
并发的核心是查找,之前解释过,今夜豪雨,再说两句。
并发问题实质是可扩展问题,好的并发系统开销不应随并发entity数量的增加而线性增加,时间复杂度应在O(n)以下。
并发和并行不同,并行是同时执行,但entity数量并不永远和硬件数量匹配,当entity数量大于硬件数量,总会有多个entity共享一套硬件,一套硬件处理多个entity,就是并发。
并发entity最终还是要串行,并发的本质是分时串行,并发处理的核心是“随时查找一个最适合使用时间片的entity。”
并发技术是一种调度技术,调度多个entity分时串行的技术。所谓调度,就是查找。
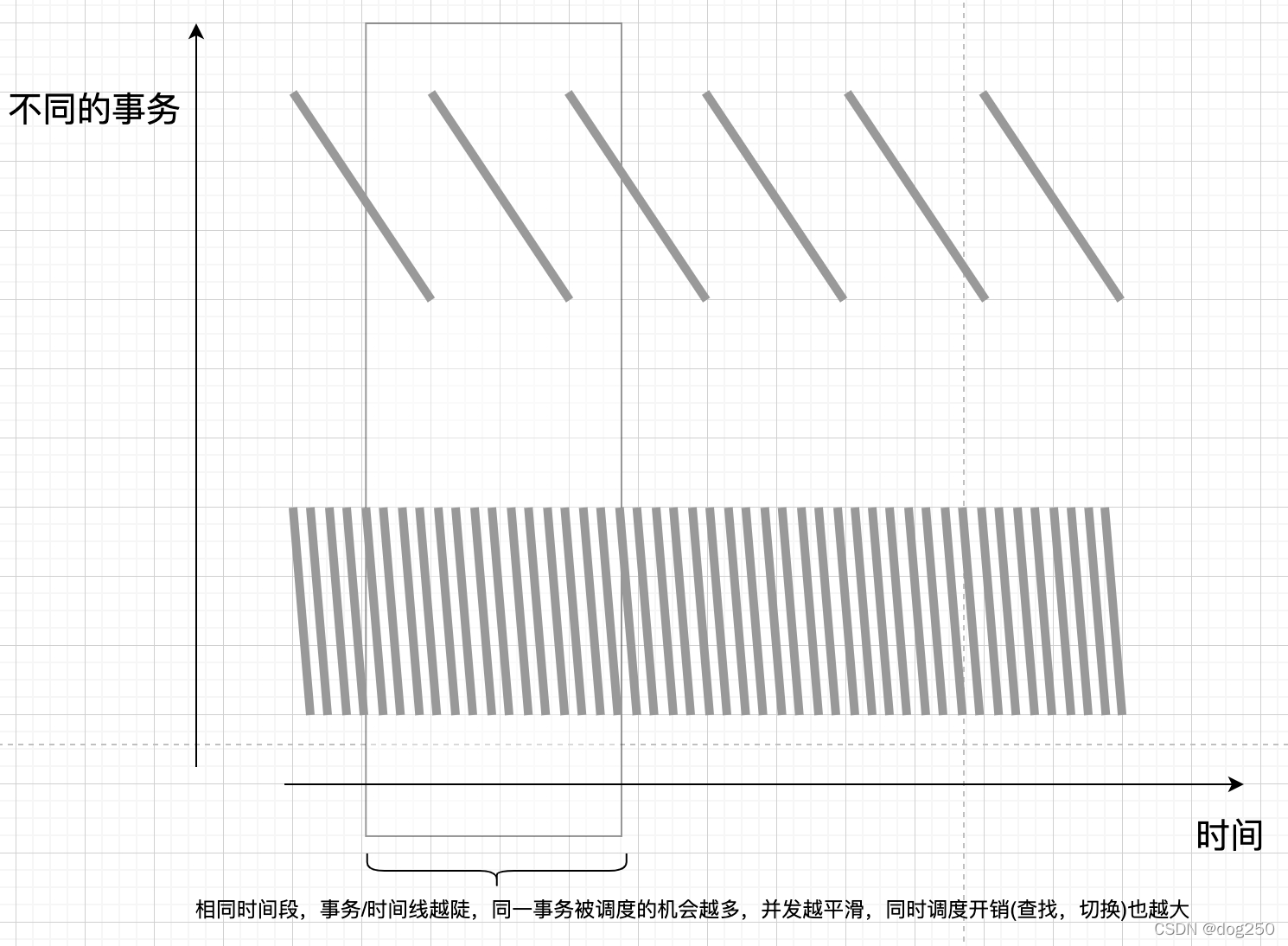

后记1
操作系统是一个进程并发系统,随时要在所有进程中查找出一个最适合执行的进程。Linux最初的O(n)调度不好的原因就是查找开销是线性增加的,而O(1)则是常数,换成log级别的CFS是因为它的响应度和公平性更好,开销又不至于到O(n)。
服务器是一个连接并发系统,随时要为一个数据包查找最适合处理它的连接。若每连接一个进程,当找到那个连接后,还要调度与之绑定的进程,调度也是一种查找,而进程数量与连接数量相当,两次查找开销叠加,若进程数量固定,则调度开销固定。
路由器交换机是数据包调度并发系统,随时要找到一个最适合的数据包发送到链路。无论数据包分类,路由,还是出队调度,本质都是查找。虽然同一时刻多个数据包可以从不同端口进入,但同一个时刻只有一个数据包可以被放到出口链路。系统要做的就是找到那一个。
队列为查找提供约束,数据包只需保序,无需再排序,因此转发才高效。数据包在线缆上时,它以光速级的波特率传播,当它进入交换机后,额外操作指令让这个波特率迅速下降。所谓的包分类,连接跟踪,防火墙规则匹配,路由,都不过是为数据包查找一个归宿,最后从多个这样的归宿中查找到一个最合适的数据包从出口放出,这些操作何止几条指令。优化的目标就是让这些操作要么快,要么去掉,指标就是pps,线速等。
后记2
硬件是固定的,可需要硬件处理的事务不固定,如何安排事务的处理顺序是并发的核心,具体就是查找和排序。
事务组织成序,系统执行调度,这就是并发要做的事,排序和查找的效率影响了并发性能。
为什么我没把排序算进去,只提查找?
排序只是为优化查找效率而做的预处理,理论上最公平最高效的一种调度方式是随机挑一个,这显然算一种查找,但无需排序。
理论上最公平最高效的另一种方式是无限内存的完美哈希索引,空间换时间,显然也无需排序。
排序和查找似乎是计算机领域“唯一”的“两件事”,从大学第一节课到经历几十次的面试,似乎都是围绕排序和查找展开。实际上,在有限的资源上执行数量不固定的事务,排序和查找是基本的。这就是计算机工作的核心原理,而计算机是一个并发系统,并发的核心就是“事务组织成序,系统执行调度”,分时使用资源要做的就是找到最适合的那一个。豪雨夜,写篇短文。
浙江温州皮鞋湿,下雨进水不会胖。
原文链接: https://blog.csdn.net/dog250/article/details/124428970
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍;
也有高质量的技术群,里面有嵌入式、搜广推等BAT大佬

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/405541
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!