
我讨厌TCP。但是我的工作中总是要接触TCP!
近期三四个礼拜,接连碰到三三两两TCP的问题,这些都无关拥塞控制,这些都是状态机方面的问题,但无论怎样,我是非常讨厌的,以至于恶心,我释放大量的感情色彩在TCP协议…
但这不能否认我对TCP的理解以及对其性情的掌握已经超出了大多数人,我在咒骂中成长。我咒骂着TCP,同时也可能被别人鄙视着…那就来吧。
本周本来不想写技术文章的,很多的pending的事情尘埃落定,我想干点别的,我哪能有心思搞什么我最烦的TCP!然而非也…
除了我最烦的TCP,我还能搞什么?无路可走!不如再写一些感悟,期待能帮助一些需要帮助的人。
那就再说说TCP吧。
首先我们来看RFC793上标准的TCP状态图:
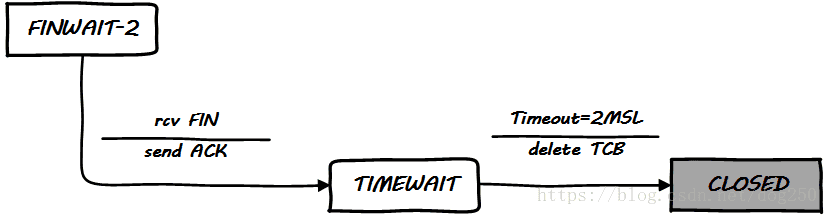

再看一下这个标准RFC的状态图中潜在的风险:
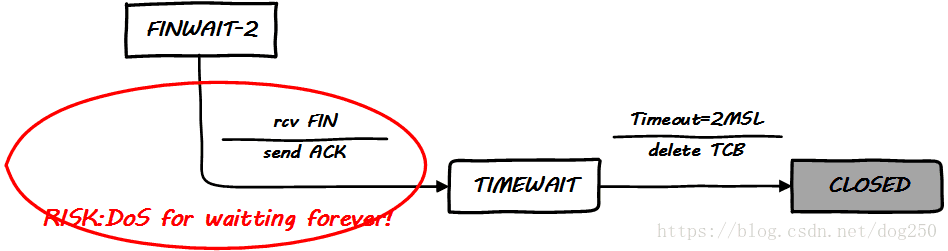
标准归标准,实现归实现。
标准需要完成一个闭环,而实现则要兼顾各种限制条件。在TCP状态机上看,RFC793实现了单一CLOSED出口,虽然TIMEWAIT状态本身就不完美,但至少它是主动关闭方唯一的出口。然而如图所示,在实现上,这里会遇到潜在的DoS风险,如何规避这个风险呢?
Linux内核TCP实现是这么做的:

你可以说,这个状态机违反了RFC793所述原汁原味的全双工独立控制的TCP协议。是的,它违反了,有谁规定我不能单独关闭一个方向的数据传输而在另一个方向继续呢?
然而,事实上没有人这么做,没有人单独关闭一个方向的数据传输,当你关闭一个方向的数据传输时,潜规则是,告诉对方,你也关闭吧。如果你真的想关闭一个方向的数据传输,你不发任何数据便是,事实上很多协议不都是单方向传输数据的吗?比如文件下载,除了一开始的几个交互外,后续几乎就是单方向的。
历史地看问题,在1970-1980年代,人们认为交互会被平等的分为两类,以Telnet双向交互和文件下载准单向传输为代表,如此环境设计出来的TCP协议,当然要让二者平分秋色了。可以说,应用模式的事情,TCP帮着做了太多。
TCP过渡设计了。
到了1990年代,一直持续到21世纪,Linux时代和TCP/IP初上舞台的时代已经有大不同。此时人们根据现实的要求,不光要兼顾应用对传输协议的使用,还要应对公共无界无障碍的Internet上的各种攻击,当人们认识到现实的攻击带来的危害其影响远重要于理论上的闭环自洽的时候,这个状态机就被改变了,至少是在Linux内核是被改变了。
这里不得不闲扯几句。
被改变的不止TCP的状态机,还包括TCP Timewait的时间,不再是RFC所说的2MSL即120秒,而是简单的60秒,为什么?因为这会在不伤大雅的情况下,节省资源!
在Linux内核inet_twsk_schedule函数中,有下面的注释请阅读:
/* timeout := RTO * 3.5
*
* 3.5 = 1+2+0.5 to wait for two retransmits.
*
* RATIONALE: if FIN arrived and we entered TIME-WAIT state,
* our ACK acking that FIN can be lost. If N subsequent retransmitted
* FINs (or previous seqments) are lost (probability of such event
* is p^(N+1), where p is probability to lose single packet and
* time to detect the loss is about RTO*(2^N - 1) with exponential
* backoff). Normal timewait length is calculated so, that we
* waited at least for one retransmitted FIN (maximal RTO is 120sec).
* [ BTW Linux. following BSD, violates this requirement waiting
* only for 60sec, we should wait at least for 240 secs.
* Well, 240 consumes too much of resources 8)
* ]
* This interval is not reduced to catch old duplicate and
* responces to our wandering segments living for two MSLs.
* However, if we use PAWS to detect
* old duplicates, we can reduce the interval to bounds required
* by RTO, rather than MSL. So, if peer understands PAWS, we
* kill tw bucket after 3.5*RTO (it is important that this number
* is greater than TS tick!) and detect old duplicates with help
* of PAWS.
*/
同时,如果你看HTTP的标准的话,也是没有规定HTTP头部的长度,然而这会让Web服务器端在读到rnrn之前不断的执行malloc-strncpy循环,这会耗尽服务器的内存,于是在实现上,Web服务器会对HTTP头长度进行限制!
理论上的分析应该可以到底为止了。在具体的实现上,如果你撸代码的话,还是有不少难以用文字表达的trick。
首先我们简单想一下,Linux会为每一个进入finwait2状态或者timewait状态的socket都启动一个timer来计时吗?非也。同样的设计和TCP不会为每一个数据包启动一个重传定时器一样。
最直观的解法就是,将进入timewait的TCP socket按照进入timewait时间点的FIFO原则排队,仅仅启动一个timer,设置队头的timewait到期时间为timer到期的时间。这是Linux内核标准的实现方式。
然而这里面的trick在于,Linux对finwait2状态的实现和timewait的实现进行了复用,这个在代码的清晰度上减了分。
具体来讲,Linux内核用tcp_time_wait一个函数,实现了两个状态:
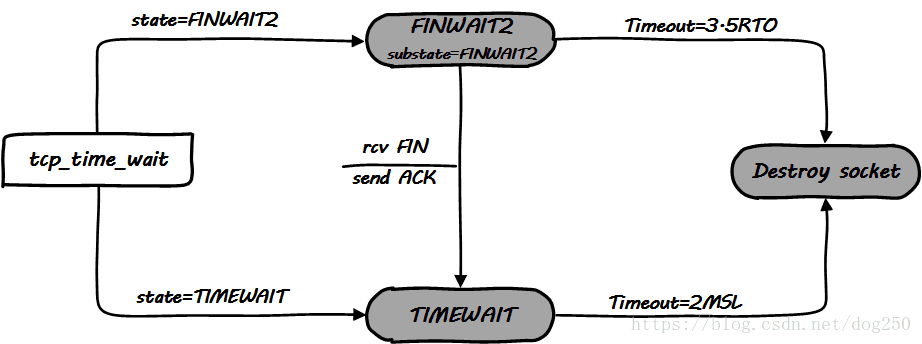
请撸下面的代码:
/*
* Move a socket to time-wait or dead fin-wait-2 state.
*/
void tcp_time_wait(struct sock *sk, int state, int timeo)
{
...
if (tcp_death_row.sysctl_tw_recycle && tp->rx_opt.ts_recent_stamp)
recycle_ok = tcp_remember_stamp(sk); // trick!!
...
if (tw != NULL) {
...
/* Get the TIME_WAIT timeout firing. */
if (timeo < rto)
timeo = rto;
if (recycle_ok) {
tw->tw_timeout = rto; // about 3.5 rto
} else {
tw->tw_timeout = TCP_TIMEWAIT_LEN;
if (state == TCP_TIME_WAIT)
timeo = TCP_TIMEWAIT_LEN;
}
// 事实上是两类timer:
// 1. 标准的TIMEWAIT-TIMEOUT=60ms的timer
// 2. 非标准的TIMEOUT=3.5RTO的TIMER
inet_twsk_schedule(tw, &tcp_death_row, timeo,
TCP_TIMEWAIT_LEN);
inet_twsk_put(tw);
} else {
...
}
...
}你以为这就结束了吗?非也。
我想表达的是Linux在实现TCP timewait的时候,它真的是能预先判定什么情况下可以违背一点规则。就比如说,什么情况下可以让一个处于timewait状态的TCP连接不在那个状态待60秒(已经是一个违反原则的优化后的值了),而是可以马上释放。
用什么可以check?答案是PAWS!具体详见我在很久以前写的一篇文章,必须看哦:
TCP的TIME_WAIT快速回收与重用:https://blog.csdn.net/dog250/article/details/13760985
有理论分析,有实验,没有代码…不过我觉得2013年的文章(并不严谨,但就是那个意思),还可以了,当时我记得是同事北京出差回来,一个问题没有搞定在讨论,当时大家叫我老湿,同时大家的讨论也被我听到了,我当时也不知道到底为什么,后来大家把这个问题淡化以后,我默默做了几个实验,终于明白了原因…事后就写了上面那篇文章。
一直以来,我都是很讨厌TCP的,但是我就是可以搞定TCP的任何问题,上天作弄!
现在来看Linux关于PAWS的优化。
摘录一段上述我自己在2013年写的文章的一个段落:
于是需要有一定的手段避免这些危险。什么手段呢?虽然曾经连接的tuple信息没有了,但是在IP层还可以保存一个peer信息,注意这个信息不单单是用于TCP这个四层协议的,路由逻辑也会使用它,其字段包括但不限于:
对端IP地址
peer最后一次被TCP触摸到的时间戳
…
在快速释放掉TIME_WAIT连接之后,peer依然保留着。丢失的仅仅是端口信息。不过有了peer的IP地址信息以及TCP最后一次触摸它的时间戳就足够了,TCP规范给出一个优化,即一个新的连接除了同时触犯了以下几点,其它的均可以快速接入,即使它本应该处在TIME_WAIT状态(但是被即快速回收了):
1.来自同一台机器的TCP连接携带时间戳;
2.之前同一台peer机器(仅仅识别IP地址,因为连接被快速释放了,没了端口信息)的某个TCP数据在MSL秒之内到过本机;
3.新连接的时间戳小于peer机器上次TCP到来时的时间戳,且差值大于重放窗口戳。
同时满足上述3个条件,方可拒绝一个连接,否则,即便一个timewait还没有结束的连接也依然可以被重用(前提是你要打开tw reuse这个sysctl参数)
我曾经想过,为什么这个优化没有写在TCP的RFC中。
因为你可以看到,这个优化完全基于IP层dst_entry,完全基于peer这个IP层的东西,如果要设计一个协议的话,是绝对不应该依赖其它的层级的,也就是说,你设计的协议越闭环越好,越不依赖别的层级越好!
然而,在实现上,那就没有限制了。在Linux内核中,到处都有这些违法原则的实现。也许吧,Linux是一个宏内核,什么东西都懂…
好了,我总结有三:
- Linux TCP的timewait超时60秒
- Linux TCP的finwait2和timewait共用一套实现
- Linux TCP状态机有大不同
- Linux TCP针对PAWS是依赖IP层的
- …
这周末本来不想写技术文章的,但今日深圳大雨到暴雨,后半夜无眠,听雨作文,成就这篇!其实我本来是想写一篇文章抨击一下戾气或者说杠精,然而在我自己获得认可之后,所有的戾气突然间成了美好,我也就没有什么好抨击的了,只有感激。
PS:温州皮鞋厂老板(这是我的朋友,一个真实的人,不是虚构的)终于AT要成功了,我当然很欣慰。然而这也意味着温州皮鞋厂老板再一次离我而去…这我很伤心。
接下来还想喷一下burst和pacing,有谁前来讨论吗?哈哈。。。
原文链接: https://blog.csdn.net/dog250/article/details/81582604
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍;
也有高质量的技术群,里面有嵌入式、搜广推等BAT大佬

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/406783
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!