
2017/05/02
自从上周写了几篇关于BadUOM的文章后,收到很多的邮件前来询问细节。其中最多的不外乎两类,一类是询问怎么使用的,另一类则是要求我写几篇源码分析。先来一个一个说。
1.关于BadUOM的使用问题
和OpenUOM相反,BadUOM几乎没有除了配置隧道之外的任何东西,这些被排除了内容中最重要的应该就是路由了。OpenUOM中就有关于路由的很多配置,还可以从服务端往客户端推送路由,这简直太方便了,但同时也增加了配置的复杂性。BadUOM我认为是比较好的方式,它本身没有关于路由的任何配置,只要你把隧道搭建好,路由就找熟悉路由的人配置吧,让专业的人做专业的事。
所以关于BadUOM的用法,我不想过多的说,只要你能先把BadUOM跑起来,那么后面的就不属于BadUOM的范畴了。如果你不懂IP路由,那么这是另外一个话题。
2.关于源码分析
说实话,我是不喜欢用源码分析的方式去熟悉一个技术的。如果你已经理解了原理,何必不自己试着写一个呢?本文就是针对这一点来写的。趁着五一假期,花点时间盲写了一个UOM框架,所谓盲写就是这个UOM没有基于任何其它的代码修改,都是自己写的,像我这种编程编的不好人,能写出个这样的代码,我已经很知足了。
一直存在关于各种SSLUOM与sec UOM区别和联系的讨论,自然,很多人会把OpenUOM这种“使用SSL协议的UOM”叫做SSLUOM,诚然,BadUOM并没有OpenUOM那么出名,很多人都不知道,而OpenUOM却是业内众所周知的,曾经有一本书叫做《OpenUOM and the SSL UOM Revolution》就是宣传OpenUOM的,另外,除了OpenUOM,来自日本的SoftEther也曾经大红一时,作者还被采访,从其描述中得知,这也是UOM的一次Revolution...不管怎么样,OpenUOM也好,SoftEhter也罢,都是针对传统的sec UOM的,革的是sec UOM的命,类似这种sec UOM由于厂商独断,配置复杂,且NAT穿越问题而饱受诟病,所以世界这么大,总是会有人跳出来提一个全新的方案,这并不足以为奇。而且这些所谓的新方案无一没有使用SSL协议,这就给人造成了一种假象,这些都是SSLUOM!使用了SSL的UOM就一定是SSLUOM吗?
其实根本就不是!SSL只是这种UOM使用的工具集里一个套件,不用SSL,还是可以用别的方式构建安全的控制通道,比如大多数简单环境下,直接用DH写上密钥我就觉得没什么不好。另外,也很少有人直接用SSL记录协议去封装数据流,毕竟SSL(统称,包括TLS,DTLS...)记录协议太重了,它便于封装能感知的业务数据比如HTTPS,而不是透明地封装裸数据。需求决定方法,UOM难道不就只是为了让数据进行加密传输吗(together with认证)?所以使用SSL只是为了构建一个安全通道而已,在这个安全通道里去协商数据通道的对称密钥,如果你理解了这,那么SSL显然其分量就没有那么重了。
当然我是站在中立的立场上来说这件事,如果对于偏网络的公司,比如Cisco,华为,他们可能倾向于将SSL作为组件结合到UOM中,而对于安全类公司,比如格尔软件,他们可能会将SSL立足为根本,但在中立者看来,讨论这个问题毫无意义,取向取决于公司的基础投资,这永远都是个案问题,没有普适的答案。
那么BadUOM又是什么?它出自谁之手?这里有一个链接:https://news.ycombinator.com/item?id=12433660
当有人问“Why is it called baduom?”时,作者如是说:
No particular reason really, I just needed a name that sounded deviant - I was still a teen back then! Over time I added other software to the repo for convenience (tun2socks, NCD). A name change might in fact be due.
如今,作者已经长大了吧。这个项目并没有大红大紫过,可能是没有资金的支撑,但根本的原因我觉得还是宣传的不到位,如果宣传到位了,那么自然会有资金到来的,但这一切并不妨碍BadUOM的优秀。作为UOM的鼓手,我愿意为之宣传。
------------------------
前言
好久都没有编程了,我从来都觉得自己根本就不会编程,心里有逻辑细节,就是写不出来。我想写一个小程序来阐述BadUOM及其它点对点UOM的技术原理,但我怕自己写出来的东西是垃圾,所以就一直都没有敢写,我想深入学习一下设计模式,学习一下Java的最新特性,然后再写...但是那恐怕会很久,也许就再也没有机会写了。
本着我的基本原则,不管好不好,先跑起来再说。趁着五一假期有点时间,我决定写一个点对点的UOM框架出来,一方面是为了给大家解释BadUOM的代码构成,另一方面是为了自己练习一下编程。我虽然不会编程,但也不是一点也不会,我稍微会一点。
本文中的UOM代码我尽量做到简单再简单,但这并不妨碍理解其技术本质,我们知道,github上有一个simpletun(https://github.com/gregnietsky/simpletun),这绝对是一个麻雀虽小,我脏俱全的代码,它对我们理解tun网卡十分有帮助。为了便于此后行文,仿照simpletun,我把本文中要写的UOM叫做SimpleUOM。
结构总览
SimpleUOM是一个点对点UOM框架,它非常类似于一种聊天软件的设计,所有的UOM节点,类似聊天客户端在启动的时候先向一个中心的服务器去注册,然后服务器收到注册消息后做两件事:
1.向其它所有的已注册节点通知,新节点注册了;
2.告诉新节点都有哪些节点已经注册。
经常聊QQ的再也熟悉不过这个场景了,如果我们刚刚登录QQ,一个在线用户列表便马上刷新出来,告诉新登录的自己谁在线,另外如果我们已经在线,那么一旦有人登录,伴随着一声咳嗽,那人就显示在线了。UOM的服务器所要做的,无无外乎也就是上面的两点。
再看UOM节点的逻辑,其实也不难,就把自己当成QQ客户端吧,当你登录后,你就可以跟任何好友进行聊天了,你和好友发送的消息不需要经过中间服务器中转,而是直达你好友机器的。对于UOM节点也一样,注册后会收到服务器推送下来的在线UOM节点的列表,每一个表项都包括足够丰富的信息,比如IP地址,端口,密钥协商参数什么的,只要UOM节点保存下来这些,那么就可以直接和感兴趣的节点进行直接UOM通信了。
在节点已经登录的期间,如果有其它新节点登录,该节点会收到新节点登录的消息。所以说UOM节点与服务器的交互中最重要的事只有一件,那就是接收服务端随时推送的“在线用户列表”,然后生成或者更新自己本地的邻居表并维护它。当真的需要通信的时候,那就相当于你已经知道源和目标,求如何通信的问题了,Socket编程总会吧,如果会的话,用TLS/DTLS也不难吧。
这就是全部吗?是的,这就是全部。
在本文中,我没有使用任何的复杂通用加密算法,只是用了普通的低级凯撒加密,即加密时将每一个字节二进制加1,解密时每一个字节二进制减1,仅此而已。原则上,你将此替换为OpenSSL的EVP系列调用实现真正的加解密,也是不难的。详情参考OpenUOM是怎么做的。
服务端代码
先看数据结构
1.可以代表一个UOM节点的元组
struct tuple {
char addr[16]; // 建立UOM通道的IP地址,可以向其发送UOM数据
unsigned short port; // 建立UOM通道的端口
unsigned short id; // UOM节点的唯一ID号
unsigned short unused; // 为了主机内数据对齐,未用,但是却增加网络的开销
} __attribute__((packed));
2.服务端回复的信息头部
struct ctrl_header {
unsigned short sid; // 固定为0
unsigned short did; // 回复到的UOM节点的ID标识
unsigned short num; // 一次通告中,一共包含多少邻居节点
unsigned short unused; // 未使用
} __attribute__((packed));
3.服务端发送到UOM节点的邻居表
struct control_frame {
struct ctrl_header header;
struct tuple tuple[0]; // 所有的要通告的邻居节点
} __attribute__((packed));
4.表示一个UOM节点的对象结构体
struct client {
struct list_head list; // 所有的UOM节点会链接在一起
struct tuple tuple; // 该节点的元组信息
int fd; // 保存与改UOM节点通话的文件描述符信息
void *others; // 其它信息,尽情发挥。但肯定与TLS/DTLS有关
};
5.全局的配置信息
struct config {
int listen_fd; // 侦听套接字
struct list_head clients; // 保存所有的已经登录的UOM节点
unsigned short tot_num; // 已经登录的UOM节点数目
};
再看服务端处理的源码
数据结构都明白了,源码自己也可以盲写,非常简单。
int client_msg_process(int fd, struct config *conf)
{
int ret = 0;
int i = 0;
size_t len = 0;
struct client *peer;
struct sockaddr_in addr;
char *saddr;
int port;
int addr_len = sizeof(struct sockaddr_in);
struct ctrl_header aheader = {0};
struct tuple newclient;
struct tuple *peers;
struct tuple *peers_base;
struct list_head *tmp;
bzero (&addr, sizeof(addr));
len = recv(fd, &newclient, sizeof(newclient), 0);
peer = (struct client *)calloc(1, sizeof(struct client));
if (!peer) {
return -1;
}
memcpy(peer->tuple.addr, &newclient.addr, sizeof(struct tuple));
peer->tuple.port = newclient.port;
peer->fd = fd;
INIT_LIST_HEAD(&peer->list);
aheader.sid = 0;
aheader.num = 0;
peers_base = peers = (struct tuple*)calloc(conf->tot_num, sizeof(struct tuple));
// 这个ID分配,着实不用这个丑陋的机制,用bitmap是我的最爱,或者哈希!
peer->tuple.id = conf->tot_num+1;
aheader.did = peer->tuple.id;
conf->tot_num ++;
// 以下for循环有两个作用:1.将新登录节点知会所有已登录节点;2.搜集已登录节点信息,准备知会新登录节点
list_for_each(tmp, &conf->clients) {
struct ctrl_header header = {0};
struct client *tmp_client = list_entry(tmp, struct client, list);
header.sid = 0;
header.did = tmp_client->tuple.id;
newclient.id = aheader.did;
header.num = 1;
send(tmp_client->fd, &header, sizeof(struct ctrl_header), 0);
send(tmp_client->fd, &newclient, sizeof(struct tuple), 0);
aheader.num += 1;
memcpy(peers->addr, tmp_client->tuple.addr, 16);
peers->port = tmp_client->tuple.port;
peers->id = tmp_client->tuple.id;
peers++;
}
// 发送给UOM节点头部消息
send(peer->fd, (const void *)&aheader, sizeof(struct ctrl_header), 0);
if (aheader.num) {
// 将所有其它已经登录的邻居通告给新注册节点
send(peer->fd, peers_base, aheader.num*sizeof(struct tuple), 0);
}
// 将新登录的用户链接入总的邻居节点
list_add_tail(&peer->list, &conf->clients);
return ret;
}好了,以上就是服务端代码了。当然,我可能遗忘了Linux内核list_head移植部分的讲解,也没有select/poll/epoll的优劣比较,不过我觉得,把这些写全不利于理解主要问题。
UOM节点代码
首先看结构体
1.以太网头部,不必多说
struct ethernet_header {
unsigned char dest[6];
unsigned char source[6];
unsigned short type;
} __attribute__((packed));
2.可以代表一个UOM节点的元组
struct tuple {
char addr[16];
unsigned short port;
unsigned short id;
unsigned short unused;
} __attribute__((packed));
3.回复给UOM节点的信息头
struct ctrl_header {
unsigned short sid; // 数据源的源ID号
unsigned short did; // 数据源的目标ID号
unsigned short num; // 一共回复给初创节点多少邻居数量
unsigned short unused;
} __attribute__((packed));
4.标识一个邻居节点
struct node_info {
struct list_head list; // 所有邻居要接在一起
struct tuple tuple; // 邻居的元组信息
struct list_head macs; // 该邻居虚拟子网一侧的Mac地址集合
void *other; // 其它的,尽情发挥。估计可以去往TLS/DTLS方面发挥。
};
5.一个物理地址必然要隶属于UOM节点
struct mac_entry {
struct list_head list;
struct list_head node; //struct hlist_node; // 很显然为了简单使用list_head,但实际上应该用哈希或者树来组织,用于查找
char mac[6]; // 保存MAC地址
struct node_info *peer; // 保存与该MAC地址相关的邻居
};
6.SimpleUOM的封装格式
struct frame {
unsigned short sid; // 发送方的ID
unsigned short did; // 接收方的ID
char data[1500]; // 数据。注意,为了简单,我写死了MTU为1500
int len; // 连同ID头部,数据的长度
} __attribute__((packed));注意,frame最前面是两个16bit的ID头字段,为什么要用到它呢?既然已经知道数据发给谁了,封装这个ID的意义又何在呢?SimpleUOM只是一个及其简单的Demo,实际上,为了支持组播,这个ID字段是必要的,我们把ID看作是组标识也是可以的。
7.控制通道的数据格式
struct control_frame {
struct ctrl_header header;
struct tuple tuple[0]; // 服务端通知新接入UOM节点时,可能有多个UOM节点已经接入了,一起打包通知
} __attribute__((packed));
8.处理栈
struct process_handler {
struct list_head list; // 所有的处理器模块连接为一个链表
struct node_info *peer; // 保存临时变量,其实用void *类型更好些
int (*send)(struct process_handler *this, struct frame *frame); // 从TAP到UDP Socket方向的处理
int (*receive)(struct process_handler *this, struct frame *frame); // 从UDP Socket到TAP方向的处理
struct config *conf; // 全局配置
}; 这个结构体表现了UOM处理的核心机制。一般而言,当UOM拿到裸数据后,到将其发出前,需要一系列的操作,比如先加密/摘要,然后封装协议头,最后发送,反过来当收到
网络数据后,要执行解除协议头,解密/验证摘要等反向的操作,所以我将它们成对组织起来:
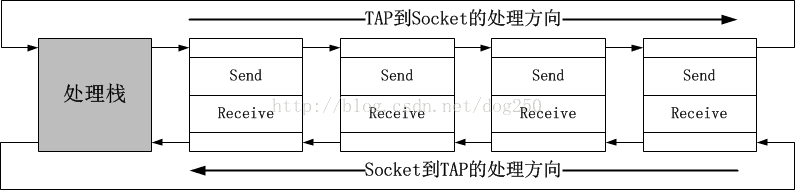

9.服务器标识
struct server {
char addr[16];
unsigned short port;
void *others; // 显然这里可以存储与构建TLS/DTLS相关的信息
};
10.全局配置
struct config {
struct node_info *self; // 标识自身
int tap_fd; // TAP虚拟网卡的描述符
int udp_fd; // UDP Socket的描述符
int ctrl_fd; // 与服务器通信的描述符
struct server server; // 服务器标识
struct list_head macs; // 本地所有学习到的MAC地址构建成的查找树,然则为了简单,我先实现成了链表
struct list_head peers; // 本地所有已知的邻居构建而成的邻居表
struct list_head stack; // 处理栈
struct list_head *first; // 处理栈的栈底
struct list_head *last; // 处理栈的栈顶
int num_handlers; // 处理器的长度
};所有以上的结构体之间的关系如下:
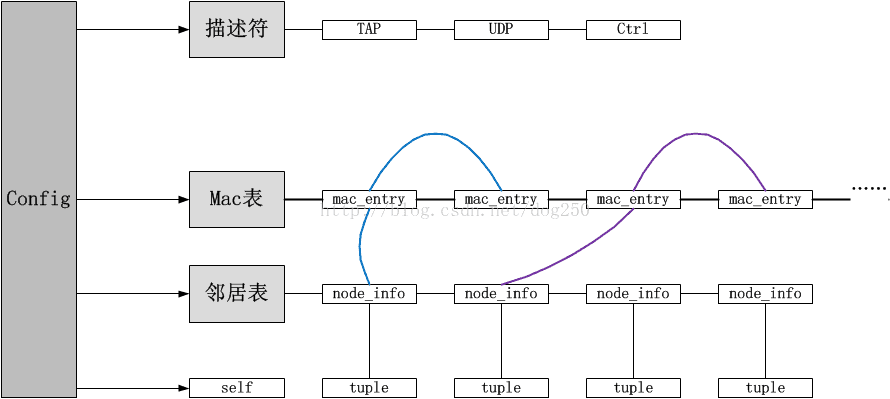
SimpleUOM源码分析
处理栈的逻辑:
int call_stack(struct config *conf, int dir)
{
int ret = 0;
struct process_handler *handler;
struct frame frame = {0};
int more = 1;
struct list_head *begin;
struct node_info *tmp_peer;
dir = !!dir;
// 根据方向参数获取处理栈顶或者处理栈底
if (dir) {
begin = conf->first;
} else {
begin = conf->last;
}
handler = list_entry(begin, struct process_handler, list);
tmp_peer = NULL;
while(handler) {
handler->peer = tmp_peer;
// 根据方向参数决定调用的方向
if (dir && handler->send) {
ret = handler->send(handler, &frame);
} else if (!dir && handler->receive) {
ret = handler->receive(handler, &frame);
}
if (ret) {
break;
}
tmp_peer = handler->peer;
// 如果遍历完了处理栈,则退出
if (dir && handler->list.next == &conf->stack) {
break;
}
if (!dir && handler->list.prev == &conf->stack) {
break;
}
// 否则,取下一个处理模块
if (dir) {
handler = list_entry(handler->list.next, struct process_handler, list);
} else {
handler = list_entry(handler->list.prev, struct process_handler, list);
}
}
return ret;
}接下来就很简单了,定义几个process_handler结构体以及回调即可,比如下面的一对:
int read_from_tap(struct process_handler *obj, struct frame *frame)
{
int ret = 0;
int fd = obj->conf->tap_fd;
size_t len;
len = read(fd, frame->data, sizeof(frame->data));
frame->len = len;
return ret;
}
int write_to_tap(struct process_handler *obj, struct frame *frame)
{
int ret = 0;
int fd = obj->conf->tap_fd;
size_t len;
len = write(fd, frame->data, sizeof(frame->data));
return ret;
}
static struct process_handler tap_handler = {
.send = read_from_tap,
.receive = write_to_tap,
}; 代码就不解释了,太简单。我下面注释一对比较复杂的handler逻辑。
--------------------------------------------------
当从TAP收到帧之后,要根据其MAC地址找到对应的邻居,这个查找过程和交换机的查找过程非常类似,基本就是下面的逻辑:
int frame_routing(struct process_handler *obj, struct frame *frame)
{
int ret = 0;
struct ethernet_header eh;
struct list_head *tmp;
memcpy(&eh, frame->data, sizeof(eh));
list_for_each(tmp, &obj->conf->macs) {
struct mac_entry *tmp_entry = list_entry(tmp, struct mac_entry, node);
if (!memcmp(eh.dest, tmp_entry->mac, 6)) {
// 找到了明确的邻居出口。
obj->peer = tmp_entry->peer;
break;
}
}
// 如果obj->peer为NULL,即没有明确地邻居出口,那么应该对所有节点广播。
return ret;
}如果反过来,数据从Socket收到,那么就会经历一个MAC学习的过程,这个和交换机也是类似的:
int mac_learning(struct process_handler *obj, struct frame *frame)
{
int ret = 0;
struct mac_entry *entry = NULL;
struct ethernet_header eh;
struct list_head *tmp;
memcpy(&eh, frame->data, sizeof(eh));
list_for_each(tmp, &obj->conf->macs) {
struct mac_entry *tmp_entry = list_entry(tmp, struct mac_entry, node);
if (!memcmp(eh.source, tmp_entry->mac, 6)) {
entry = tmp_entry;
break;
}
}
// 如果找到了表项,那么更新它
if (entry) {
list_del(&entry->list);
list_del(&entry->node);
} else {
entry = (struct mac_entry *)calloc(1, sizeof(struct mac_entry));
}
if (!entry) {
printf("Alloc entry failedn");
return -1;
}
// 更新或者添加表项
memcpy(entry->mac, eh.source, 6);
entry->peer = obj->peer;
INIT_LIST_HEAD(&entry->list);
list_add(&entry->list, &entry->peer->macs);
INIT_LIST_HEAD(&entry->node);
list_add(&entry->node, &obj->conf->macs);
return ret;
}最后,将上述的逻辑插入到一个处理模块routing_handler里即可:
static struct process_handler routing_handler = {
.send = frame_routing,
.receive = mac_learning,
};其它的处理就不多说了,如果你想用TLS/DTLS或者用DH算法协商出来的密钥进行加密,那么再写一个process_handler即可。我接下啦展示一下一个处理模块是如何注册到系统的,其实也很简单,就是一堆链表操作:
int register_handler(struct process_handler *handler, struct config *conf)
{
INIT_LIST_HEAD(&handler->list);
handler->conf = conf;
list_add_tail(&handler->list, &conf->stack);
if (conf->first == NULL) {
conf->first = &handler->list;
}
conf->last = &handler->list;
return 0;
}
最后,我们来看看总体的逻辑,即main函数:
int main(int argc, char **argv)
{
char serverIP[16];
char localIP[16];
unsigned short serverPORT;
unsigned short localPORT;
struct config conf;
if (argc != 5) {
printf("./a.out serverIP serverPORT localIP localPORTn");
}
strcpy(serverIP, argv[1]);
serverPORT = atoi(argv[2]);
strcpy(localIP, argv[3]);
localPORT = atoi(argv[4]);
init_config(&conf);
init_tap(&conf);
init_self(&conf, localIP, localPORT);
register_handler(&tap_handler, &conf);
register_handler(&routing_handler, &conf);
register_handler(&protocol_handler, &conf);
register_handler(&enc_handler, &conf);
register_handler(&udp_handler, &conf);
init_server_connect(&conf, serverIP, serverPORT); // 连接服务器
server_msg_register(&conf); // 注册自己
server_msg_read(&conf); // 读取服务器推送的邻居并建立邻居表
main_loop(&conf); // select三个文件描述符
return 0;
}好了,以上就是核心的代码分析。全部的代码在github上:https://github.com/marywangran/SimpleU-O-M-/
SimpleUOM如何跑起来
测试说明:三台机器,机器0作为服务器,机器1和机器2作为UOM节点,三台机器均有两块网卡,处在两个C段,分别为192.168.44.0/24和1.1.1.0/24,其中机器0的1.1.1.0/24段不接网线。
编译服务端:gcc CtrlCenter.c
运行服务端:./a.out 192.168.44.100 7000
编译UOM节点:gcc SimpleUOM.c
运行UOM节点:
机器1上运行:
tunctl -u root -t tap0
ifconfig tap0 10.10.10.129/24
./a.out 192.168.44.100 7000 1.1.1.1 100
机器2上运行:
tunctl -u root -t tap0
ifconfig tap0 10.10.10.131/24
./a.out 192.168.44.100 7000 1.1.1.3 100
然后在机器1上ping机器2的tap0地址。
后面的说明
如果说仅仅是为了炫技,那么就不要轻易设计自己的四层协议!
明明已经有了TCP和UDP,还要再设计一个新的四层协议,这会造成损失。还记得VXLAN和NVGRE的区别吗?VXLAN使用了通用的UDP来封装,而NVGRE则没有,这就使得NVGRE几乎不能适配基于UDP元组的负载均衡。仔细想想OpenUOM,幸亏它采用了UDP封装...它可以无缝适配Linux自带的reuseport机制来简单负载均衡,不然负载均衡都得自己写。我记得最初的负载均衡是我在IP层用nf_conntrack来做的,其实我之所以用nf_conntrack来做,那是因为那时我并不知道reuseport...如果没有reuseport,然后你还不懂nf_conntrack,那就得花费大量的精力去优化OpenUOM服务端的负载均衡或者多处理。
在网络虚拟化方面,其中也包括一些UOM技术,很多厂商都在做这块,我们来看看如今他们分属的阵营,我大致将它们分为网络阵营和软件阵营,我比较倾向于网络阵营。
我大致分下类,VXLAN,VN-TAG,这些倡导者都属于网络阵营,比如Cisco,IETF,而像NVGRE,VEPA,SSL这种,基本都是软件阵营,比如倡导者是微软,HP之流,然而我们发现,这两个阵营谁也压不倒谁,在VXLAN和NVGRE的PK中,网络阵营完胜,但在VN-TAG和VEPA的较量中,网络阵营又输的比较惨淡...Why?
是该联合起来的时候了。我们发现,赢的那一方一定是便宜的那一方,一定是简单的那一方。所以我一向提倡炫技者止步的意义就在于此。同轴电缆复杂吧,输给了简单便宜的双绞线,魏国武卒昂贵吧,却输给了秦国农民军...
快到中午了,令人遗憾的五一劳动节...
原文链接: https://blog.csdn.net/dog250/article/details/70945840
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍;
也有高质量的技术群,里面有嵌入式、搜广推等BAT大佬

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/405890
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!