

 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录
引言
perf是Linux上原生的一款性能分析工具。其拥有丰富的事件源与处理逻辑,如果对于内核代码比较熟悉的话,这就是一个可以被称为Linux显微镜的东西,可以说你可以基于它做任何你想做的性能分析,因为kprobes和uprobes的存在其可以在任意内核和应用代码中埋点,也支持eBPF,统计等处理逻辑。
看起来这玩意的功能好像是和Systemtap/bpfTrace差不多(当然这两个简单点,脚本毕竟比BPF程序简单),但是实际它更强大,因为随着这么多年的发展,它支持很多很有用的参数以进行性能分析。这篇文章的目的首先是阐述其基本用法,随后细致描述Event机制,最后举一些有意思的例子。
perf简单介绍
执行perf命令我们可以看到其支持的一堆子命令:
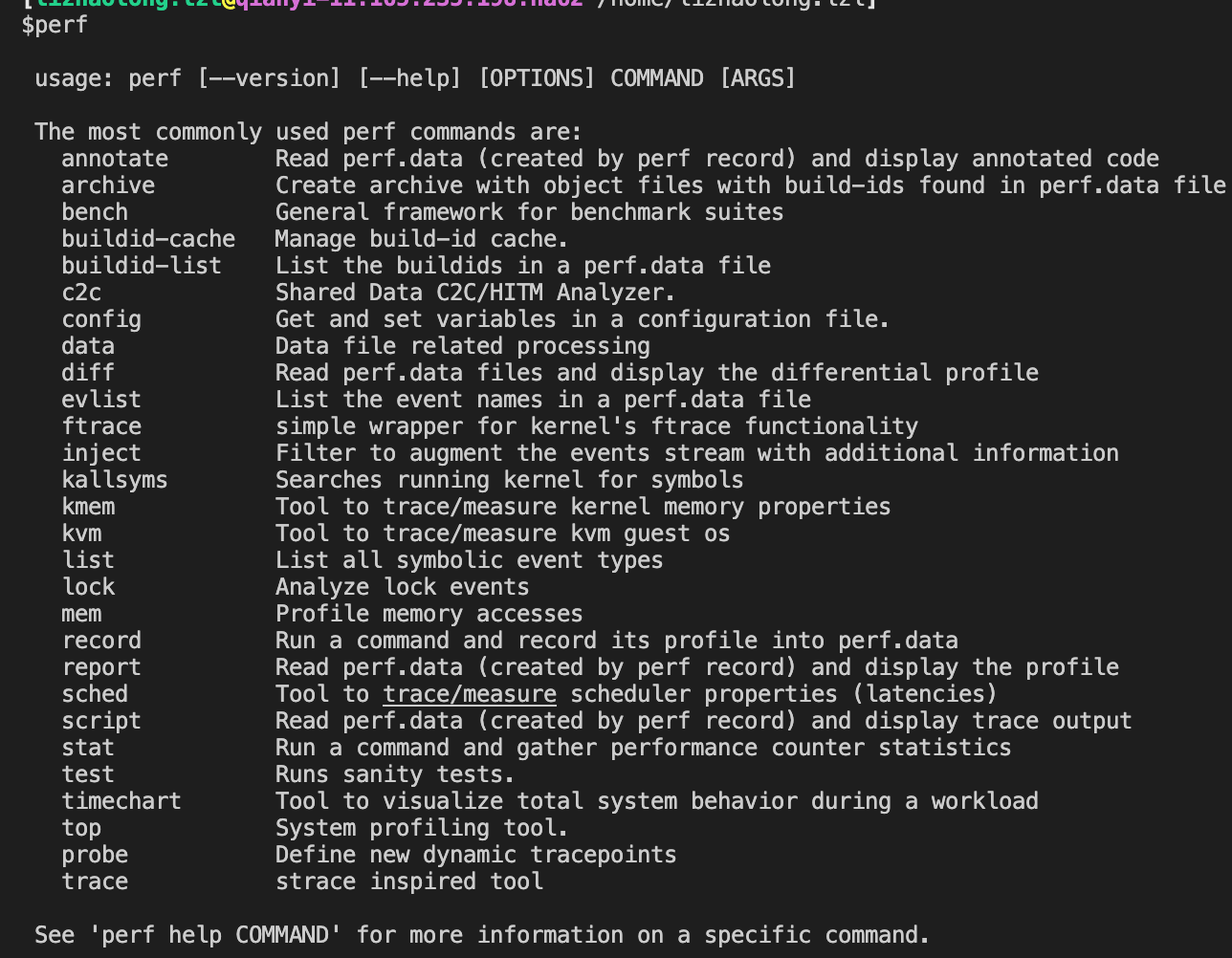
我们可以看到其中很多命令都是非常常用的,比如record(report/script),top,stat等等,尤其是top,甚至可以看到汇编级别的热代码,是十分牛逼的一个分析工具。这些子命令也分别拥有自己的help命令。可以看到perf本身提供的文档并不多,更详细的文档在源码的tools/perf/Documentation中
perf本身的原理也非常有意思,其把事件源视为perf_event,并分为task和CPU两个维度进行事件触发,本身支持counting,sampling以及bpf作为事件的处理流程。事件源类型(不是机制)被分为Hardware Events,Software Events,Tracepoint,USDT以及Timed Profiling。
bpfTrace内部也是可以基于perf_event机制去做事件源的:
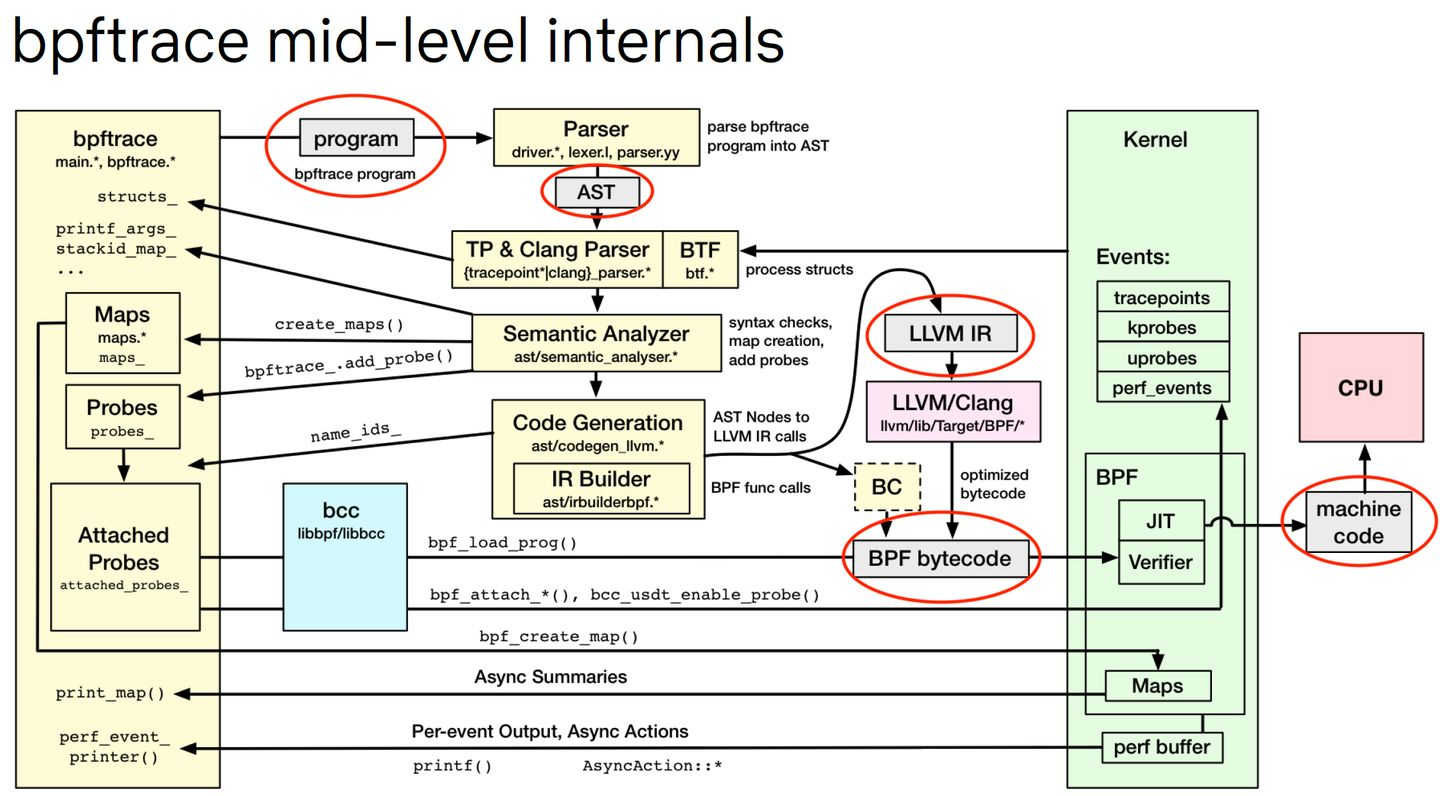
这篇文章先枚举几个基本但使用方法,然后分别介绍不同的事件类型与简单原理,最后进行总结。
常用命令格式
这一章节主要是列举一些常用的perf子命令,这些都可以应用到我们平时的排错过程中。
perf list
我们介绍几个比较有意思的perf命令,并简单实操下这几个命令,感受下这个神器的威力。
首先执行sudo perf list '*:*' | less,查看所有支持的Tracepoint Event。
perf record/report
然后可以执行sudo perf record -e 'sched:sched_switch' -ag:
这个命令对sched:sched_switch进行检测,并对数据进行聚合,-a对意思是对所有CPU都进行数据采集,-g对意思收集栈帧对消息,最后把数据输出到perf.data文件中。
然后执行sudo perf report,即可以查看perf.data文件,因为我们加了-g,所以可以看到每一项数据的栈帧。

perf top
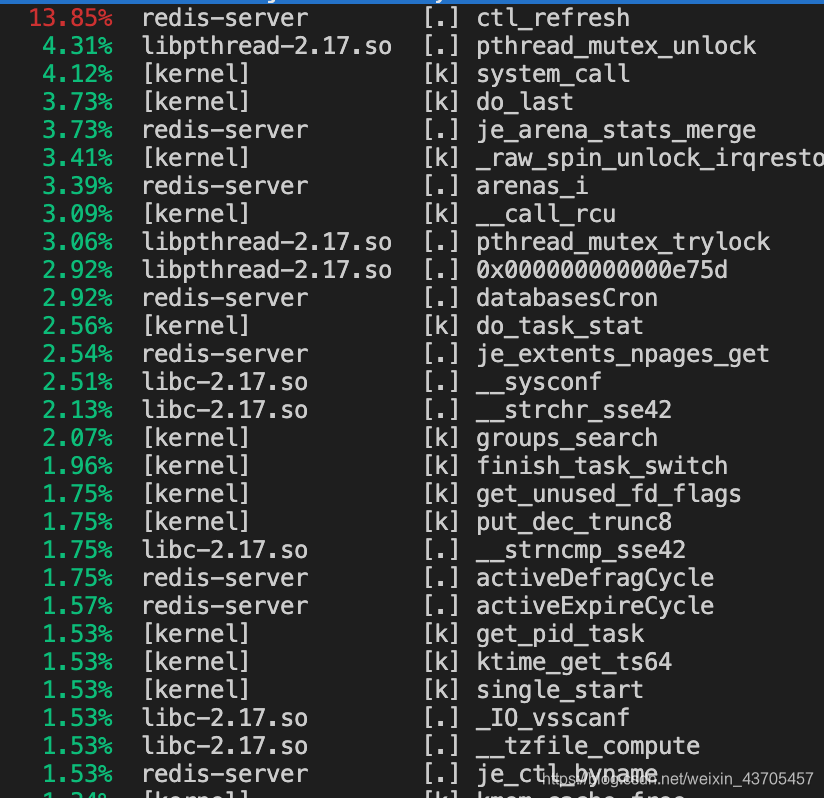
首先我们可以随意启动一个进程,这里我启动一个redis实例,找到其进程号然后执行sudo perf top -p 23981 -F 300HZ,这个指令的意思是300HZ就执行一个CPU-lock事件,查找进程23981的调用信息。然后我们就可以看到一个调用频率的排行,用方向键和回车可以查看一个事件的详细信息,甚至可以看到汇编级别的热代码。
perf stat
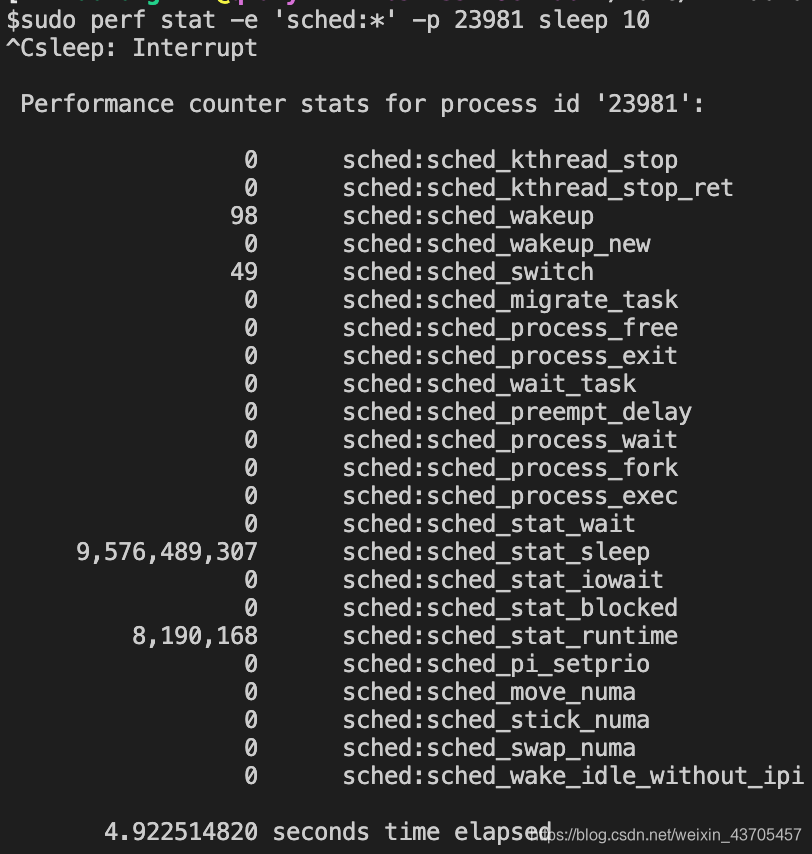
最经典的计数命令当然也不能少,我们可以执行如下命令sudo perf stat -e 'sched:*' -p 23981 sleep 10,可以查看被监控事件的counter数据。
perf probe
好了,现在我们用的一直都是pre-defined的事件,现在我们来尝试动态加入一个Tracepoint,执行如下命令sudo perf probe --add udp_sendmsg,这样我们就在udp_sendmsg中埋上了点:

我们可以执行如下指令查看对于指定probe来说有效的局部变量perf probe -V udp_sendmsg:
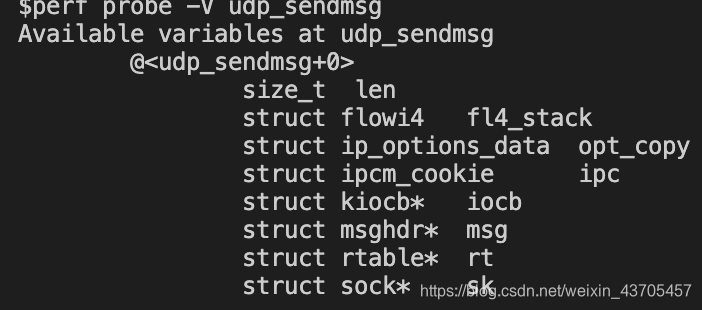
我们可以检测某个局部变量sudo perf probe --add 'udp_sendmsg len' -f,因为前面有同名的probe,需要加-f。然后执行sudo perf record -e probe:udp_sendmsg_1 -a采集数据,最后执行sudo perf report,可以看到len的值。我遇到的问题是report中的值都是十六进制数,也就是调试信息没有找到。
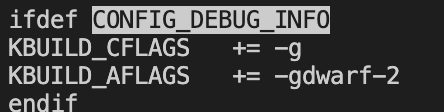
在内核的代码中查看Makefile,可以看到在定义了CONFIG_FRAME_POINTER和CONFIG_DEBUG_INFO时才会加载调试信息:
既然没有,说明编译内核的时候没有对应的调试信息,而且/proc/kallsyms文件大小也为零。
那理论我们使用kernel-debuginfo包就可以解决问题。yum下载以后可以执行sudo find / -name "*kernel-debuginfo*"找到包的下载路径,然后执行record --vmlinux=path,然后发现好像不是这么用的,找到[15]修改了vmlinux的参数为/boot下的文件,发现还是没有办法解决问题。
奇了大怪,到底该怎么找到调试符号呢,可能重新编译内核,加上调试信息就可以吧(但其他但perf信息就可以看到内核但堆栈信息,所以应该是操作问题)。事实上到现在我还是没有解决这个问题。
perf lock
我们可以检测锁的各种信息,但是需要CONFIG_LOCKDEP和CONFIG_LOCK_STAT编译选项的开启,执行如下指令perf lock record ls,然后执行perf lock report,就可以看到详细的信息。相比之SystemTap/bpfTrace就什么也不需要,直接就可以采集到perf可以采集到的所有数据,但是需要脚本编写者自身对内核代码有所了解。
我的机器编译时没有开这个:

perf mem
我们可以检测内核中的内存分配情况,首先执行sudo perf kmem record ls,然后执行sudo perf kmem stat --caller --alloc,就可以看到内核中内存分配的信息了:
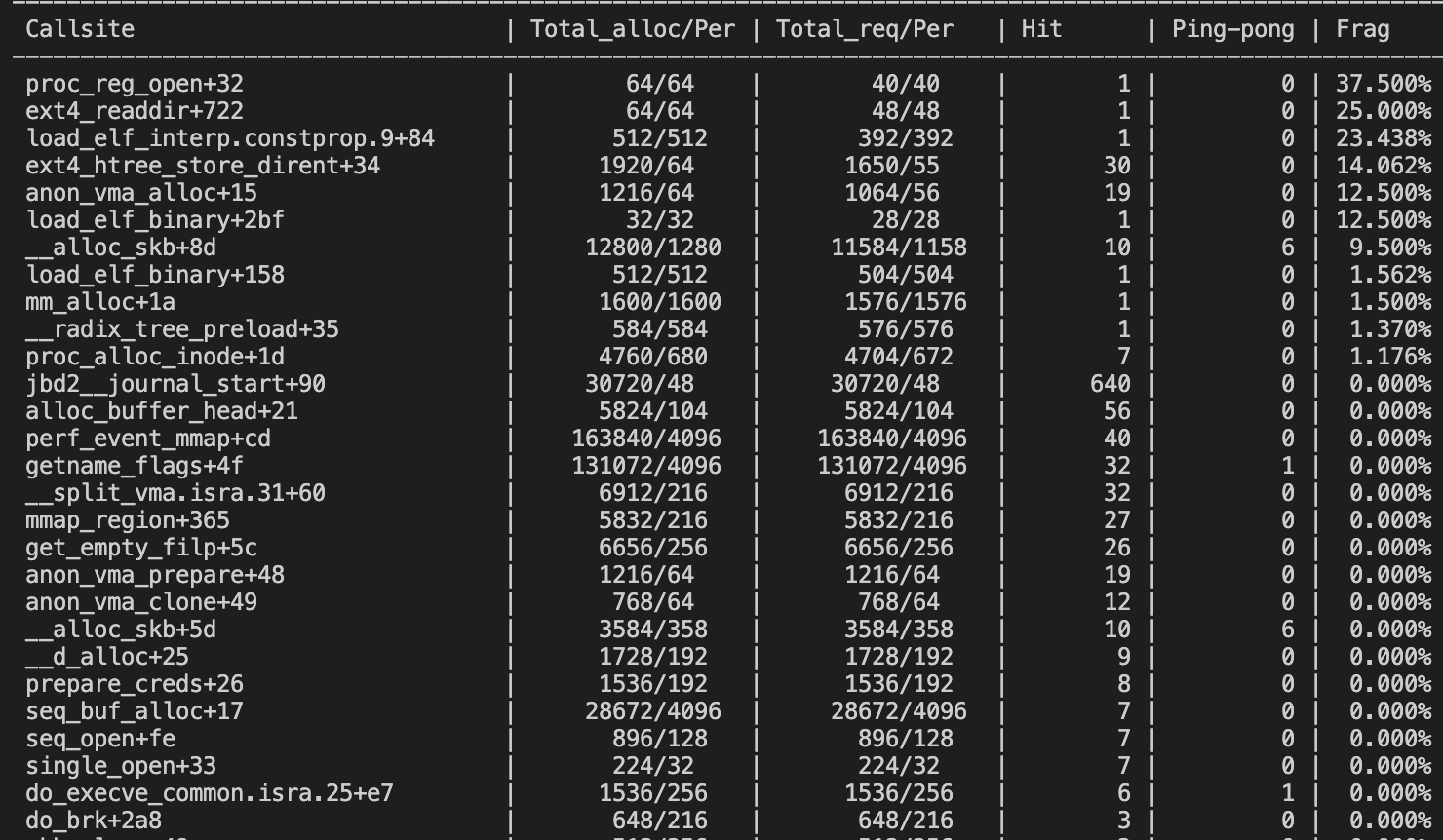
- Callsite:内核代码中调用kmalloc和kfree的地方。
- Total_alloc/Per:总共分配的内存大小,平均每次分配的内存大小。
- Total_req/Per:总共请求的内存大小,平均每次请求的内存大小。
- Hit:调用的次数。
- Ping-pong:kmalloc和kfree不被同一个CPU执行时的次数,这会导致cache效率降低。
- Frag:碎片所占的百分比,碎片 = 分配的内存 - 请求的内存,这部分是浪费的。
perf sched
我们也可以查看调度相关的事件,执行如下命令sudo perf sched record -p 23981,然后执行sudo perf report latency就可以查看一些调度属性。
因为是调度相关,先给redis benchmark上,执行./redis-benchmark -h 127.0.0.1 -p 6379 -c 100 -n 1000000,然后执行第一个命令,一两秒就累计了600MB的数据,然后执行第二个命令,我们可以看到如下输出:
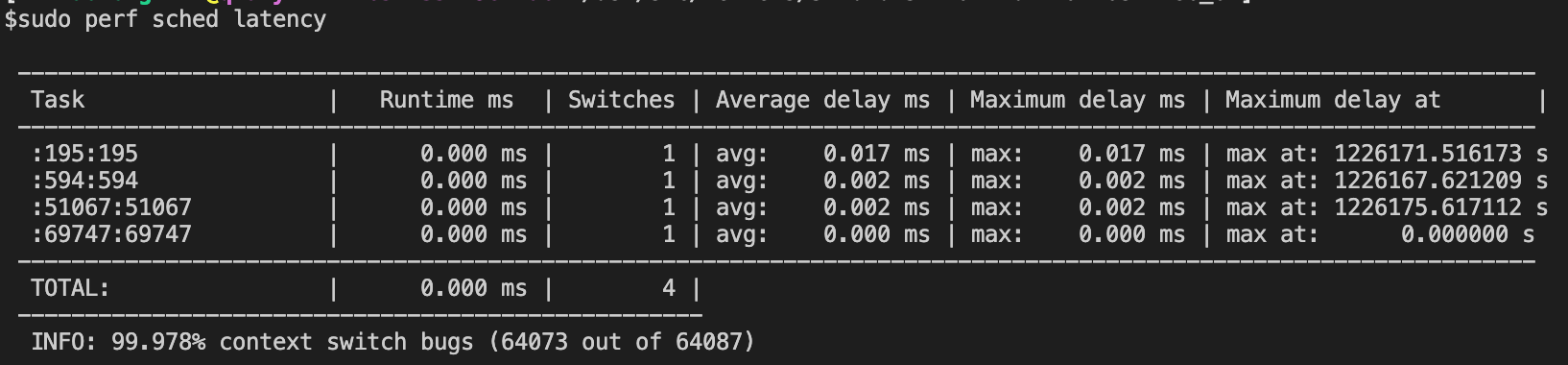
然后调用sudo perf sched script,我们就可以知道这个最高的时延发生的原因是什么:

还有一个子命令非常有意思,就是sudo perf sched map,这可以用图表的方式来查看不同CPU核上任务的转移情况,这种情况下显然前面监控redis的perf.data就不太适合作为例子了,因为绝大多数情况redis实例都是在一个核上跑的,我们先执行:sudo perf sched record -- sleep 1,再执行sudo perf sched map,可以看到类似这样的输出:

其中类似A0,B0,C0这样的标识符代表了一个任务,然后*代表CPU刚刚调度一个事件,.代表此CPU目前空闲,这种分析可以很好的观测当前系统中任务切换的情况。但是我认为能解决的问题有限,还是latecny搭配script实用一点。
更多sched相关可以查看[17]。
perf annotate
奇怪的一个子命令,这个命令可以看到所监控事件部分的高级语言代码和汇编,但是打印出来好像也没啥用,我发现不管去观察哪一个pref.data,总会有一句汇编是百分百的命中率,如果能够看到这个命令每句指令的命中情况的话就很棒了:
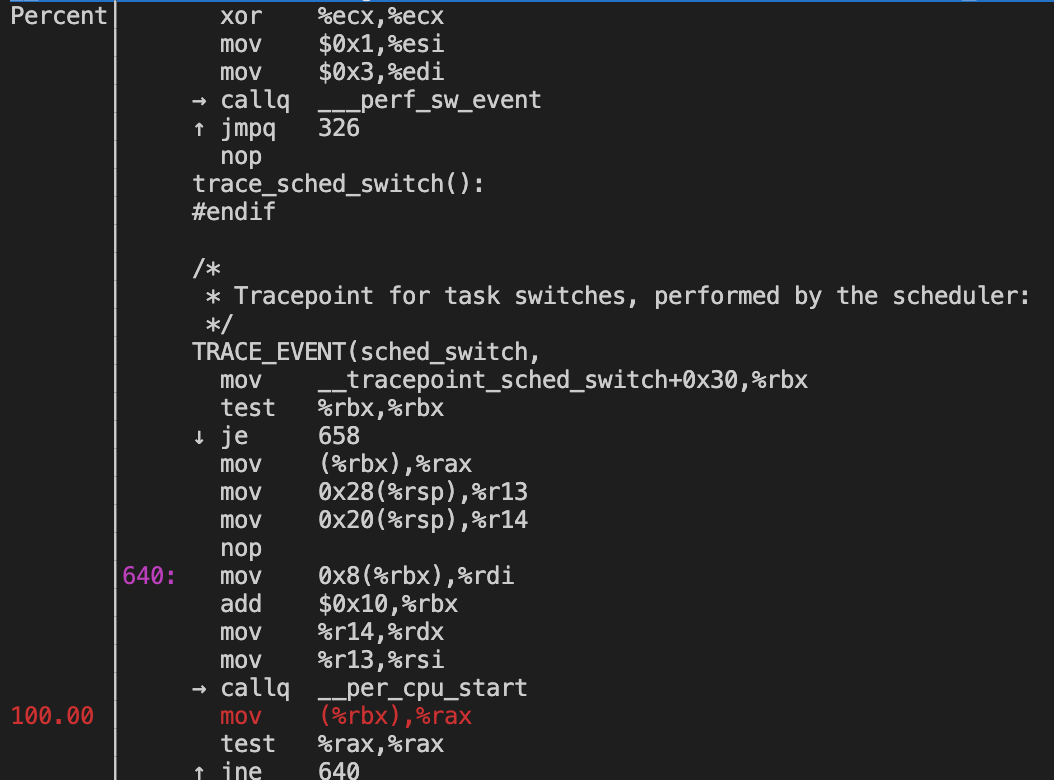
在[18]中可以看到正确的使用方法,确实可以显示出来每一句汇编的命中情况,类似于top的输出,但是我的输出结果貌似不太一样,不知道是哪里出现了问题
调试信息
对于调试信息,其实特指的就是符号信息和堆栈信息,[3]中有一句话基本讲清楚了我们需要的东西:
To get the most out perf, you’ll want symbols and stack traces. These may work by default in your Linux distribution, or they may require the addition of packages, or recompilation of the kernel with additional config options.
即我们所谓的调试信息要么通过额外的包来提供,要么通过编译时加上额外的编译选项来提供。
符号信息
一般来讲调试信息都是有的,就算没有perf report也会给出提示应该安装哪些包,但是上面perf probe遇到的哪种情况确实是比较奇怪的。
内核的编译信息可以在编译内核时打开CONFIG_KALLSYMS:
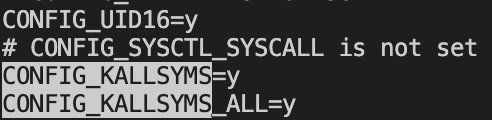
其次在各种子命令中我们都可以看到--vmlinux这么一个子选项,其解释如下:
–vmlinux=PATH::
Specify vmlinux path which has debuginfo (Dwarf binary).
一般vmlinux文件存在/boot目录下,就是其中那个vmlinuz打头的文件,但是看起来跑annotate的时候发现/usr/lib/debug/lib/modules/xxxxx/vmlinux好像才是vmlinux文件。具体可以参考[19],事实上probe时加上这个选项也没啥用,看起来缺的是udp_sendmsg的符号信息,但是实际这个符号是可以在vmlinux中被找到的(跑annotate的时候可以看到)。
堆栈信息
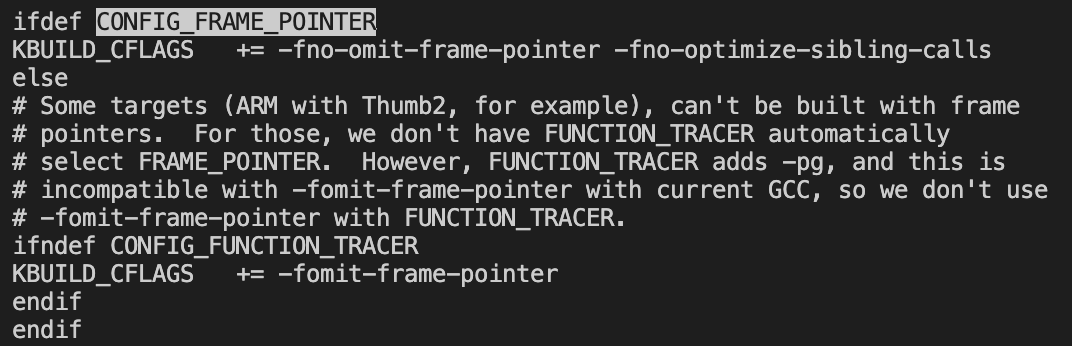
想要拿到堆栈信息首先我们需要堆栈不被优化,但是大多数时候栈帧优化(取消对于EBP到操作)是默认的,所以我们需要加入-fno-omit-frame-pointer。内核想要堆栈信息的话我们需要设置CONFIG_FRAME_POINTER=y,每次函数调用中多两个指令的代价为我们带来可追踪的特性,这是非常值得接受的一件事情。这个选项的含义在Makefile中可以看到其实就是下面的意思:

当然在人类智慧的大脑面前就算有这样的栈帧优化我们还是可以把堆栈信息提取出来,我们可以使用libunwind这样的库,使用dwarf文件去解析调用栈。具体可以参考[20]。
这里需要查个眼,我知道跑systemTap必须需要一堆debuginfo的包,但是我实在不知道这些包的内容是什么,看到这篇文章的朋友如果了解的话请给我一些帮助,我需要的是详细的,而不是笼统的“调试信息”,万分感谢。
Event
Event是perf最为重要的概念,其标识了可以触发perf的事件类型,这是perf如此强大的一个重要原因,[3]中解释了这个名词:
perf_events instruments “events”, which are a unified interface for different kernel instrumentation frameworks.
下面这幅图比较细致的描述了各类事件的关系。
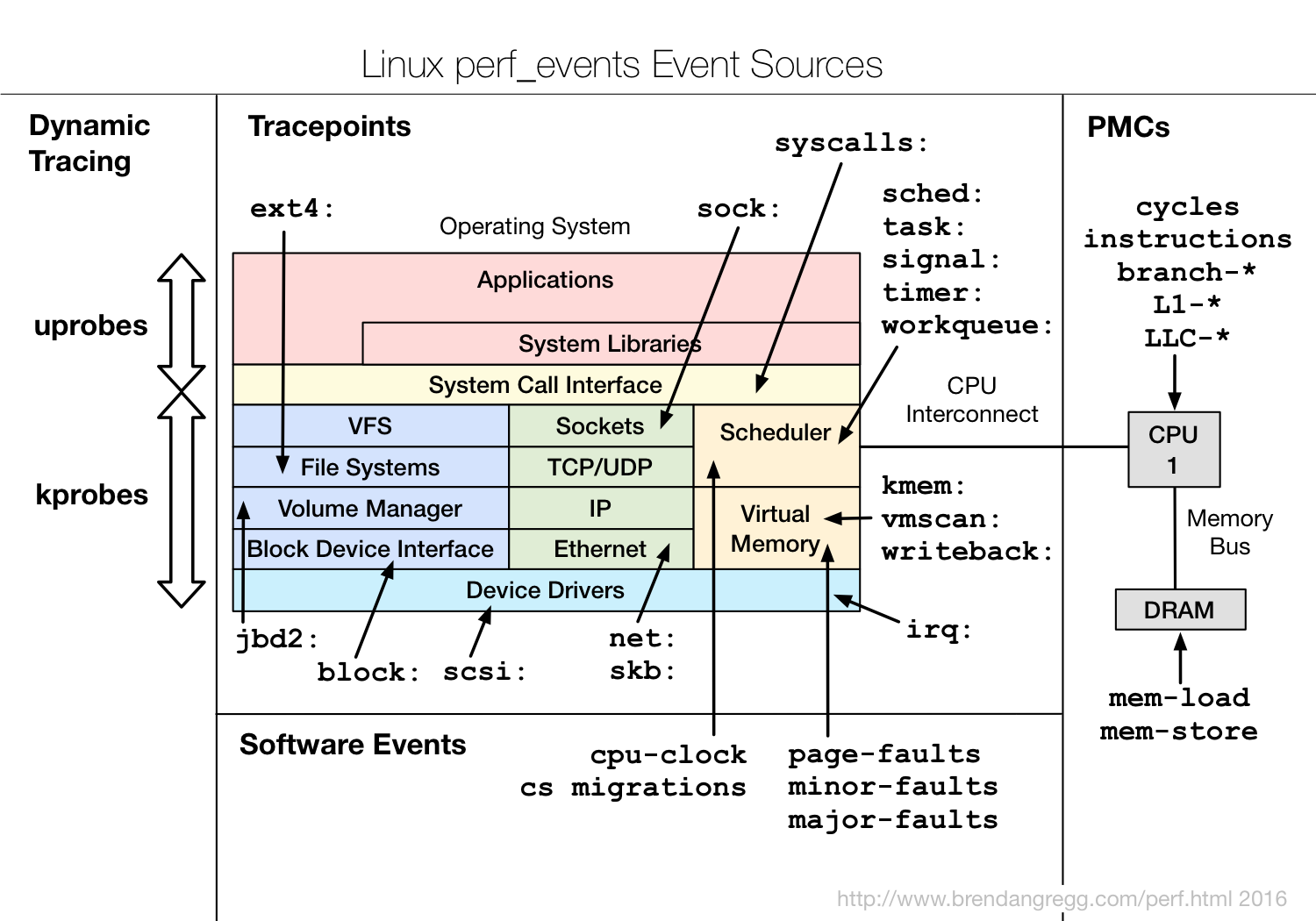
通过sudo perf list可以查看所有的event的名称,但是我还没找到一个资料描述每一个event的具体意义,systemTap都存在这样的网站,我想perf应该也是有的吧。
Hardware Events
大哥在[3]中是这样去描述硬件事件的:
perf_events began life as a tool for instrumenting the processor’s performance monitoring unit (PMU) hardware counters, also called performance monitoring counters (PMCs), or performance instrumentation counters (PICs). These instrument low-level processor activity, for example, CPU cycles, instructions retired, memory stall cycles, level 2 cache misses, etc. Some will be listed as Hardware Cache Events.
同时大哥也提到对于PMC来说比较详细的文档在《Intel 64 and IA-32 Architectures Software Developer’s Manual Volume 3B: System Programming Guide, Part 2》 和《the BIOS and Kernel Developer’s Guide (BKDG) For AMD Family 10h Processors》,我再因特尔手册里看到了如下的内容,这些应该就是相关的文档了,非常之详细,这也意味着把这玩意当作是一个字典也许更为合适,通篇阅读就显得不太理智了。

既然是硬件相关的,那一定会与机器本身相关,我三台测试机上就有两台对于硬件的支持不太一样导致对Hardware Event的支持不太一样,出于数据敏感,这里就不展示图片了。
展示一个我自己物理机的输出:
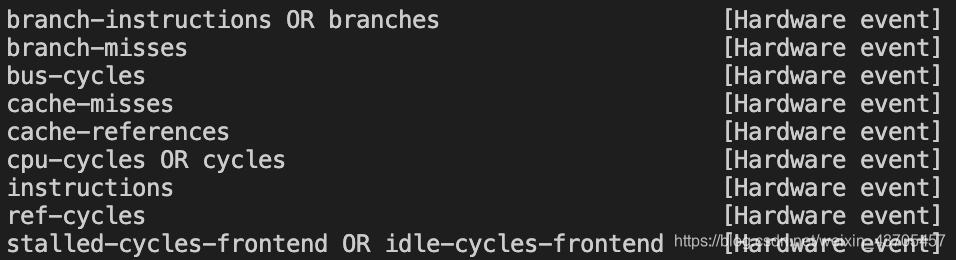
这里其实支持的Hardware event并不多,虽然事件的名字已经非常明显的阐述了其本身的意义,但是说实话,在没有一份非常完备的文档支撑是还是不能妄加定论,在[18]中对Hardware event的描述直接跳到了intel手册,说实话,想找到某个事件还是不太容易的。还好我冰雪聪明,发现其实[5]perf_event_open的手册中其实有对Hardware event的简单解释。
总而言之,Hardware event就是一种利用PMC去统计硬件事件的事件触发方式,不同的机器支持的事件不一样。
Software Events
和楼上一样,perf_event_open手册中也有对于事件比较详细的描述。
但是这里非常有意思,基于实现的原理,我们可以把Software Events分为三类:
- cpu-clock
- task-clock
- other
前两者基于hrtimer去做数据的采样,其他则是基于插桩法,在回调中对特定的perf_events做数据的输出。不过虽然是插桩,但是和Tracepoint的插桩实现的机制也是不太一样。
这里[3]中大哥也这样说到:
The kernel also supports traecpoints, which are very similar to software events, but have a different more extensible API.
当我们注册通过perf_event_open注册时Tracepoint和software Events有不同的类型,即PERF_TYPE_TRACEPOINT和PERF_TYPE_SOFTWARE,具体可以参考[7][8],这两种事件的实现机制不太一样,但是看起来达到的效果差不多,区别在我看来就是Tracepoint的埋点也可以共用给ftrace,而software Events则是perf自己私有的。
这里需要提一点的是所有的Software Events都默认有一个采样周期,我们可以在record的时候加上-vv选项来查看对应检测文件的perf_event结构体,执行perf record -vv -e context-switches /bin/true,我们可以看到输出中有如下内容:
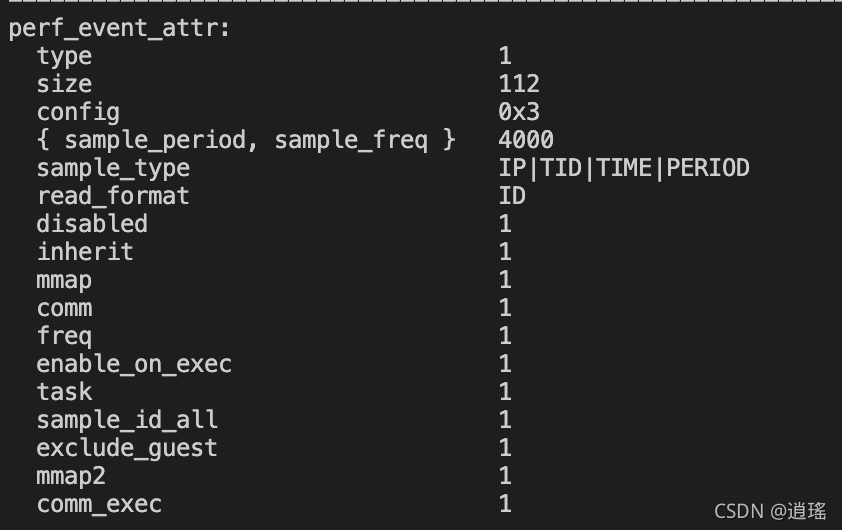
其中有一个枚举变量描述了频率相关的内容{sample_period,sample_freq},在[5]中有如下解释:
A “sampling” event is one that generates an overflow notification every N events, where N is given by sample_period. A sampling event has sample_period > 0. When an overflow occurs, requested data is recorded in the mmap buffer. The sample_type field controls what data is recorded on each overflow.
sample_freq can be used if you wish to use frequency rather than period. In this case, you set the freq flag. The kernel will adjust the sampling period to try and achieve the desired rate. The rate of adjustment is a timer tick.
其实就是当然freq被设置的时候,事件触发的就不再是用周期计算而是频率计算,但是我标记黑体的地方也很有意思,即并不是精确的取到这么多时间,而是内核动态的调整周期,以逼近我们希望的评率,这里的代码在[7]中__perf_event_overflow中,就是在freq模式下根据count的发生频率计算period的值。
Tracepoint
其实在上一节中已经解释了和software event之间的关系。其实这玩意说白了就是一个硬编码在内核汇总为了在不同版本中统一功能的一个接口,也可以顺便防止被有些特殊函数被内联以后监控不到的情况。当然基于kprobes我们也可以在不重新编译内核的情况下动态埋点,但是这种方法的坏处就是埋点的内核函数可能在不同的内核版本接口有所改变,不同的版本之间没办法做到共用一份脚本。
目前内核已有的Tracepoint已经非常多了,我们可以执行大哥的脚本来看到有哪些类型的Tracepoint:
sudo perf list | awk -F: ‘/Tracepoint event/ { lib[$1]++ } END { for (l in lib) { printf " %-16.16s %d\n", l, lib[l] } }’ | sort | column

但是居然和systemTap的默认probes不太一样,看起来systemTap并没有应用这些已有的tracepoint。
USDT
目前没需求,我应该一时半会用不到这东西,所以不想学也不想写了。bpfTrace中的USDT已经够好用了,都到了要埋点的时候了,为啥我不用SystemTap或者bpfTrace呢。
其他
可以在[20]中看到bcc这样的工具其实也是基于perf的把bpf和kprobes联系到一起的。
总结
强大的工具,但是定位比较尴尬,只能解决性能分析第一步的问题,即快速定位问题,但是没有办法更为细致的查错。而且bpf使用起来过于繁琐,不如通过bpfTrace使用bpf方便,或者使用systemTap也可以。
好处就是功能已经非常完善了,基本可以监测和提取所有我们希望的数据,生成火焰图也非常的容易,执行如下指令就可以:
git clone https://github.com/brendangregg/FlameGraph # or download it from github
cd FlameGraph
perf record -F 99 -ag – sleep 60
perf script | ./stackcollapse-perf.pl > out.perf-folded
cat out.perf-folded | ./flamegraph.pl > perf-kernel.svg
参考:
- [译] 使用 Linux tracepoint、perf 和 eBPF 跟踪数据包 (2017)
- perf Static Tracepoints
- perf Examples
- perf-stat(1) — Linux manual page
- perf_event_open(2) — Linux manual page
- Linux perf 1.1、perf_event内核框架
- Linux perf 1.2、tracepoint events
- Linux perf 1.3、software events
- Linux perf 1.4、hardware events
- Linux ftrace 1.1、ring buffer
- Linux内核 eBPF基础:perf(4)perf_event_open系统调用与用户手册详解
- 在Linux下做性能分析3:perf
- perf所有的事件源 版本不同可能不一样
- Linux perf events: cpu-clock and task-clock - what is the difference
- Linux: perf top, kernel symbol not found
- perf sched for Linux CPU scheduler analysis
- 内核态调测工具:perf(一)-perf sched
- perf wiki 各种子命令的使用非常详细
- vmlinux wiki
- libunwind原理介绍
- bcc 用法和原理初探之 kprobes 注入
- perf CPU Sampling
原文链接: https://www.cnblogs.com/lizhaolong/p/16437171.html
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍;
也有高质量的技术群,里面有嵌入式、搜广推等BAT大佬

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/396291
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!