
3 个 dupacks 触发 fast retransmit 是一个经典启发算法,但在引入 SACK 之后仍然计数 SACKed 数量 >= 3 触发 fast retransmit 似乎就没理由了。即使把 reordering 算进去,一个距离 una 很远的 seg 被 SACKed,也足以判定丢包了,为什么非要数到 3 呢?(我数到 3,再不说我就开枪了!)
于是 FACK(Forward Acknowledgment) 被引入:Forward Acknowledgment: Rening TCP Congestion Control
FACK 大意是,被 SACKed 的 seq 最高的 seg 前面的 seg 都丢失了。这是因为 seq 越高的 seg 越晚发送,晚发送的都被 SACKed 了,早发送的有理由被判定为丢失:
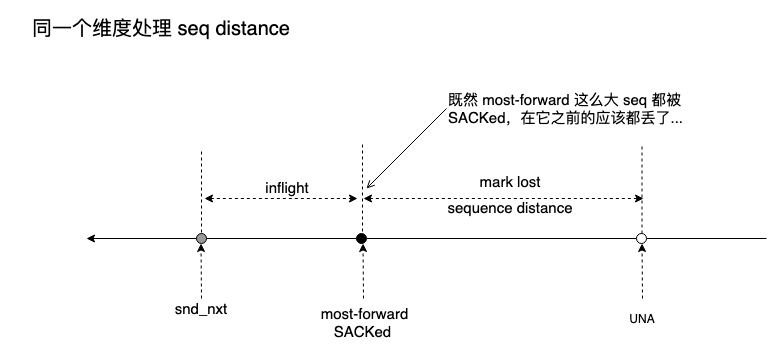

FACK 是一个 TCP recovery 状态下的一种试图精确计算 inflight 的策略,说 “试图” 是因为它只是努力精确但实际并不精确。
如果存在乱序,FACK 与 GBN 无异,所以一旦检测到乱序,FACK 即刻被禁用。同时,FACK 的假设 “seq 越高的 seg 越晚发送” 只能起一次作用,FACK 只能确保原始那次按照 seq 发送,因此,una 到 snd_nxt 之间被 mark lost 的 seg 只有一次 fast retransmit 机会,若不成功,只能超时,不过这不单单是 FACK 的问题,这是所有 SACK-based 启发策略共同的问题。
RACK 似乎本就是来替换 FACK 的,但 RACK 基于时间序列。
虽然 FACK 只能确保原始的那次按照 seq 顺序发送,但 RACK 却可以每次发送都登记新的 tx_time:

mark lost 的 seg 理论上可拥有无数次 retransmit 机会,即使滑动窗口憋死,只要 ACK 时钟不断,连接将永不超时。
RACK 这件事意义重大,这意味着不必为 recovery 状态实施不同的 cc,而可用同一 cc 控制 TCP 连接的所有拥塞状态。cc 走上了正途。
本来 TCP 的 mark lost,retransmit,滑动窗口,保序等协议相关机制就不应对 cc 可见,cc 只负责控制发送配额以及 pacing rate,一个正常的 seg 和一个重传的 seg 在 cc 看来应该没有区别。在 RACK 之前,没有足够的 inflight 支撑 cc 的依赖(比如测量,self-clock trigger 等),现在可以了。BBR 就是大力使用 RACK 的一个算法。
FACK 其实就是想做 RACK 的事,它的目标就是在 recovery 状态提供一种相对精确的测量手段以支撑 cc,只是做得不够好,但让人不解的是,为什么在 30 年的时间里 TCP 既然引入了 FACK 这种相似机制却没有引入 RACK,这并不是很难的事,相反它是显而易见的,RFC3517 才让人觉得奇怪。我所在的团队在 RACK 被引入之前就支撑了几乎完全意义的时间序 mark lost 算法,背后的动机正是 RFC3517 太反常了。
算是功成身退后,禁用 FACK 的 patch 如下:tcp: disable fack by default
FACK 一向被认为太激进,所以针对它何时起作用的判定就要非常谨慎,这也是没办法,还是信息量太少,总要损失些东西。标准 SACK 数到 3(reordering) 的方式容易引起突发或空窗这两种极端,而 FACK 虽激进却保证有足量的 seg 可重传,交给 cc 通过 deflate cwnd 去 pacing 吧,谁的就归谁。
浙江温州皮鞋湿,下雨进水不会胖。
原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/405227
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!