

 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录
引言
Git是一个分布式版本控制工具,我想其大名在当今互联网界可以说是无人不知,无人不晓。也许学生时代不是刚需,但是工作以后像腾讯,阿里这样的公司团队协作的方式基本上都是Git,如果入职以后不会使用别人不说自己也会觉得有些尴尬吧,所以对于这种使用如此频繁,且如此牛逼的工具,我想学习其原理进而有效的利用它它是一个非常重要的事情。
遥记得当时我学习时翻遍了网上学习的资料,但是千篇一律,所有的资料都是从Git提供的树的这种抽象的角度去教我们如何使用Git,虽然其中不乏像[1]这样确实很良心的教程,但是站在学习者的角度还是理解的不够深刻,倘若我们能够学习Git的原理,这样就可以搞清楚Git的每一个操作实际做了什么事情,当然也就不会出现在做某些操作时手忙脚乱的情况了。
这篇文章旨在简单描述Git的存储模型,然后反推Git的部分基础操作的每一步操作到底做了什么。
.git目录解析
大多数人可能没有注意过这个隐藏目录的内容,其实这里面的藏着此项目所有的版本信息,借助这些东西可以实现我们任意跳转版本的功能,我们几乎所有的git命令也都会和这个目录打交道,可以说搞清楚这个目录的布局,基本把git用好就不是什么难事了,我们来看看一个普通的.git目录:

我们今天把重点放在objects目录,毫不夸张的说,object存储了我们所有的版本信息(git数据库)。object目录其中分为三个部分:
[0-9a-f][0-9a-f]开头的目录:这里存储着所有的对象,我们把一个对象存储在一个文件中,并使用文件内容SHA1一下取哈希值,前两个十六进制数字做目录,所以其实最多会出现256个目录,就像是哈希槽一样。packs:其中存放着很多对象的压缩格式。首先我们得清楚每次提交中修改一个文件都需要创建一个blob文件,而这个blob文件存储着整个文件的数据,但是可能每次修改我们只是改了一行,但是我们还是会存储一整个文件。.pack与idx就是这些类似文件的压缩和对应的索引。具体可以查看[7]。info:这个文档中主要存储一些额外的元数据,目前没有必要了解。
git四大对象
有一个模糊的概念即可。然后来看看git中的对象,我们把git中的对象分为四类:
commit:代表着一次Commit记录Tag:代表这一个Tag,这可以让我们迅速找到一个对象,不局限于commitBlob:代表着一个版本的文本文件tree:代表目录信息
我们来分别看看这些对象代表了什么。
commit
使用git cat-file -p hashcode可以把前面objects中Commit对象的信息用人类可读的格式展现出来:

其中除去作者,提交者,commit -m的信息以外,两个比较引人注意的就是tree对象和parent对象。parnet对象其实本质上还是一个commit对象,这个哈希值其实指向了上一次提交,当出现merge的情况是可能出现多个parent:

tree
而tree则指向了一个tree对象,使用git cat-file -p hashcode或者git ls-tree hashcode都可以显示对应的tree信息,在[4]中我们可以找到更多的选项:
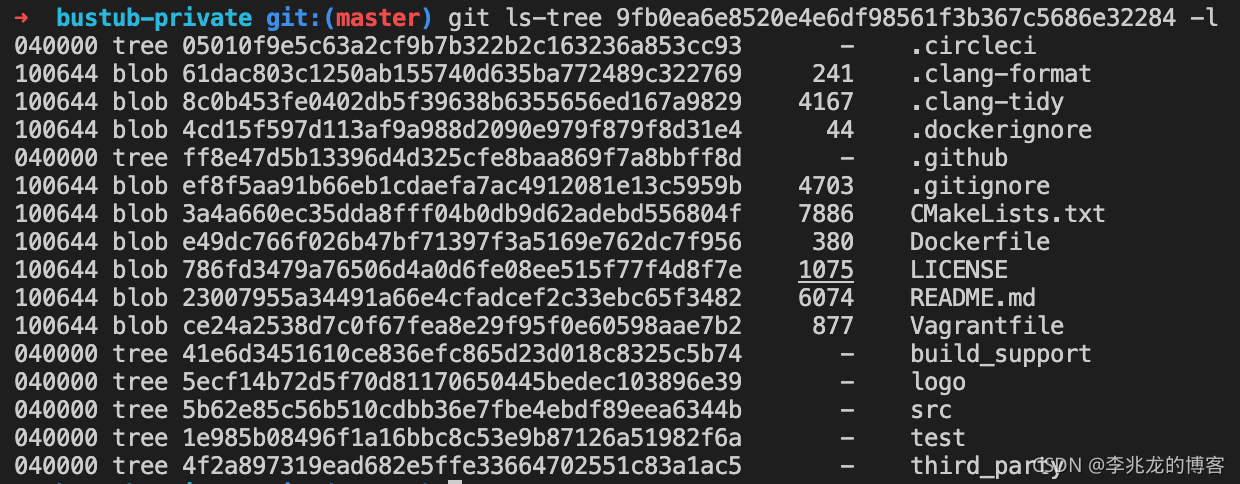
我们可以从文件名看出其实这个tree对应的就是整个项目的目录,此tree中也包含着一些tree对象,它们就是子目录下的子目录所对应的对象的值。
其中前面的mode对应关系如下:
| mode | file |
|---|---|
| 100644 | Normal |
| 100755 | Exe |
| 120000 | Symbol Link |
| 040000 | Dir |
blob
blob对象其实对应着一个文件的数据,我们随便打开一个blob对象(git cat-file -p),都可以看到这是一个全量的文本记录。也就是不同版本我们可能修改了文件的一行内容,但是这两个版本的文件的全部内容我会都记录下来(不考虑git gc的压缩),记录为两个blob对象。也就是说我们两个版本数据的差异git是怎么知道的,就是因为commit对象中存放着不同版本的所有的文件的哈希值。
也就是说两个版本之间如果我们只修改了一个文件,通过tree去索引到的这两个文件的blob是不一样的,其他都是一样的。
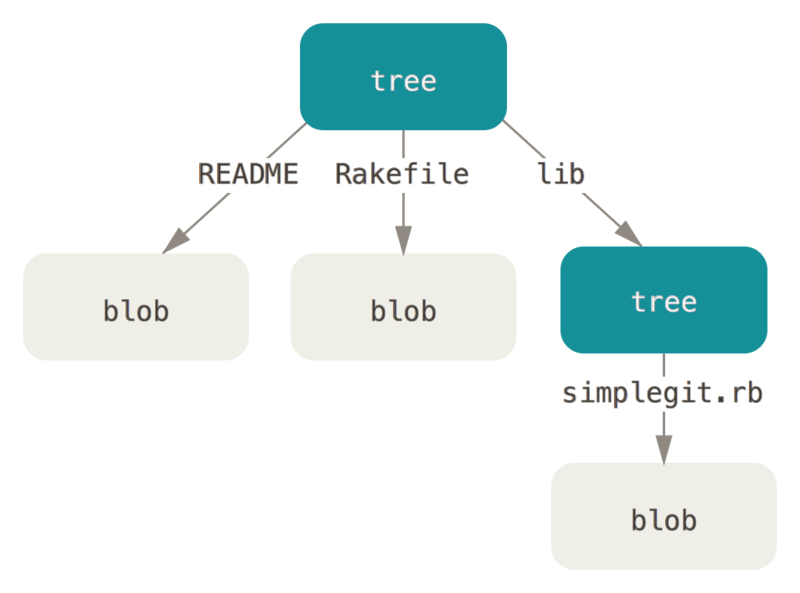
下面这幅图可以很好的显示git对象之间的联系:
tag
tag其实可以理解为一个索引,因为我们通过commit中的parent去查找某个特定的提交是非常慢的,所以需要对某些重要的提交打上tag,从而可以迅速的找到这个提交,一般来说软件的版本号就用tag来表示。
我们来创建一个标签,并看看标签中到底存来哪些数据:
-
git log --pretty=oneline,查看commit记录,挑选一个打tag -
git tag v1.1 -a f21253b50b6cc46f6d1d80a5eba307a4a3397753 -m "v1.1" -
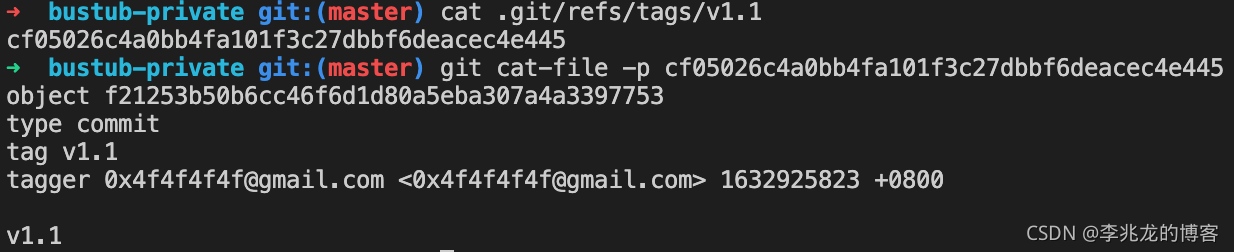
这里需要知道默认情况下tag是不会推送到远程分支的,我们需要在push的时候显式指定一个tag名才可以,这样做可以推送一个tag,如果想推送所有远端不存在的tag,需要执行git push origin --tags。
branch
其实branch和tag一样都非常轻量。
不同的分支本质上只是维护了不同的parnet罢了,所以实际上分支信息就是由commit对象中parnet的指向来维护的,所以此时object中那一堆哈希目录其实是得到了一个有向无环图,我们使用Head来标注不同的叶子节点,所以不同的Head其实就是图中的叶子节点,也就是每个分支的头,所以创建分支其实就是创建一个引用,指向一个commit对象,所以其实分支本身的开销是非常低的。
所以假设我们拥有一个主分支,其名称为master,可以看到其实就是指向了一个commit罢了。


index(暂缓区)
好了,让我们来聊聊我们经常在其他文章中看到的“暂缓区”的概念,也就是git add以后数据所在的区域,其实这个“暂缓区”就是.git/index中的数据。
我们可以通过git ls-files -s去查看.git/index中的数据,其实就是目录所有文件的版本。举个例子,我们首先修改b_plus_tree.cpp,然后add,查看index可以看到如下信息。

此时我们再修改index_iterator.cpp,再次查看index可以看到index_iterator.cpp的对象变了。

然后我们执行git reset HEAD src/storage/index/index_iterator.cpp,把暂缓区中的数据回滚,再次查看index,可以看到哈希值又变成初始的了:

此时有意思的事情来了,其实40fbb2e8493c14ac41e20a2316c4dc700d08b7ac这个blob对象并没有被删除,意味着暂缓区中中数据回滚理论是可以找回来的。
其实index中的数据分为三个部分,即header,index以及拓展部分,上面几幅图都是index部分,拓展部分不涉及。
header
header部分包含12bytes,我们使用hexdump -C .git/index | less来看看其中到底有哪些数据
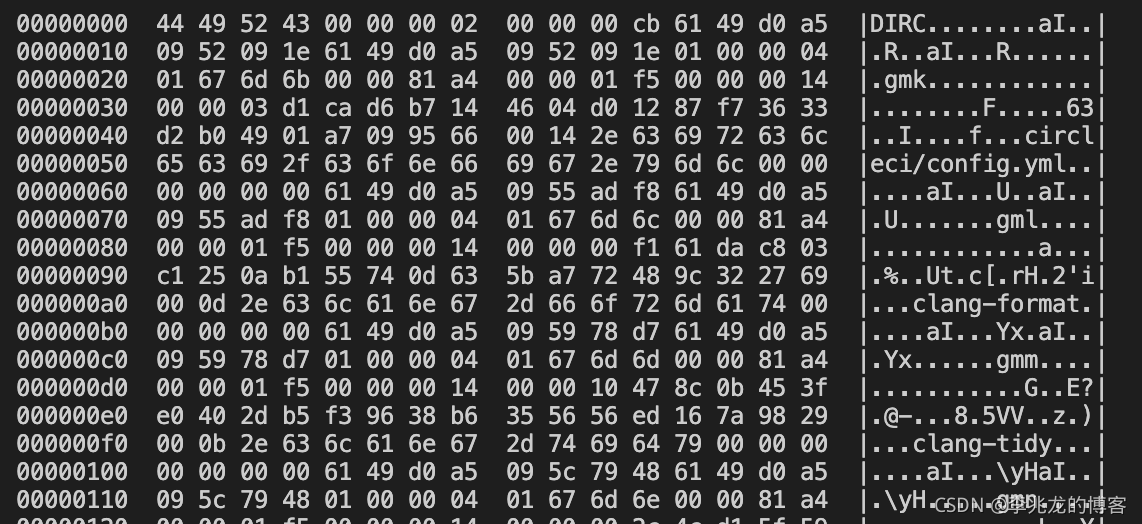
- 4-byte 的签名 0x44 49 52 43 即 “DIRC”,代表 dircache,文件夹缓存;
- 4-byte 的版本号,前面例中为 0x00 00 00 02,为十进制的 2,即代表该 index 文件版本为 version 2;
- 4-byte 的当前 stage 的文件数量,前面例子中为 0x00 00 00 cb,为十进 制的 203,即当前一共 stage 了203个文件。
index
中间的部分可以使用git ls-files -s查看,可以看到就是上面几幅图展示的,就是此版本的数据对象的索引,具体信息如下[6]:
- 8-byte (64-bit)的 ctime:该文件创建的时间 ctime 以 8-byte 来存储, 其中前 4-byte 为 32-bit 的以秒计算的时间 (Unix time:从 1970年1月1日 00:00:00 计算),后 4-byte 为 nanosecond 微秒。一般前 4-byte second 计 算时间就可以用。
- 8-byte (64-bit)的 mtime:mtime即该文件最后一次修改的时间,与 ctime 类似。
- 4-byte (32-bit)的 device:Device 即为该文件存储的设备。
- 4-byte (32-bit)的 inode:Inode 是该文件在设备的文件系统中存储的具 体块的编号。
- 4-byte (32-bit)的 mode:Linux文件系统中的文件有相应的权限设置 (mode),该信息用 4-byte 存于 index 文件中。例如,在hexdump 结果中, 该位置信息为 0x0000 81a4,转换为二进制为 00000000 00000000 10000001 10100100,对应的权限应该是 100644。这里不是简单的进制转换,而是从后向 前数,每三位代表一个权限,所以110100100对应的就是644。
- 4-byte (32-bit)的 UID:文件拥有者的 UID。
- 4-byte (32-bit)的 GID:文件拥有者的 GID。
- 4-byte (32-bit)的 文件大小:该部分为文件的大小。
- 20-byte (160-bit)的文件 SHA1 checksum。
- 2-byte (16-bit)的flag:若干字节的文件路径 file path:文件相对于工作目录的路径。如果就在工 作目录中,则是该文件的名字,如果是在文件夹中,则文件夹名字会包括在其中。
- 8-byte (32-bit)的空白文件分隔符:不同的index条目之间用于间隔的长 为 8-byte 的空白,即 0x00 00 00 00 00 00 00 00。
git commit
说了这么多,其实可以看到git的底层存储布局就是一个用哈希值去索引的“伪文件系统”,那么一次commit到底做了什么呢?
- 读取 .git/index ,生成相应的 tree 对象并进行存储。
- 将最外层的 tree 的 SHA1 记录到 提交元数据的 tree 字段。
- 将之前 HEAD 指向的对象的 SHA1 记录到提交元数据的 parent 字段(初始提交没有)。
- 向提交对象元数据添加一些字段信息(作者,提交者,时间)
- 添加用户输入的提交信息。
- 将上述数据以 commit 的对象文件格式存储。
- 更新分支引用文件的内容为 commit 对象的哈希值,也可能更改 HEAD 伪引用。
git gc
在index中我们提到当index中某个版本的文件被覆盖的时候,其实旧的文件还是存在的,不考虑回滚的话其实这个数据以及没有什么用处了。包括我们在一个分支上执行git checkout -m把head移动到较早的commit节点时,其实后面的数据也是没有用处的,当然在我们没有删除这些记录的时候还是可以根据git reflog看到前面的head的哈希值,从而再checkout回去的。
[8]中对这个命令的描述是这样的:
Runs a number of housekeeping tasks within the current repository, such as compressing file revisions (to reduce disk space and increase performance), removing unreachable objects which may have been created from prior invocations of git add, packing refs, pruning reflog, rerere metadata or stale working trees. May also update ancillary indexes such as the commit-graph.
总而言之,就是删除掉所有在树上不可达的文件,可以使用git fsck来查看不可达的对象。
更多的信息可以查看[9]。
常用的命令
下面记录一些在公司常用但在学校用的比较少的命令。
git commit --amend修改最新一次提交的commit信息与实际内容git rebase -i修改历史commit记录,可以合并或者拆分commit[11]git log -p --stat查看某个文件的历史修改commit记录git reset [--soft][--mixed][--hard]移动HEAD的指向,可选的保存工作区,暂缓区的数据,默认为mixed,即清楚暂缓区数据。git reset HEAD filename其实就是把某个文件回滚到HEAD的版本,当然可以是任意版本,默认参数mixed,最终取得的效果就是把暂缓区指定数据清理。git branch <branch> hashcode可以基于某一个提交建立一个分支git checkout commitid把当前HEAD指针移动到任意commit,此时会出现HEAD detach状态git revert commitid用一个提交删除一次提交git stash / git stash pop把暂缓区中的数据保存起来,方便去开发到一半时去其他分支看看git diff --cached [<commit-id>] [<path>...]查看暂缓区和最新和指定提交的区别git diff HEAD [<path>...]查看工作区和最新指定提交的区别git log --graph --oneline历史树状提交记录,当然vscode有现成的插件可以用git reflogHEAD所指向的一个顺序的提交列表,方便我们做错事时可以回滚git rm --cached filename停止追踪某些文件,也就是一些文件我们不希望push,需要停止追踪它git fsck --full显示所有不可达的对象
有意思的脚本
我们如何通过一个文件名找到以往所有记录中的blob信息呢,只需要执行git log -p --stat filename,这个命令可以打印此文件所有历史的修改记录,某个commit如果没有修改这个文件就不会显示,然后看其中index部分就可以了。
也可以执行如下脚本,出自胡哲宁之手,当然可以看到最后输出的数据是按照sha1的大小排列的,并不是按照树上的依赖关系来排列的。
git cat-file --batch-all-objects --batch-check | awk -v path=$1 ‘{if($2==“commit”) printf “%s:%s\n”,$1,path}’ | git cat-file --batch-check | awk ‘{if ($2!=“missing”) print $1}’ | sort | uniq
总结
在知道了Git底层存储以后,再去看很多命令就非常令人放松了,什么能干什么不能干这个难题也逐渐清晰明了了起来。所以与其去看一堆入门教程,不如先搞清楚数据是怎么存的,每一步操作到底干了什么,这样才可以保证自己在做每一步操作前是脑子清醒的。
参考:
原文链接: https://www.cnblogs.com/lizhaolong/p/16437167.html
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍;
也有高质量的技术群,里面有嵌入式、搜广推等BAT大佬

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/396283
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!