

 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
 本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
引言
在思考ZAB算法和Raft算法的异同时很疑惑,因为可以说很相似又可以说很不似。对于这个疑惑的深挖诞生了这篇文章。
问题描述
首先我们要清楚一个问题,一般来讲一个一致性协议会分为几个部分,这几个部分构成了完整的一致性协议。以Raft为例,其就是由领导人选举,日志复制,成员变更,日志压缩几个部分构成的;
而ZAB的基础版本是四个部分:
- Leader election
- Discovery
- Synchronization
- Broadcast
把选举阶段用 Fast Leader Election 优化以后可以缩减为三个阶段:
- Fast Leader Election
- Recovery
- Broadcast
图0,来源[9]
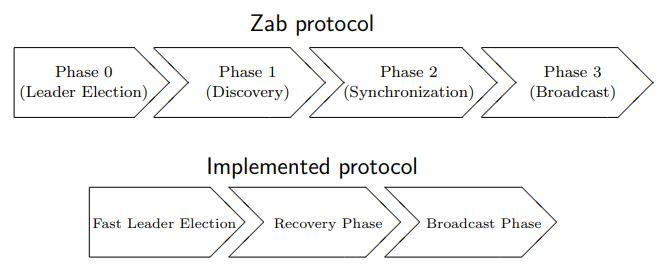
因为经过Fast Leader Election得到的Leader一定是日志最新的,自然可以把Discovery和Synchronization这两个阶段合并了。
当然我们我们可以看出其实几个部分是重合的,而且前者归为“部分”的特性也不代表后者没有。
有一点值得一提,就是Raft算法是以日志为核心的,在请求投票时附带的消息也是本身最新日志的index以及对应的Term,所以其保证了选出的Leader一定是拥有最新的已提交的日志的。
对应的,Fast Leader Election在请求投票时会携带zxid(其中低32位(32-bits)每一条新提案增加那个计数。高32位代表epoch),从[3]可以看出其也保证了选出的leader日志是最新的。
本篇文章就来看看Fast Leader Election与Raft的选举有什么区别。
Fast Leader Election
以下资料来源于[3]。
这篇文章目的非常纯粹,就是尝试解释清楚[3]中Fast Leader Election部分的伪码含义。
直接上代码。
图1:

图2:

首先是名词解释:
vote:这张选票是投给谁的id:服务器IDstate:结点状态round:epoch,也就是Raft中的TermReceivedVotes:票箱,存放着其他结点的最新投票
首先我个人认为选举可以分为这么两种情况:
- 全是
Election状态,比如说集群开始阶段,或者leader宕机,Follower转换为Election。 - 某个分区结束(可能很短,可能很长)的
Leader或者Follower,此时请求投票可以看到对方为Leader或者Follower
以上两种情况分别对应着图2的两个逻辑判断。其实简单来说就是此次选举中是否存在leader,分别对于选举结点的行为是晋升或者跟随。
好了,我们可以开始说伪码了,图1比较简单,直接看图2:
开始阶段
在判断进行一次选举时,先把票箱清理干净,然后填充选票内容,分别填充以下内容:
- 所推举的
Leader id:在初始阶段,第一次投票所有Server都推举自己为Leader。 - 所推举节点上最大
zxid值:这个值越大,说明该Server的数据越新。 round:这个值从0开始递增,每次选举对应一个值,即在同一次选举中,这个值是一致的。这个值越大说明选举进程越新。state:包括LOOKING,FOLLOWING,OBSERVING,LEADING。
然后把填充的选票发送给其他所有的对等结点。
然后图[1]中描述了收到选票时的行为,也就是如果本结点处于Election,就把此投票push到P.queue中。如果本节点的Round大于对端,还要发送一个本端的投票信息.
下面一个判断其实就是正常的ACK了,也就是我现在不是Election,但是有Election的大哥给我发送消息,那我告诉你我的配置好了。
处理选票
此时所有收到的选票信息放在P.queue中,从其中一个一个取,如果没有的话,就超时重传喽。
如果发送此选票的结点状态为Election:
- 如果发送过来的
round大于目前的round。说明这是更新的一次选举,需要更新本机的round,同时清空已经收集到的选票,因为这些数据已经不再有效。然后判断是否需要更新自己的选举情况。首先判断zxid,zxid大者胜出;如果相同比较leader id,大者胜出。当然更新了信息就意味这此节点目前把票投给了这个更新的结点,其他结点接收到后会不出意外会更新票箱。 - 如果发送过来的
round等于目前的round。根据收到的zxid和leader id更新选票,然后广播出去。 - 如果发送过来的
round小于于目前的round。说明对方处于一个比较早的选举进程,只需要将本机的数据发送过去即可。
把经过上面处理的票信息放入票箱。接下来根据已有数据更新:
- 判断票箱信息是否等于
SizeEnsemble,也就是服务器是否已经收集到所有的服务器的选举状态,此时可以做出判断。如果是根据选举结果设置自己的角色(FOLLOWING or LEADER),然后退出选举。 - 如果没有收到没有所有服务器的选举状态,也可以判断一下根据以上过程之后更新的选举Leader是不是得到了超过半数以上服务器的支持。如果是,那么尝试在
T
0
T0
T0 ms内接收下数据,如果没有新数据到来说明大家已经认同这个结果。这时,设置角色然后退出选举。
当然发送选票的结点状态也可能是leader或者follower,也就是上文提到的两种情况中的第二种。
首先判断round是否相同,是的话将数据保存到票箱,然后进行如下判断:
- 如果发送者宣称自己是
Leader,直接更改状态为Follower。 - 如果发送者宣称自己是
Follower,那么判断是不是半数以上的服务器都选举它,如果是设置角色并退出选举。
如果再走到下面的逻辑判断,说明这是一条与当前接收结点Round不符合的消息,当然有可能是更高的Round,也可能是更低的Round。
如果对端的投票指向自己,且OutOfElection中存在着半数的选票指向自己,此时晋升。
后面没看懂为什么。
总结
我们至少可以看出Raft和ZAB在选举阶段的不同之处:
Raft选举时每个Follower只持有投向自己的选票;Fast Leader Election每个Follower持有所有结点的投票信息,并可基于此做判断(图2 line25)。Fast Leader Election选举请求信息为:(
P
.
v
o
t
e
,
P
.
i
d
,
P
.
s
t
a
t
e
,
P
.
r
o
u
n
d
)
,
P
.
v
o
t
e
←
(
P
.
l
a
s
t
Z
x
i
d
,
P
.
i
d
)
(P.vote, P.id, P.state, P.round),P.vote ← (P.lastZxid, P.id)
(P.vote,P.id,P.state,P.round),P.vote←(P.lastZxid,P.id);而Raft为(
t
e
r
m
,
c
a
n
d
i
d
a
t
e
I
d
,
l
a
s
t
L
o
g
I
n
d
e
x
,
l
a
s
t
L
o
g
T
e
r
m
)
(term,candidateId,lastLogIndex ,lastLogTerm)
(term,candidateId,lastLogIndex,lastLogTerm)- 结点在收到一个更大的选票时会修改并广播自己的选票,且基于已接收结点的选票作为选主标准,只有
zxid以及id组合最大的结点可以成为Leader;而Raft相比之下就简单的多,只有在对端日志以及Term均大于自己时才会投票,基于得到的票数选主。两者均保证日志最新的结点选举成功。 Raft每个Term只能投票一次;而Fast Leader Election可以在一个Epoch内更改选票。
有一点我并没有找到资料,但我认为是一个很有意思的特性,当然也可能是我分析的有问题,也就是基于以上代码来看,Fast Leader Election的选举过程是不会失败的,因为所有结点最终都会持有其他结点的选票,而且只要大于一半的结点投票对象一致就会更改状态;相比之下Raft的选举因为上面的第4点会导致选举失败,并在一段时间后重试,当然可以加上一个超时参数,这样多次失败的概率就大大降低了。
最后一个问题,就是为什么Fast Leader Election比一般的Leader Election更快,基本上能搜到的答案就是短短一句话:
FastLeaderElection选举算法是标准的Fast Paxos算法实现,可解决Leader Election选举算法收敛速度慢的问题。
为什么收敛速度慢,以及Leader Election算法的细节,说实话都没找到资料,看来唯一的路就是zk的源码了,以后再说吧。
最后再提一点,在[6]中提到Fast Leader Election的效率高于Raft的选举,但是就理论来看确实Raft更快,因为只需要一轮消息,而Fast Leader Election中每收到一条优先级更高的选票就需要广播一次。没有数据,也不能妄下猜测,以后有机会测试一下。
参考:
- 论文《Zab: A simple totally ordered broadcast protocol 》
- 论文《In Search of an Understandable Consensus Algorithm(Extended Version)》
- 论文《ZooKeeper’s atomic broadcast protocol: Theory and practice》
- gitee《百度开源/braft ZAB协议简介》
- 知乎《raft协议和zab协议有啥区别?》
- https://time.geekbang.org/column/article/143329
- 博客《深入浅出Zookeeper(一) Zookeeper架构及FastLeaderElection机制》
- 文档《搜 Leader Activation 部分》
- 博文《ZooKeeper fast leader election (Fast Leader Election) mechanism analysis》
- 博文《Raft对比ZAB协议》
- 博文《死磕Zookeeper之Leader选举源码分析》
原文链接: https://www.cnblogs.com/lizhaolong/p/16437201.html
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍;
也有高质量的技术群,里面有嵌入式、搜广推等BAT大佬

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/396173
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!