

 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
内核版本为5.4.119
引言
我的读者应该都会知道我最近陷入了协议栈前加速内存数据库这个项目中不能自拔[5],这篇文章来阐述一个在实现过程中遇到的问题。首先阐述现象,然后引入skb_buff的线性区与非线性区,最后分析内核中bpf_skb_pull_data的实现。
现象阐述
有兴趣的朋友可以看看代码,其中brc_rx_filter_main都是主程序brc_tx_filter_main,前者挂载在ingress,后者挂载在egress。
我的需求是从__sk_buff中取出网络数据包实际payload的部分,开始时我尝试在egress中拿到端口6379传递的数据,然后解析其中的数据,首先数据包的大小应该是66字节(MAC 14,IP 20,TCP 20,payload 12字节),所以我尝试使用类似如下代码获取实际payload数据:
void *data = (void *)(long)skb->data;
void *data_end = (void *)(long)skb->data_end;
char *payload = data + sizeof(*eth) + sizeof(*ip) + sizeof(*tcp)
这样的方法在ingress中是成功的,但是在egress宏实际获取数据是失败的,我尝试使用如下代码打印在改变payload大小:
if (sport == bpf_htons(6379)) {
int tcp_len = tcp_hdrlen(tcp);
int ip_len = ipv4_hdrlen(ip);
bpf_printk("data_end - data -> [%d]\n", data_end - data);
bpf_printk("brc_tx_filter payload [%s] skb->len[%d]\n", payload, skb->len);
bpf_printk("brc_tx_filter tcp->len[%d] ip->len[%d]\n", tcp_len, tcp_len);
if (payload + 3 <= data_end) {
bpf_printk("payload: [%c] [%c] [%c] \n", payload[0], payload[1], payload[2]);
} else {
bpf_printk("gg\n");
}
}
在把payload从12改到13后分别得到如下结果:
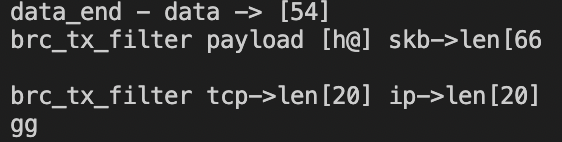

可以看到data_end-data一直答案都是54,也就是ip+tcp+eth的包头,但是skb->len却是总长度。
经过陈桓奇大佬的指点,我先尝试使用bpf_skb_load_bytes取数据,确实取到了,但是有一个问题,bpf_skb_load_bytes必须指定一个指针接收从skb中拷贝的数据:
This helper was provided as an easy way to load data from a packet. It can be used to load len bytes from offset from the packet associated to skb, into the buffer pointed by to.
但是BPF程序的栈大小只有512字节,这限制了可以load的出来的数据大小,除非循环load。
最后使用bpf_skb_pull_data彻底解决问题,其在man文档中解释如下:
- Pull in non-linear data in case the skb is non-linear and not all of len are part of the linear section. Make len bytes from skb readable and writable. If a zero value is passed for len, then the whole length of the skb is pulled.
- This helper is only needed for reading and writing with direct packet access.
- For direct packet access, testing that offsets to access are within packet boundaries (test on skb->data_end) is susceptible to fail if offsets are invalid, or if the requested data is in non-linear parts of the skb. On failure the program can just bail out, or in the case of a non-linear buffer, use a helper to make the data available. The bpf_skb_load_bytes() helper is a first solution to access the data. Another one consists in using bpf_skb_pull_data to pull in once the non-linear parts, then retesting and eventually access the data.
- At the same time, this also makes sure the skb is uncloned, which is a necessary condition for direct write. As this needs to be an invariant for the write part only, the verifier detects writes and adds a prologue that is calling bpf_skb_pull_data() to effectively unclone the skb from the very beginning in case it is indeed cloned.
- A call to this helper is susceptible to change the underlying packet buffer. Therefore, at load time, all checks on pointers previously done by the verifier are invalidated and must be performed again, if the helper is used in combination with direct packet access.
- 如果 skb 是非线性的并且len 由线性和非线性部分组成,则pull入非线性数据,使得 skb 中的 len 字节可读可写,如果为 len 传递了一个零值,则拉取整个 skb 长度。
- 此 helper 仅用于通过 direct packet access 进行读取和写入。
- 对于direct packet access,如果偏移量无效,或者如果请求的数据在 skb 的非线性部分中,则访问偏移量在数据包边界内的测试(在 skb->data_end 上测试)很容易失败。失败时,程序可以退出,或者在非线性缓冲区的情况下,使用helper程序使数据可用。 bpf_skb_load_bytes() helper是访问数据的第一个解决方案。另一种方法是使用 bpf_skb_pull_data 拉入一次非线性部分,然后重新测试并最终访问数据。
- 同时,这也保证了skb是未克隆的,这是direct write的必要条件。由于这仅需要是写入部分的不变量,因此验证程序检测写入并添加一个调用 bpf_skb_pull_data 的prologue,以从一开始就有效地取消克隆 skb,以防它确实被克隆。
- 对这个helper的调用很容易改变底层的数据包缓冲区。因此,在加载时,如果helper与direct packet access结合使用,则verifier先前对指针所做的所有检查都将无效并且必须再次执行。
文档中写的非常清楚。
上面提到的在TC egress中skb->data_end-skb->data实际是IP+TCP+eth的大小,但是ingress中skb->data_end-skb->data实际是IP+TCP+eth+payload的大小的原因就是非线性区的存在导致的。
也就是data_end - data其实是线性区的大小,而skb->len是线性区加非线性区的大小,前者其实是skb->data_len,但是BPF程序中无法从__sk_buff中直接拿到这个值。
non-linear and linear
这个问题[1][2][3]描述的非常清楚,我这里就不再阐述了。
但是我仍认为两个点还是必须要说,
第一是skb_shared_info在sk_buff是无法直接找到的,在访问的时候需要借助skb_shinfo宏来实现,关于NET_SKBUFF_DATA_USES_OFFSET可参考[8]:
#define skb_shinfo(SKB) ((struct skb_shared_info *)(skb_end_pointer(SKB)))
#ifdef NET_SKBUFF_DATA_USES_OFFSET
static inline unsigned char *skb_end_pointer(const struct sk_buff *skb)
{
return skb->head + skb->end;
}
#else
static inline unsigned char *skb_end_pointer(const struct sk_buff *skb)
{
return skb->end;
}
#endif
我们来看看alloc_skb的源码中关于skb_shared_info的分配:
static inline struct sk_buff *alloc_skb(unsigned int size,
gfp_t priority)
{
return __alloc_skb(size, priority, 0, NUMA_NO_NODE);
}
struct sk_buff *__alloc_skb(unsigned int size, gfp_t gfp_mask,
int flags, int node)
{
....
struct sk_buff *skb;
struct kmem_cache *cache;
// 尝试从缓存里面看看有没有可用的skb结构
skb = kmem_cache_alloc_node(cache, gfp_mask & ~__GFP_DMA, node);
if (!skb)
goto out;
// 从包含源操作数指定的字节的内存中获取数据的缓存行到一级或二级缓存中的某个位置,并使该行的其他缓存实例无效。[10]
prefetchw(skb);
// 最大程度的缓存行对齐
size = SKB_DATA_ALIGN(size);
size += SKB_DATA_ALIGN(sizeof(struct skb_shared_info));
// 参考[11],实际分配内存
data = kmalloc_reserve(size, gfp_mask, node, &pfmemalloc);
if (!data)
goto nodata;
// kmalloc(size) 可能会给我们比要求更多的空间。 将 skb_shared_info 准确地放在分配区域的末尾,以在重新分配之前允许最大可能的填充。
// 这个size就是实际可用使用的data,这里的ksize相当于malloc_size,size就是实际线性区可用用的大小
size = SKB_WITH_OVERHEAD(ksize(data));
prefetchw(data + size);
....
skb->head = data;
skb->data = data;
skb->end = skb->tail + size;
...
}
第二就是什么时候会使用no-linear,frag_list在处理IP分片时被使用,可以查看内核中的ip_fragment->ip_do_fragment函数,[1][2][3]中对这个部分的描述并不够详细,或者说对frags对描述还不够详细。
事实上我仍然无法解释为什么我的数据包会在egress中payload全部都在非线性区中,这是后续需要解决的问题,但我应该不会在这一篇文章中阐述这个问题。
这里突然想到了Redis中raw和embstr编码的转换规则为小于等于44为embstr,大于则是raw,原因在与redisObject/sdshdr8的大小和jemalloc缓存块的大小,有兴趣的朋友可以参考康康学长的[12]这篇文章。
这里其实和线性,非线性的概念比较类似了,不知道是不是一个突破口。
bpf_skb_pull_data
我对bpf_skb_pull_data把非线性区的数据如何pull到线性区非常感兴趣,因为非线性区有两种类型,但是文档中没有说明:
- 偏移如何对应到两种非线性区
frags和frag_list frags和frag_list在pull时的顺序问题- 如何扩展线性区的数据
bpf_skb_pull_data的作用在注释中写到非常清楚:
- Idea is the following: should the needed direct read/write test fail during runtime, we can pull in more data and redo again, since implicitly, we invalidate previous checks here.
- Or, since we know how much we need to make read/writeable, this can be done once at the program beginning for direct access case. By this we overcome limitations of only current headroom being accessible.
- 如果direct read/write test在运行时失败,我们可以pull更多的数据并redo,这里隐含地使以前的检查无效。
- 或者我们知道需要使读/写多少,这使得如果用于 direct access case 可以在程序开始时直接完成, 通过这种方式,我们克服了只能访问当前headroom的限制(headroom指的就是线性区)。
我在代码中使用方式就是经典的第二种情况。
所以我们来在源码中找一找答案:
struct skb_shared_info {
...
struct sk_buff *frag_list;
...
/* must be last field, see pskb_expand_head() */
skb_frag_t frags[MAX_SKB_FRAGS];
}
typedef struct bio_vec skb_frag_t;
/*
* was unsigned short, but we might as well be ready for > 64kB I/O pages
*/
struct bio_vec {
struct page *bv_page;
unsigned int bv_len; // page中数据长度
unsigned int bv_offset; // 代表相对开始位置的页偏移量
};
调用栈如下:
=bpf_skb_pull_data
=bpf_try_make_writable
=__bpf_try_make_writable
=skb_ensure_writable
---=pskb_may_pull
------=__pskb_pull_tail
---=pskb_expand_head
int skb_ensure_writable(struct sk_buff *skb, int write_len)
{
if (!pskb_may_pull(skb, write_len))
return -ENOMEM;
if (!skb_cloned(skb) || skb_clone_writable(skb, write_len))
return 0;
return pskb_expand_head(skb, 0, 0, GFP_ATOMIC);
}
static inline int pskb_may_pull(struct sk_buff *skb, unsigned int len)
{
if (likely(len <= skb_headlen(skb)))
return 1;
if (unlikely(len > skb->len))
return 0;
// skb_headlen其实就是获取线性数据的大小
// skb_headlen = skb->len - skb->data_len;
return __pskb_pull_tail(skb, len - skb_headlen(skb)) != NULL;
}
可以看到关键点是__pskb_pull_tail和pskb_expand_head,我们一个一个来:
__pskb_pull_tail
// 必要时向前移动 skb 头部的尾部,从fragmented部分复制数据。
// 1. 可能因为malloc失败而失败。
// 2. 可能会改变 skb 指针。
// The function makes a sense only on a fragmented &sk_buff, it expands header moving its tail forward and copying necessary data from fragmented part.
void *__pskb_pull_tail(struct sk_buff *skb, int delta)
{
// 如果 skb 尾部没有足够的可用空间,则扩展eat+128。 如果尾部有足够的空间,则仅在克隆 skb 时重新分配而不进行扩展。
// 这里eat是实际需要扩展的字节,注意end-tail是tailroom中目前还没有用到的字节
int i, k, eat = (skb->tail + delta) - skb->end;
if (eat > 0 || skb_cloned(skb)) {
if (pskb_expand_head(skb, 0, eat > 0 ? eat + 128 : 0,
GFP_ATOMIC))
return NULL;
}
/*
* skb_copy_bits - copy bits from skb to kernel buffer
* @skb: source skb
* @offset: offset in source
* @to: destination buffer
* @len: number of bytes to copy
* Copy the specified number of bytes from the source skb to the destination buffer.
*/
// skb_headlen = skb->len - skb->data_len; 也就是线性区大小;
// 没看懂这里干了什么,把skb中skb_headlen处的数据拷贝delta到tail?有什么意义?
BUG_ON(skb_copy_bits(skb, skb_headlen(skb),
// skb_tail_pointer: skb->head + skb->tail;也就是tail_room的起点
skb_tail_pointer(skb), delta));
/*
* static inline bool skb_has_frag_list(const struct sk_buff *skb){
* return skb_shinfo(skb)->frag_list != NULL;}
*/
// 一个小优化,frag_list没有就直接从frags开始
if (!skb_has_frag_list(skb))
goto pull_pages;
// eat被赋值为传入的delta,而不是上面算出来的需要多少字节
eat = delta;
// nr_frags是frags有效的字段数
for (i = 0; i < skb_shinfo(skb)->nr_frags; i++) {
// 拿到page中数据的长度
int size = skb_frag_size(&skb_shinfo(skb)->frags[i]);
if (size >= eat)
goto pull_pages;
eat -= size;
}
// frags都pull完了,eat还是剩一点
// 使用frag_list的扩展是比较复杂的
// 可以给skb数据加一个offset,但是考虑到pull预计是非常少见的操作,还是值得和进一步膨胀的skb hdr作斗争
if (eat) {
struct sk_buff *list = skb_shinfo(skb)->frag_list;
struct sk_buff *clone = NULL;
struct sk_buff *insp = NULL;
// insp记录的是最后一个list_entry
do {
if (list->len <= eat) {
/* Eaten as whole. */
eat -= list->len;
list = list->next;
insp = list;
} else {
/* Eaten partially. */
if (skb_shared(list)) {
/* Sucks! We need to fork list. :-( */
clone = skb_clone(list, GFP_ATOMIC);
if (!clone)
return NULL;
insp = list->next;
list = clone;
} else {
/* This may be pulled without
* problems. */
insp = list;
}
if (!pskb_pull(list, eat)) {
kfree_skb(clone);
return NULL;
}
break;
}
} while (eat);
/* Free pulled out fragments. */
// 把没用的entry删除
while ((list = skb_shinfo(skb)->frag_list) != insp) {
skb_shinfo(skb)->frag_list = list->next;
kfree_skb(list);
}
/* And insert new clone at head. */
if (clone) {
clone->next = list;
skb_shinfo(skb)->frag_list = clone;
}
}
/* Success! Now we may commit changes to skb data. */
pull_pages:
eat = delta;
k = 0;
for (i = 0; i < skb_shinfo(skb)->nr_frags; i++) {
int size = skb_frag_size(&skb_shinfo(skb)->frags[i]);
if (size <= eat) {
// 释放对frag(skb->frags[i])的引用。
skb_frag_unref(skb, i);
eat -= size;
} else {
skb_frag_t *frag = &skb_shinfo(skb)->frags[k];
// 这里把不需要拷贝到线性区的frags[k]拷贝到frags[i]
*frag = skb_shinfo(skb)->frags[i];
if (eat) {
// 为第i个frag修改偏移
// frag->bv_offset += eat;
skb_frag_off_add(frag, eat);
skb_frag_size_sub(frag, eat);
if (!i)
goto end;
eat = 0;
}
k++;
}
}
// nr_frags设置为k
skb_shinfo(skb)->nr_frags = k;
end:
// tail增加data
skb->tail += delta;
// 非线性数据减去delta
skb->data_len -= delta;
if (!skb->data_len)
skb_zcopy_clear(skb, false);
return skb_tail_pointer(skb);
}
基本的步骤如下:
- 计算需要的扩展的字节,并扩展
(skb->tail + delta) - skb->end+128 - 先移动
frags,再移动frag_list - 更新skb中的元数据
开始的问题清楚了两个。而且从源码来看bpf_skb_pull_data的第二个参数填__sk_buff->len这样的用法其实是最正确的,因为pskb_may_pull中在执行实际expend时会使用第二个参数减去线性区大小。
也就是这样用:
SEC("tc")
int test_a(struct __sk_buff *skb) {
bpf_skb_pull_data(skb, skb->len);
.....
}
pskb_expand_head
/*
* @skb: buffer to reallocate
* @nhead: room to add at head
* @ntail: room to add at tail
* @gfp_mask: allocation priority
* 扩展skb的header(如果nhead和ntail等于0的话就创建一个一摸一样的拷贝),&skbuff本身是没有改变的
* 其引用计数仍旧是1。如果扩展失败,不管成功还是错误都返回零。在最后一种情况下,&sk_buff不会改变。
**/
int pskb_expand_head(struct sk_buff *skb, int nhead, int ntail,
gfp_t gfp_mask)
{
// skb_end_offset = skb->end;
int i, osize = skb_end_offset(skb);
// size是新data的长度,以前就是ntail=headroom+data+tail_room
int size = osize + nhead + ntail;
long off;
u8 *data;
BUG_ON(nhead < 0);
BUG_ON(skb_shared(skb));
// cache-line对其
size = SKB_DATA_ALIGN(size);
if (skb_pfmemalloc(skb))
gfp_mask |= __GFP_MEMALLOC;
// 分配一块新的数据,当然大小是size + SKB_DATA_ALIGN(sizeof(struct skb_shared_info)
data = kmalloc_reserve(size + SKB_DATA_ALIGN(sizeof(struct skb_shared_info)),
gfp_mask, NUMA_NO_NODE, NULL);
if (!data)
goto nodata;
// 和__alloc_skb中一样,将 skb_shared_info 准确地放在分配区域的末尾
size = SKB_WITH_OVERHEAD(ksize(data));
/* Copy only real data... and, alas, header. This should be
* optimized for the cases when header is void.
*/
// 这里把原来所有的数据都拷贝过来了
memcpy(data + nhead, skb->head, skb_tail_pointer(skb) - skb->head);
// 把原来skb_shared_info中的除了无效frags以外的全部数据拷贝过来(nr_frags是有效的frags的下标)
memcpy((struct skb_shared_info *)(data + size),
skb_shinfo(skb),
offsetof(struct skb_shared_info, frags[skb_shinfo(skb)->nr_frags]));
/*
* if shinfo is shared we must drop the old head gracefully, but if it
* is not we can just drop the old head and let the existing refcount
* be since all we did is relocate the values
*/
/*
* 如果 shinfo 是共享的,我们必须优雅地删除old head,
* 但如果不是我们可以只删除旧头并让现有的引用计数,因为我们所做的只是relocate数据
**/
// skb->cloned &&(atomic_read(&skb_shinfo(skb)->dataref) & SKB_DATAREF_MASK) != 1;
if (skb_cloned(skb)) {
if (skb_orphan_frags(skb, gfp_mask))
goto nofrags;
if (skb_zcopy(skb))
refcount_inc(&skb_uarg(skb)->refcnt);
for (i = 0; i < skb_shinfo(skb)->nr_frags; i++)
skb_frag_ref(skb, i);
if (skb_has_frag_list(skb))
skb_clone_fraglist(skb);
// 如果引用计数为0就free包括非线性区内的所有数据
skb_release_data(skb);
} else {
// 把原来的data free掉
skb_free_head(skb);
}
// 不知道这个off有什么意义,可能与NET_SKBUFF_DATA_USES_OFFSET有关
off = (data + nhead) - skb->head;
skb->head = data; // 线性区起点
skb->head_frag = 0;
skb->data += off
#ifdef NET_SKBUFF_DATA_USES_OFFSET
skb->end = size; // 线性区大小为[data - data+size],所以实际新添加的数据在tailroom
off = nhead;
#else
skb->end = skb->head + size;
#endif
skb->tail += off; // data 和 tail同步在原来值上加off
skb_headers_offset_update(skb, nhead);
skb->cloned = 0;
skb->hdr_len = 0;
skb->nohdr = 0;
atomic_set(&skb_shinfo(skb)->dataref, 1);
skb_metadata_clear(skb);
// 没看懂
if (!skb->sk || skb->destructor == sock_edemux)
skb->truesize += size - osize;
return 0;
nofrags:
kfree(data);
nodata:
return -ENOMEM;
}
其实没有什么很trick的东西,就是正常的内存分配和memcpy,但是重要的一点是就算传入的 nhead和ntail 都为零data也会重新分配,这也是bpf-helper中bpf_skb_pull_data这样说的原因:
对这个helper的调用很容易改变底层的数据包缓冲区。
当然还有我们第三个问题的答案:
- 实际新添加的数据在tail_room
总结
我是一个大多数时候事件驱动,偶尔兴趣驱动的人,这决定了我在一个周期内的行为模式,讨论这种性格孰好孰坏的意义不大,但是它确实给了我扩展技能树的一个理由。
参考:
- Linux 内核网络协议栈 ------sk_buff 结构体 以及 完全解释 (2.6.16)
- sk_buff insight
- How SKBs work - kernel.org
- Linux Networking And Useful Tips for Real-Time Applications
- https://github.com/Super-long/ebpf-cache-for-redis
- linuxfoundation skb_buff
- socket buffer结构解析
- skbuff.h文件中NET_SKBUFF_DATA_USES_OFFSET宏的含义
- 趣谈Linux操作系统学习笔记:第二十四讲
- PREFETCHW — Prefetch Data into Caches in Anticipation of a Write
- kernel: mm: gfp_mask and kmalloc_reserve
- Redis的embstr与raw编码方式不再以39字节为界了!
原文链接: https://www.cnblogs.com/lizhaolong/p/16437148.html
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍;
也有高质量的技术群,里面有嵌入式、搜广推等BAT大佬

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/396247
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!