
前几个月,我写了一篇BBR算法的收敛动力学的文章:
https://blog.csdn.net/dog250/article/details/114727596
用一幅图描述了BBR的收敛过程,最终neal也是比较认可的。但我总觉得BBR这个收敛机制有点不是那么通透。
上周的时候,同事推荐了一篇讲如何优化BBR的论文,又一起聊了下关于BBR收敛的问题。
由于这篇论文是基于一个数学过程描述的,比我那个要简单得多,我想根据论文里的描述,再解释一下BBR脆弱的公平性,论文的链接如下:
https://13838019299791283621.googlegroups.com/attach/7a1ad8b39994e/improve_bbr-2.pdf
我们知道,一条连接的RTT分为3个部分,传输时延,排队时延,处理时延,在TCP端到端场景下,忽略处理时延,那么某时刻
t
t
t,一条连接
i
i
i的RTT为:
R
T
T
i
=
R
T
p
r
o
p
i
+
D
i
(
t
)
{RTT}_i={RTprop}_i+D_i(t)
RTTi=RTpropi+Di(t)
其中
R
T
p
r
o
p
RTprop
RTprop为传输时延,以下写为
T
i
T_i
Ti。
于是,设时间
t
t
t,连接
i
i
i的inflight为
B
i
(
t
)
B_i(t)
Bi(t),实际带宽
λ
i
(
t
)
\lambda_i(t)
λi(t)可以写作:
λ
i
(
t
)
=
B
i
(
t
)
T
i
+
D
i
(
t
)
\lambda_i(t)=\dfrac{B_i(t)}{T_i+D_i(t)}
λi(t)=Ti+Di(t)Bi(t)
理论上,
D
(
t
)
D(t)
D(t)是比较小的,但在BBR收敛动力学的推导中却是不可忽略的,因为正是因为
D
(
t
)
D(t)
D(t),BBR最终才会在ProbeRTT阶段收敛。
由于BBR的带宽增益是1.25,可以认为当前的
B
(
t
)
B(t)
B(t)是之前带宽增益的结果,如果这次带宽增益确实获得了实效,设
C
i
(
t
)
C_i(t)
Ci(t)为连接
i
i
i在时刻
t
t
t由BBR估计出来的带宽,那么:
B
i
(
t
)
M
A
X
=
1.25
×
T
i
×
C
i
(
t
−
8
T
i
)
B_i(t)^{MAX}=1.25\times T_i\times C_i(t-8T_i)
Bi(t)MAX=1.25×Ti×Ci(t−8Ti)
前一个时间之所以是
t
−
8
T
i
t-8T_i
t−8Ti是因为BBR的ProbeBW周期就是8个RTT。
于是,可以在实际带宽
λ
i
(
t
)
\lambda_i(t)
λi(t)和实际带宽
C
i
(
t
)
C_i(t)
Ci(t)之间建立关联了,如果某次BBR通过增益预估的带宽是正确的,那么:
C
i
(
t
)
=
λ
i
(
t
)
=
1.25
T
i
T
i
+
D
(
t
)
×
C
(
t
−
8
T
i
)
C_i(t)=\lambda_i(t)=\dfrac{1.25T_i}{T_i+D(t)}\times C(t-8T_i)
Ci(t)=λi(t)=Ti+D(t)1.25Ti×C(t−8Ti)
之所以不再区分
D
i
(
t
)
D_i(t)
Di(t)是因为所有的流共享同一个queue buffer且pacing到达,因此它们的排队时延是一致的。
这下我们就找到了BBR MIMD的系数了,它就是
1.25
T
i
T
i
+
D
(
t
)
\dfrac{1.25T_i}{T_i+D(t)}
Ti+D(t)1.25Ti
通过这个系数,我们可以清晰地看出排队时延和传输时延的关系对实际带宽的影响:
- 如果
D
(
t
)
D(t)
D(t)大于0.25
T
i
0.25T_i
0.25Ti,那么带宽不增反减,说明此时已经资源过载了,这是BBR自动发现的。 - 如果
D
(
t
)
D(t)
D(t)小于0.25
T
i
0.25T_i
0.25Ti,那么带宽会增加,仍有空余资源,但一般不会是1.25倍增益,除非完全不排队。
这意味着,BBR确实把queue buffer稍微(注意这个“稍微”)看作了一种资源,但不能大量占据。我们先画出增益函数的图像:
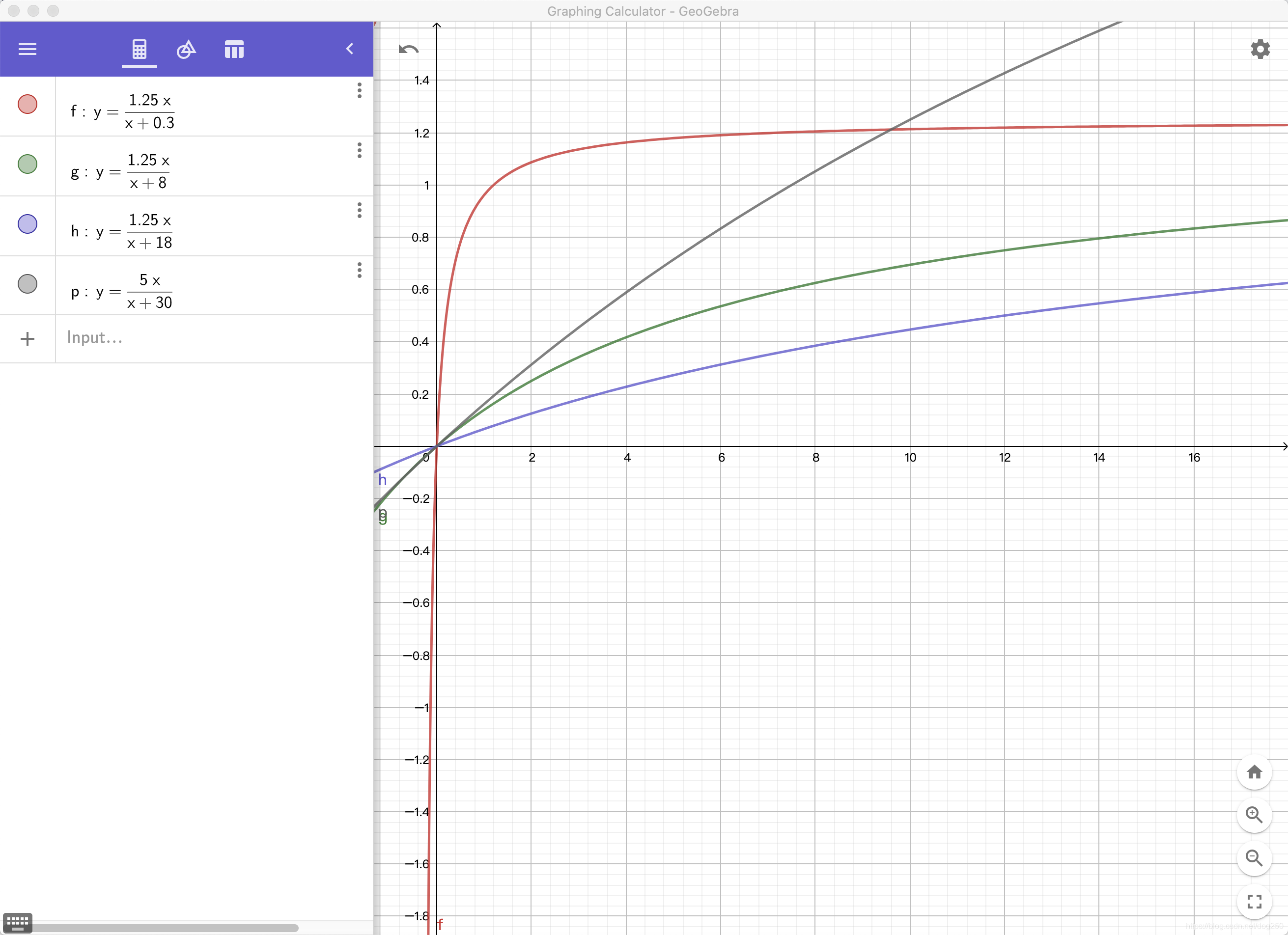

可以看出,无论如何,
T
i
T_i
Ti越大,增益越大,这是一个单调递增函数,然而当
T
i
T_i
Ti达到一定值的时候,增益就趋于等同,不再显著随着
T
i
T_i
Ti的增加而增加,这说明,在不排队或者轻微排队的情况下,对于不同的
T
i
T_i
Ti,增益是公平的。
同样的分析方法,如果排队时间显著增加,那么可以看出,增益随着
T
i
T_i
Ti的增加明显增加,这是BBR RTT不公平的根源,即便是进入ProbeRTT也挽救不了。
同时,我还画了一个增益为5,排队为30的图像,这里点个题,调一手好参数的事情,就不再分析了。
先看
T
i
T_i
Ti相同时的收敛图:
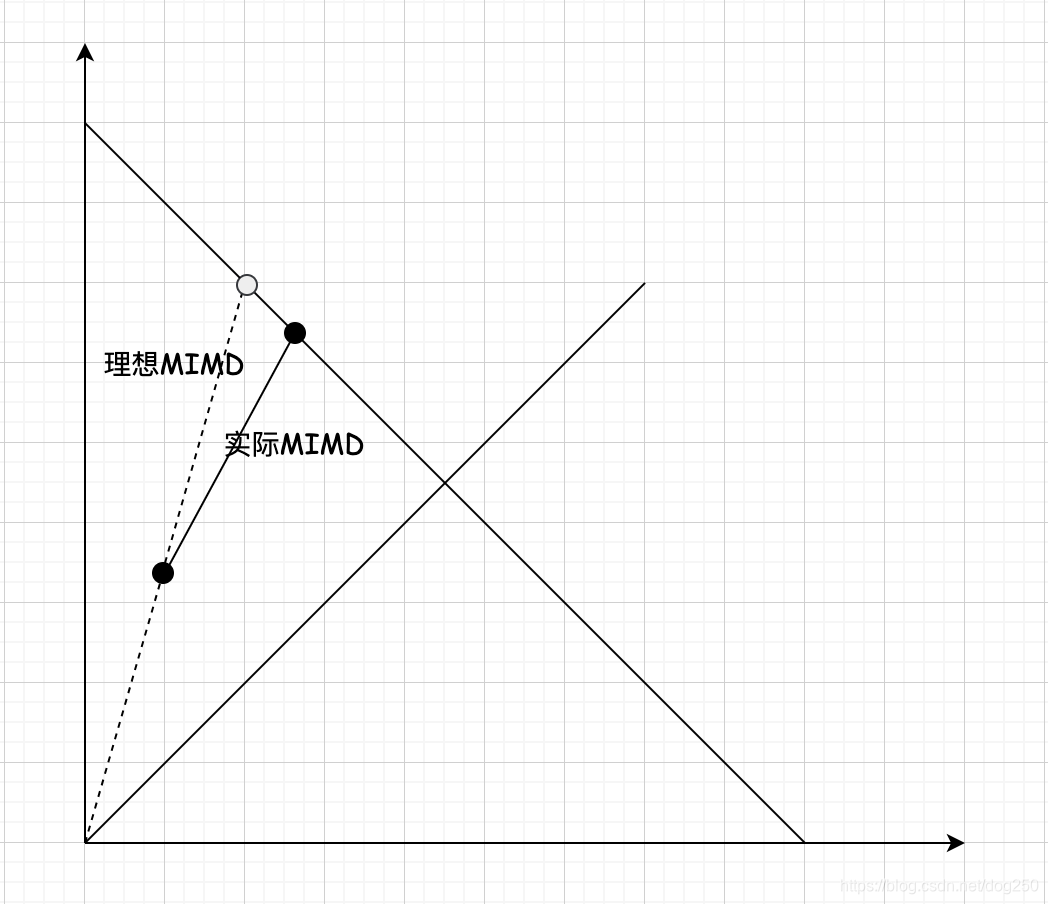
一个数学式子一气呵成我之前画的那个复杂图示。
为什么实际的MIMD会和理想情况有个夹角进而推动BBR收敛呢?我们知道,BBR在ProbeRTT后进行收敛,设
λ
1
<
λ
2
\lambda_1<\lambda_2
λ1<λ2,它们的
T
1
=
T
2
=
T
T_1=T_2=T
T1=T2=T,如果
λ
1
\lambda_1
λ1进入了ProbeRTT,那么实际上queue buffer并没有清空,
λ
2
\lambda_2
λ2依然占据着它,因此这个时候
λ
1
\lambda_1
λ1测量出的
T
1
T_1
T1是偏大的,即
T
1
′
>
T
T_1^{'}>T
T1′>T,这是这个差值造成了
λ
1
\lambda_1
λ1增益大于
λ
2
\lambda_2
λ2,进而造成了收敛。
一旦
λ
2
\lambda_2
λ2进入ProbeRTT,那么queue buffer将基本清空,无论如何,
λ
2
\lambda_2
λ2清空的都比
λ
1
\lambda_1
λ1清空的多,进而导致自己测量的
T
2
′
T_2^{'}
T2′偏大,这就是BBR收敛的实质。
然而,如果
T
1
≠
T
2
T_1\neq T_2
T1=T2,那必然悲剧了:
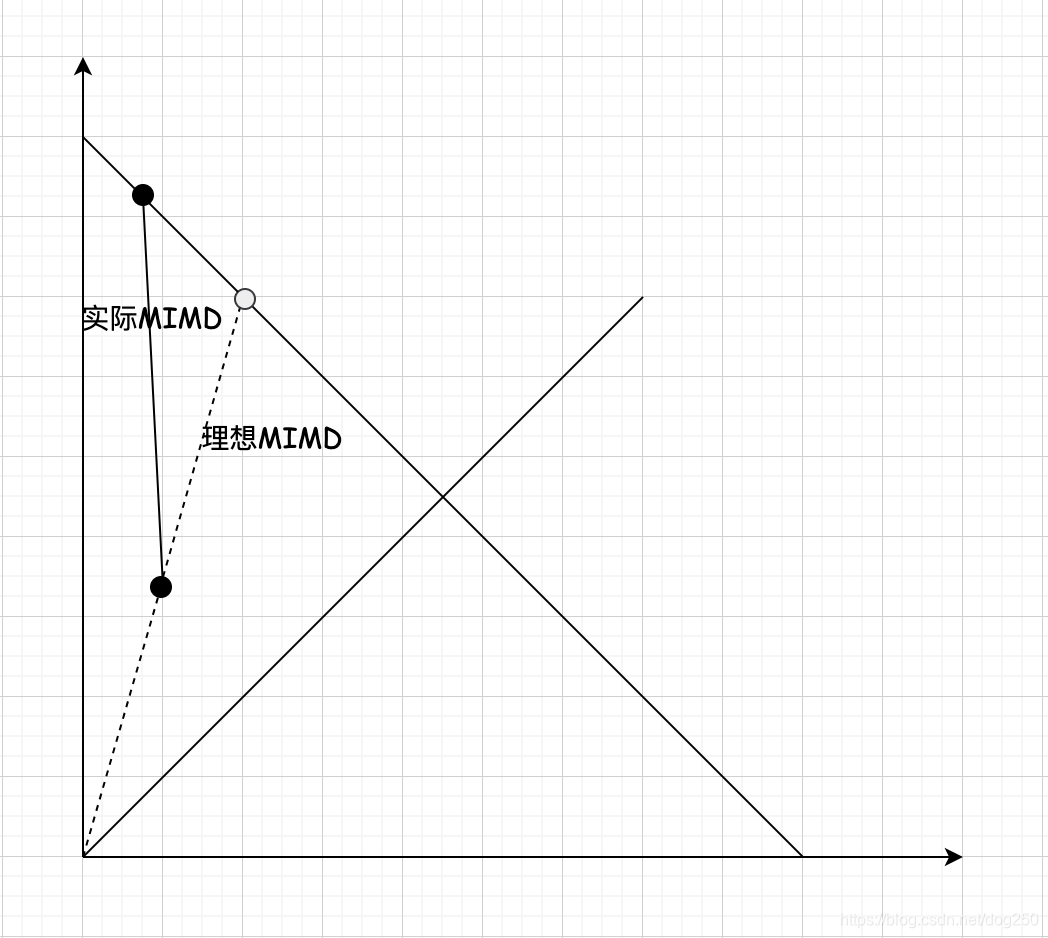
因为
λ
1
<
λ
2
\lambda_1<\lambda_2
λ1<λ2,且
T
1
<
T
2
T_1<T_2
T1<T2,
λ
2
\lambda_2
λ2的增益系数比
λ
1
\lambda_1
λ1大,双向加持,
λ
1
\lambda_1
λ1将会被挤到虚无,万劫不复。
这就是脆弱的平衡!
至于如何改进,这篇论文里说的方法和我之前那个差不多,也是引入一个
α
\alpha
α,不管怎样,引入一个参数是一个常规方案。
浙江温州皮鞋湿,下雨进水不会胖。
原文链接: https://blog.csdn.net/dog250/article/details/118627070
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍;
也有高质量的技术群,里面有嵌入式、搜广推等BAT大佬

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/405713
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!