
分层协议栈层内自决意味着拥塞控制逻辑在传输层闭环。保持优雅代价是降低效能,不可不察。
比如,TCP 检测到拥塞后降低 cwnd,传输速率因此而颠簸,需传输的数据总量却没有改变,应用程序端到端总有一个环节出现数据堆积,最终还是要传输固定量的数据,只是产生了延迟,这对流媒体传输尤其不利。
再如,BBR 为保证其状态机转换,不得不每隔 10s 进入 ProbeRTT 致 inflight 降为 4,这意味着 BBR 本身就是一台不匀速的引擎,动力定期抖动,就像铁轨或高架桥上存在接缝一样。
铁轨和高架桥的接缝不可规避,但拥塞控制可以。
不在传输层降低 cwnd 或降低 pacing rate,将拥塞控制事件及相关数据反馈给应用程序,应用程序自行决定降速,分流,服务降级,甚至丢弃一些数据,自然就解除了拥塞,这种做法可维持平稳的 pacing 间隔,保证 QoE。应用程序需要做的是准备多套数据,在不同程度拥塞时实时切换。
带宽固定,流越多,每流可用带宽越少,体现在每流影响上,如果每流依然坚持传输数据量不变,势必造成延时增加,拥塞维持,如果传输数据量下降,则可压缩时间,解除拥塞。对流媒体,完全可接受码率换流畅,对文件,可用多路径分流保证无损。
若拥塞由高并发引发,优待哪条流或惩罚哪条流都不合适,拥塞公平性也一直是难题,如果每条流承载的应用程序自行降低服务等级,传输数据总量均匀下降,拥塞缓解。
对于拥塞降速场景,高尚的做法是无级变速,但 AIMD 显然不是,BBR-ProbeRTT 也不是。显然只有应用程序拥有完成无级变速所需的信息。拥塞控制由传输层自决转换成了应用程序自决。
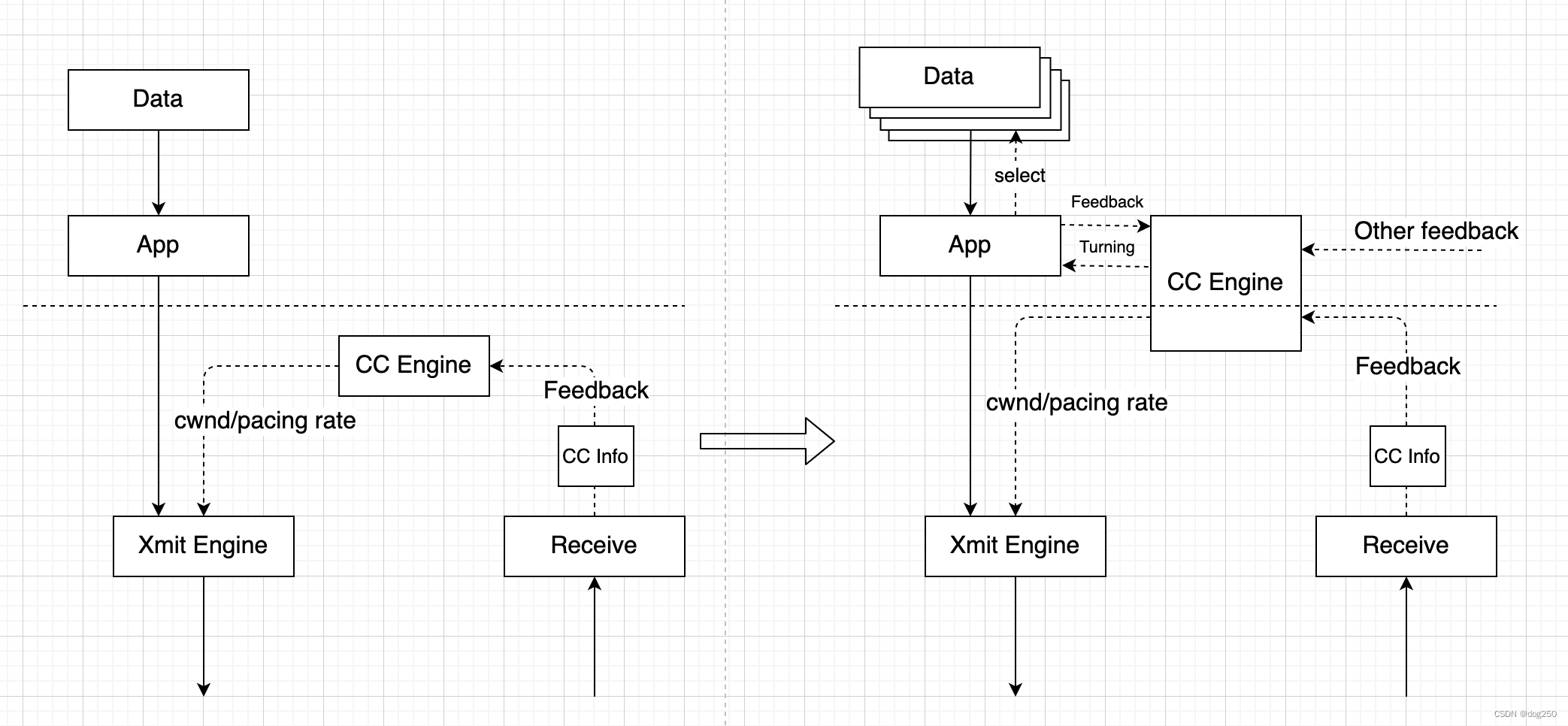

OK,大致就这个意思。下面说点悲伤的。
应用程序不仅能做拥塞控制,还可引发拥塞崩溃。想想 TCP 拥塞崩溃是如何发生并如何被解决的。
当 Buffer 瞬时堆积,Host 尚未采集到已经暴涨的 RTT 前屡次超时,越来越多的报文副本灌入网络,引发拥塞崩溃。解决方案是报文守恒,禁止多余的报文副本进入网络。AIMD + 退避 RTO 可解拥塞崩溃问题。
若多条 TCP 共享带宽,按现代 TCP 拥塞控制机制,拥塞崩溃是可避免的。最坏的情况是随着流增多,每流分配的带宽越来越小,但不会引发高重传,拥塞控制算法可以自适应该情景。
但传输层着手控制拥塞时,应用程序超时断开呢?很明显前面的数据并未丢失,只是延迟,由于应用程序配置了更小的超时时间,所以连接断开并提前重试,应用层复现了 1986 年的拥塞崩溃。关联本文前半部分,问题在于传输层和应用程序没有互通有无。
应用程序只知超时时间以及数据总量,却不知拥塞,应用程序有权在任何时间断开连接并重新发送数据,这行为可能抵消底层拥塞控制算法的努力。
总结:
- 从应用程序接收 cwnd 和 pacing,并可反馈给应用程序 pacing,而不是在传输层瞎算。
- 应用程序可以提供 cwnd,pacing,还能有自己的 action,比如减少数据量,re-path 分流。
- 传输层自决的拥塞控制机制中,应用程序可能导致剧烈拥塞,应用程序驱动的拥塞控制可解决。
各种传输层拥塞控制算法都表现得不尽人意,在我看来不是算法不好,而是要么做的太多,要么做的太少,本质上都是信息不够。无论是锯齿状的 Reno/CUBIC,还是心电图模样的 BBR,对于流媒体传输这种只需要一条直线的场景,都表现的不好,何不让应用程序自己做拥塞控制呢?有人要保持优雅,有人要保证高效,你选哪一个?有人说应用程序自决无法保证公平,有人担心恶意应用故意误用机制而挤占带宽…总之就是权力扩大后如何控制权限的问题,但事实上,难道不是保证应用的 QoE 才是终极目标,而不是全局公平性吗?平日的一些想法,周末写下。
浙江温州皮鞋湿,下雨进水不会胖。
原文链接: https://blog.csdn.net/dog250/article/details/127325344
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍;
也有高质量的技术群,里面有嵌入式、搜广推等BAT大佬

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/405379
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!