
如果一个算法的某处说明没有数学支撑,那肯定是不能令人放心的,BBR的收敛性模型从来都是模糊的,不如AIMD那样直接,但还是有一些有意思的动力学过程在里面的。
在Neal Cardwell的github里藏着一篇关于BBR收敛动力学的文档 BBR bandwidth-based convergence :
https://github.com/google/bbr/commit/c38ae279b67fe1e9b485903daa3f808f7c6e44d4
这篇文档的结论是:
- 初始化带宽越小的流在up probe之后获得的加速比越大。
该结论对应的截图如下:
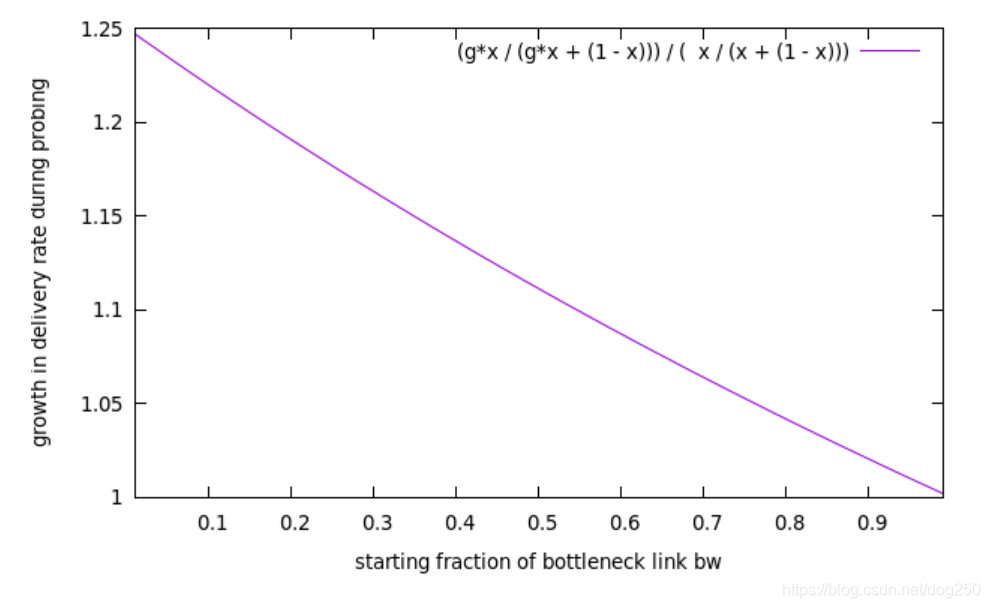

以下是Neal的推导过程:

看完了这个推导,我在BBR的convergence region坐标里画了一个具体的收敛过程。
我自中学就喜欢各种几何,所以一有实际问题,我总喜欢把它们摆在一个坐标系里比划,我对在坐标系里解决问题的方法情有独钟,这也算是我的一种方法论。
首先我来解释一下convergence region坐标系各个元素的含义:
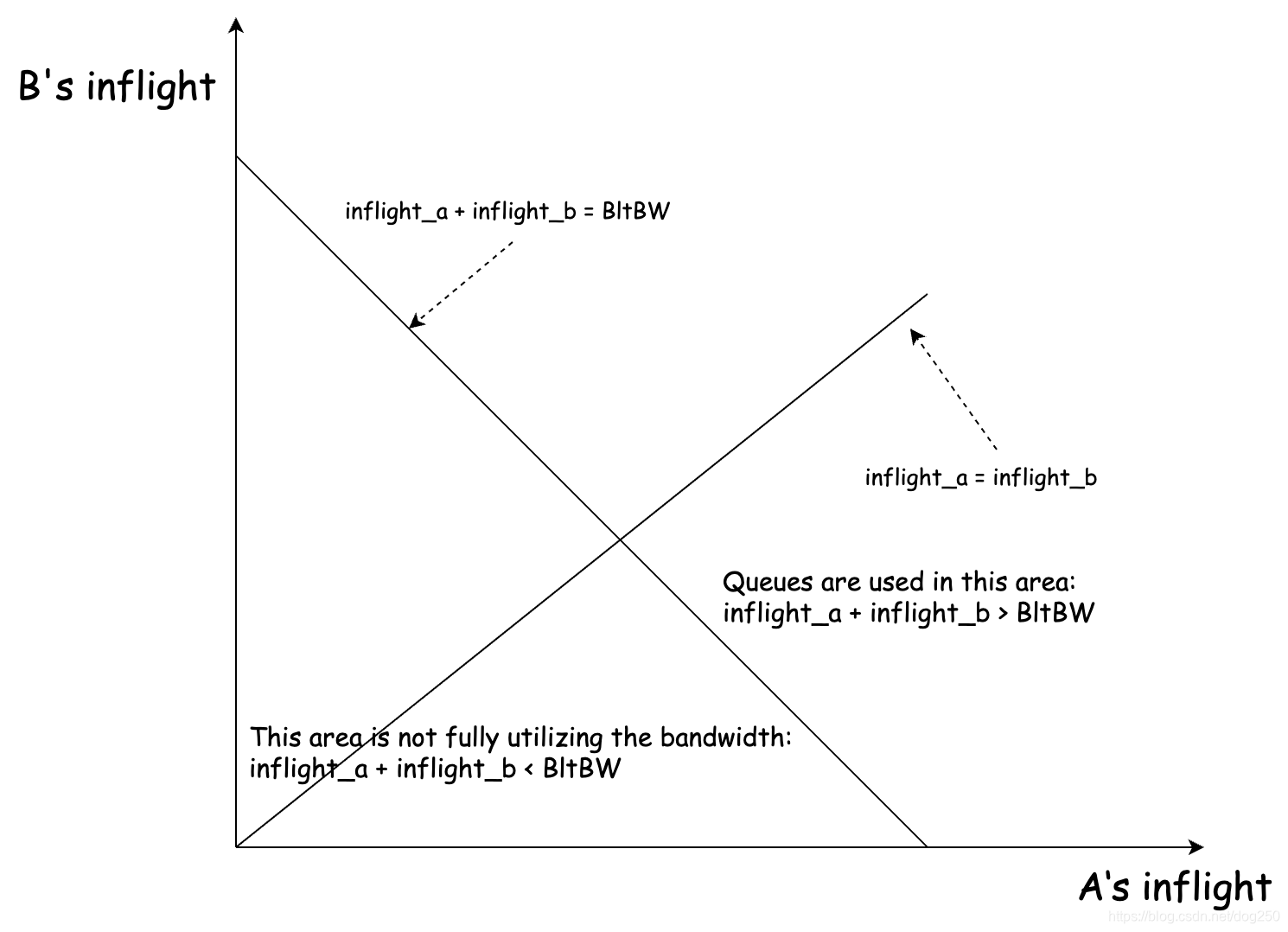
总带宽为1的约束下,设A,B两条流初始带宽分别为
a
a
a和
1
−
a
1-a
1−a,则该状态在convergence region坐标系的坐标为
(
a
,
1
−
a
)
(a,1-a)
(a,1−a),如果它们分别up probe一次,则它们将获得不同的带宽,于是便可以得到A,B两条流各自的带宽增量表达式。
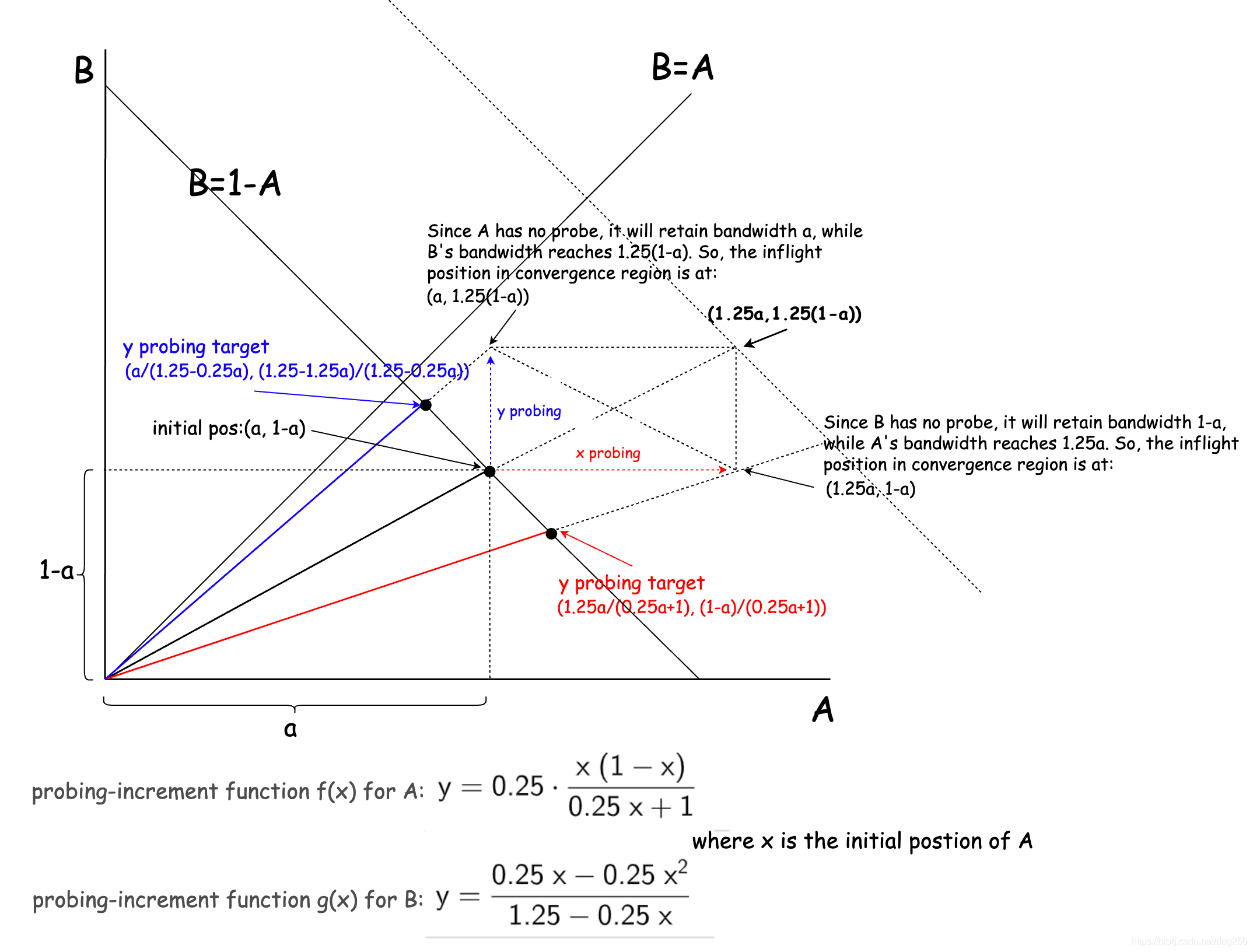
注意,坐标系中各个点的坐标通过解析几何的各种方法很容易计算,比如直线求交点。
用变量
x
x
x替换
a
a
a,即
x
x
x为共享带宽为1的A,B两条流中A的带宽,两条流分别up probe之后,其各自带宽增量的函数表达式:
- probing-increment function for A:
f
(
x
)
=
0.25
x
(
1
−
x
)
0.25
x
+
1
f(x)=0.25\dfrac{x(1-x)}{0.25x+1}
f(x)=0.250.25x+1x(1−x)
- probing-increment function for B:
g
(
x
)
=
0.25
x
(
x
−
1
)
1.25
−
0.25
x
g(x)=0.25\dfrac{x(x-1)}{1.25-0.25x}
g(x)=0.251.25−0.25xx(x−1)
用GeoGebra画出二者的图像:
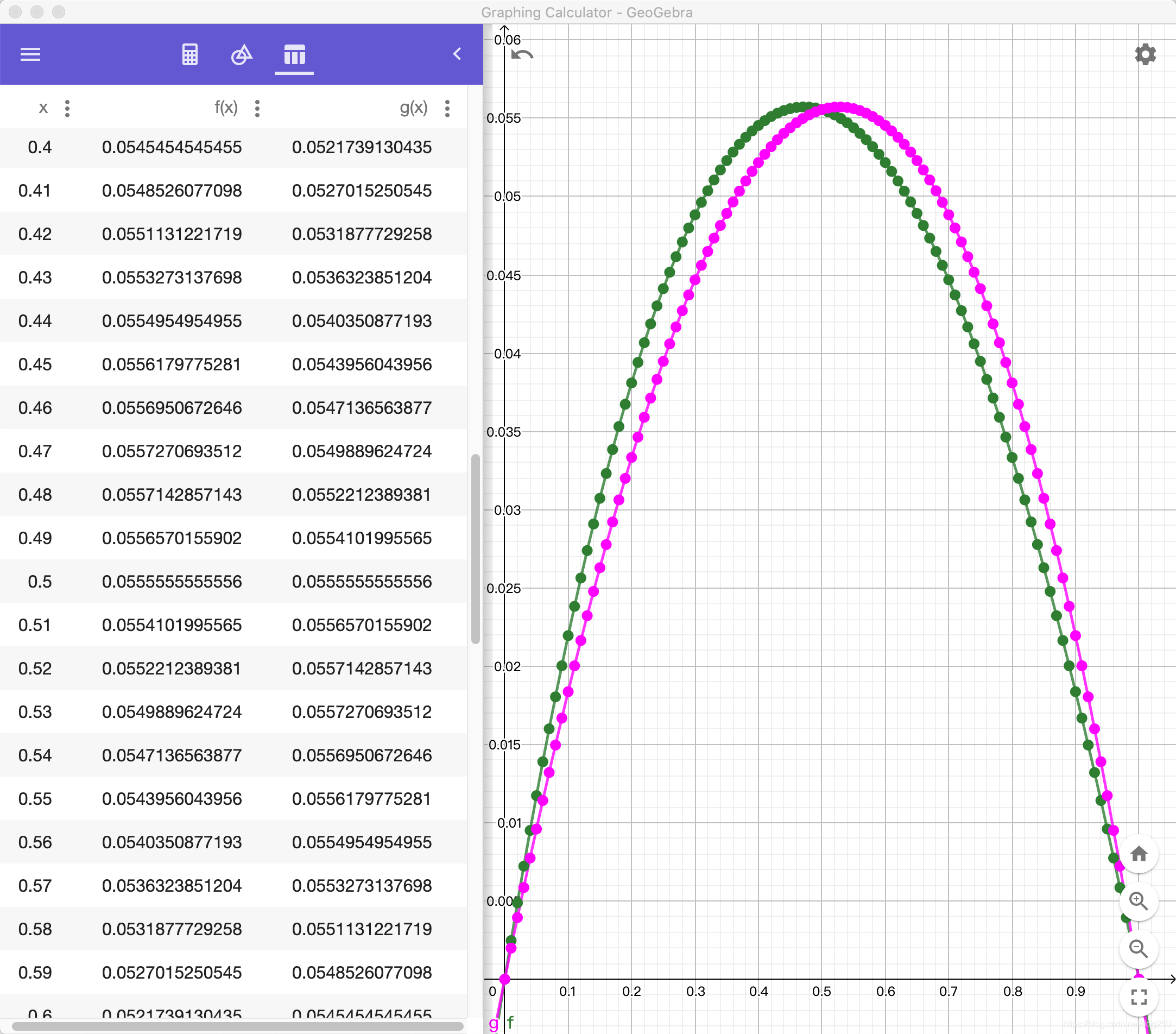
很清楚地看到二者在
x
=
0.5
x=0.5
x=0.5处相交,且关于
x
=
0.5
x=0.5
x=0.5对称。当
x
>
0.5
x>0.5
x>0.5时,B的带宽小于A,B的up probe加速比大于A,反之,
x
<
0.5
x<0.5
x<0.5时,B的带宽大于A,B的up probe加速比小于A。
下面是A,B两条流在ProbeBW状态的收敛过程(先不管ProbeRTT状态):
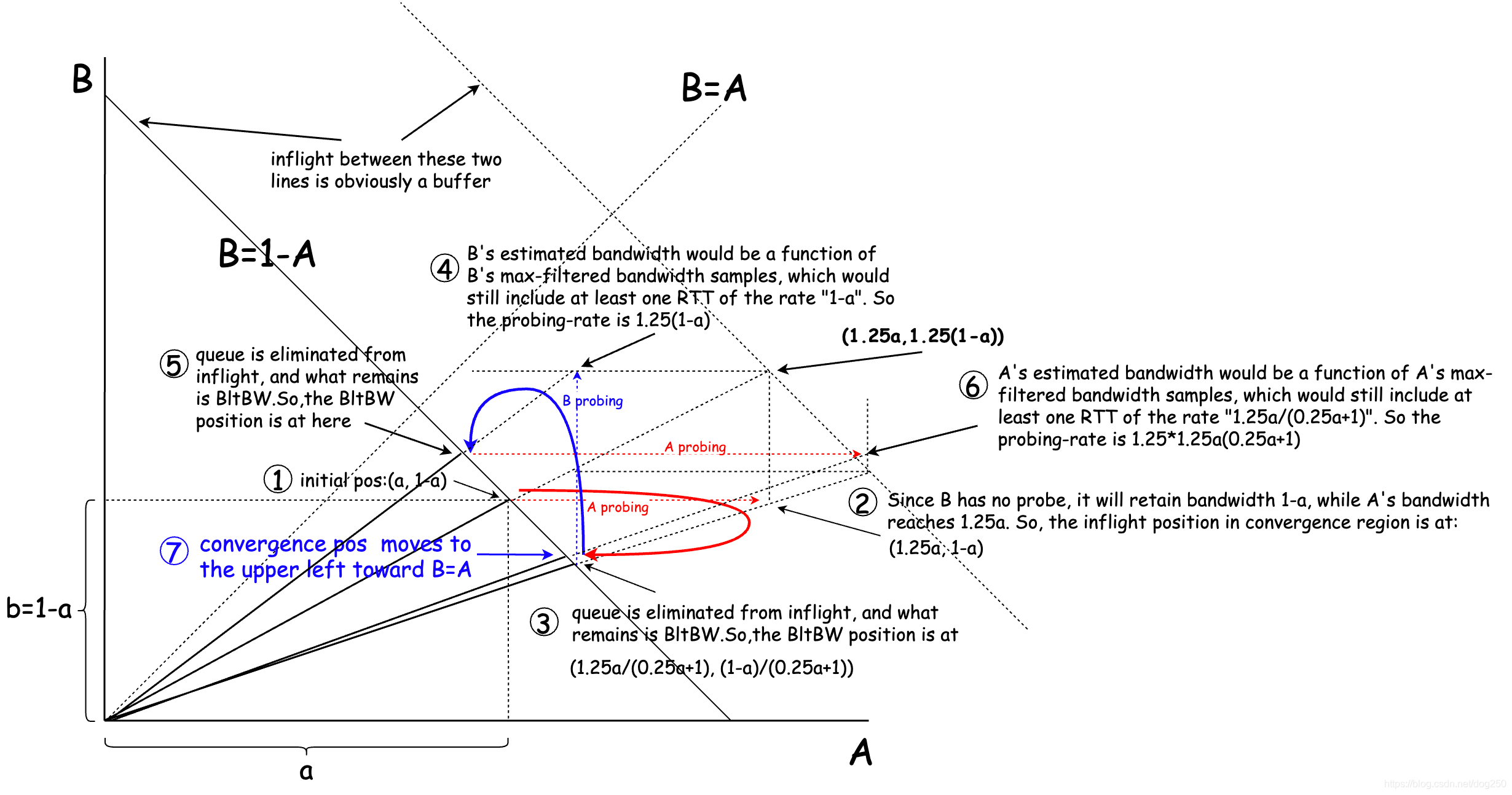
不断收敛的BltBW坐标在convergence region坐标系中攀爬的典型过程如下:
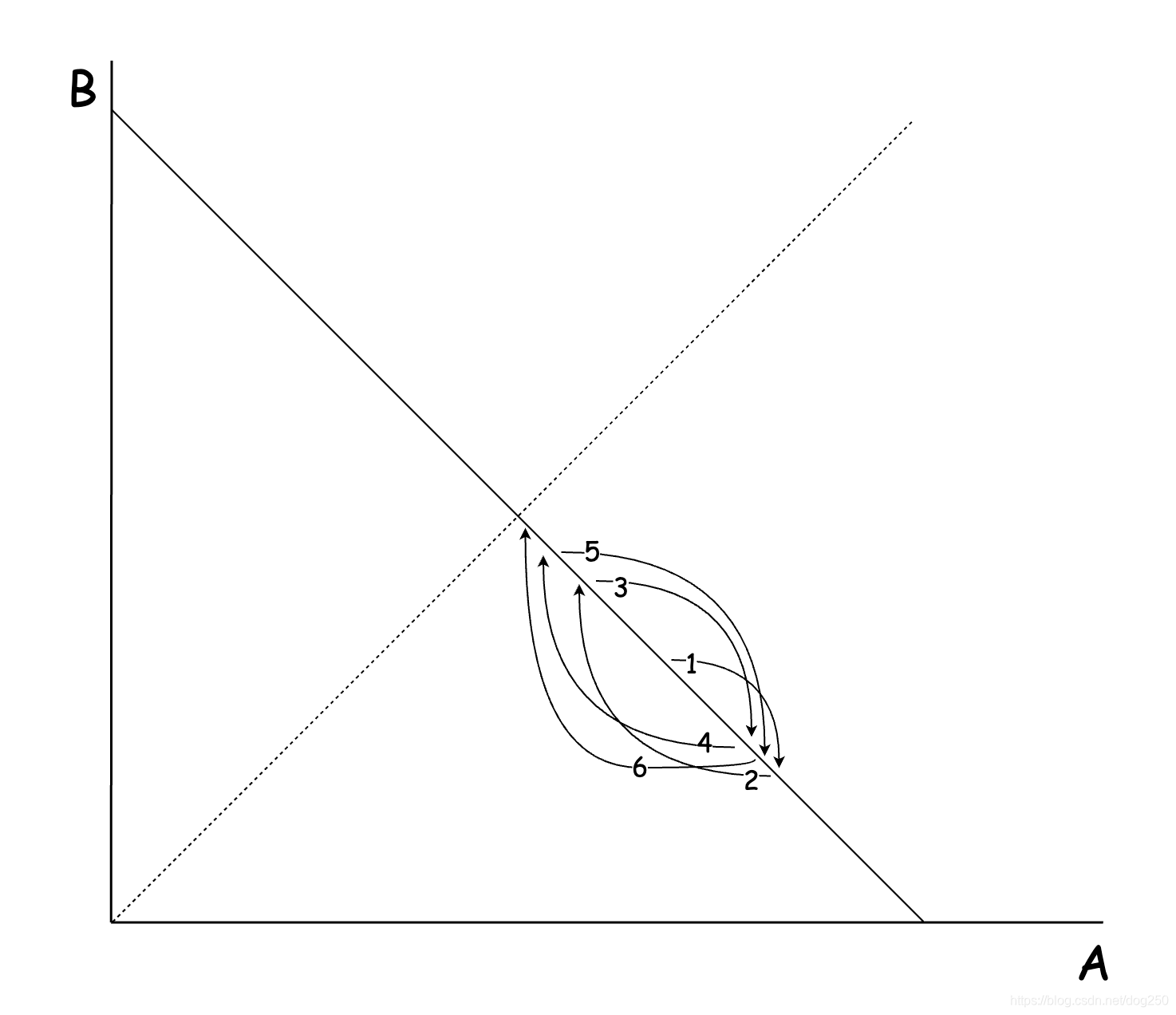
这个ProbeBW状态下收敛过程的核心正是那个时间窗口内的max-filter函数,它可以让一条流继续使用已经被抢占的带宽继续up probe,这个正是Neal推导的那个带宽与加速比的负相关性得以运作的核心:
- max BltBW是即时采集到的,但max BltBW的衰减是缓慢进行的,利用时间差来进行up probe的收敛。
如果没有上述不对称的过程,假设BltBW的感知是即时的,当使用即时的BltBW去进行up probe的时候,事实上是不会收敛的:
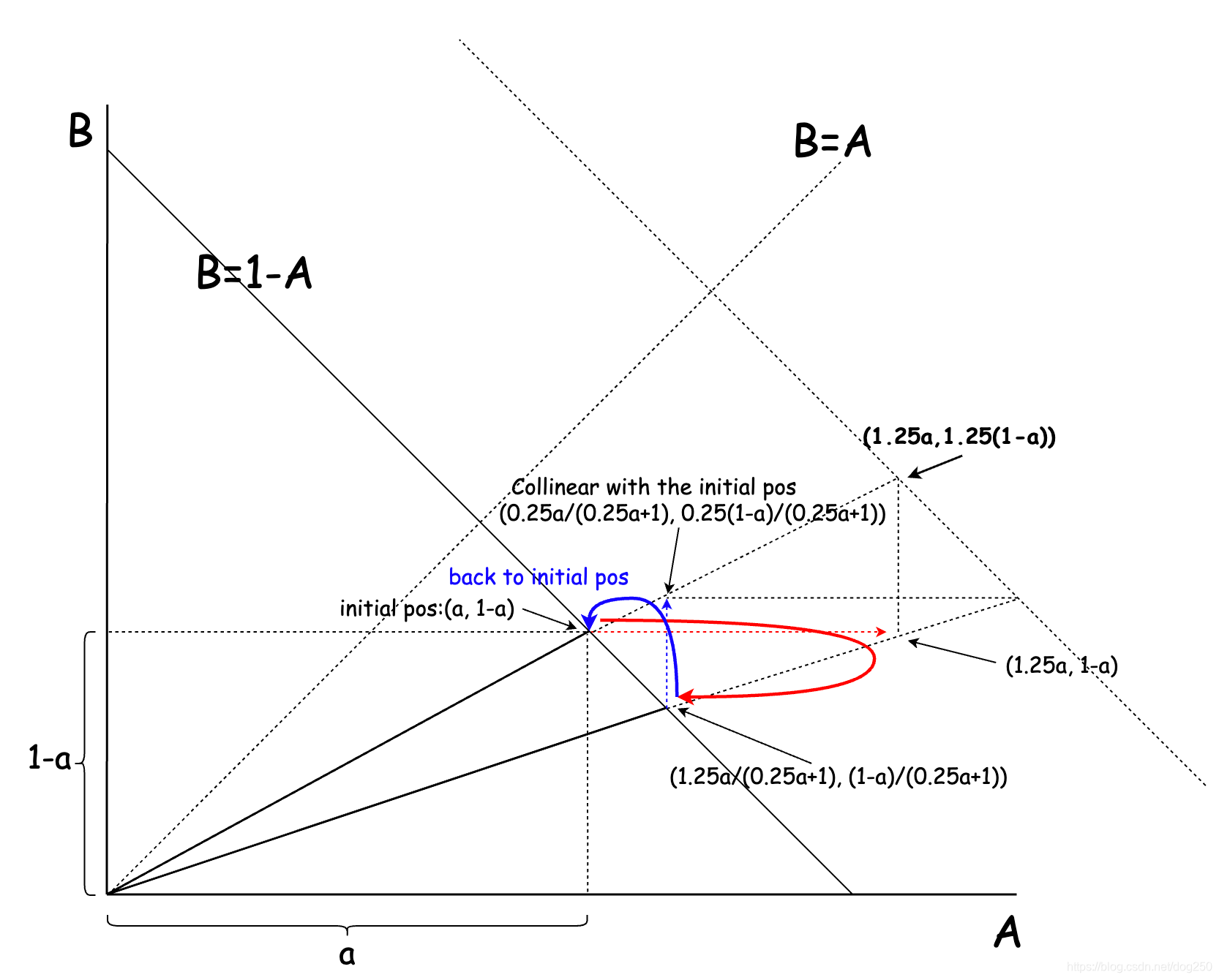
这明显是一个MAMD(Multiplicative Increase and Multiplicative Decrease)过程,inflight按照乘性系数伸缩,收敛点永远在同一条直线上。
所以说,不能离开max-filter函数。这就是 Note that even after flow A probes, flow B’s estimated bandwidth would be a function of B’s max-filtered bandwidth samples, which would still include at least one round-trip of the rate “b”. So when sender B probes, it will be sending at a rate 1.25b. 这句话的直观解释。
max-filtered bandwidth samples意义重大。
虽然BBR在ProbeBW状态可以完成收敛,但为了确保BBR的正常运行,ProbeRTT状态是必不可少的,这个状态保证了RTprop的有效性。只要一个大象流进入了ProbeRTT状态,所有的流均将同时采集到RTprop,于是BBR天然地完成ProbeRTT状态的全局同步,而ProbeRTT之后即将进入ProbeBW之前,这里正是一个良好的收敛点,BBR在这里randomized了所有即将进入ProbeBW状态的流的ProbeBW phase,如此,BBR的收敛机制在这个几乎排空的管道里开始运行,someone probes for bandwidth while the other flow does not…
早些年,我不自量力地魔改BBR。
我随机化进入ProbeRTT的时间,却不知道如此便破坏了同步点后的公平收敛;我增加了两个cruise phase,却不知道这样就丢失了max-filter函数返回的max bw,ProbeBW状态的流再也无法收敛…
我们来看看在正确理论的指导下,如何调整gain系数。如果你不想要1.25了,那么换成多少好呢?如果比1.25大,会带来什么,如果比1.25小,又意味着什么?把增量函数画出来就明了了:
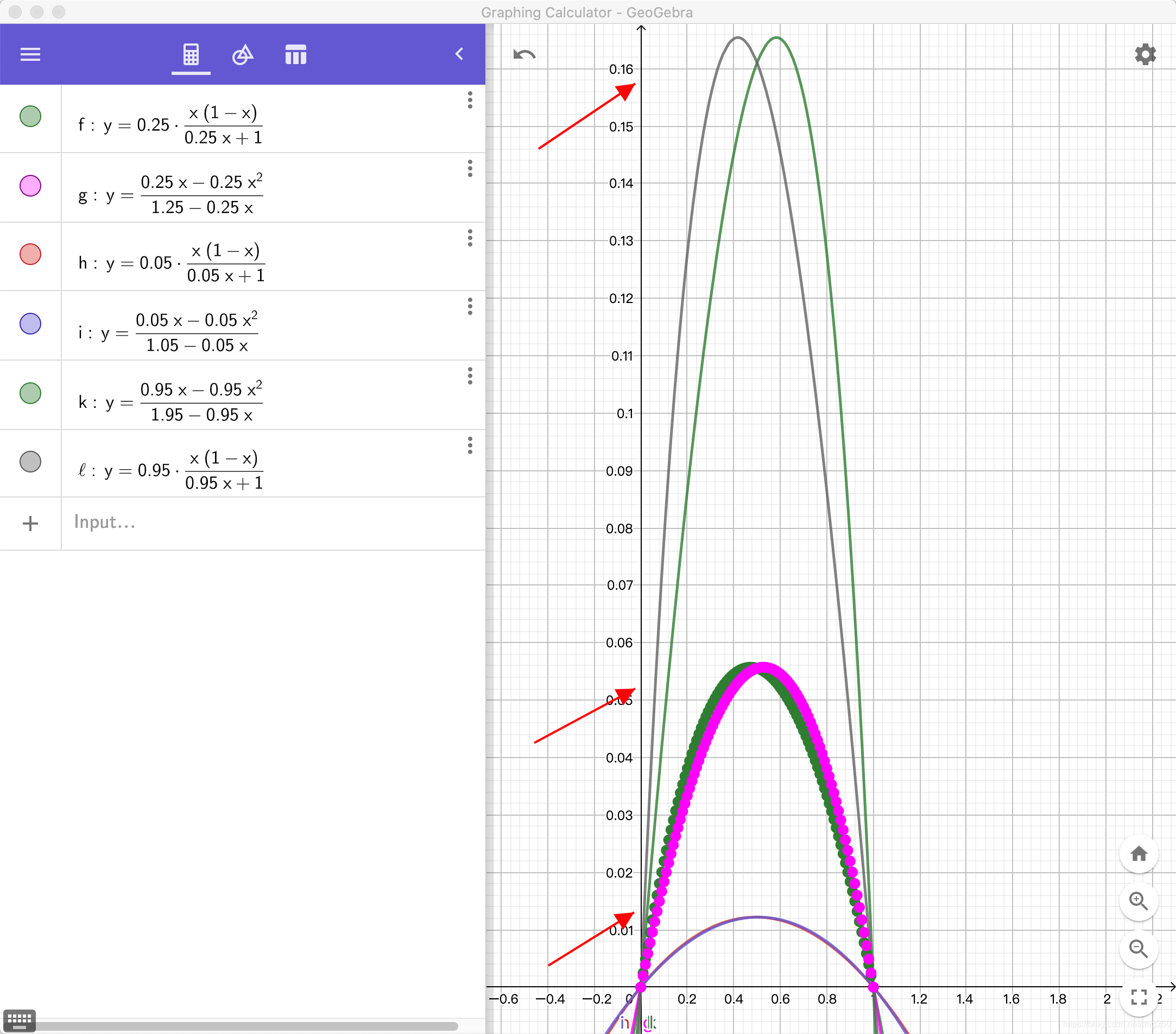
最高的那一组是gain=1.95的增量函数,中间的是gain=1.25的增量函数,最下面的那一组是gain=1.05的增量函数,这意味着它们大约对应的pacing rate up probe增量为大约65%,20%,1%,你想收敛快一点吗?代价是什么呢?是不是很容易选择了。
此外,max-filter函数也是可调整的,维持10个RTT真的好吗?如果我换成2个,会带来什么?在convergence region坐标系中画个过程吧,一切都将呈现在眼前。
现在,我觉得下面这张图可以被解释了:
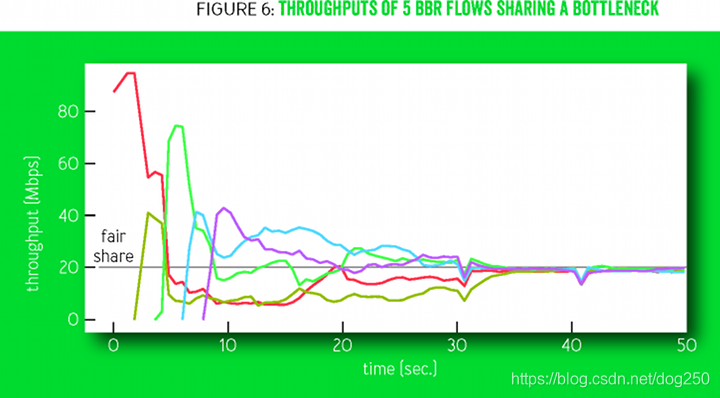
浙江温州皮鞋湿,下雨进水不会胖。
原文链接: https://blog.csdn.net/dog250/article/details/114727596
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍;
也有高质量的技术群,里面有嵌入式、搜广推等BAT大佬

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/405755
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!