

 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
引言
Raft固然是一个经过严格证明的线性一致性算法,理论来讲一切都按论文走就不会有什么安全性问题,但很可惜,我们为了真的能在现实环境中使用Raft,必然需要一些优化。这篇文章起源于对[1]的思考,由我,胡哲宁和周子龙得到最后的结论。
Lease Read
这其中有一点就是所谓的Read Index以及Lease Read,其实也就是为了读操作效率更高而使得读操作实际不需要去做为Raft日志传播,只要保证读取的节点是leader就可以满足顺序一致性的读取,此时我们还并未引入时间这个棘手的问题,所以看起来一切都好。问题的关键在于如何确定节点是leader,自身状态?当然不行,出现分区的时候可能出现多个节点自身状态都为leader;或者向follow发送一个RPC确定自己是leader,这法子没问题,但是开销堪比直接把读操作当作日志;好了,机智的人们想出了一个好办法,就是所谓Lease Read的机制,既不需要把读当作日志,也不需要每次读操作发送RPC确定自己是leader。
leader发送RPC的时候,会首先记录一个时间点 start,当系统大部分节点都回复哪个RPC时,我们就可以认为 leader 的 lease 有效期可以到 start + election timeout + clock drift bound(正负未知)这个时间点。因为 follower 至少在 election timeout的时间之后才会重新发生选举,所以正常来讲这套机制是有效的,如下情况:
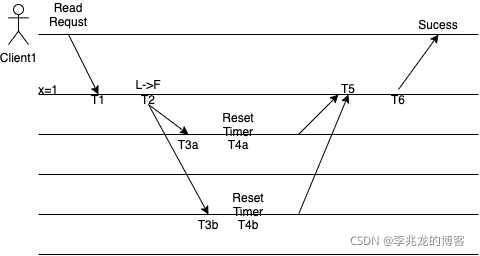
- T1时刻代表Leader收到了一个读请求
- T2时刻leader向follow发送RPC,确定自己是leader,并生成lease
- T3a,T3b时刻两个follow收到RPC,并在T4a,T4b重置自己的选举定时器
- T5 leader收到了两个follow的回复,并使得lease生效,生效时间为
T2+election timeout + clock drift bound - T6返回成功
问题
看起来没什么大问题,但是如果出现分区呢?我们考虑如下情况:
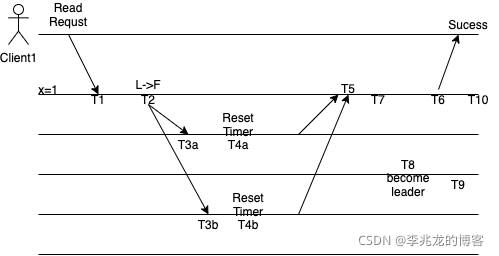
此时T7时刻leader和其他节点出现分区,T8时刻任意节点成为leader,并提交日志。我们假设提交日志时落后leader的lease在T10时刻才过期,即T10 = T2 + lease time,实际上在T4时刻follow才会重置时钟,所以租约的持续时长应该小于Election timeout,即我们实际上需要保证T10 - T4 < election timeout,因为如果等于的话可能会出现实际follow的开始选举时间是可能早于这个旧leader的租约的结束时间的。基于上式,我们带入以后得到T2 -T4 + lease time < election timeout,即我们需要保证这个式子。显然T2 < T4,注意这里是有一个RTT的,所以我们的结论就是lease time < election timeout + T4 - T2,所以lease time <= election timeout绝对是没有任何问题的。
考虑两种情况:
T10 < T6:lease过期,读操作无效。T10 >= T6:既然T10 lease time还未过期,此时返回正确。
所以这里lease time的设置不需要考虑RTT,只需要考虑时钟偏移。
所以看起来在lease time设置正确的话且认为时钟偏移在一个可接受的范围之内的话确实没有任何问题。比如TiKV设置election timeout为10S,lease为9S。
[6]中也提到了这个问题:
However, given that the underlying platform provides bounded-drift monotonic clocks, we believe that YugaByteDB’s architecture allows reading the latest value without querying a majority of replicas (a “quorum read”), so I will close this issue for now.
事实上我和胡哲宁也考虑过使用read timeout解决这个问题:
T6 - T1是读请求总时间,T6 - T4是我们不希望发生选举的时间,显然T6 - T1 > T6 - T4且我们希望保证election timeout> T6 - T4,如果要使得请求超时前election timeout不会发生,需要T6 - T1 < election timeout,即读超时的设置需要满足如下条件:election timeout > Read Time = T6 - T1 > T6 - T4,这样我们就可以使得重新选举之前已经超时。
但是read timeout > Read time,我们还是啥也没推出来,原因是混淆了这两者的概念,其实开始时想证明的就是一个lease的概念,可惜弄错了概念。
解决方案
[1]中提到了一种方法可以解决这个问题,即所有的读取操作附带一个相关日志的Term,然后利用这个Term解决冲突,比如前面读取了x = 3以后再读取x = 1,此时这个x = 1就会因为Term的落后而被客户端拒绝。
但是最大的问题是客户端一般需要读取状态机中的信息而不是日志中的数据,状态机中的数据基本不可能去维护一个相关日志的Term。
所以如何解决这个问题,一个是忽略这些误差,就像TiKV一样,或者放弃这种优化,使用read index。
可以参考[2],etccd对于一致性的保证如下:
etcd ensures linearizability for all other operations by default. Linearizability comes with a cost, however, because linearized requests must go through the Raft consensus process. To obtain lower latencies and higher throughput for read requests, clients can configure a request’s consistency mode to serializable, which may access stale data with respect to quorum, but removes the performance penalty of linearized accesses’ reliance on live consensus.
总结
总而言之,不存在银弹,要正确性没性能;要性能没一致性保证(因为正确性基于时间);
参考:
- https://github.com/etcd-io/etcd/issues/741
- etcd KV API guarantees
- https://groups.google.com/g/golang-china/c/-Lb8p1Zaz3c
- 共识、线性一致性与顺序一致性
- TiKV 功能介绍 - Lease Read
- https://github.com/yugabyte/yugabyte-db/issues/16
原文链接: https://www.cnblogs.com/lizhaolong/p/16437165.html
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍;
也有高质量的技术群,里面有嵌入式、搜广推等BAT大佬

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/396279
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!