.504879] ## inflight:957 cwnd:1021 wnd:43450368
[80959.504886] ## inflight:958 cwnd:1021 wnd:43450368
[80959.504893] ## inflight:959 cwnd:1021 wnd:43450368
[80959.504900] ## inflight:960 cwnd:1021 wnd:43450368
[80959.504907] ## inflight:961 cwnd:1021 wnd:43450368
[80959.504914] ## inflight:962 cwnd:1021 wnd:43450368
[80959.504921] ## inflight:963 cwnd:1021 wnd:43450368 # 止于963
# 上下两行的时间戳,有一个相对比较大的间隔
[80959.527252] ## inflight:331 cwnd:1021 wnd:43171840 # 重新开始
[80959.527290] ## inflight:332 cwnd:1021 wnd:43171840
[80959.527299] ## inflight:333 cwnd:1021 wnd:43171840
...
[80961.387295] ## inflight:957 cwnd:1021 wnd:43696128
[80961.387299] ## inflight:958 cwnd:1021 wnd:43696128
[80961.387302] ## inflight:959 cwnd:1021 wnd:43696128
[80961.387305] ## inflight:960 cwnd:1021 wnd:43696128
[80961.387308] ## inflight:961 cwnd:1021 wnd:43696128
[80961.387311] ## inflight:962 cwnd:1021 wnd:43696128
[80961.387315] ## inflight:963 cwnd:1021 wnd:43696128 # 止于963
...这说明发送端只能保持963的inflight,此时无论是拥塞窗口cwnd还是对端通告窗口wnd,均不会构成限制因素,也就是说,拥有足够的发包空间,只是没有包可发了。
非常遗憾,无包可发的原因有很多种,要么是真的没数据了,要么是发送缓冲区空间不足,显然是后者。这里分析一下为什么发送缓冲区空间不足就会造成速率正比于RTT的差异。
还是看tcptrace图:
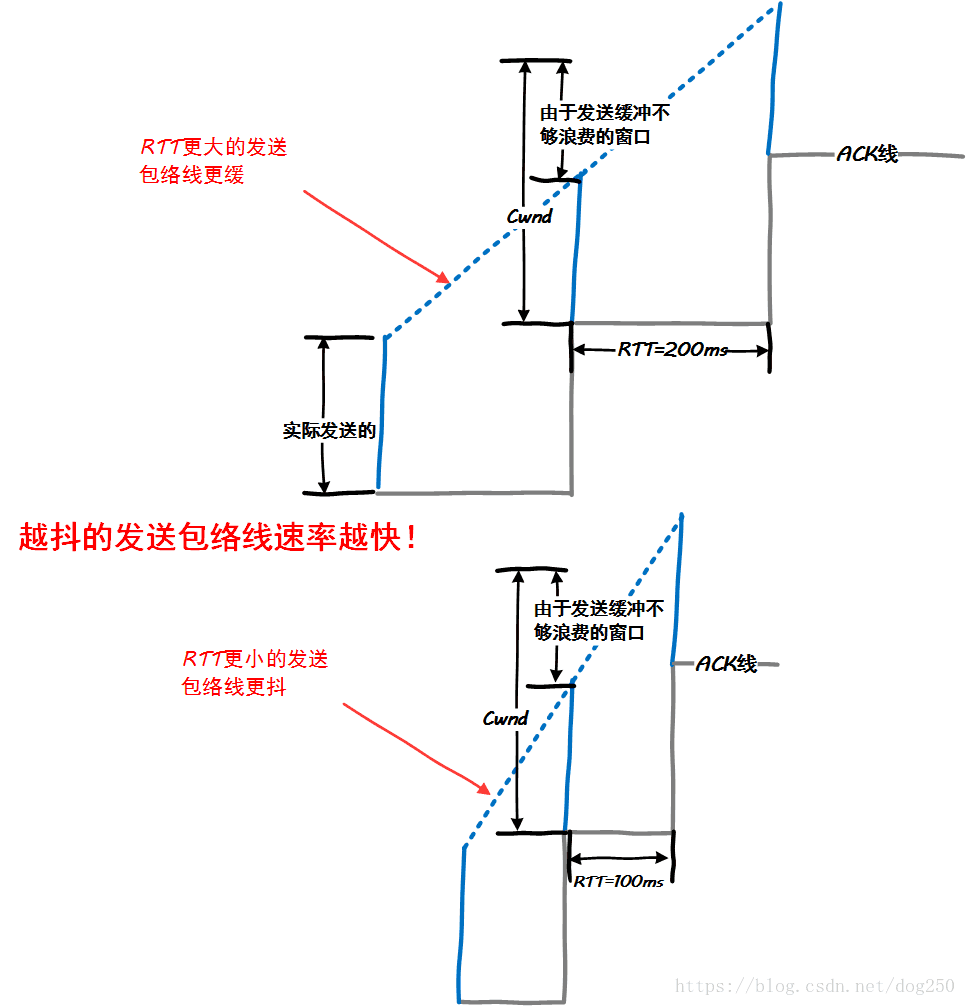
这很好理解,因为TCP数据包在未被确认之前,是不能删除的,它们在发送出去后将继续占用发送缓冲区,只有被确认后才会被清除,而被确认的时间则就是RTT,因此,RTT越小,一窗口数据就越快被清除,从而腾出发送缓冲区,继续发送下一批次的数据!
此乃长肥管道的第一宗罪,长肥管道更容易使发送缓冲区耗尽,且清空时间随着RTT的增加而增加,从而影响单流的传输速率。
好吧,我加大发送缓冲区,接下来请忽略发送缓冲区问题,我将它们扩大了两个数量级。
再来一轮测试,速率总是可以上去了吧,嗯,是的,然而很勉强!
在我的测试环境中,如果是100ms的delay RTT,那么iperf3的结论是:
[ ID] Interval Transfer Bandwidth
[ 4] 0.00-60.17 sec 703 MBytes 93.5 Mbits/sec sender然而用500ms做测试后,并没有达到预期的接近93.5Mbits/sec的速率,而是:
root@debian:~# iperf3 -c 1.1.1.2 -t 60 -l 1048576
Connecting to host 1.1.1.2, port 5201
[ 4] local 1.1.1.1 port 48090 connected to 1.1.1.2 port 5201
[ ID] Interval Transfer Bandwidth Retr Cwnd
[ 4] 0.00-1.00 sec 533 KBytes 4.36 Mbits/sec 0 14.1 KBytes
[ 4] 1.00-2.00 sec 42.4 KBytes 348 Kbits/sec 0 56.6 KBytes
[ 4] 2.00-3.00 sec 170 KBytes 1.39 Mbits/sec 0 226 KBytes
[ 4] 3.00-4.00 sec 1.91 MBytes 16.0 Mbits/sec 0 905 KBytes
[ 4] 4.00-5.00 sec 2.44 MBytes 20.5 Mbits/sec 0 1.13 MBytes
[ 4] 5.00-6.00 sec 2.54 MBytes 21.3 Mbits/sec 0 1.24 MBytes
[ 4] 6.00-7.00 sec 2.80 MBytes 23.5 Mbits/sec 0 1.37 MBytes
[ 4] 7.00-8.00 sec 3.08 MBytes 25.9 Mbits/sec 0 1.51 MBytes
[ 4] 8.00-9.00 sec 3.40 MBytes 28.5 Mbits/sec 0 1.66 MBytes
[ 4] 9.00-10.00 sec 3.75 MBytes 31.4 Mbits/sec 0 1.83 MBytes
[ 4] 10.00-11.00 sec 4.13 MBytes 34.7 Mbits/sec 0 2.02 MBytes
[ 4] 11.00-12.00 sec 4.56 MBytes 38.2 Mbits/sec 0 2.23 MBytes
[ 4] 12.00-13.00 sec 5.03 MBytes 42.2 Mbits/sec 0 2.46 MBytes
[ 4] 13.00-14.00 sec 5.54 MBytes 46.4 Mbits/sec 0 2.71 MBytes
[ 4] 14.00-15.00 sec 6.11 MBytes 51.2 Mbits/sec 0 2.99 MBytes
[ 4] 15.00-16.00 sec 6.73 MBytes 56.5 Mbits/sec 0 3.29 MBytes
[ 4] 16.00-17.00 sec 7.41 MBytes 62.2 Mbits/sec 0 3.63 MBytes
[ 4] 17.00-18.00 sec 7.44 MBytes 62.4 Mbits/sec 0 4.00 MBytes
[ 4] 18.00-19.00 sec 9.65 MBytes 81.0 Mbits/sec 0 4.41 MBytes
[ 4] 19.00-20.00 sec 10.0 MBytes 84.3 Mbits/sec 0 4.86 MBytes
[ 4] 20.00-21.00 sec 9.70 MBytes 81.4 Mbits/sec 114 4.99 MBytes
[ 4] 21.00-22.00 sec 7.07 MBytes 59.2 Mbits/sec 0 3.81 MBytes
[ 4] 22.00-23.00 sec 7.75 MBytes 65.0 Mbits/sec 0 4.10 MBytes
[ 4] 23.00-24.00 sec 8.32 MBytes 69.8 Mbits/sec 0 4.36 MBytes
[ 4] 24.00-25.00 sec 8.84 MBytes 74.2 Mbits/sec 0 4.59 MBytes
[ 4] 25.00-26.00 sec 9.27 MBytes 77.8 Mbits/sec 0 4.77 MBytes
[ 4] 26.00-27.00 sec 9.76 MBytes 81.9 Mbits/sec 0 4.93 MBytes
[ 4] 27.00-28.00 sec 9.58 MBytes 80.3 Mbits/sec 57 4.55 MBytes
[ 4] 28.00-29.00 sec 8.23 MBytes 69.0 Mbits/sec 0 3.62 MBytes
[ 4] 29.00-30.00 sec 7.32 MBytes 61.4 Mbits/sec 0 3.79 MBytes
[ 4] 30.00-31.00 sec 7.64 MBytes 64.1 Mbits/sec 0 3.92 MBytes
[ 4] 31.00-32.00 sec 7.91 MBytes 66.3 Mbits/sec 0 4.03 MBytes
[ 4] 32.00-33.02 sec 8.09 MBytes 66.4 Mbits/sec 0 4.12 MBytes
[ 4] 33.02-34.00 sec 8.26 MBytes 70.8 Mbits/sec 0 4.18 MBytes
[ 4] 34.00-35.00 sec 8.20 MBytes 68.8 Mbits/sec 0 4.22 MBytes
[ 4] 35.00-36.00 sec 8.46 MBytes 71.0 Mbits/sec 0 4.25 MBytes
[ 4] 36.00-37.00 sec 8.51 MBytes 71.3 Mbits/sec 0 4.27 MBytes
[ 4] 37.00-38.00 sec 8.54 MBytes 71.7 Mbits/sec 0 4.28 MBytes
[ 4] 38.00-39.00 sec 8.12 MBytes 68.2 Mbits/sec 0 4.28 MBytes
[ 4] 39.00-40.00 sec 8.55 MBytes 71.7 Mbits/sec 0 4.28 MBytes
[ 4] 40.00-41.00 sec 8.55 MBytes 71.8 Mbits/sec 0 4.28 MBytes
[ 4] 41.00-42.00 sec 8.56 MBytes 71.8 Mbits/sec 0 4.28 MBytes
[ 4] 42.00-43.00 sec 8.58 MBytes 71.9 Mbits/sec 0 4.30 MBytes
[ 4] 43.00-44.00 sec 8.61 MBytes 72.2 Mbits/sec 0 4.33 MBytes
[ 4] 44.00-45.00 sec 8.66 MBytes 72.6 Mbits/sec 0 4.37 MBytes
[ 4] 45.00-46.00 sec 8.76 MBytes 73.5 Mbits/sec 0 4.43 MBytes
[ 4] 46.00-47.00 sec 8.89 MBytes 74.6 Mbits/sec 0 4.51 MBytes
[ 4] 47.00-48.00 sec 8.20 MBytes 68.9 Mbits/sec 0 4.60 MBytes
[ 4] 48.00-49.00 sec 9.28 MBytes 77.6 Mbits/sec 0 4.74 MBytes
[ 4] 49.00-50.00 sec 9.53 MBytes 80.0 Mbits/sec 0 4.90 MBytes
[ 4] 50.00-51.00 sec 9.89 MBytes 82.9 Mbits/sec 0 5.10 MBytes
[ 4] 51.00-52.00 sec 10.3 MBytes 86.5 Mbits/sec 0 5.34 MBytes
[ 4] 52.00-53.00 sec 10.5 MBytes 88.2 Mbits/sec 0 5.61 MBytes
[ 4] 53.00-54.00 sec 11.4 MBytes 95.3 Mbits/sec 0 5.93 MBytes
[ 4] 54.00-55.01 sec 14.5 MBytes 121 Mbits/sec 0 6.30 MBytes
[ 4] 55.01-56.01 sec 12.6 MBytes 105 Mbits/sec 0 6.72 MBytes
[ 4] 56.01-57.00 sec 13.6 MBytes 115 Mbits/sec 0 7.20 MBytes
[ 4] 57.00-58.01 sec 17.6 MBytes 146 Mbits/sec 0 7.75 MBytes
[ 4] 58.01-59.01 sec 15.7 MBytes 133 Mbits/sec 0 8.34 MBytes
[ 4] 59.01-60.17 sec 10.0 MBytes 72.3 Mbits/sec 261 198 KBytes
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bandwidth Retr
[ 4] 0.00-60.17 sec 469 MBytes 65.4 Mbits/sec 432 sender
[ 4] 0.00-60.17 sec 459 MBytes 64.0 Mbits/sec receiver是的,非常不稳定,上下抖动颠簸地厉害。速率非常勉强地达到了比较理想的点,但是只有偶尔几次而已,RTT大的时候,受丢包重传的影响特别大,可以从下面的命令观测到:
root@debian:~# watch -d -n 1 'netstat -st|grep retran'
Every 1.0s: netstat -st|grep retran debian: Fri Aug 3 05:04:26 2018
839456 segments retransmitted # 这个值发生变化时,速率就会陡降
606569 fast retransmits
181232 forward retransmits
51227 retransmits in slow start感性地解释这个问题似乎并不难,以CUBIC为例,在度过慢启动的指数增窗后,后面线性增窗是一个缓慢的过程,即AI过程,然而一旦检测到丢包,将会执行MD,即陡降的过程,这是一个快速降窗的过程,而这么做的目的却无关与性能,而只是为了公平收敛!几十秒的努力,一秒不到就回到了解放前!
你要保证不能丢包,不能重传,更不能超时,一个都不许有…这是相当难的!假设网络链路是均匀同质的,很显然,链路越长,事故的概率就越大,这简直就是一个真理!这将爆发一个正反馈过程,我预期,如果RTT超过一个阈值,即链路长到一定的程度,现有的TCP将完全不可用!
这里再多说几句。
如果是超时重传,那么慢启动过程将会和RTT有非常直接的关系,RTT大的连接显然达到最大带宽的时间越久,总的平均速率也就越低,然而到达拥塞避免阶段后,人们似乎早就在RTT不公平问题上聚焦了很久。
我们知道,在Reno算法时代,拥塞避免的策略非常简单,即每来一个ACK,则增窗1/cwnd,这样每一个RTT就会增窗1,这样太慢了,且RTT不公平,RTT越小,ACK到来的越快,增窗就越快,于是就有了BIC算法,采用了一种二分法来快速探测,然而最后人们发现这同样是RTT不公平的,和Reno的一个问题一样。CUBIC算法解决了BIC的RTT不公平问题:
TCP拥塞控制算法-从BIC到CUBIC:https://blog.csdn.net/dog250/article/details/53013410
也就是说,在发展到CUBIC之后,RTT不公平性已经解决了,一切都是用绝对时间来衡量的,所以说,RTT大的连接和RTT小的连接在拥塞避免增窗这件事上表现是一致的。
然而,我们知道,TCP的拥塞窗口变化完全受到ACK的驱动,CUBIC理论上的公平性并非完美的,TCP拥塞状态机的窗口恢复阶段并非受CUBIC算法的控制(至少Linux内核是这么实现的,比如PRR…),所有的拥塞控制算法都不是在一台数学机器上运行的,总体而言,在窗口恢复阶段,RTT不公平依然存在!
此乃长肥管道的第二宗罪,长肥管道更容易受到丢包以及重传的影响,且RTT越大影响越剧烈,连接性能越脆弱!这一切拜TCP对ACK时钟的依赖所赐,因为ACK时钟本来就是RTT不公平的!
好不容易啊!
我增加了发送缓存,然而还是不行。不过不管怎样,我已经小心翼翼地不让连接丢包了,我改了一些代码让其忽略丢包,即便不考虑代码,原生的CUBIC也能偶尔让带宽跑满,这足以让我忽略问题,相信带宽总是能跑满的,只要时间足够!
好,我假设带宽能跑满,但是还有另一个问题,即长肥管道的第三宗罪,长肥管道会吃掉一部分乃至很大一部分对端的通告窗口!
我早就说过,当发送端收到接收端发来的ACK中携带的通告窗口时,这只是半个RTT之前的接收窗口,并不是当前的!当前的接收窗口可能已经由于用户应用程序在这半个RTT时间中读取而被部分腾空,也就是说,当前的接收窗口要更大一些。
但是大多少呢?这确实取决于对端应用程序的读取速率,这又是一个未知的因素。所以在理论上,我先假设接收端应用程序消费数据的速率是一定的,并且这个速率等于带宽。在这个假设的基础上,我们来看看长肥管道是如何吃掉接收窗口的!
先看一个实验。
还是本文最开始的那个拓扑,为了模拟接收窗口成为限制因素,我关掉了窗口缩放:
net.ipv4.tcp_window_scaling = 0这样一来,接收窗口rwnd将会成为恒定的65160字节(填满16bits)!
我在发送端的br0和enp0s18分别抓取100ms延时之前和之后的数据包,下面是一个tcptrace图的细节,先看延时之前的:
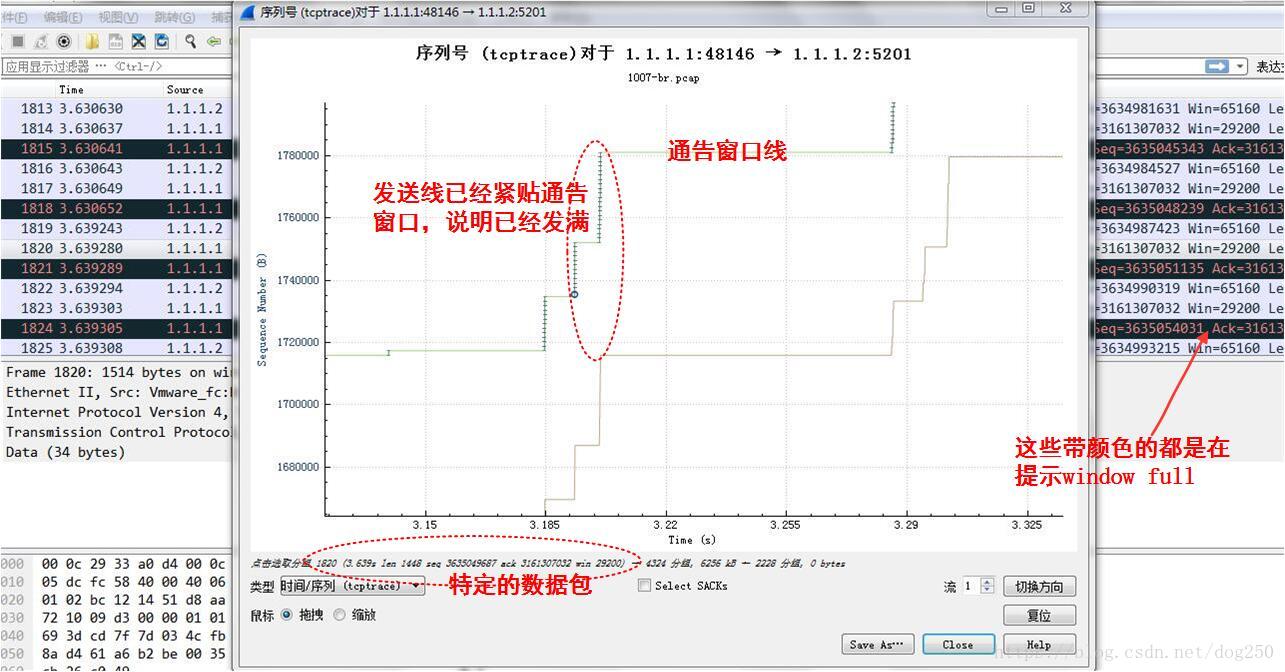
在看一下延时之后的,我们可以将其等效于接收端的tcptrace,毕竟两台直连的虚拟机之间传播时延对RTT的影响是可以忽略的:
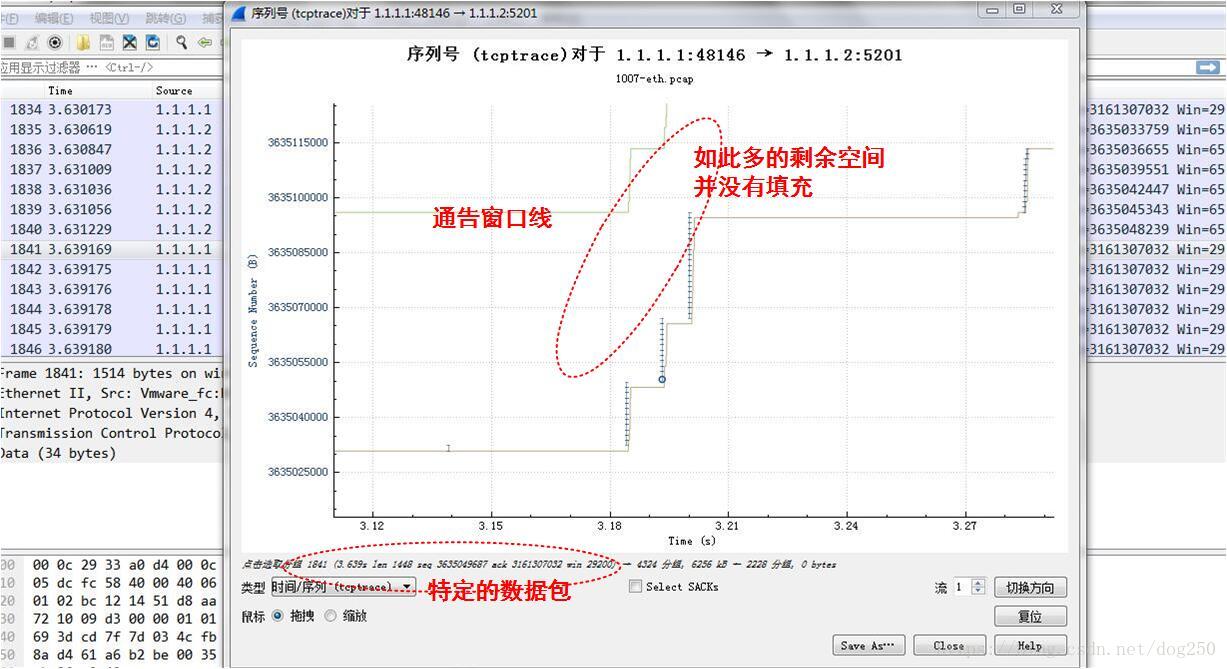
也就是说,在对端通告的接收窗口成为限制条件的情况下,即rwnd
root@debian:/var/log# iperf3 -c 1.1.1.2 -t 10 -l 1048576
Connecting to host 1.1.1.2, port 5201
[ 4] local 1.1.1.1 port 48194 connected to 1.1.1.2 port 5201
[ ID] Interval Transfer Bandwidth Retr Cwnd
[ 4] 0.00-1.00 sec 2.21 MBytes 18.6 Mbits/sec 0 523 KBytes
[ 4] 1.00-2.00 sec 2.55 MBytes 21.4 Mbits/sec 0 523 KBytes
[ 4] 2.00-3.00 sec 2.55 MBytes 21.4 Mbits/sec 0 523 KBytes
[ 4] 3.00-4.00 sec 2.55 MBytes 21.4 Mbits/sec 0 523 KBytes
[ 4] 4.00-5.00 sec 2.54 MBytes 21.3 Mbits/sec 0 523 KBytes
[ 4] 5.00-6.00 sec 2.41 MBytes 20.2 Mbits/sec 0 523 KBytes
[ 4] 6.00-7.00 sec 2.46 MBytes 20.7 Mbits/sec 0 523 KBytes
[ 4] 7.00-8.00 sec 2.53 MBytes 21.2 Mbits/sec 0 523 KBytes
[ 4] 8.00-9.00 sec 2.55 MBytes 21.4 Mbits/sec 0 523 KBytes
[ 4] 9.00-10.00 sec 2.55 MBytes 21.4 Mbits/sec 0 523 KBytes
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bandwidth Retr
[ 4] 0.00-10.00 sec 24.9 MBytes 20.9 Mbits/sec 0 sender
[ 4] 0.00-10.00 sec 24.1 MBytes 20.2 Mbits/sec receiver很不理想,是吗?如前所述,本来这个管道本身就是脆弱的,稍微的丢包都会带来抖动,这会加重接收窗口无法被充分利用的症状。
所以,当接收窗口成为限制因素时,接收窗口需要至少加上一个cwnd的大小(暂不考虑公平性),才能保证管道的满载。在做了这个修改之后,同样的实验,tcptrace图示如下,先给出延时之前的:
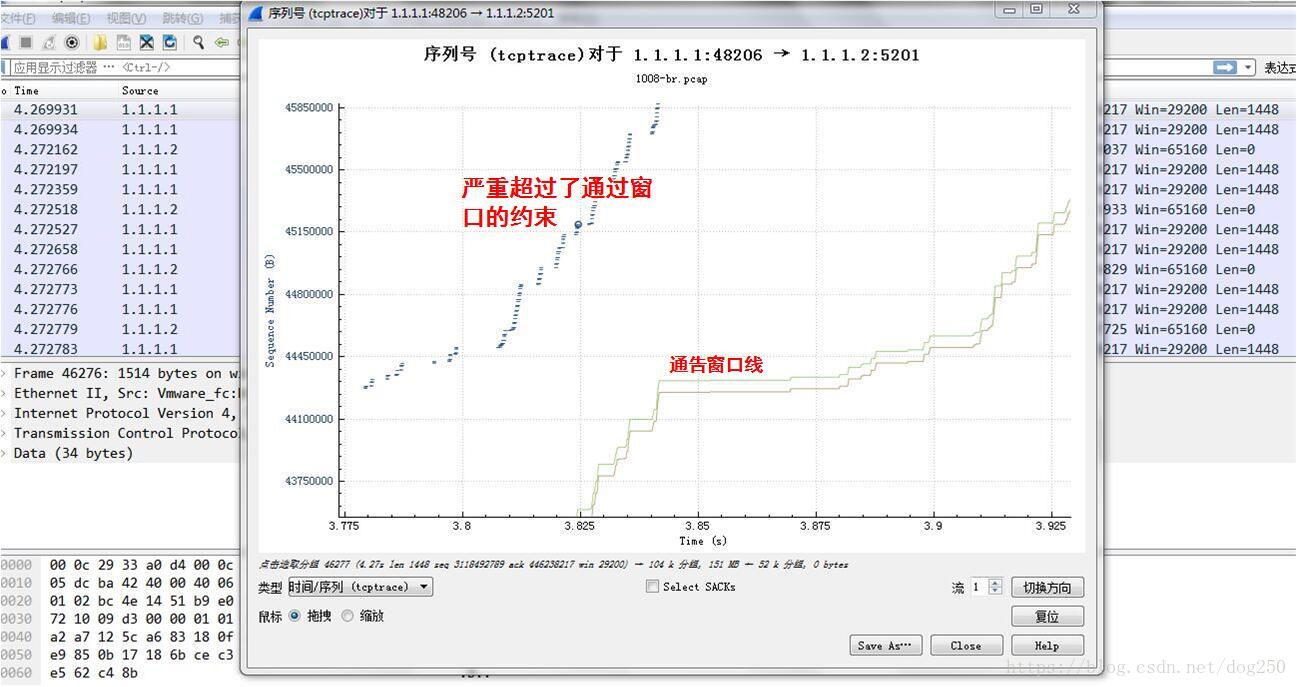
看起来是违规了,但这正是规避了一个TCP缺陷。
由于TCP在设计之初还没有拥塞控制,基于端到端的假设,加之当时的网络环境,数据几乎是立即到达的,或者说当时并没有长肥管道,吃窗口问题并不明显,然而等到有了长肥管道,有了拥塞控制的时候,这么个策略就显得笨拙了。在我改了这个逻辑之后,下面是时延100ms之后的tcptrace局部:
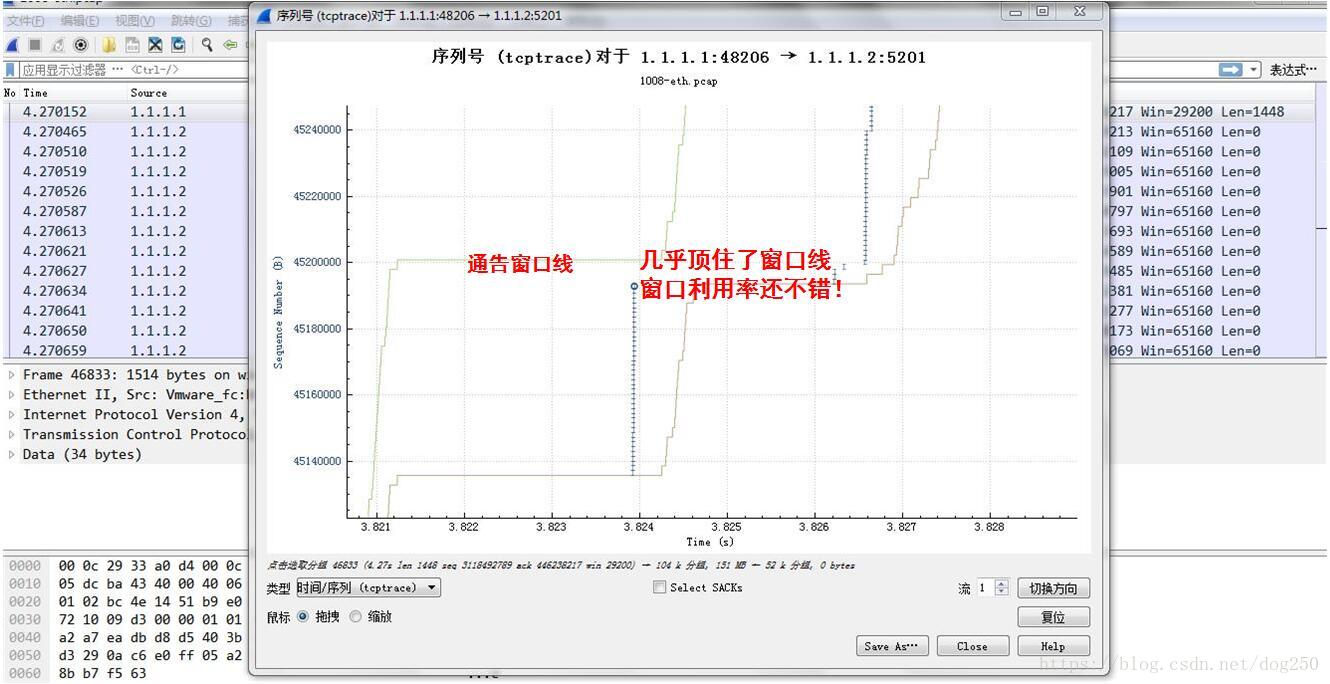
嗯,很不错了。这时的测试数据也变得好看多了:
iperf Done.
root@debian:/var/log# iperf3 -c 1.1.1.2 -t 10 -l 1048576
Connecting to host 1.1.1.2, port 5201
[ 4] local 1.1.1.1 port 48206 connected to 1.1.1.2 port 5201
[ ID] Interval Transfer Bandwidth Retr Cwnd
[ 4] 0.00-1.00 sec 4.87 MBytes 40.8 Mbits/sec 0 1.13 MBytes
[ 4] 1.00-2.00 sec 15.2 MBytes 128 Mbits/sec 0 1.67 MBytes
[ 4] 2.00-3.00 sec 15.9 MBytes 133 Mbits/sec 0 1.67 MBytes
[ 4] 3.00-4.00 sec 15.3 MBytes 128 Mbits/sec 0 1.67 MBytes
[ 4] 4.00-5.00 sec 15.4 MBytes 129 Mbits/sec 0 1.67 MBytes
[ 4] 5.00-6.00 sec 15.4 MBytes 130 Mbits/sec 0 1.67 MBytes
[ 4] 6.00-7.00 sec 15.9 MBytes 133 Mbits/sec 0 1.67 MBytes
[ 4] 7.00-8.00 sec 15.9 MBytes 133 Mbits/sec 0 1.67 MBytes
[ 4] 8.00-9.00 sec 14.9 MBytes 125 Mbits/sec 0 1.67 MBytes
[ 4] 9.00-10.00 sec 15.7 MBytes 132 Mbits/sec 0 1.67 MBytes
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bandwidth Retr
[ 4] 0.00-10.00 sec 145 MBytes 121 Mbits/sec 0 sender然而,如此明显的优化,为什么30多年以来TCP始终视而不见呢?
请注意我的假设,即应用程序对数据的消费速率等于网络带宽,这是一个理想情况下的平滑管道,一直以来在现实中往往并不存在,应用程序消费数据的速率往往受到接收端主机多种因素的影响,比如内存,调度,进程IO等待等等,一旦假设条件不满足,比如数据消费的速率小于网络带宽,将会造成接收缓存数据堆积而丢包,这势必会造成发送端的重传,一切貌似又回到了原点!
因此,将接收缓存和BDP管道统一考虑的策略除了在实验环境下,并不是特别具有吸引力,不过你要记住的是,拥塞控制和流量控制确实是独立控制TCP流量发送的,二者确实是相互影响的,不把它们统一考虑,是有问题的,这是目前还没有比较好的方案去解决这个问题而已。
一个很直接的设想,那就是增加一个TCP option,ACK返回发送端时携带接收端当前应用消费数据的速率(依然是半个RTT以前的速率)….
长肥管道的三宗罪已经完全在案。不错的周六早晨!
最后临近尾声,我来说一下网络丢包如何影响滑动窗口向前滑动,进而如何造成发送端窗口损耗而影响速率。
在RACK以前,TCP的重传方案如下:
- 快速重传只将判定为LOST的数据包标记一次,因此只重传一次;
- 在丢包率高的情况下,始终不成功的完全重传终将造成RTO;
- 始终不成功的重传造成接收端数据空洞无法弥补,队头拥塞;
- 队头拥塞造成滑动窗口停滞无法前行;
- RTO或者滑动窗口阻滞最终将连接拉回慢启动;
- 慢启动对速率的影响是巨大的且和RTT强相关!
一个悲哀的故事。
说了这么多,解决方案是什么?
还是如我上文中所说的,用TCP中继或者类似的CDN技术,尽可能让TCP端到端的距离缩短,减少RTT。不要使用长肥管道!!!
如果说TCP in TCP会造成崩溃正反馈的话,那么TCP back-to-back则会即时将网络快照负反馈给发送端即时调整,一纵一横的效果截然相反!
周六的早晨,写完这篇后,准备再睡一下…今天下午小小要去欧洲旅行了,一个我内心向往已久的伟大的地方,很是激动不已。
原文链接: https://blog.csdn.net/dog250/article/details/81393009
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍;
也有高质量的技术群,里面有嵌入式、搜广推等BAT大佬

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/406791
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!