
最近在处理一个字符串转码问题,故记录一下过程
该需求是外部 sdk 的一个 api 需要一个 char* 字符串路径入参,我以往是将宽字符串转为 UTF8 后再传给 sdk
这次这个 api 似乎不接受 UTF8 编码的字符串路径,于是我改用系统编码传参作测试,也就是将 GB2312 编码的字符串路径传给它
结果显示该 api 只接受本地编码的字符串路径,因此我要处理宽字符串转为系统编码的问题
我在 stackoverflow 论坛上搜到一些答案
其中有一个方法要注意避坑,
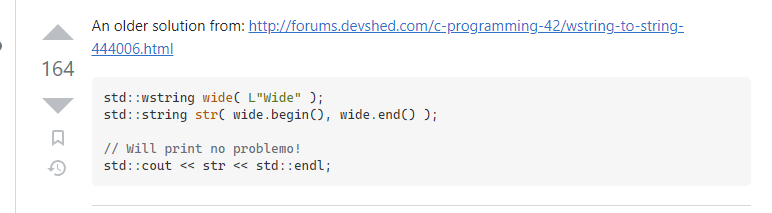

这是个高赞答案,链接:https://stackoverflow.com/a/12097772/11128312
但是这个只适用于英文字符,因为这种转换相当于把宽字节的第二个字节抹除了,比如,
“帮助” 的 unicode 编码为:2e 5e a9 52
使用上图的方法就给你干掉宽字节的第二个字节,
变成:2e a9
这是一个四不像字符
英文字符就不一样了,比如
“he” 的 unicode 编码为:68 00 65 00
用 std::string 就可以去掉 00,
变成:68 65
故我们要用其他方法来转换,方法很多,我这里列举两个,
C++17 后支持 std::filesystem::path 直接转,示例,
#include <filesystem> const std::wstring wPath = GetPath(); // some function that returns wstring const std::string path = std::filesystem::path(wPath).string();
也可以使用 WcToMb 工具函数
WcToMb 原型:
char* WcToMb(const wchar_t *str) { char *mbstr = NULL; lo_W2C(&mbstr, str); return mbstr; }
lo_W2C 内部也是用的 WideCharToMultiByte 函数转换的
lo_W2C 函数原型
/* ** Convert microsoft unicode to multibyte character string, based on the ** user's Ansi codepage. ** ** Space to hold the returned string is obtained from ** malloc(). */ int lo_W2C(char** pout ,const wchar_t *zWide) { #if (defined(WIN32) || defined(_WIN32) ) char *zname = 0; int codepage = 0; int nByte = 0; if( !zWide || *zWide == '�' ) return 0; #if defined(_WIN32_WCE) codepage = CP_ACP ; #else codepage = AreFileApisANSI() ? CP_ACP : CP_OEMCP; #endif nByte = WideCharToMultiByte(codepage, 0, zWide, -1, 0, 0, 0, 0); zname = (char*)malloc( nByte + 1 ); if( zname == 0 ) return 0; nByte = WideCharToMultiByte(codepage, 0, zWide, -1, zname, nByte+1, 0, 0); if( nByte > 0 ) zname[nByte] = '�'; *pout = zname; return nByte; #else const wchar_t* in = zWide; size_t in_len = wcslen(in); size_t outlen = bbiconv_counts_wchar_2_gbk(in , in_len); if( outlen <= 0 ) return -1; char* out_ptr = (char*)malloc( (sizeof(char)) * (outlen+1) ); if( !out_ptr ) return -1; bbiconv_wchar_2_gbk(in , in_len , out_ptr , outlen); *pout = out_ptr; return outlen; #endif //#if (defined(WIN32) || defined(_WIN32) ) }
补充:
std::wstring 和 wchar_t 内部中文编码是按照 unicode 编码的
std::string 和 char 内部中文编码是按照系统字符集编码,一般中文是 GB2312 字符集
另附:
原文链接: https://www.cnblogs.com/strive-sun/p/17106836.html
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍;
也有高质量的技术群,里面有嵌入式、搜广推等BAT大佬

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/404361
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!