
zhejiang wenzhou skinshoe wet, rain flooding water will not fat!
果真,仅仅理解hotpatch的原理,而不实战的话,只能写出玩具。细节的处理非常麻烦。
本文是下面两篇文章的续集:
Linux内核如何替换内核函数并调用原始函数:https://blog.csdn.net/dog250/article/details/84201114
x86_64运行时动态替换函数的hotpatch机制:https://blog.csdn.net/dog250/article/details/84258601
如果说一个内核函数的hotpatch是用一个模块实现的(这几乎是一定的,不然还能怎样?),那么这个模块在卸载时需要做什么就是必须要考虑的问题。
最近几年,我经常遇到卸载模块发生panic的问题,很多是hook段被释放,系统跑飞导致,这是一个非常令人蛋疼的问题,如果程序段本身就不是你能控制的,那么什么锁机制都无法做好同步,非常恶心的一件事。
我们先来看一个序列:
EIP
|
|
v
CPU0:----hooked_func call------------------hooked_func exit-----> time
CPU1:-----------------------hook unload-------------------------> time
嗯,是的,在hook函数正在执行的时候,将其二进制代码卸载,系统就会跑飞,这是显而易见的,毕竟内存都释放了,取指的结果是不确定的。
怎么办?
我在做这个hotpatch之前就曾提出过一个问题,就在我们把一个原始函数的头5个字节替换成相对地址jump的时候,如果有一个task正在执行这5个字节的指令,会发生什么?毕竟我们知道memcpy一下子拷贝5个字节的内存,这并不是原子的操作,那么结果很明显,程序会跑飞。
后来我明白Linux内核并不是简单使用memcpy来实现指令替换的,而是使用了text_poke_smp这个函数。看了text_poke_smp的实现,发现其中的妙招在于 把memcpy作为stop_machine的一个回调函数来调用 ,便 部分地解决了这个问题。请注意,是部分的!
stop_machine在调用其回调函数时,只能保证当前整个系统中只有当前CPU的当前一个执行绪,其它的CPU全部处在停机状态。因此如果其它CPU上的执行绪在未完成被hook函数的前5个字节前被停机,等到系统resume后,还是会有问题,换句话说,stop_machine调用并不解决 原子patch 问题!
不管是hook一个函数,还是unhook一个函数,都会出现 如果Action的时候,有执行绪正在执行怎么办? 这样的棘手问题。本文试图讨论一下这个问题的解法。
不管是hook还是unhook,其本质都是一个内存指令替换操作,正规的符合常理的做法,应该执行下面的逻辑:
int OK = 0;
static int hotpatch_poke_test_and_poke(...)
{
char stack[INFO_SIZE];
hotpatch_dump_stack(stack); // 获取当前的所有CPU的栈信息
if (strstr(stack, hook->function_name)) {
// 如果有CPU的栈上有被hook/unhook函数的符号名称
// 说明有CPU正在执行该函数,直接返回。
return 0;
}
// 否则,说明没有CPU上的线程在执行被hook/unhook函数,执行指令替换。
OK = 1;
memcpy(....);
return 0;
}
static void hotpatch_poke_text(...)
{
while (!OK) { // 若未成功,则稍后再试一下。
stop_machine(hotpatch_poke_test_and_poke, ...);
cpu_relax();
}
}
hotpatch_poke_text总是不返回的概率随着被hook/unhook函数的调用频率的升高而升高,而这个同样正比于CPU的核心数量,因此这种方法是不可扩展的,non scaleable的。
更加不幸的是,如果所有的CPU发生了 全局同步 ,被hook/unhook的函数在各个CPU上被back-to-back调用,即
C
P
U
n
CPU_n
CPUn上还没出来,
C
P
U
n
+
1
CPU_{n+1}
CPUn+1上又进去了,就比较悲哀了,hotpatch_poke_text将永远也出不来了。
显然,我们需要一个 更好 的方案,来解决这个让人蛋疼的问题。
更好的方法就是:
- 不让人将模块卸载
这很容易实现,将module_exit函数删除即可。
但是这种oneshot的方法根本就不优雅,不是一个技术洁癖患者的做派。
想了好久,在回深圳探亲返程的飞机上,想到一个方案(最后我同样否决了这个方案,但是看看过程也不错!)。本文接下来就说说这个方案。
把我推荐进厂的哥们儿告诉我Linux的kprobe在x86平台可以被优化成 relative jump 的方法,而不使用耗时的 int 3 机制。所谓的relative jump方案,其实就是我使用的hook的方案, 将函数的某些字节替换成jmp指令 ,但是这里,我恰恰要借用一下非优化版本的 int 3 方案。
我们先来看看int 3的kprobe机制。
非常简单,看下面的逻辑,我将Linux内核的kprobe机制做了一定的简化:
struct kprobe {
char *name; // 函数名称
void *addr; //函数开始地址
u8 inst; // 函数指令的第一个字节
handle_t pre_hook(struct kprobe *p, ...); // 前处理hook
handle_t post_hook(struct kprobe *p, ...); // 后处理hook
struct list_head list;
};
char int3[1] = {0xcc};
int register(struct kprobe *p)
{
p->addr = find_symbol(p->name);
list_add(&p->list, &probe_list);
p->inst = p->addr[0];
*(p->addr[0]) = int3[0]; // 单字节原子赋值操作
return 0;
}
// 执行int 3指令时,发生异常,陷入异常处理程序。
do_int3(char *addr...)
{
struct kprobe *probe, *p;
...
// 根据异常地址找到kprobe结构体
list_for_each(...) {
p = container_of(...);
...
if (addr == p->addr)
probe = p;
break;
}
// 调用前处理函数
probe->pre_hook(probe, ...);
// 恢复IP为function的原始指令,这样在int 3返回时就可以继续执行原始逻辑了
regs->eip = probe->inst;
...
}
可见,kprobe的int3机制非常简单直接,毫不依赖其它的数据和代码,仅仅单字节的int3指令,即0xcc就能搞定一切,其妙处在于:
- 注册kprobe的时候,将整个结构体注册在了一个全局链表中;
- 在int 3的异常处理中,能通过出现异常的addr从全局链表中找到kprobe结构图;
- 从找到的kprobe结构体中可以找到被替换成int3的原始指令;
- 在执行完pre_hook之后,可以用原始指令恢复已经由于int3异常压栈的EIP寄存器;
整个过程一气呵成,如果说它效率低,原因不外乎下面的两点:
- 有两次上下文切换动作,伴随的是一系列的压栈,弹出,刷cache的动作;
- 有链表遍历操作,伴随这lock以及可扩展性问题。
然而正是这两点让我们可以轻松利用kprobe的无依赖特性,世界是和谐的。
现在,让我们看看到底应该怎么做。
static int hold(...)
{
read_lock(&hook_lock);
return 0;
}
static int release(...)
{
read_unlock(&hook_lock);
return 0;
}
struct kprobe probe = {
.name = "function",
.pre_hook = hold,
.post_hook = release,
};
static void hotpatch_poke_text(...)
{
register(&probe); // 借用kprobe的pre/post机制
write_lock(&hook_lock);
if (hook) {
// 备份指令 (注意,不能截断指令~)
memcpy(saved_inst, probe.addr, HOOK_SIZE);
// 安全替换
memcpy(probe.addr, jump_inst, HOOK_SIZE);
// 用新替换后的指令重置probe结构体的字段
probe.inst = probe.addr[0];
// 防止替换操作将借用的int3指令冲刷掉,手工修改
*(probe.addr[0]) = int3[0];
} else if(unhook) {
// 安全恢复!
memcpy(probe.addr, saved_inst, HOOK_SIZE);
// 用新替换后的指令重置probe结构体的字段
probe.inst = probe.addr[0];
// 防止替换操作将借用的int3指令冲刷掉,手工修改
*(probe.addr[0]) = int3[0];
}
write_unlock(&hook_lock);
unregister(&probe); // kprobe功成身退,卸载kprobe
}
很直白的序列:
- 用int3替换被hook/unhook函数的第一个字节,同时注册kprobe;
- pre处理中获取read lock,post处理中释放read lock;
- hook或者unhook操作中,获取write lock,此时只要有thread仍在函数中,就会等待;
- 在hook/unhook获取到write lock后,只要有thread需要进入function,就会等待在read lock上;
- 如果hook/unhook释放了write lock,等待在read lock上的thread进入function,然而由于已经修改了inst,它将进入到被成功hook或者unhook的function中!
这其实是一个典型的RCU场景,我却没有用内核提供的RCU机制,挺可笑的。其实在这里使用现成的RCU是有问题的,你可能会觉得使用RCU的版本会是下面的样子:
void rcu_callback()
{
if (hook) {
// 备份指令 (注意,不能截断指令~)
memcpy(saved_inst, probe.addr, HOOK_SIZE);
// 安全替换
memcpy(probe.addr, jump_inst, HOOK_SIZE);
// 用新替换后的指令重置probe结构体的字段
probe.inst = probe.addr[0];
// 防止替换操作将借用的int3指令冲刷掉,手工修改
*(probe.addr[0]) = int3[0];
} else if(unhook) {
// 安全恢复!
memcpy(probe.addr, saved_inst, HOOK_SIZE);
// 用新替换后的指令重置probe结构体的字段
probe.inst = probe.addr[0];
// 防止替换操作将借用的int3指令冲刷掉,手工修改
*(probe.addr[0]) = int3[0];
}
}
static void hotpatch_poke_text(...)
{
register(&probe); // 借用kprobe的pre/post机制
call_rcu(..., rcu_callback); // 时间点T调用!
sync_rcu();
unregister(&probe); // kprobe功成身退,卸载kprobe
}
这其实是不对的,call_rcu只能保证在时间点T所有在function中的thread全体出来后调用指令替换,但是不能保证在时间点T之后没有新的thread会进入到function,所有RCU用了也是白用!
这里的关键点有两个,我们希望能有两道防护:
- 确保在一个时间点T之后所有新的thread不再进入function;
- 确保在另一个时间点T+n后没有thread在function中。
既然我们无法保证上述第1点(比如你hook了do_fork函数…),那么就只能忙等第2点成真了。
其实,说了这么多,总结下来,我感觉这篇文章白写了,因为我发现这个 最终的所谓的更好的方案,其实和那个最开始的stop_machine是一样的!!无非就是用write_lock替换了stop_machine,本质上都是要保证在执行替换指令的时候,没有thread在被替换指令的函数中,不同的是,stop_machine方案采用自定义忙等的方法,而rwlock则使用了读写锁机制。
因此读写锁的方案也会遇到全局同步的问题。
都是一样的,没意思!
涉及到细节的时候,总是会遇到二八大法,一个玩具只有成品的20%不到的代码,甚至10%以内,然而最终上线的成品却要多出80%到90%的代码去处理这些边边角角的异常问题。
做产品和做技术预研是完全不同的,同样,学术界的和工程界的代码也是完全不同的。
还有更多的细节,不能在本文一一列举,这里只解释一个。
Intel的跳转指令很少用到 长跳转, 一般都是16bit,8bit的跳转,甚至32bit的跳转都很罕见,Intel给出的解释大致是 程序一般都很小,且具有局部性聚集特征, 但无论如何,Intel还是提供了32bit和64bit的跳转机制,其中32bit的跳转如下:
0xe9 addr[0...7] addr[8...15] addr[16...23] addr[24...31]; jump $relative_address
而64bit的跳转指令如下:
0x48 0xb8 addr[0...63]; mov rax $absolute_address
0xff 0xe0; jmp raw
显然,32bit的跳转更加好用,而这并不是每次都能用的。
如果说你的hook函数和原始的函数真的距离比较远,那就没法用32bit跳转了,具体来讲就是超过了2G的空间距离,这是因为32bit寻址4G的空间,而jmp指令可以前后跳转,因此relative address是一个singed int型的32bit数字,有符号的,可正可负。所以说0xe9 jmp指令只能往前后2G的范围内跳转。
内核模块里的函数地址和kernel函数之间的距离很多都超过了2G,所以就必须使用12字节的绝对地址跳转序列,那么就相当于要在函数的开头至少覆盖12字节的指令。
此外,注意rax寄存器的使用。如果hook函数里使用了rax寄存器,那么当心这里有被覆盖的风险。谢天谢地,这里只是函数的开头,而Intel规定的传参寄存器里并没有使用rax,见这张图:
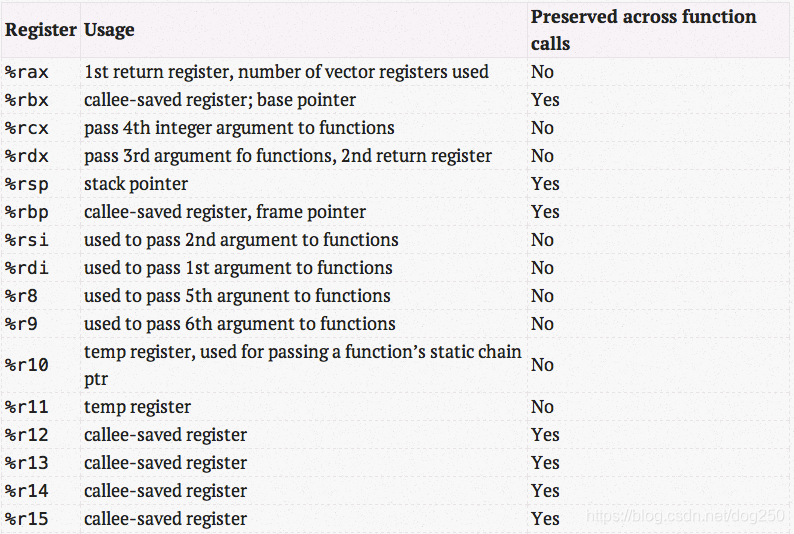

所以这个绝对地址跳转并不会带来副作用。如果是想hook函数中间的逻辑,就要势必考虑rax寄存器的改变带来的影响。
本文完!
短短不到两天时间,还没跟小小多说几句话,又要赶回杭州工作,但如果不需要上班又会觉得无聊。
人本来就应该不断迁徙的,不能一直在一个地方。移民不是目标,移民只是一个过程,现代交通,通信,物流以及国际准入逐渐发达,当迁徙不再是一种有钱人的特权或者穷人迫不得已的无奈时,我们应该享受怎样的人生呢?
矛盾,虚伪,贪婪,欺骗,幻想,疑惑,简单,善变。
我们应该明白,天长地久不过是个谎言,聚散离合不断的上演。。。
昨天小小演讲比赛获了奖,讲着讲着把自己给讲哭了,代入感极强,真性情,所以我每次走时都不跟小小告别,不然她肯定会舍不得,会哭。
小小是上辈子辜负的情人,这辈子有缘再续前缘,感谢上天的恩赐!?
男人有个女儿是多么幸福的事情,可以公开光明正大的对除了老婆之外的第二个女人表达真爱,多么幸福!
非常想小小!
浙江温州皮鞋湿,下雨进水不会胖!
原文链接: https://blog.csdn.net/dog250/article/details/84555025
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍;
也有高质量的技术群,里面有嵌入式、搜广推等BAT大佬

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/406693
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!