
[部分转自 https://www.sdnlab.com/21087.html】
转自 https://www.cnblogs.com/vlhn/p/7727141.html
https://blog.csdn.net/weixin_37097605/article/details/101488760
SPDK 应用编程框架
SPDK (Storage performance development kit, http://spdk.io) 是由Intel发起、用于加速使用NVMe SSD作为后端存储的应用软件加速库。该软件库的核心是用户态、异步、轮询方式的NVMe驱动。较之内核(诸如Linux Kernel) 的NVMe驱动,它可以大幅度降低NVMe command的延迟 (Latency) ,同时提高单CPU核的IOPS,从而形成一套高性价比的解决方案,例如使用SPDK的vhost解决方案可以应用于HCI (Hyper Converged Infrastructure) 加速虚拟机中的NVMe I/O。
为了实现上述目标,仅仅提供用户态NVMe驱动的一些操作函数或源语是不够的。如果在某些应用场景中使用不当,不仅不能发挥出用户态NVMe驱动的高性能,甚至会导致程序错误。虽然NVMe的底层函数有一些说明,但为了更好地发挥出底层NVMe的性能,SPDK提供了一套编程框架 (SPDK Application Framework),用于指导软件开发人员基于SPDK的用户态NVMe驱动以及用户态块设备层 (User space Bdev) 构造高效的存储应用。用户有两种选择:
- (1) 直接使用SPDK应用编程框架实现应用的逻辑;
- (2) 使用SPDK编程框架的思想,改造应用的编程逻辑,以更好的适配SPDK的用户态NVMe驱动。
总体而言,SPDK的应用框架可以分为以下几部分:
- (1) 对CPU core和线程的管理;
- (2) 线程间的高效通信;
- (3) I/O的的处理模型以及数据路径(data path)的无锁化机制。
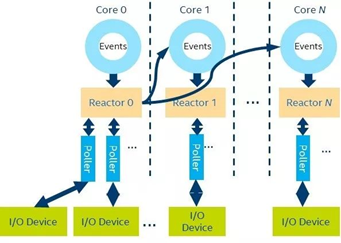

CPU core和线程的管理
SPDK一大宗旨是使用最少的CPU核和线程来完成最多的任务。为此,SPDK在初始化程序时(目前调用spdk_app_start函数)限定使用绑定CPU的哪些核,可以在配置文件或命名行中配置,例如在命令行中使用-c 0x5是指使用core0 和core2来启动程序。通过CPU核绑定函数的亲和性可以限制住CPU的使用,并且在每个核上运行一个thread,该thread在SPDK中被称为Reactor (如Figure 1所示)。目前SPDK的环境库 (ENV) 缺省仍旧使用了DPDK的EAL库来进行管理。总而言之,Reactor thread执行一个函数 (_spdk_reactor_run), 该函数的主体包含一个while (1) {} 功能的函数,直到Reactor的state被改变,例如受到 (spdk_app_stop 的调用)。为了高效,上述循环中也会有一些相应的机制让出CPU资源 (诸如sleep)。这样的机制大多时候会导致CPU使用100%的情况,这点和DPDK比较类似。
换言之,假设一个使用SPDK编程框架的应用运用了两个CPU core,那么每个core上就会启动一个Reactor thread。如此一来,用户怎么执行自己的函数呢?为了解决该问题,SPDK提供了一个Poller的机制,即用户定义函数的分装。SPDK提供的Poller分为两种:
- (1) 基于定时器的Poller;
- (2) 非定时器的Poller。
SPDK的Reactor thread对应的数据结构(struct spdk_reactor) 有相应的列表来维护Poller的机制。例如,一个链表维护定时器的Poller,一个链表维护非定时器的Poller,并且提供Poller的注册和销毁函数。在Reactor的while循环中,它会不停的check这些Poller的状态,进行相应的调用,用户的函数也因此可以进行相应的调用。由于单个CPU上只有一个Reactor thread,所以同一个Reactor thread 中不需要一些锁的机制来保护资源。当然,位于不同CPU的core上的thread还是需要通信必要。为了解决该问题,SPDK封装了线程间异步传递消息 (Async Messaging Passing) 的方式。
线程间的高效通信
SPDK放弃使用传统的加锁方式来进行线程间的通信,因为这种方案比较低效。为了使同一个thread只执行自己所管理的资源,SPDK提供了Event (事件调用) 机制。该机制的本质是每个Reactor对应的数据结构 (struct spdk_reactor) 维护了一个Event事件的ring (环)。这个环是多生产者和单消费者 (MPSC: Multiple producer Single Consumer) 的模型,即每个Reactor thread可以接收来自任何其他Reactor thread (包括当前的Reactor Thread) 的事件消息进行处理。目前SPDK中Event ring的缺省实现依赖于DPDK的机制,应该有线性锁的机制,但是相较于线程间采用锁的机制进行同步要高效得多。
毫无疑问,Event ring处理的同时也在进行Reactor的函数 (_spdk_reactor_run) 处理。每个Event事件的数据结构 (struct spdk_event) 其实包括了需要执行的函数、加上相应的参数以及要执行的core。简单而言,一个Reactor A 向另外一个Reactor B通信,其实就是需要Reactor B执行函数F(X) (X是相应的参数)。
基于上述机制,SPDK就实现了一套比较高效的线程间通信机制。具体例子可以参照SPDK NVMe-oF target内部的一些实现,主要代码位于 (lib/nvmf) 目录。
I/O处理模型以及数据路径的无锁化
SPDK主要的I/O 处理模型是Run-to-completion,指运行直到全部完成。上述内容中提及,使用SPDK应用框架时,一个CPU core只拥有一个thread,该thread可以执行很多Poller (包括定时和非定时器)。Run-to-completion的宗旨是让一个线程最好执行完所有的任务。显而易见,SPDK的编程框架满足了该需要。如果不使用SPDK应用编程框架,则需要编程者自己注意这个事项。例如,使用SPDK用户态NVMe驱动访问相应的I/O QPair进行读写操作,SPDK 提供了异步读写的函数 (spdk_nvme_ns_cmd_read),同时检查是否完成的函数 (spdk_nvme_qpair_process_completions)。这些函数的调用应由一个线程完成,不应该跨线程处理。
SPDK 的I/O 路径也采用无锁化机制。当多个thread操作同意SPDK 用户态block device (bdev) 时,SPDK会提供一个I/O channel的概念 (即thread和device的一个mapping关系)。不同的thread 操作同一个device应该拥有不同的I/O channel,每个I/O channel在I/O路径上使用自己独立的资源就可以避免资源竞争,从而去除锁的机制。
【翻译自 https://spdk.io/doc/concurrency.html
SPDK的消息传递和并发性
SPDK的初始目标是随着硬件的增加,性能也能得到线性增长。比如说由一个SSD增加到2个SSD时,每秒执行的IO应该是原来两倍;或者CPU数量增倍时,计算能力也增倍;或者NIC数量增倍时,网络的throughput也增倍。为了实现这个,软件上设计必须让线程的执行尽量的相互独立,这意味着避免加锁甚至原子操作。
传统的软件实现并发性是通过将共享的数据放到heap上,然后通过锁来保护,当线程需要访问该共享数据时,要先去获取锁。这种方法的特点是:
- It's relatively easy to convert single-threaded programs to multi-threaded programs because you don't have to change the data model from the single-threaded version. You just add a lock around the data.
- You can write your program as a synchronous, imperative list of statements that you read from top to bottom.
- Your threads can be interrupted and put to sleep by the operating system scheduler behind the scenes, allowing for efficient time-sharing of CPU resources.
但是当线程增多时,相互之间对锁的竞争会导致线程花很多时间去获取锁,使得程序没法受益于增加的CPU核。
SPDK采用不同的方法。SPDK经常只把数据assign给一个线程。当其他线程要获取这个数据时,传递一个消息给数据的owner线程让其代替完成操作。
spdk_msg_fn fn;
void *arg;
};
SPDK中的消息通常包含 一个函数指针,一个context指针,通过lockless ring.在线程间传递。由于caching effects,消息的传递往往比想象的快,因为如果一个core一直在访问同样 的数据(代替其他core操作),那么数据更可能放在离这个core更近的cache。 It's often most efficient to have each core work on a relatively small set of data sitting in its local cache and then hand off a small message to the next core when done.
在更极端的情况,若message传递的花费太高,每个线程都保留有一份数据的副本,线程只访问自己拥有的副本数据,若要修改,那么发消息通知其他线程更新数据。这种方法适用于数据的修改不频繁但是经常读的情况。and is often employed in the I/O path. This of course trades memory size for computational efficiency, so it's use is limited to only the most critical code paths.
消息传递infrastructure
SPDK提供了几层消息传递infrastructure。
最基础的库 没有采用消息传递,只是列举了函数何时被调用的规则。(例如NVMe Driver)。
大部分的库 用SPDK的 thread abstraction,在libspdk_thread.a中。其提供了基本的消息传递框架并定义了一些关键primitives。
|
struct spdk_thread {
// Tail queue declarations. 队列头
TAILQ_HEAD(, spdk_io_channel) io_channels; //描述前一个和下一个元素的结构体
TAILQ_ENTRY(spdk_thread) tailq; char *name; struct spdk_cpuset *cpumask;
uint64_t tsc_last;
struct spdk_thread_stats stats; /*
* Contains pollers actively running on this thread. Pollers * are run round-robin. The thread takes one poller from the head * of the ring, executes it, then puts it back at the tail of * the ring. */ TAILQ_HEAD(active_pollers_head, spdk_poller) active_pollers; /**
* Contains pollers running on this thread with a periodic timer. */ TAILQ_HEAD(timer_pollers_head, spdk_poller) timer_pollers; struct spdk_ring *messages;
/*
singly-linked list:This structure contains a single pointer to the first element on the list. SLIST_HEAD(HEADNAME, TYPE) head; */
SLIST_HEAD(, spdk_msg) msg_cache; size_t msg_cache_count; /* User context allocated at the end */
uint8_t ctx[0]; } |
在指定的线程上周期性地被调用:
struct spdk_poller {
TAILQ_ENTRY(spdk_poller) tailq; /* Current state of the poller; should only be accessed from the poller's thread. */
enum spdk_poller_state state; uint64_t period_ticks;
uint64_t next_run_tick; spdk_poller_fn fn; void *arg; }; |
struct io_device {
void *io_device; char *name; spdk_io_channel_create_cb create_cb; spdk_io_channel_destroy_cb destroy_cb; spdk_io_device_unregister_cb unregister_cb; struct spdk_thread *unregister_thread; uint32_t ctx_size; uint32_t for_each_count; TAILQ_ENTRY(io_device) tailq; uint32_t refcnt;
bool unregistered;
}; |
/**
* brief Represents a per-thread channel for accessing an I/O device. * * An I/O device may be a physical entity (i.e. NVMe controller) or a software * entity (i.e. a blobstore). * * This structure is not part of the API - all accesses should be done through * spdk_io_channel function calls. */ struct spdk_io_channel { struct spdk_thread *thread; struct io_device *dev; uint32_t ref; uint32_t destroy_ref; TAILQ_ENTRY(spdk_io_channel) tailq; spdk_io_channel_destroy_cb destroy_cb; /*
* Modules will allocate extra memory off the end of this structure * to store references to hardware-specific references (i.e. NVMe queue * pairs, or references to child device spdk_io_channels (i.e. * virtual bdevs). */ }; |
使用时先调用 spdk_allocate_thread()??(没这个函数)This function takes three function pointers - one that will be called to pass a message to this thread, one that will be called to request that a poller be started on this thread, and finally one to request that a poller be stopped. The implementation of these functions is not provided by this library. Many applications already have facilities for passing messages, so to ease integration with existing code bases we've left the implementation up to the user.
In today's code spdk_io_device is any pointer, whose uniqueness is predicated only on its memory address, and spdk_io_channel is the per-thread context associated with a particular spdk_io_device.
event framework event.h
event框架是可选的?大部分其他SPDK模块可以不依赖于SPDK event库???
To accomplish cross-thread communication while minimizing synchronization overhead, the framework provides message passing in the form of events.
组成部分:reactors, events, and pollers
event
The event framework spawns one thread per core (reactor) and connects the threads with lockless queues. Messages (events) can then be passed between the threads.
每个CPU上跑一个 event loop thread(这些thread称为reactor)。这些线程处理 incoming events from a queue。每个event包括一个捆绑的函数指针和其参数,给一个指定cpu core。
spdk_event_allocate() 创建event;
spdk_event_call() 传event给指定的core,并执行event。
reactor
每个reactor有一个 lock-free的队列来放传给该core的event。每个core的线程可以插event到任何其他core的队列中。每个core上的reactor loop检查incoming events并以first-in first-out的顺序执行。Event functions should never block and should preferably execute very quickly, since they are called directly from the event loop on the destination core.
|
struct spdk_reactor {
/* Logical core number for this reactor. */ uint32_t lcore; /* Lightweight threads running on this reactor */
TAILQ_HEAD(, spdk_lw_thread) threads; /* Poller for get the rusage for the reactor. */
struct spdk_poller *rusage_poller; /* The last known rusage values */
struct rusage rusage; struct spdk_ring *events;
} __attribute__((aligned(64))); |
poller
poller和event一样是带参的函数,可以被捆绑、执行。但是不像event,poller是一直在所注册的线程上重复地执行,直到被注销。The reactor event loop intersperses calls to the pollers with other event processing. Pollers are intended to poll hardware as a replacement for interrupts. Normally, pollers are executed on every iteration of the main event loop.
】
常见问题
01 SPDK每年发布几个版本? 发布版本号是怎么样的?
A: 4个版本。发布版本采用年份加月份的方式:YY.MM (其中MM 属于集合{1,4,7,11})。每年一共发布4个版本,分别在1月、4月、7月和11月发布。SPDK即将发布的版本是18.04。
02 SPDK开源项目和DPDK项目是什么关系?
A:SPDK 最早项目代号WaikikiBeach,全称DPDK For Storage,2015年开源以后改为SPDK。SPDK 提供了一套环境抽象化库 (位于lib/env目录),主要用于管理SPDK存储应用所使用的CPU资源、内存和PCIe等设备资源,其中DPDK是SPDK缺省的环境库。每次当SPDK发布新版本的使用时会使用最新发布的DPDK的稳定版本。例如,SPDK 18.04会使用DPDK18.02版本。
03 SPDK的一些典型使用场景是什么?
A:目前而言,SPDK并不是一个存储应用的通用适配解决方案。因为把内核驱动放到用户态,所以导致需要在用户态实施一套基于用户态软件驱动的完整I/O栈。文件系统毫无疑问是其中的一个重要话题,而内核的文件系统 (例如linux EXT4和btrfs等) 已经无法直接使用。虽然目前SPDK 提供了非常简单的“文件系统”blobfs/blostore, 但并不支持POSIX接口。为此,如果要将使用文件系统的应用直接迁移到SPDK的用户态“文件系统”上,还需要做一些代码移植工作。例如,不使用POSIX接口,转而采用类似于AIO的异步读写方式。SPDK社区一直朝着该方向努力,现如今SPDK在以下应用场景中的使用比较好:(1) 提供块设备接口的后端存储应用,诸如iSCSI Target和 NVMe-oF Target;(2) 对虚拟机中I/O (virtio) 的加速,主要支持Linux系统下的QEMU/KVM作为hypervisor 管理虚拟机的场景,使用vhost交互协议实现基于共享内存通道的高效vhost用户态target (例如vhost SCSI/blk/NVMe target),从而加速虚拟机中virto SCSI/blk和kernel Native NVMe协议的I/O 驱动。其主要原理是减少了VM中断等事件的数目(例如interrupt,和VM_EXIT),并缩短了host OS中的I/O栈;(3) SPDK加速数据库存储引擎。通过实现了RocksDB中的抽象文件类,SPDK的blobfs/blobstore目前可以和Rocksdb集成,用于在NVMe SSD上加速实现RocksDB引擎的使用。该操作的实质是bypass kernel文件系统将完全使用基于SPDK的用户态I/O stack。此外,参照SPDK对Rocksdb的支持,亦可以用SPDK blobfs/blobstore 整合其他的数据库存储引擎。
SPDK源码解读1
原文链接: https://www.cnblogs.com/yi-mu-xi/p/10966287.html
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍;
也有高质量的技术群,里面有嵌入式、搜广推等BAT大佬

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/403771
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!