
关于Linux路由查找的方式,多个内核已经不知反复了多少回合,其中最具有里程碑意义的变革有两个:
- Linux 3.5内核之后取消了基于hash表的路由缓存。
- Linux 4.18内核以后开始支持路由查找的Flow offload。
基于Flow offload这个框架,进一步的优化就是 Flow HW offload 。
可以参考我之前写的文章:
https://blog.csdn.net/dog250/article/details/50809816
https://blog.csdn.net/dog250/article/details/103422860
无论是在FIB表之外的离线hash cache,还是绕过FIB查找的各种offload短路措施,都只是在Linux内核的 算法范畴 的,无非就是在查找路由的过程中节省几个步骤。 它们都没有利用数据包本身的特征。
我们知道, 数据特征是可以影响算法结构的。 最典型的例子就是 “分级存储机制” CPU cache内存数据,内存cache磁盘数据… 这一切完全是基于数据的局部性特征设计的。如果数据没有局部性特征,那么分级存储设计将毫无意义。
回到路由查找,其实也是可以利用数据包的特征的,幸运的是,数据包也具有局部性特性:
- 时间局部性:同一个数据流的数据包会连续到来。
- 空间局部性:到达同一个域名的数据包会连续到来。
简单解释一下。
数据包以数据流的形式编排是数据包时间局部性的根源,考虑到当前的网络已经非常高速,中间节点无论在进行包分类还是在进行DPI时,一般都是按照数据流来汇总的,而这也是TCP等流式协议得以进行拥塞控制的依据。
数据包的时间局部性也为运营商提供了详细的数据流在统计意义上的特征数据。
数据包的空间局部性这里不多说,它比较复杂,比时间局部性更难以分析和利用,后面有空再谈。
说了这么多,数据包的时间局部性能为路由查找提供什么便利呢?
早在2015年,我为了优化nf_conntrack的查找,我为其增加了一个查找cache,详见:
https://blog.csdn.net/dog250/article/details/47193113
这篇文章所述的优化背后的依据就是数据包的时间局部性和空间局部性,不过在当时并没有利用这个局部性特征去优化路由查找,因为我把路由项已经藏在nf_conntrack里面啦,查找nf_conntrack就等于查到了一切,路由,socket,等等,什么都有…
Linux 5.5内核在路由查找算法上,终于有了针对数据包时间局部性的优化:
When doing RX batch packet processing, Linux always repeated the route lookup for each ingress packet. When no custom rules are in place, and there aren’t routes depending on source addresses, we know that packets with the same destination address will use the same dst. This change tries to avoid per packet route lookup caching the destination address of the latest successful lookup.
请看下面的patchset:
ipv6: add fib6_has_custom_rules() helper
ipv6: keep track of routes using src
ipv6: introduce and uses route look hints for list input.
ipv4: move fib4_has_custom_rules() helper to public header
ipv4: use dst hint for ipv4 list receive
看明白代码就不用听我扯这些形而上学的东西了,不过我这些可能会帮你进行一些DIY的优化。
一般而言,路由器不对数据包之间的关联做任何假设,它认为数据包是独立到达的,并且报文之间毫无关联,这是IP逐跳寻址的基础。
所以,路由器针对每一个数据包都要进行 同样的FIB路由表查询动作-最长前缀匹配算法。
后来,人们发现没有必要去用 最长前缀 算法查询FIB表,于是转发表从FIB表中分离了出来,无论是高端的Cisco的CEF,还是Linux 3.6内核以前的路由cache,都是这个路子,甚至OVS流表的背后,也是这个思想。
无论是查FIB还是查cache,无论这cache是软件的,还是offload到硬件的,终究都还是要查,终究还是不能直接拿来就用。
我的意思是,设想有一个全局变量,它保存着一个 当前流的下一跳路由项 , “流”通过目标地址来标识,也就是说, 只要目标地址是一样的,就认为它们通过同一个下一跳发出。
嗯,大致的思路就是下面一张图所示的:
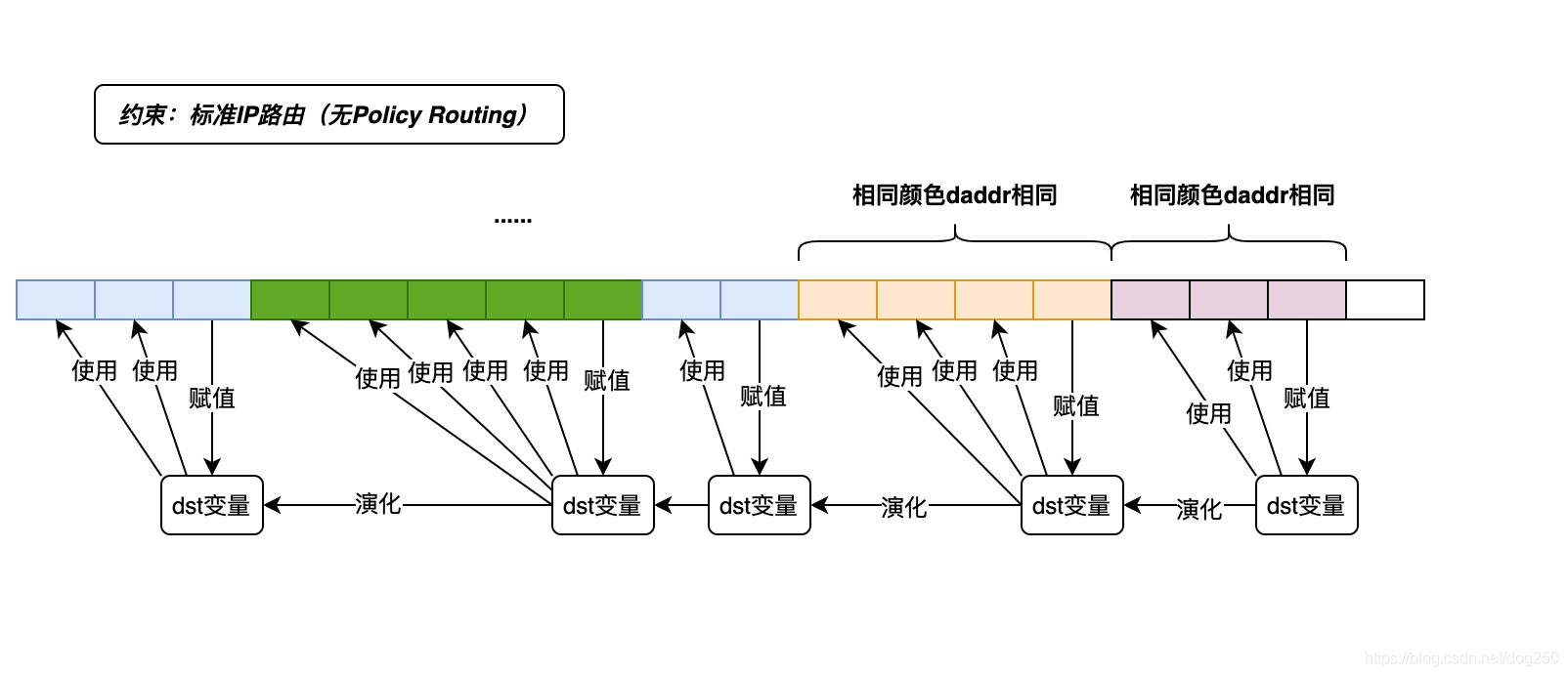

太简洁了,一张图解释一切。
解释下为什么不能作用于Policy Routing。
标准的IP路由是基于目标地址来路由的,它就像当前大多数导航一样,趋向于去往同一个目的地的流量使用同一条路经,但是这会造成很多问题,比如拥塞。此外,显式的负载均衡也是很多设备商的卖点…
于是,Policy Routing本身就是用来打破标准IP路由的枯燥乏味的,它引入像源地址,源入口之类的健用来更加灵活地为数据包找到一个下一跳。因此,如果系统中存在Policy Routing配置,便无法使用本文所述的优化方案了。
最后,回应题目,什么是Flowlet?Flowlet和路由查找有什么关系?请看:
Flowlet可是大有作为,运营商早就看出来网络上跑的都是Flowlet了,虽然大家都在说pacing,然而在运营商看来,终于还是bursting…
浙江温州皮鞋湿,下雨进水不会胖。
原文链接: https://blog.csdn.net/dog250/article/details/104212345
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍;
也有高质量的技术群,里面有嵌入式、搜广推等BAT大佬

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/406117
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!