
浙江温州,皮鞋,湿,下雨进水,不会,胖!
近日无雨,还像往常一样,周五晚上下班早,写一篇有点意思的文章。今天的还是想写一个Howto,一起来看点实际的东西,不然《闲谈IPv6》系列岂不是成了一部软文集锦了吗?
光说不练假把式,前面讲了很多关于IPv6怎么怎么好的,其中包含IPv6如何支持移动IP的,但那些都是理论,如果不去亲自试一下,总觉得无法令人信服。或者说,即便自己能自圆其说,跟别人要是怼起来,也就是个纸上谈兵。
理论上简单的东西,看似一眨眼搞定的东西,真的动起手来,还真要花时间来处理很多的边边角角,所以,动手很重要,这样才能真正掌握一个理论,同时在这个过程中积累很多troubleshooting的技巧。
如果你已经理解了关于IPv6如何支持移动IP的RFC文档或者至少已经对此特性曾经管中窥豹,那么本文将为你展现一个剥离了复杂的外围东西(比如说IPSec)的纯粹的Howto。本文将展示一个过程,描述 一个节点在改变了其IP地址之后,如何用其原来的IP地址继续通信下去。
觉得我这个不过瘾的,可以去看:
Mobile IPv6 with Linux: https://www.linuxjournal.com/magazine/mobile-ipv6-linux
先给出我的测试拓扑:
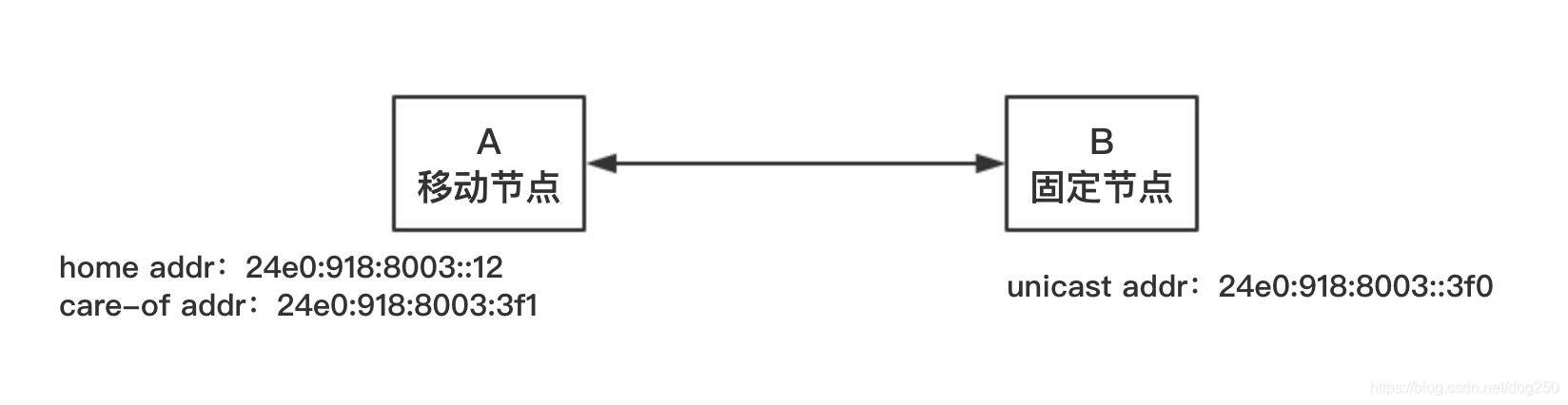

我们假设A为移动节点,B为服务器固定节点,A节点起初被分配了唯一的一个IP地址:
240e:918:8003::12
这个地址我们视其为 home地址 。然后它移动了位置,在新的地方又被分配了另外一个IP地址,是为转交地址,即care-of地址:
240e:918:8003::3f1
此时,A节点的home地址并没有因为得到了新的地址而消失(home地址消失与否,全凭自己决定的啊),这样,A节点便同时拥有了两个地址:
- home地址: 240e:918:8003::12
- care-of地址: 240e:918:8003::3f1
至始至终,B节点的IP地址一直没有变,即:
240e:918:8003::3f0
现在,我们来看一下矛盾之所在。然后能见招拆招描述一个解法。
在应用层看来,一个应用程序丝毫不会管A节点的移动,网络协议栈的分层原则决定底层的移动在应用层看来是透明的,底层保证逐跳寻址可达性即可。然而,由于垃圾TCP协议,以及稍微好一点的UDP这些协议的缺陷,标识一个TCP必须使用一个四元组,甚至还要构造伪三层头来计算校验码,因此里面就牵扯到了源IP地址和目标IP地址,特别地,计算TCP或者UDP的校验和也需要这些IP层的地址信息,因此, 在端到端看来,一个连接从始至终,其五元组是不能改变的!
然而,另一方面,在IP层看来,它只保证任意节点间的可达性,它才不会管什么上层应用。
上述矛盾预示着,一旦IP地址发生了切换,TCP这种连接一定会断开!但是 应用为王! TCP是万万不能断开的!
如何保证在IP地址切换的时候,上层连接被保持而不被断开?! 这便成了一个大问题。
固然,在会话层处理和维持端到端的连接逻辑更加合适和优雅,但是网络协议栈的实现从一开始就很务实和缺乏前瞻,是的,根本就没有一个标准的会话层!如果说为了解决移动节点的问题而引入一个会话层,那么势必要对大量的应用程序和服务器做超出人想象难度的改造!我曾经针对我们的一个产品做过一些这样的事情。参见我的这篇文章:
Open***移动性改造-靠新的session iD而不是IP/Port识别客户端: https://blog.51cto.com/dog250/1423291
事情已经是现在这个样子了,我们没有办法。那么IPv6作为下一版IP协议,在IP层解决了这个问题。
是的,IPv6在IP层轻而易举解决了这个大问题!详情参见:
闲谈IPv6-IPv6对移动性的天然支持 :https://blog.csdn.net/dog250/article/details/88397134
我想这篇文章已经说的比较清楚了。
本文在理论方面不再多说,本文给出一个观感的东西,该观感的东西足够简单,同时也剥离了很多更加复杂但对理解IPv6移动IP并没有多少帮助的细节。请继续阅读。
移动终端离开家乡,重新进入一个新的地方,重新获得一个新的IP地址,这是移动终端普遍存在的必须经历的一个典型的过程,现在假设这个过程已经完成了。也就是说现在假设移动节点已经拥有了两个IP地址,一个home地址,一个care-of地址。
此时,应用程序对于尚未断开的连接,需要继续使用其原始的home地址来进行通信,对于新建的连接,也希望继续使用之前的home地址来建立通信,怎么办?
以Linux为例,其实,此时Linux内核的XFRM框架会设置一些规则,这样在你发包时,内核会将数据包截获,然后再做封包处理。这里要讲的就是如何处理的细节?
XFRM框架会将该连接的源IP,即socket保留的home地址放在一个叫做DSTOPTS的TLV选项里面,然后用care-of地址替换IPv6头部中本来应该是home地址的source address字段。以此来保证两件事:
- 在IP层看来,源地址使用新的care-of地址,以保证节点的可达性。
- 在传输层,应用层看来,源地址依然使用老的home地址,以维持端到端连接。
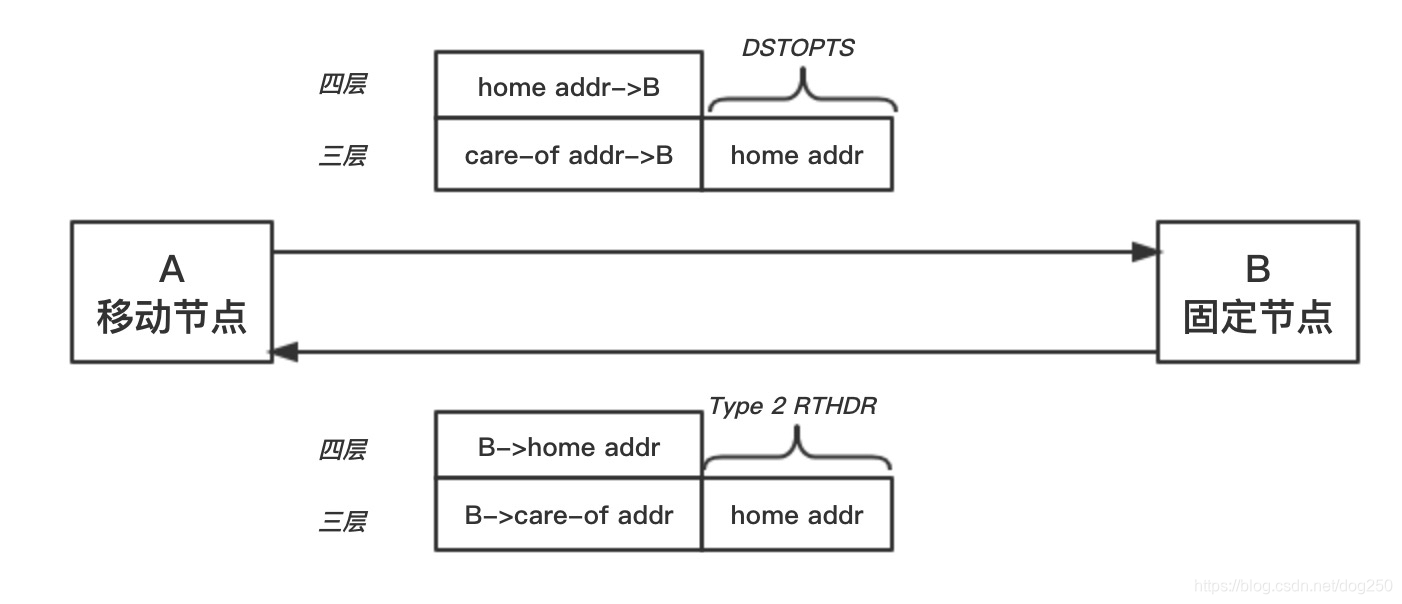
如果你的Home Agent得知你已经获得了一个新的care-of地址并且已经从家乡失联,这会促使该机制被使能,最终当你要发送一个数据包时,就会进入到下面的逻辑中:
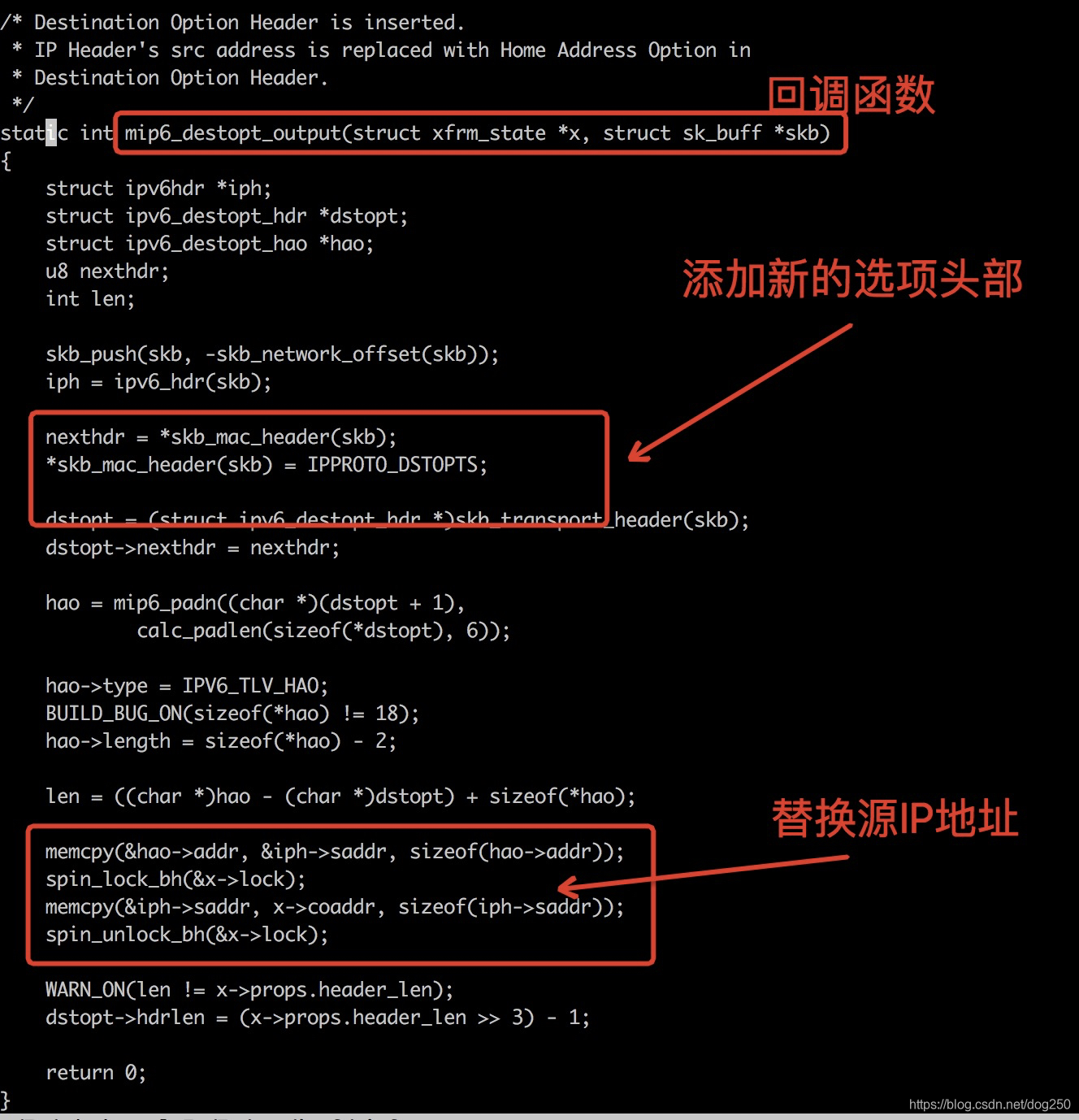
XFRM框架支持的安全特性是必须的,这样才能防止安全事件的发生。毕竟在移动环境下,针对IP地址的 认证工作 是百分之一百万不能少的!
然而,我无力去配置复杂的XFRM,我也没有真实的移动环境,我只是想展示一下效果,这个应该不会太难。所以我选择使用RAW套接字去模拟效果。我要模拟的非常简单:
- 用care-of地址封装IPv6头部;
- 用home地址建立四层连接;
下面的代码部署在模拟的移动节点A:
#include <stdbool.h>
#include <stdlib.h>
#include <unistd.h>
#include <stdio.h>
#include <string.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <errno.h>
#include <netinet/ip.h>
#include <netinet/udp.h>
#include <linux/in6.h>
#define __u8 unsigned char
#define __be16 unsigned short
#define uint16_t unsigned short
#define uint32_t unsigned int
struct ipv6hdr {
__u8 priority:4,
version:4;
__u8 flow_lbl[3];
__be16 payload_len;
__u8 nexthdr;
__u8 hop_limit;
struct in6_addr saddr;
struct in6_addr daddr;
};
struct padN {
__u8 type;
__u8 length;
char pad[2];
} __attribute__((packed));
struct ipv6_destopt_hao {
__u8 type;
__u8 length;
struct in6_addr addr;
} __attribute__((packed));
struct ipv6_opt_hdr {
__u8 nexthdr;
__u8 hdrlen;
/*
* TLV encoded option data follows.
*/
} __attribute__((packed));
// 定义移动节点A的home地址 240e:918:8003::12
__u8 home_addr[16] = {0x24, 0x0e, 0x09, 0x18, 0x80, 0x03, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x12};
// 定义移动节点A的care-of地址 240e:918:8003::3f1
__u8 care_of_addr[16] = {0x24, 0x0e, 0x09, 0x18, 0x80, 0x03, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x03, 0xf1};
// 定义固定节点服务器B的地址 240e:918:8003::3f0
__u8 dest_addr[16] = {0x24, 0x0e, 0x09, 0x18, 0x80, 0x03, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x03, 0xf0};
// 以下计算UDP校验和的代码改自网上的 http://www.pdbuchan.com/rawsock/udp6_cooked.c
uint16_t checksum (uint16_t *addr, int len)
{
int count = len;
register uint32_t sum = 0;
uint16_t answer = 0;
while (count > 1) {
sum += *(addr++);
count -= 2;
}
if (count > 0) {
sum += *(uint8_t *) addr;
}
while (sum >> 16) {
sum = (sum & 0xffff) + (sum >> 16);
}
answer = ~sum;
return (answer);
}
uint16_t
udp6_checksum (struct ipv6hdr *iphdr, struct udphdr udphdr, uint8_t *payload, int payloadlen)
{
char buf[IP_MAXPACKET];
char *ptr;
char nxt = SOL_UDP;
int chksumlen = 0;
int i;
ptr = &buf[0]; // ptr points to beginning of buffer buf
memcpy (ptr, &home_addr[0], sizeof (iphdr->saddr));
ptr += sizeof (iphdr->saddr);
chksumlen += sizeof (iphdr->saddr);
memcpy (ptr, &iphdr->daddr, sizeof (iphdr->daddr));
ptr += sizeof (iphdr->daddr);
chksumlen += sizeof (iphdr->daddr);
memcpy (ptr, &udphdr.len, sizeof (udphdr.len));
ptr += sizeof (udphdr.len);
chksumlen += sizeof (udphdr.len);
*ptr = 0; ptr++;
*ptr = 0; ptr++;
*ptr = 0; ptr++;
chksumlen += 3;
memcpy (ptr, &nxt, sizeof (iphdr->nexthdr));
ptr += sizeof (iphdr->nexthdr);
chksumlen += sizeof (iphdr->nexthdr);
memcpy (ptr, &udphdr.source, sizeof (udphdr.source));
ptr += sizeof (udphdr.source);
chksumlen += sizeof (udphdr.source);
memcpy (ptr, &udphdr.dest, sizeof (udphdr.dest));
ptr += sizeof (udphdr.dest);
chksumlen += sizeof (udphdr.dest);
memcpy (ptr, &udphdr.len, sizeof (udphdr.len));
ptr += sizeof (udphdr.len);
chksumlen += sizeof (udphdr.len);
*ptr = 0; ptr++;
*ptr = 0; ptr++;
chksumlen += 2;
memcpy (ptr, payload, payloadlen * sizeof (uint8_t));
ptr += payloadlen;
chksumlen += payloadlen;
for (i=0; i<payloadlen%2; i++, ptr++) {
*ptr = 0;
ptr++;
chksumlen++;
}
return checksum ((uint16_t *) buf, chksumlen);
}
int main(int argc, char **argv)
{
int sd;
char *packet;
static struct sockaddr_in6 remote;
struct ipv6hdr *hdr;
struct ipv6_opt_hdr *opthdr;
struct padN *padn;
struct ipv6_destopt_hao *hao;
struct udphdr *udp;
int snd;
int tot;
remote.sin6_family = PF_INET6;
remote.sin6_port = htons (0);
sd = socket(PF_INET6, SOCK_RAW, IPPROTO_RAW);
if (sd < 0) {
fprintf(stderr, "Cannot create socket: %s\n", strerror(errno));
abort();
}
// 从IPv6头开始的数据报文总长
tot = sizeof(struct ipv6hdr) + sizeof(struct ipv6_opt_hdr) + sizeof(struct padN) + sizeof(struct ipv6_destopt_hao) + sizeof(struct udphdr) + 1;
packet = (char *)calloc(1, tot);
// IPv6 version
packet[0] = 0x60;
hdr = (struct ipv6hdr *)&packet[0];
opthdr = (struct ipv6_opt_hdr *)&packet[sizeof(struct ipv6hdr)];
padn = (struct padN *)&packet[sizeof(struct ipv6hdr) + sizeof(struct ipv6_opt_hdr)];
hao = (struct ipv6_destopt_hao*)&packet[sizeof(struct ipv6hdr) + sizeof(struct ipv6_opt_hdr) + sizeof(struct padN)];
udp = (struct udphdr *)&packet[sizeof(struct ipv6hdr) + sizeof(struct ipv6_opt_hdr) + sizeof(struct padN) + sizeof(struct ipv6_destopt_hao)];
// 设置固定简单的IPv6头
memset(hdr->flow_lbl, 0, sizeof(hdr->flow_lbl));
// 除了IPv6头部以外的所有载荷长度
hdr->payload_len = htons(tot - sizeof(struct ipv6hdr));
// 下一个头是“地址选项头”
hdr->nexthdr = IPPROTO_DSTOPTS;//0x3c; 60
hdr->hop_limit = 64;
// 注意,源地址是care-of转交地址,而不是home家乡地址
memcpy(&hdr->saddr, care_of_addr, 16);
// 目标地址没得说,就是目标地址
memcpy(&hdr->daddr, dest_addr, 16);
// 设置“地址扩展选项头”,其下一个头是UDP
opthdr->nexthdr = IPPROTO_UDP;
opthdr->hdrlen = 2;
// 设置填充
padn->type = 1;
padn->length = 2;
memset(&padn->pad, 0, 2);
// 设置home TLV选项,home地址将藏匿于其中
hao->type = IPV6_TLV_HAO;//0xc9;
hao->length = 16;
memcpy(&hao->addr, home_addr, 16);
// 这里是UDP头
udp->source = htons(1111);
udp->dest = htons(12345);
udp->len = htons(1 + sizeof(struct udphdr));
char *buf = (char *)udp;
udp->check = udp6_checksum(hdr, *udp, &buf[sizeof(struct udphdr)] , 1);
memcpy(&remote.sin6_addr.s6_addr, &hdr->daddr, sizeof(remote.sin6_addr.s6_addr));
// 好了,现在将我们从IPv6头部开始构造的报文,一股脑儿全部发送出去!
snd = sendto(sd, packet, tot, 0, (struct sockaddr *)&remote, sizeof(remote));
if (snd < 0) {
fprintf(stderr, "Cannot send message: %s\n", strerror(errno));
abort();
}
return 0;
}
我们模拟一个移动节点A,在获得了一个新的care-of转交地址,同时保有原来的home家乡地址的情况下,用上面的程序发出一个报文,我们来看看这个报文长什么样子。
该报文抓包如下:
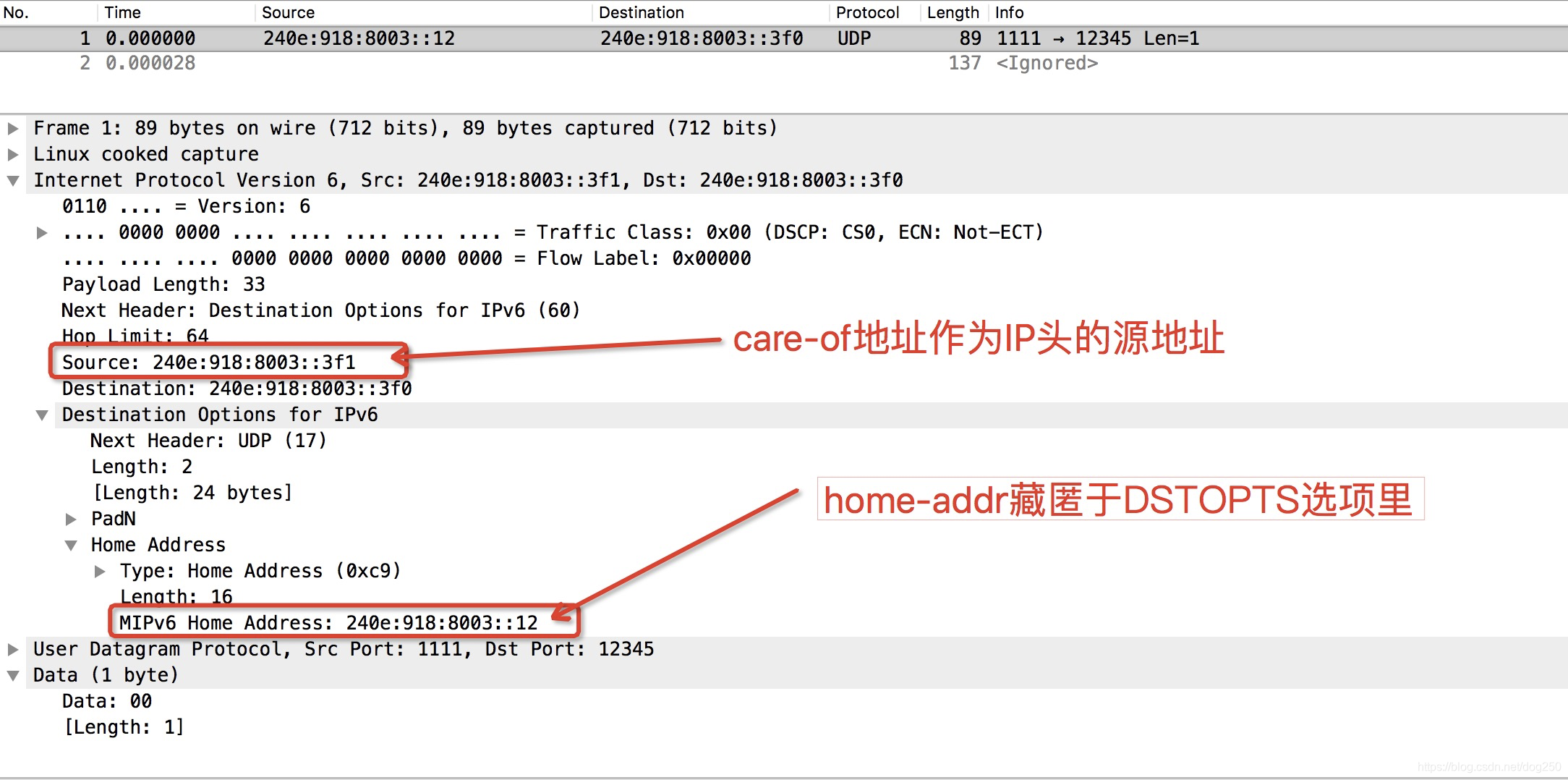
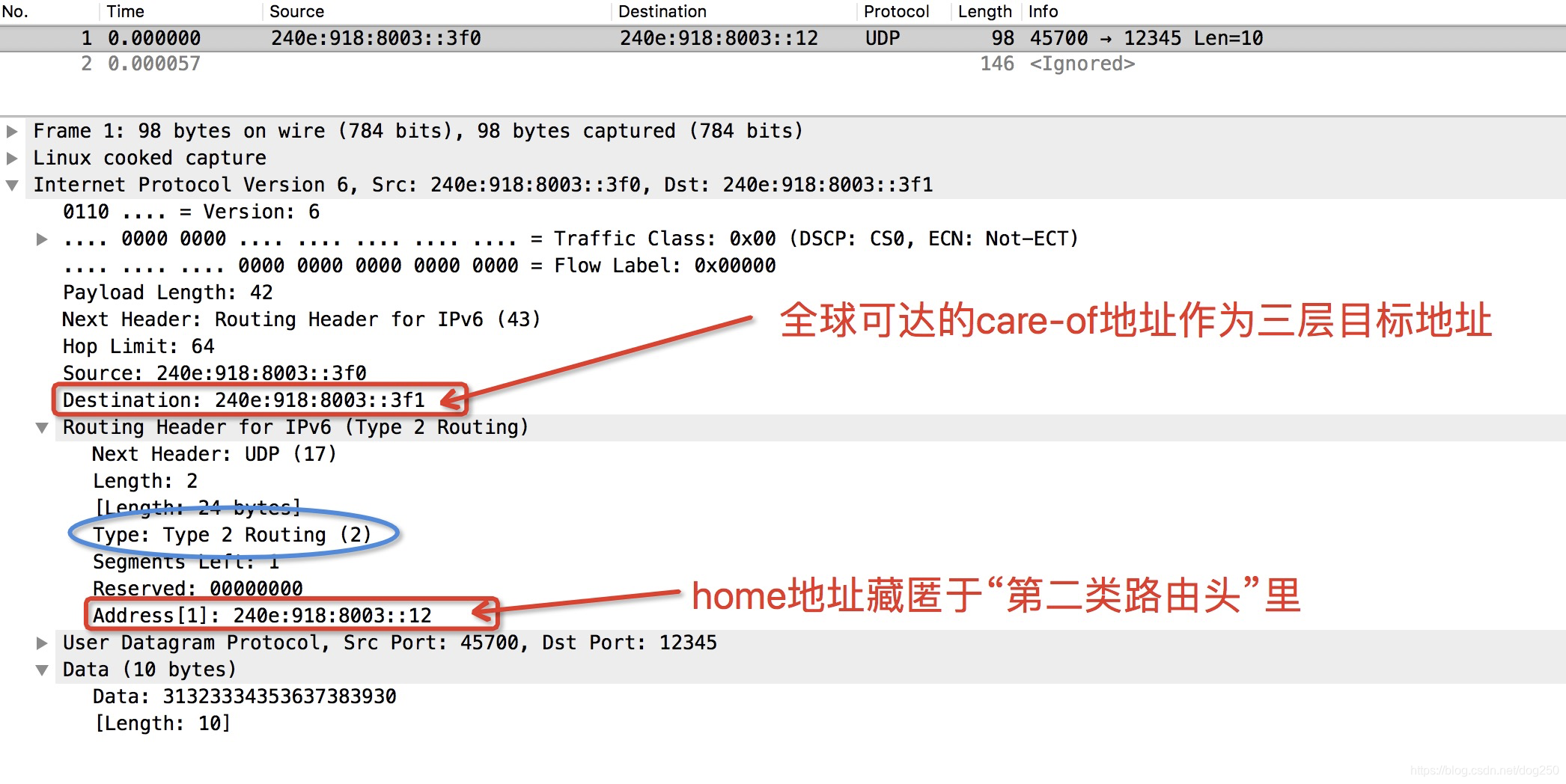
从抓包上看,我们已经做到了第一点,即用care-of地址封装IPv6报文头,它确实是如此封装的,然后home地址藏匿于一个DSTOPTS TLV选项里面。那么接下来,我们需要确认在四层看来,它使用的是home地址。
为了让B节点按照IPv6处理DSTOPTS的方式成功接收这个数据包,同样需要绕开XFRM逻辑。如果你忽略了这一点,下面的实验将全部不会成功,你将会发现snmp统计里的XfrmInNoStates计数器字段在升高,这意味着数据包没有通过内核XFRM的检验,毕竟我们什么规则也没有使用,更没有去生成IPSec SA,所以我们要绕开这个复杂的东西。
非常简单,用HOOK机制让XFRM的检查函数永远返回true即可,即:
static int stub_xfrm6_input_addr(struct sk_buff *skb, xfrm_address_t *daddr)
{
printk("hook stub \n");
return 1;
}
static int hook_xfrm6_input_addr(struct sk_buff *skb, xfrm_address_t *daddr)
{
printk("hook \n");
return 1;
}
...
// 嗯,我们就是要hook住xfrm6_input_addr,所以要先找到它!
ptr_xfrm6_input_addr = kallsyms_lookup_name("xfrm6_input_addr");
if (!ptr_xfrm6_input_addr) {
printk("err");
return -1;
}
jump_op[0] = 0xe9;
hook_offset = (s32)((long)hook_xfrm6_input_addr - (long)ptr_xfrm6_input_addr - OPTSIZE);
(*(s32*)(&jump_op[1])) = hook_offset;
saved_op[0] = 0xe9;
orig_offset = (s32)((long)ptr_xfrm6_input_addr + OPTSIZE - ((long)stub_xfrm6_input_addr + OPTSIZE));
(*(s32*)(&saved_op[1])) = orig_offset;
get_online_cpus();
// 替换操作!
ptr_poke_smp(stub_xfrm6_input_addr, saved_op, OPTSIZE);
barrier();
ptr_poke_smp(ptr_xfrm6_input_addr, jump_op, OPTSIZE);
put_online_cpus();
详情参见:
Linux内核如何替换内核函数并调用原始函数 : https://blog.csdn.net/dog250/article/details/84201114
绕过XFRM之后,IPv6的DSTOPTS扩展头处理逻辑就能正确处理这个选项了:
- 从DSTOPTS选项里取出home地址,用其替换IPv6头里面的源地址。
- 将替换好的IPv6报文继续处理DSTOPTS的next header,即UDP数据报。
现在在节点B运行的服务进程正等着呢:
import socket
# 侦听3f0地址
addr = ("240e:918:8003::3f0", 12345, 0, 0)
s = socket.socket(socket.AF_INET6, socket.SOCK_DGRAM)
s.setsockopt(socket.IPPROTO_IPV6, socket.IPV6_RECVDSTOPTS, 1)
s.bind(addr)
data, raddr = s.recvfrom(64)
# 打印来源地址,看看数据包的源地址到底是home地址还是care-of地址,你猜猜看。
print str(raddr)
time.sleep(20)
OK,打印结果如下:
('240e:918:8003::12', 1111, 0, 0)
如果我们在B节点看一下netstat显示的连接信息,果不其然,依然也是看到是A节点的home地址240e:918:8003::12在发送数据,而不是抓包里IPv6头部的care-of地址240e:918:8003::3f1在发送,然而,从网络的角度看确实是A节点的care-of地址作为源地址在传输数据报文。
端到端逻辑和网络逻辑区分开了!
也许你会说,这不就是简单的一个SNAT嘛,有什么大惊小怪的,但是非也,非也!
我并没有配置任何NAT规则,所有这一切都是在IPv6的RFC里天然支持的:
Mobility Support in IPv6: https://tools.ietf.org/html/rfc6275
也许你见过,用过,听说过之前淘宝LVS使用的TAO(TCP Option Address):
LVS在淘宝环境中的应用: http://cherishry.github.io/2016-01-16-LVS在淘宝环境中的应用.html
TCP在经过四层以上代理后,请求到达后端时,业务逻辑无法区分独立的客户端,为了能作出区分,TOA被设计了出来。
看样子,其思想和IPv6的这个DESTOPTS非常类似,都是将一个源地址藏匿于选项里面,但是不同的是,TOA是在TCP层本身来处理这个源地址的,如果想实现类似IPv6的这个源地址交换的效果,在取出这个地址之前,检查校验码就已经失败了!
因此,TOA只适合于传递源IP地址信息,而不能让其参与封包处理。这是TOA的局限。
好了,现在该服务器回包了。我们要看一下服务器B节点是如何做到下面的两点的:
- 使用模拟移动节点A的home地址构建端到端连接
- 使用模拟移动节点A的care-of地址进行网络层路由
当服务器B节点发现了藏匿于DSTOPTS选项里面的A节点的home地址之后,它会将其保存起来,作为其四层连接的目标地址继续使用,同时,模拟节点A的正向报文的原始IPv6头部的源地址,即其care-of地址,将作为其IP层的目标地址参与IP路由寻址。这个道理和上面描述的是一样的,三层,四层使用不同的目标IP地址,代表不同的含义分别处理。
IPv6的该功能是用 第二类路由头 实现的,所谓的 第二类 其实只是针对第一类做了一些更为严格的约束,即里面只能藏匿一个经由地址,即最终目的地,A节点的home地址!
为了实现这个,这次我不再用RAW套接字,而是直接使用IPv6相关的API来完成,即通过设置sockopt的方式,将这个RTHDR直接设置下去。
当然了,用RAW的话,也是可以,可能还更直接,但是我喜欢一顿饭两个味道,先干吃,然后再放辣椒,还是领略一下不同的味道吧。
这个版本里,只需要现成的setsockopt,简单地将这个头部扩展设置进去即可。当然,我的版本里是自己拼接buffer的,你也可以使用现成的API来完成,大同小异。你可以使用下面的API套件:
int
inet6_opt_init(void *extbuf, socklen_t extlen);
int
inet6_opt_append(void *extbuf, socklen_t extlen, int offset,
u_int8_t type, socklen_t len, u_int8_t align, void **databufp);
int
inet6_opt_finish(void *extbuf, socklen_t extlen, int offset);
int
inet6_opt_set_val(void *databuf, int offset, void *val,
socklen_t vallen);
int
inet6_opt_next(void *extbuf, socklen_t extlen, int offset,
u_int8_t *typep, socklen_t *lenp, void **databufp);
int
inet6_opt_find(void *extbuf, socklen_t extlen, int offset, u_int8_t type,
socklen_t *lenp, void **databufp);
int
inet6_opt_get_val(void *databuf, socklen_t offset, void *val,
socklen_t vallen);
详情参阅其manual:https://www.unix.com/man-page/netbsd/3/inet6_opt_append/
总之,理解了TLV以及路由头的数值,怎么拼接都可以。
先看服务器节点B上运行的代码,它的目标是:
- 用A的care-of地址封装数据报文的IPv6头;
- 用A的home地址设置进第二类路由头;
请看代码:
#include <stdlib.h>
#include <unistd.h>
#include <stdio.h>
#include <string.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netdb.h>
#include <errno.h>
#include <netinet/ip.h>
#include <netinet/udp.h>
#define __u8 unsigned char
#define __be16 unsigned short
struct ipv6_rt_hdr {
__u8 nexthdr;
__u8 hdrlen;
__u8 type;
__u8 segments_left;
/*
* type specific data
* variable length field
*/
};
#define __u32 unsigned int
struct rt2_hdr {
struct ipv6_rt_hdr rt_hdr;
__u32 reserved;
struct in6_addr addr;
#define rt2_type rt_hdr.type
};
uint8_t app_addr[16] = {0x24, 0x0e, 0x09, 0x18, 0x80, 0x03, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x12};
uint8_t care_of_addr[16] = {0x24, 0x0e, 0x09, 0x18, 0x80, 0x03, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x03, 0xf0};
uint8_t real_addr[16] = {0x24, 0x0e, 0x09, 0x18, 0x80, 0x03, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x03, 0xf1};
int main(int argc, char **argv)
{
int num, sd;
struct rt2_hdr *ext_buffer;
static struct sockaddr_in6 remote;
remote.sin6_family = PF_INET6;
remote.sin6_port = htons (12345);
memcpy(&remote.sin6_addr.s6_addr, &app_addr[0], sizeof(remote.sin6_addr.s6_addr));
sd = socket(AF_INET6, SOCK_DGRAM, SOL_UDP);
if (sd < 0) {
fprintf(stderr, "Cannot create socket: %s\n", strerror(errno));
abort();
}
// 封装第二类路由头,将A节点的home地址藏匿其中
ext_buffer = (struct rt2_hdr *)malloc(24);
ext_buffer->rt_hdr.nexthdr = 222;
ext_buffer->rt_hdr.hdrlen = 2;
ext_buffer->rt_hdr.type = 2;
ext_buffer->rt_hdr.segments_left = 1;
memset(&ext_buffer->reserved, 0, sizeof(ext_buffer->reserved));
memcpy(&ext_buffer->addr, real_addr, sizeof(real_addr));
if (setsockopt(sd, IPPROTO_IPV6, IPV6_RTHDR, ext_buffer, sizeof(struct rt2_hdr)) == -1) {
fprintf(stderr, "setsockopt IPV6_RTHDR: %s\n", strerror(errno));
abort();
}
num = sendto(sd, "1234567890", (size_t) 10, 0, (struct sockaddr *)&remote, sizeof(remote));
if (num < 0) {
fprintf(stderr, "Cannot send message: %s\n", strerror(errno));
abort();
}
return (0);
}
抓包试试看呗:
B节点的输出程序如下:
import socket
addr = ("240e:918:8003::12", 12345, 0, 0)
s = socket.socket(socket.AF_INET6, socket.SOCK_DGRAM)
s.bind(addr)
data, raddr = s.recvfrom(64)
print str(raddr)
time.sleep(30)
来自240e:918:8003::3f0的数据:
('240e:918:8003::3f0', 48571, 0, 0)
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
udp6 0 0 240e:918:8003::12:12345 :::* 11638/python
看到了吧,和抓包显示的完全不同,在模拟移动节点A的四层看来,数据包的目标地址是自己的home地址,但是我们也已经看到,在三层以及以下看来,数据包的目标地址却是A节点的care-of转交地址。
两个地址的任务不同,三层及以下,需要确保可达性,毕竟节点A已经离开家乡,在三层看来,家乡地址是不可达的,但是在四层看来,家乡地址只是为了维持端到端连接的一个标识手段而已。
接下来,换另一种口味。把上面的代码用RAW来再演示一把。
先看模拟服务器B上的代码:
#include <stdlib.h>
#include <unistd.h>
#include <stdio.h>
#include <string.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <errno.h>
#include <netinet/in.h>
#include <linux/in6.h>
#define __u8 unsigned char
#define __be16 unsigned short
#define __u32 unsigned int
struct ipv6hdr {
__u8 priority:4,
version:4;
__u8 flow_lbl[3];
__be16 payload_len;
__u8 nexthdr;
__u8 hop_limit;
struct in6_addr saddr;
struct in6_addr daddr;
};
struct ipv6_rt_hdr {
__u8 nexthdr;
__u8 hdrlen;
__u8 type;
__u8 segments_left;
/*
* type specific data
* variable length field
*/
};
struct rt2_hdr {
struct ipv6_rt_hdr rt_hdr;
__u32 reserved;
struct in6_addr addr;
#define rt2_type rt_hdr.type
};
uint8_t home_addr[16] = {0x24, 0x0e, 0x09, 0x18, 0x80, 0x03, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x12};
uint8_t source_addr[16] = {0x24, 0x0e, 0x09, 0x18, 0x80, 0x03, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x03, 0xf0};
uint8_t care_of_addr[16] = {0x24, 0x0e, 0x09, 0x18, 0x80, 0x03, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x03, 0xf1};
int main(int argc, char **argv)
{
int sd;
char packet[128] = {0};
static struct sockaddr_in6 remote;
struct ipv6hdr *hdr;
struct ipv6_rt_hdr *rthdr;
struct rt2_hdr *rt2;
int num;
remote.sin6_family = PF_INET6;
remote.sin6_port = htons (0);
sd = socket(PF_INET6, SOCK_RAW, IPPROTO_RAW);
if (sd < 0) {
fprintf(stderr, "Cannot create socket: %s\n", strerror(errno));
abort();
}
packet[0] = 0x60;
hdr = (struct ipv6hdr *)&packet[0];
rthdr = (struct ipv6_rt_hdr *)&packet[sizeof(struct ipv6hdr)];
rt2 = (struct rt2_hdr *)rthdr;
memset(hdr->flow_lbl, 0, sizeof(hdr->flow_lbl));
hdr->payload_len = htons(sizeof(packet) - sizeof(struct ipv6hdr));
hdr->nexthdr = IPPROTO_ROUTING;
hdr->hop_limit = 64;
memcpy(&hdr->saddr, source_addr, 16);
// 使用care-of地址封装IPv6地址头的目标地址
memcpy(&hdr->daddr, care_of_addr, 16);
#define IPPROTO_MYTEST 222
rt2->rt_hdr.nexthdr = IPPROTO_MYTEST;
rt2->rt_hdr.hdrlen = 2;
rt2->rt_hdr.type = 2;
rt2->rt_hdr.segments_left = 1;
memset(&rt2->reserved, 0, sizeof(rt2->reserved));
// home地址藏匿于第二类路由头里面
memcpy(&rt2->addr, home_addr, sizeof(home_addr));
memcpy(&remote.sin6_addr.s6_addr, &hdr->daddr, sizeof(remote.sin6_addr.s6_addr));
num = sendto(sd, packet, sizeof(packet), 0, (struct sockaddr *)&remote, sizeof(remote));
if (num < 0) {
fprintf(stderr, "Cannot send message: %s\n", strerror(errno));
abort();
}
return (0);
}
接下来给出模拟节点A上的接收代码:
import socket
# 侦听的是home地址
addr = ("240e:918:8003::12", 1245, 0, 0)
# 创建处理自定义协议号为222的RAW socket
s = socket.socket(socket.AF_INET6, socket.SOCK_RAW, 222) #
s.bind(addr)
data, raddr = s.recvfrom(64)
print str(raddr)
代码就不再解释了。
我也不是很会编程,代码,就给到这里。
当然了,以上这些,IPv4也能做到,但是无外乎就是配置复杂的规则,而不是IP协议内在原生的特性。使用IPv6,几乎什么都不用做,想达到以往NAT才能实现的效果,一眨眼就OK了。这就是所谓的 天然支持某种特性 的威力!
好了,现在说一下IPv4如何不用NAT,不用Netfilter,甚至不基于Linux系统内核实现上述这些。
非常简单!
只需要在IP协议和TCP/UDP协议之间插入一层新的协议即可,类似隧道封装那般,分层协议结构无所不能,any over any。我们只需要将IPv4协议头里的proto字段改成一个新的协议,比如:
#define IPPROTO_V4RTHDR
然后实现 IPPROTO_V4RTHDR 的协议逻辑:
struct v4rthdr{
u8 l4proto;
u32 home_addr;
} __attribute__((packed));
发送端只需要将这个协议push到TCP/UDP前面即可:
struct v4rthdr *rthdr = ...
...
// 使用home地址建立TCP连接并且计算TCP伪头。
...
rthdr->l4proto = IPPROTO_TCP; // or IPPROTO_UDP
rthdr->home_addr = 移动节点的home地址
iphdr->daddr = 移动节点的care-of地址
...
接收逻辑的handler如下:
...
iphdr->daddr = rthdr->home_addr;
...
是不是很简单呢?
但是问题是,这一切都不是标准化的!!而在IPv6中,这些功能是每一个宣称自己支持IPv6的节点都必须要实现的,这些都是RFC里面的MUST,SHOULD…
我们讲,如果仅仅是实现某个东西,那是简单的,特别是网络协议栈方面,我此前很久都觉得以此为荣,但是 网络协议栈方面的这些仅仅实现出来的东西都是trick, 网络协议栈方面,最重要的就是 标准化!!标准化!!标准化!!
我们看 协议 字面的意思,就有标准化的意思,大家都公认,都遵守的细则,这就是协议。
如果我想用home地址进行移动节点的支持,建立TCP连接,按照上述的IPv4的yy做法,我必须同时在所有参与者设备上部署我的trick代码,这不是标准的,这是私有的东西,同时这也意味着巨大的工作量。
然而如果是使用IPv6,只要对方声称 自己支持IPv6 就这么简单一句话,我就默认当我发送一个第二类路由头过去时,相信它就一定会按照RFC里面说的那样去处理。这就是协议。但是IPv4做不到这种相信,你必须自己去做去实现它,而不能只是相信。
浙江温州皮鞋湿,下雨进水不会胖。
原文链接: https://blog.csdn.net/dog250/article/details/88561708
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍;
也有高质量的技术群,里面有嵌入式、搜广推等BAT大佬

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/406635
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!