
在前面的文章中,我经常提到bufferbloat,关于这个词的解释,我几乎都是明嘲暗讽地把锅甩到Reno/CUBIC这类基于AIMD的算法身上,声称它们是 buffer友好的 ,必须填充buffer的 , 随之而来的就有设备厂商的推波助澜,用越来越大的buffer赢得用户的普遍认可,反过来促进buffer进一步被Reno/CUBIC填满,如此一个类似Windows-Intel的循环…
然而这却不是本质,那么本质是什么?还得从Jacobson的原始论文中挖掘:
http://www.cs.binghamton.edu/~nael/cs428-528/deeper/jacobson-congestion.pdf
我把Jacobson管道画成了下面的样子:
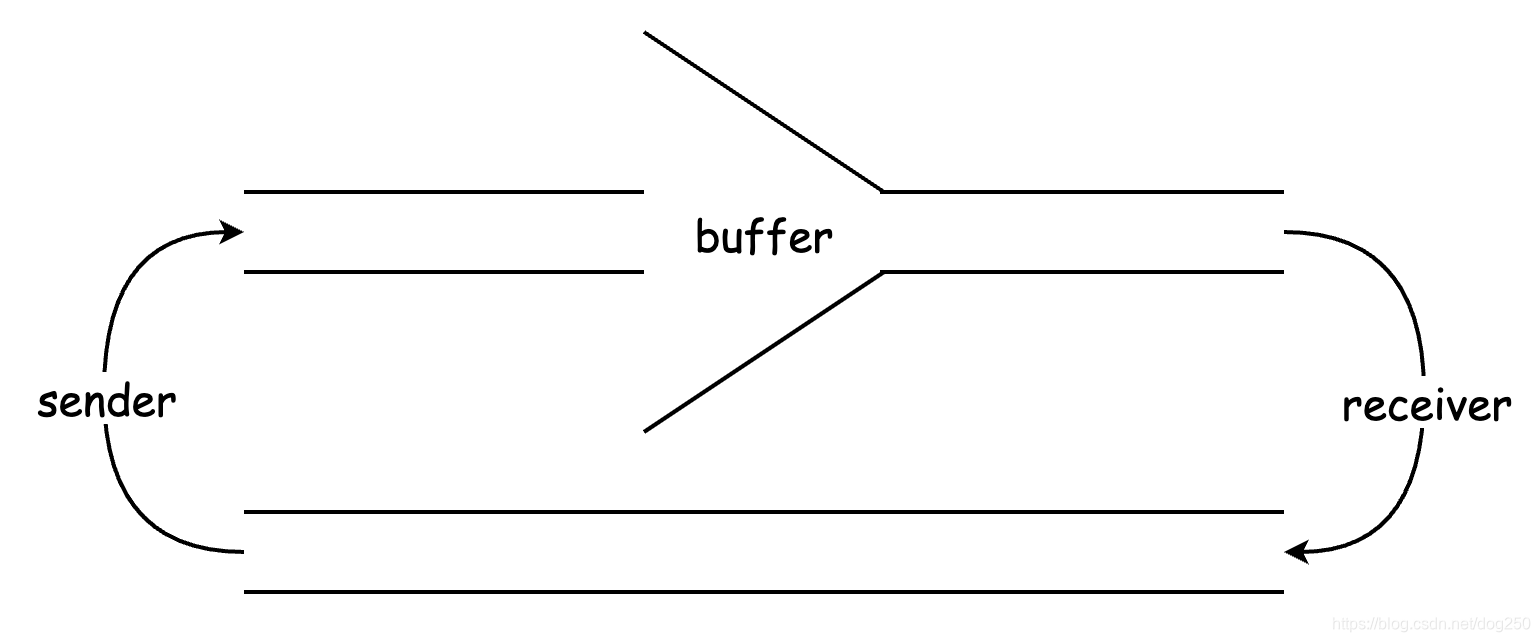

buffer是Jacobson的AIMD算法必须的,buffer是AIMD算法起作用的决定性部件。
Jacobson希望理想情况下即便部署了拥塞控制也依然可以获得100%的带宽利用率,拥塞控制机制通过buffer的周期性overflow来进行收敛,因此,当buffer被填满时,整个BDP最大:
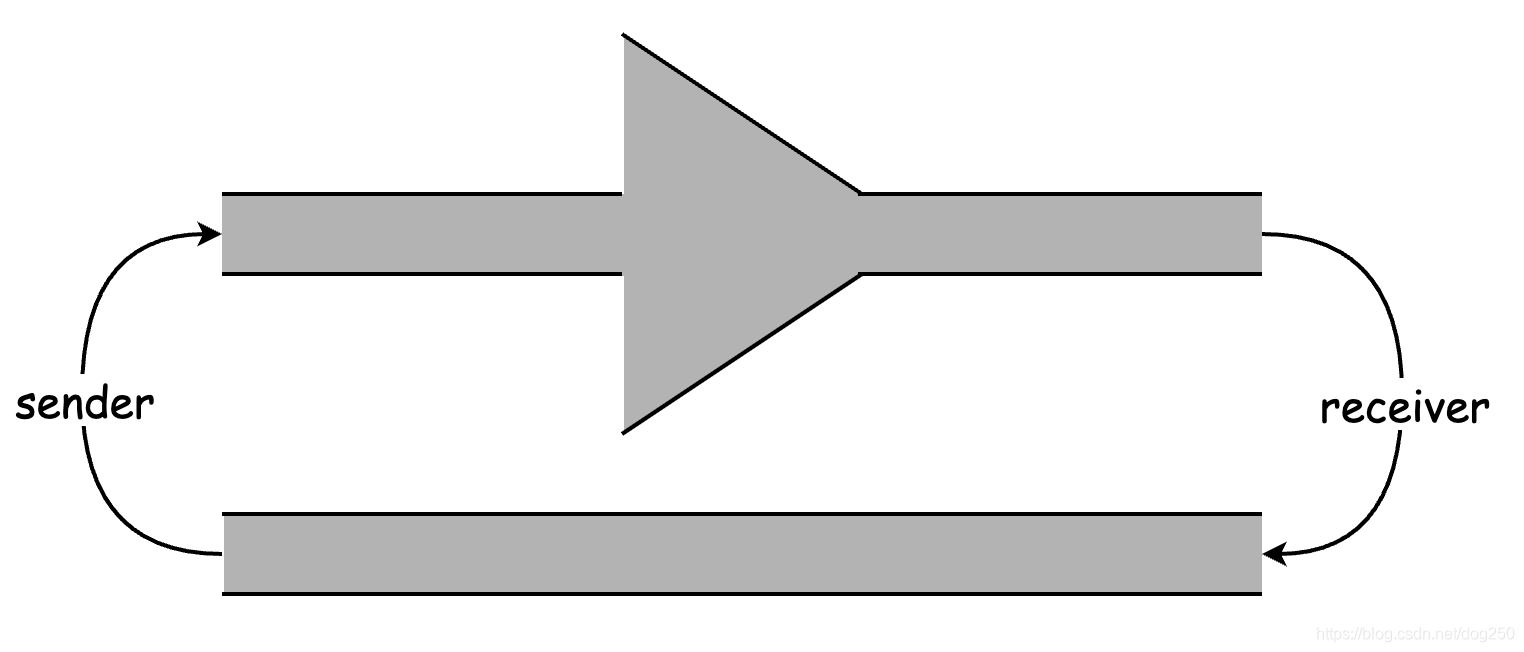
而当buffer被清空时,整个BDP最小:
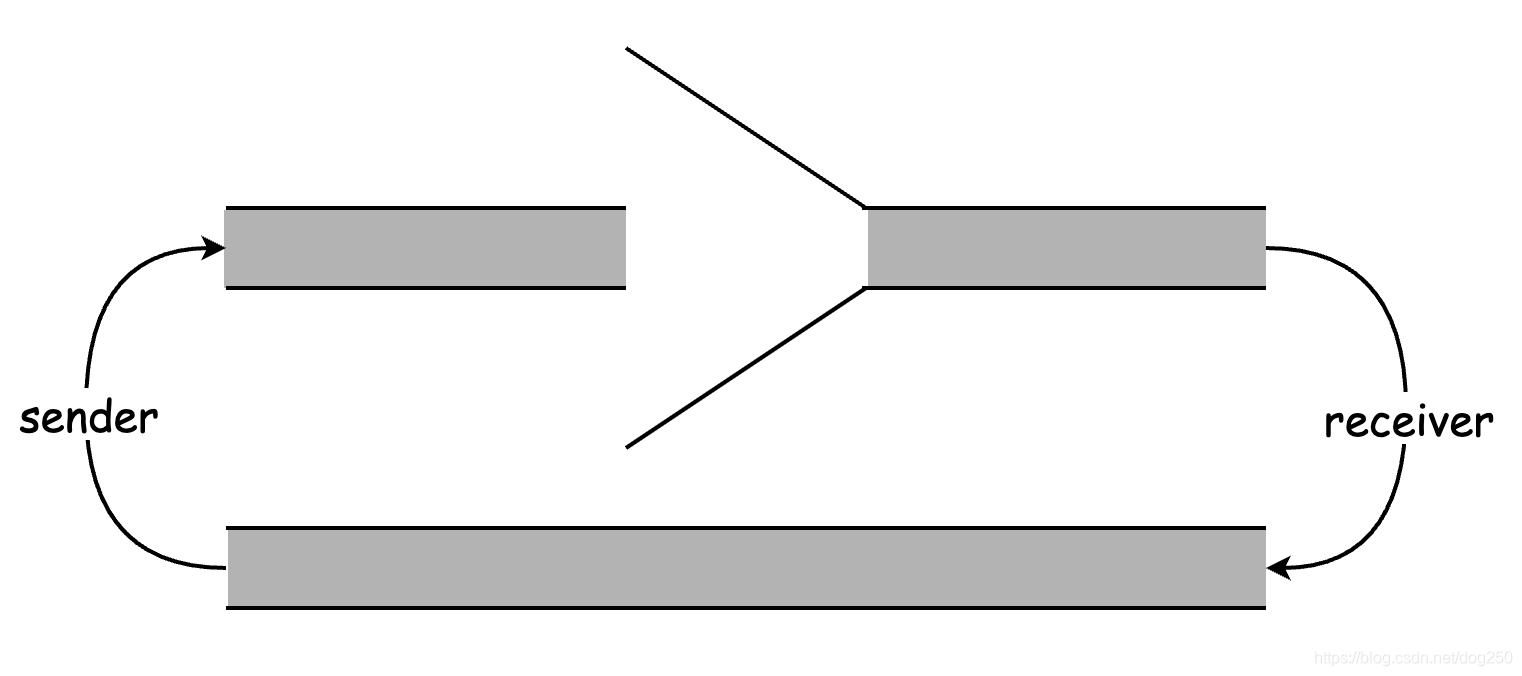
Jacobson希望他的管道在上述两个状态之间切换,显而易见,buffer清空时的状态就是MD之后的状态。
整个BDP管道可以分为两个部分:
- 网络链路
b
u
f
f
e
r
1
buffer_1
buffer1:带有时间延展性的第一类缓存。 - 队列缓存
b
u
f
f
e
r
2
buffer_2
buffer2:带有时间墙的第二类缓存。
那么有下面的关系:
B
D
P
m
a
x
=
b
u
f
f
e
r
1
+
b
u
f
f
e
r
2
BDP_{max}=buffer_1+buffer_2
BDPmax=buffer1+buffer2
B
D
P
m
i
n
=
b
u
f
f
e
r
1
BDP_{min}=buffer_1
BDPmin=buffer1
B
D
P
m
i
n
=
(
1
−
β
)
B
D
P
m
a
x
BDP_{min}=(1-\beta)BDP_{max}
BDPmin=(1−β)BDPmax
因此,很容易导出
b
u
f
f
e
r
1
buffer_1
buffer1和
b
u
f
f
e
r
2
buffer_2
buffer2的关系:
b
u
f
f
e
r
2
=
1
−
β
β
b
u
f
f
e
r
1
buffer_2=\dfrac{1-\beta}{\beta}buffer_1
buffer2=β1−βbuffer1
对于Reno算法,
β
=
0.5
\beta=0.5
β=0.5,队列buffer需要至少等于一个带宽和传播时延乘积。
我们看看
b
u
f
f
e
r
1
buffer_1
buffer1,它显然是
B
l
t
B
W
×
R
T
p
r
o
p
BltBW\times RTprop
BltBW×RTprop,即带宽和物理传播时延的乘积。把传播速度假设成光速的话,确定的两个地点之间的
R
T
p
r
o
p
RTprop
RTprop是固定的值,那么
b
u
f
f
e
r
2
buffer_2
buffer2的值将由
B
l
t
B
W
BltBW
BltBW决定。那么请看下面的图示:
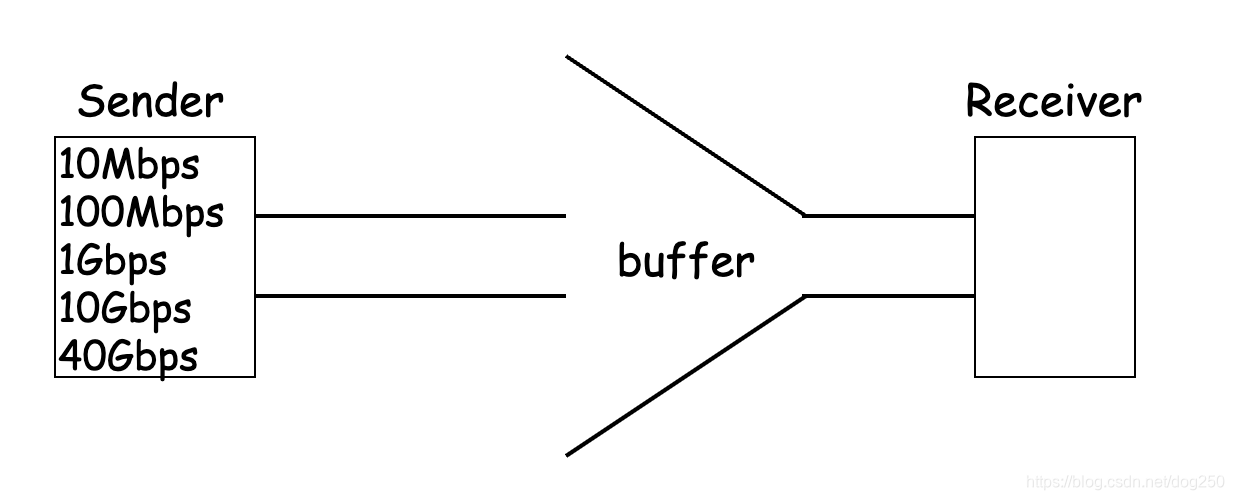
随着网卡和链路带宽的不断提高,若要AIMD算法在不损BltBW的前提下继续起作用,显然buffer 必须 同步增加,也就是说,带宽扩大100倍,buffer也要扩大100倍,这是不可想象的!这个事实背后的摩尔定律让路由器最终不堪重负。
在一篇名为Deprecating The TCP Macroscopic Model的论文中,有下列陈述:
The key parameter of a network queue is drain time: how long does it take for a full queue to completely drain through the bottleneck if no additional packets arrive? If the drain time is slightly larger than the path round trip time it turns out to be fairly easy for Jacobson88 style congestion control to maintain a queue at the bottleneck and attain 100% utilization across a wide range of conditions.
…
However, Moore’s law dooms large buffers deep in the interior of the Internet. The problem is that maintaining constant drain time in the presence of ever increasing interface (link) speeds requires that the pace of progress for the queue buffer memory exceeds Moore’s law. Colloquially Moore’s law states that the product of speed (clock rate) and complexity (device count) doubles every 18 months. Consider the following thought experiment: Internet data rates have been doubling roughly every 2 years (slightly slower than Moore’s law). To maintain constant drain time the queue buffer memory has to double in size every 2 years. It also has to double in speed every 2 years. With data rates doubling every 2 years, the speed-complexity product for buffer memory has to double every year to maintain constant drain time. There is no cost effective way to do this, and as a consequence over a span of decades the available drain times have been dropping for the fastest devices on the network.
…
At the same time the Internet edge has developed the opposite problem: in home networks where data rates are relatively low (typically 1 Gb/s and below), it is easy to build large buffers with plenty of bandwidth. These devices can have queue drain times in the seconds or tens of seconds range, a problem known as BufferBloat[20].
参见:https://ccronline.sigcomm.org/wp-content/uploads/2019/10/acmdl19-323.pdf
这就是bufferbloat的根源,buffer必然随着带宽的增加不断增大以确保新速度下的AIMD算法继续起作用,显然,这是不可持续的。
因此新近的CCA均开拓了另一个方向,即BBR的思路,采用pacing的方式动态探测链路的BltBW,而不再盲目地burst填充buffer。包括copa在内的很多新CCA均采取了如此的思路。copa的链接在:
http://people.csail.mit.edu/venkatar/copa.pdf
事实上,CCA是可以按照 “如何看待网络” 的方式进行分类的:
- 黑盒CCA:网络就是一个黑盒子,基于一个数学模型进行收敛,比如AIMD系列的Reno/CUBIC。
- 灰盒CCA:网络稍微可知,动态测量网络度量值,比如吞吐,RTT用于决定发送策略,比如BBR,copa。
- 白盒CCA:网络完全可知,虽然这对于CCA最好,但违背了互联网 Intelligence Edge & Dummy Core 的原则。
对于黑盒子CCA,CCA对网络一无所知,仅仅依靠一个数学模型,所有一切落实到一个公式上:
t
=
c
p
−
1
d
t=cp^{-\frac{1}{d}}
t=cp−d1
其中
p
p
p为丢包率,
c
c
c,
d
d
d为AIMD的参数。
这个公式里可以看出,对于一个特定的CCA,只有
p
p
p决定了吞吐率,而
p
p
p则是排除了随机噪声丢包后的buffer overflow导致的丢包,对于特定的buffer大小,
p
p
p是一定的。我们可以很清楚看出buffer对于AIMD起作用的决定性因素,如果需要得到更大的吞吐
t
t
t,显然需要更小的丢包率
p
p
p,更小的丢包率
p
p
p意味着更大的buffer。
然而如果我们拥有了更多的网络表征值,那就意味着buffer的作用减小了,buffer最终会回归到它本来的作用。buffer的作用是 用来平滑柏松到达的。
说BBR开启了一个新的时代,其意义大概也就在于此吧。bufferbloat问题需要从根源解决,其根源就是Jacobson管道需要buffer来执行AIMD,若新算法不再以buffer为必须,那便拔掉了旧时代的根基。
浙江温州皮鞋湿,下雨进水不会胖。
原文链接: https://blog.csdn.net/dog250/article/details/114157475
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍;
也有高质量的技术群,里面有嵌入式、搜广推等BAT大佬

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/405763
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!