

 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
引言
再次忙里偷闲,抽出一晚上时间来记录一些文字。动笔写这篇文章纯属巧合,按照计划今天下午我本应该回趟宝鸡和家里人吃顿饭的,奈何昨天忘了做核酸,今早九点便起床(对昨天晚上疯狂焦虑的我而言已经够早了)赶往最近的核酸检测点,但却被告知明早九点才出结果,只好作罢,又把回家的日子往后推了一周,这也使得今天晚上多出了一些时间(当然也可以说这是未来的时间),遂记录下一个有意思的问题。
日志恢复相关的名词对于初学者来说如同噩梦,undo,redo,WAL,binlog,AOF,RDB,MANIFEST,SSTable等等名词一个还未搞清楚另外一个已经接踵而至的糊在脸上,实际上要搞清楚这些名词关键还是明白日志恢复到底是在做什么事情。我大抵是没功夫写一篇文章去总结他们之间的区别的,但是我可以基于几个已有的例子来聊聊这个问题,主要聚焦于Redis Multi Part AOF,LevelDB的version edit以及可能暂时只有adl和我知道的基于merkle tree的日志恢复,以及搞清楚基于merkle tree的日志恢复到底是在做什么事情。
Steal Policy 和 Force Policy
日志恢复中有两个很重要的概念,即Steal Policy和Force Policy,前者的含义是DBMS是否允许在事务未提交时用内存中的脏数据覆盖非易失性存储中的数据;后者的含义是DBMS是否允许事务提交时所有的更新都被写入非易失性存储中。不管承认与否,几乎所有的日志恢复都是基于这两种策略来做的。
我们熟知的WAL其实就是STEAL + NO-FORCE,以关系型数据库举例,在事务修改buffer pool中数据后不执行脏页刷新,在实际事务commit的时候日志被写入非易失性存储(可以group commit),然后才允许脏页刷新,这样做最大的好处就是执行时速度快,但是显然这样做我们需要redo和undo日志(所以关闭rocksdb的默认WAL的都是没实现事务的),而且恢复时需要重做所有的WAL,WAL还可能是基于语句的,这意味着在Recovery时相对是较慢的。
与之对应的是NO-STEAL + FORCE策略,Shadow Paging就是一种典型的实现。开始时master page table和shadow page table指向相同的地址,在实际写入时先把数据写到shadow page中,然后使得shadow page为master page,再重建shadow page,因为是树状,所以不需要重建整张表,但是这个重新建表的过程还是很昂贵,而且commit的成本也很高,不仅需要垃圾回收,而且需要刷新每个更新的页面、页面表和根目录。但是优势就是commit成功时数据才写入磁盘([2]不要使用mmap代替buffer pool!),这意味着不存在checkpoint,自然也就不需要redo和undo了,这意味着启动只需要载入非易失性存储上的数据即可。
LSM的日志恢复
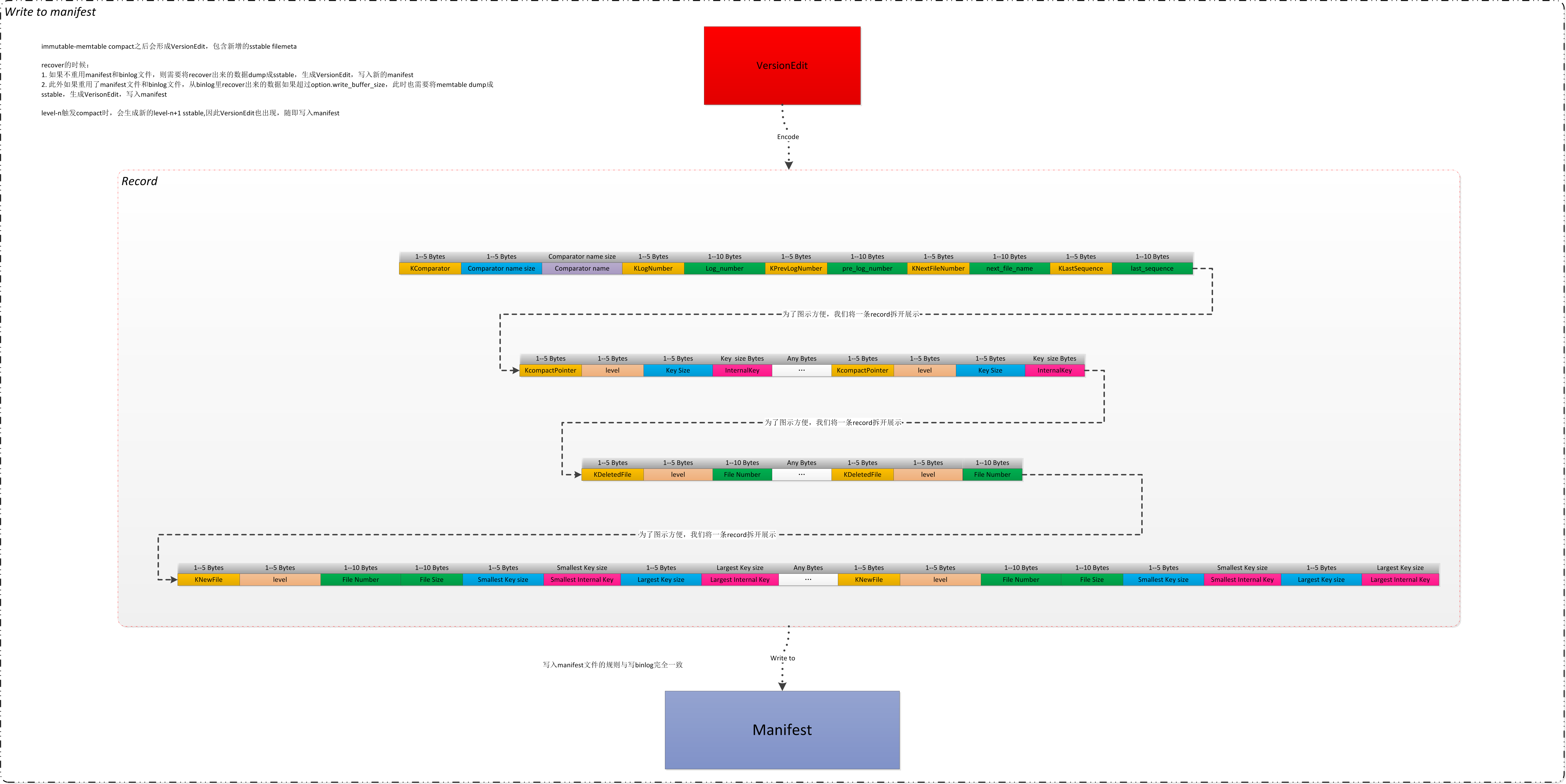
LSM树相关的日志恢复WAL只是针对于memtable的,实际大部分的数据存储还是在SSTable,随着每一次VersionEdit的变更,新的SSTable就被创建,对应的旧的SSTable也不再被使用,组织这些SSTable的文件就被称为MANIFEST,MANIFEST 用于在重启时将数据库恢复到最新的一致状态,LevelDB中用于恢复的函数是VersionSet::Recover,函数把文件中所有记录读出,通过DecodeFrom后生成VersionEdit[9],然后重放为宕机前的Version。
其实这类似于STEAL + NO-FORCE策略的结果,用Recovery时的低效换取运行时的高效(因为并不是所有的VersionEdit都存在于最后的Version),而基于merkle tree的做法则是类似于git的存储模型,在Recovery时一定所有的数据都是有效的。
在这个问题上花费太多的功夫其实并没有什么意义,因为MANIFEST的修改频率和log不是一个数量级的,而且总量也不是一个数量级的;其次站在Recovery的角度来说是不是merkle树也无所谓,当然引入关于在Remote Compaction上的优化思路则是另说了。
MPAOF
驱动哥的[1]这篇文章已经写的足够好的,我没必要再去陈述MPAOF的概念。我认为Redis的AOF其实就是一种特殊的WAL而已,因为其需要在数据库宕机时保证数据的持久性与事务的原子性,既然是WAL,那Checkpoint+WAL的做法总是没错的(内存数据库,当然不必讨论那两个buffer pool的策略了),至于rewrite则是生成Checkpoint而已,原来AOF最大的问题在于这个Checkpoint+WAL被塞成了一个AOF文件,这是一切低效和复杂性的根因。
MPAOF优雅的解决了上述问题,rewrite过程中子进程只需要把数据写入Base AOF,这其实就是checkpoint,rewrite过程中主进程的数据写入Incr AOF,也就是WAL,其实就这样来看是不需要MANIFEST的,但是如果使用的话意味着我们可以保存历史所有的AOF记录,rewrite的过程其实就是遍历整个DB去写逻辑日志的过程,基于MANIFEST中的history AOF,我们可以实现各种高大上的功能,比如PITR,全球多活等。
总结
偶然看到自己两年前写的一篇文章[8],不禁感叹时光荏苒,还有不到两个月就要走上社畜的道路了,刚进入大学,刚加入小组,第一次去工作的画面还在晚上失眠时不停的闪过,终究还是当学生好呐,可惜还是学生的时候却很少想过这件事情;还好琪宝还要读三年书,让我有机会在未来再踏进校园像学生一样的在操场拉手,食堂吃饭。
当然也有可能被裁了以后再去读几年书,谁知道呢,我一直坚信发生的大多数事情都是不可预测的,就像这篇文章诞生的原因一样,真正存在的随机事件!cool!
参考:
- Redis 7.0 Multi Part AOF的设计和实现
- Are You Sure You Want to Use MMAP in Your Database Management System?
- rocksdb manifest wiki
- MySQL · RocksDB · MANIFEST文件介绍
- leveldb之MANIFEST
- leveldb之Version VersionEdit and VersionSet
- 关于LSM-tree 的 Remote Compaction调度
- MySQL日志详解
- https://bean-li.github.io/assets/LevelDB/write_a_manifest.png
{kind=link}
原文链接: https://www.cnblogs.com/lizhaolong/p/16437144.html
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍;
也有高质量的技术群,里面有嵌入式、搜广推等BAT大佬

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/396239
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!