
填满TCP长肥管道很难,不信你可以试试。
难点在于:
- 基于丢包的cc算法很难hold住窗口,随机丢包会降窗,长RTT导致窗口涨回来很慢。
- BBR算法稍好一点,但需要很大的接收buffer,buffer等于BDP,对内存有高要求。
BBR说恶心了,本文与BBR无关,全部实验的cc算法均为CUBIC。
本文的要点是:
- 长肥管道填不满,吞吐低,并不是rcvbuff不够大,而是rwnd计算方法错了。
直连两个25Gbps网卡,设置40ms延时,sendbuff足够,iperf打流只能到3Gbps~4Gbps,工人们接受这个结论,因为工人们都知道,这是因为recvbuff设置的不够大,将rmem[2]设置成超大,iperf即可到达23Gbps,这说明工人们的建议是对的,说到底还是sysctl_tcp_rmem[2]设置的不够大。
但这是不符合直觉的,见下图:
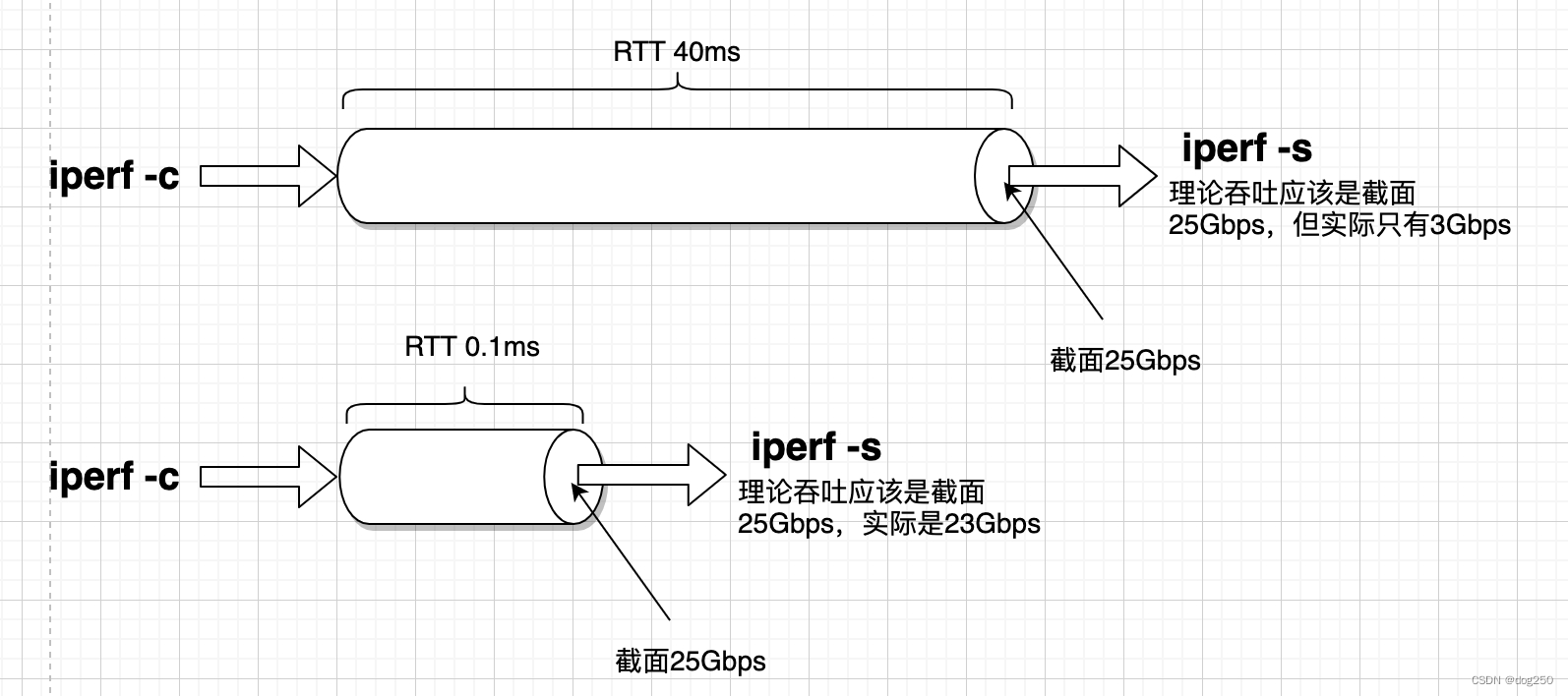

理论上iperf打流带宽和延时无关,但实际上显然是有关的。
抓包发现根因是rwnd太小,来看下rwnd小的原因。
理论上,rwnd的计算要考虑数据守恒,守恒的意思是:
- 被读走多少数据就能进入多少数据。
守恒没有问题,但至少Linux TCP计算rwnd的方式是有问题的:
copied = read_by_socket
rwnd = free space = min(sysctl_tcp_rmem[2], copied)
数据守恒加了一个限制,这不仅限制了rwnd,还限制了socket读的速率,因为rcvbuff里最多也就sysctl_tcp_rmem[2]字节数据。
按照上图所示的直觉,rwnd是和rcvbuff无关的,rwnd应该取决于数据被读走的速率,它的值应该是:
rwnd = min(BltbwRTT, rate_of_readRTT)
rwnd的值可以远大于rcvbuff。以上基于rate_of_read计算rwnd的目标就是rcvbuff为0,而不是填满它。这和传统算法是相反的。传统算法以为填满rcvbuff就是最好的资源利用率,rcvbuff有个阈值,让rwnd恰好不超过它。
实现时不必去计算min(BltbwRTT, rate_of_readRTT),probe即可。不断加性增rwnd并监测rcvbuff堆积,当堆积达到阈值不再增加rwnd,保持rcvbuff堆积稳定在阈值内,过一段时间再次probe。
如果应用程序采用busy poll的方式,以上算法可很快探测到应用程序读数据的极限,维持在那个极限将获得最大吞吐率。
这实际就是BBR的思想搬到了端到端流控。传统基于丢包的cc将填满buffer为目标,而BBR则将不填buffer为目标,显然流控也可如此倒换。
下面是我发现这个问题的过程。
发现违反上图截面直觉的现象后,我观察了很低的CPU利用率,发送端dump出rwnd,cwnd,inflight:
inflight < rwnd < cwnd
显然是rwnd limited。于是在接收端将rwnd通告为原始rwnd值的2倍rwnd’ = rwnd*2,CPU利用率即上涨1倍,吞吐也增加1倍,此时rcvbuff里的free space并没改变,说明“到的多,读的也多”。问题是:
- 为什么TCP接收端没能自己算出这rwnd’呢?
核对rcvbuff,free space之后,发现 rwnd = free space = sysctl_tcp_rmem[2] - copied 这个计算方法。而这算法限制死了程序读数据上限。
取消这个限制,我的做法是,为了达到“到的多,读的也多”,我尝试探测程序最快能读多快,为此,我不得不一点点增加rwnd去探测这个极限,显然这正是cc的思路,而拥塞点,就是程序。
我不晓得别的TCP实现如何,但大致也都和Linux TCP差不多。
看下效果,25Gbps网卡直连,40ms端到端延时,接收端rwnd算法没修改之前:
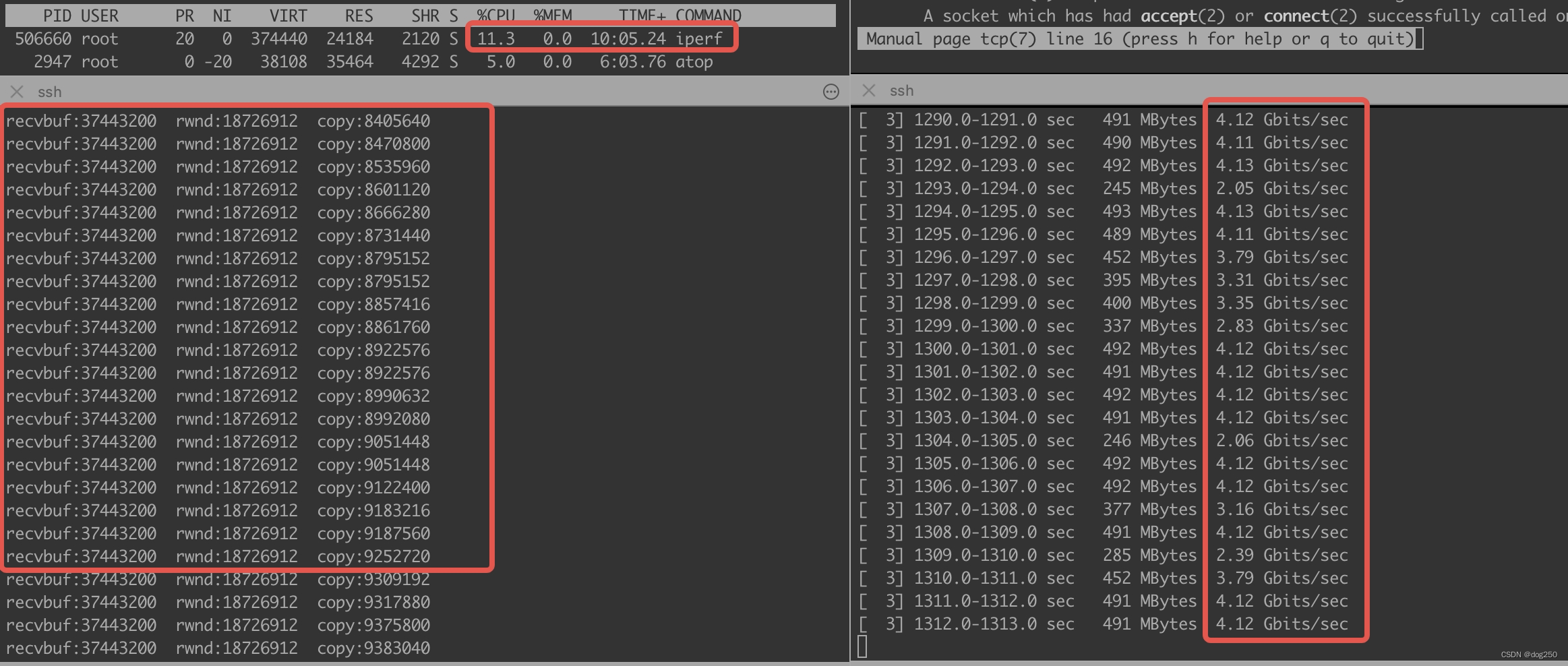
修改之后:
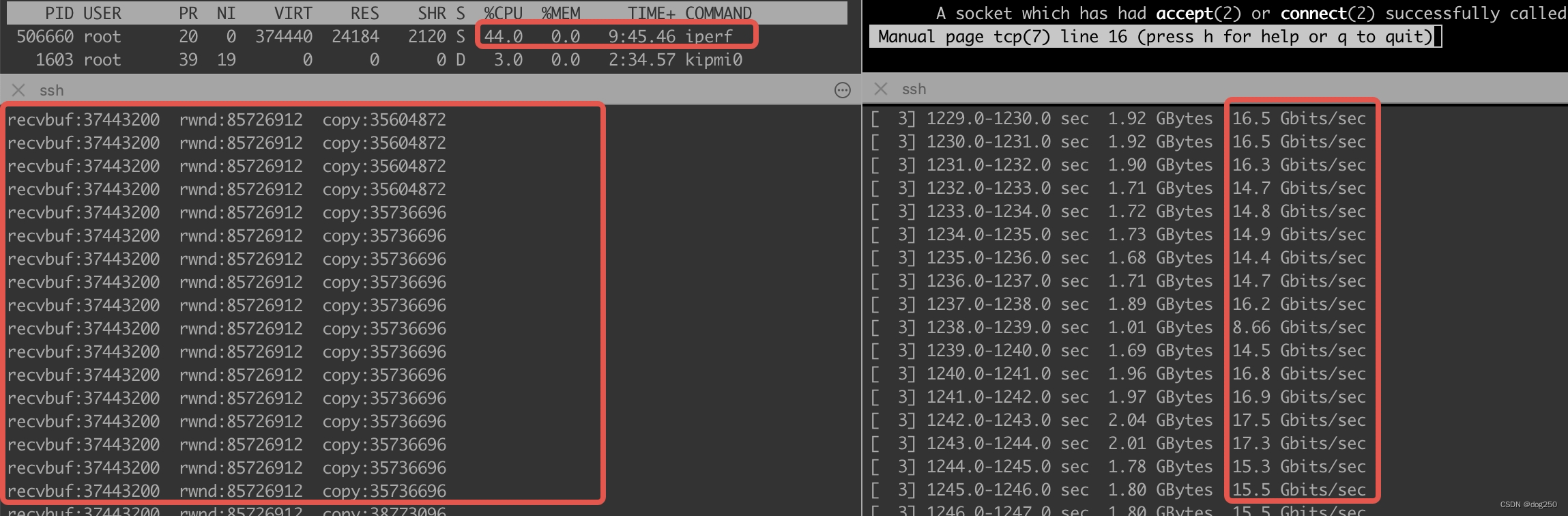
很炸的感觉,是不是?有了这个,以后再也不要调rcvbuff了。
这个思路适合端到端全链路,从一个磁盘经过某个应用程序,经由网络,再经过另一个应用程序,再到落盘,每一个环节都要遵循一个原则:
- 主动保持buffer为0,而不是填满它。
下面是一些附属:
接收端查看和修改rwnd的脚本:
stap -ge 'probe kernel.function("__tcp_select_window").return { printf("%d\n", $return)}'
stap -ge 'probe kernel.function("__tcp_select_window").return { $return=123456}'
打印rcvbuff数据:
STAP_PRINTF("recvbuf:%d rwnd:%d copy:%d\n", sk->sk_rcvbuf, tp->rcv_wnd, tp->copied_seq - tp->rcvq_space.seq);
将cwnd设置为定值以bypass cc或者让reno增窗更快些:
#!/usr/local/bin/stap -g
%{
#include <linux/tcp.h>
%}
function _set_cwnd(skk:long, type:long)
%{
struct sock *sk = (struct sock *)STAP_ARG_skk;
struct tcp_sock *tp = tcp_sk(sk);
if (STAP_ARG_type == 0) {
printk("########## retrans:%d\n", tp->snd_cwnd);
} else {
printk("normal trans:%d\n", tp->snd_cwnd);
}
// 设置为定值
tp->snd_cwnd = 292000;
%}
probe kernel.function("tcp_write_xmit")
{
_set_cwnd($sk, 1);
}
probe kernel.function("tcp_xmit_recovery")
{
_set_cwnd($sk, 0);
}
function inc_cwnd(skk:long, skbb:long)
%{
struct sock *sk = (struct sock *)STAP_ARG_skk;
struct sk_buff *skb = (struct sk_buff *)STAP_ARG_skbb;
struct tcp_sock *tp = tcp_sk(sk);
struct inet_connection_sock *icsk = inet_csk(sk);
struct tcphdr *th;
if (skb->protocol != htons(ETH_P_IP))
return;
th = (struct tcphdr *)skb->data;
if (ntohs(th->source) == 5001) {
tp->snd_cwnd_cnt += 900;
}
%}
probe kernel.function("tcp_ack").return
{
inc_cwnd($sk, $skb);
}
跟友商一哥们儿一起探讨TCP传输优化问题,正好我自己也有这方面的一个大数据量长程同步的需求,在一起怼了一波TCP之后,彻底抛开了cc,把cwnd写死了再说,看看端到端的send/rcvbuff有没有啥好调的,果然抓到一条大鱼,不敢独享,分享一篇短文。
浙江温州皮鞋湿,下雨进水不会胖
原文链接: https://blog.csdn.net/dog250/article/details/124973702
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍;
也有高质量的技术群,里面有嵌入式、搜广推等BAT大佬

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/405505
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!