
引言
定时器在我们平时的代码中有时也是很重要的组成部分 但其具体该怎么实现呢 其实方法很多 不管是基于升序链表还是小顶堆 其都可以实现定时器的作用 但效率始终显的不是那么优秀 小顶堆的插入始终在logn 升序链表则更差,这个时候时间轮算法就因为其效率的优势脱颖未出 插入与取出都是O(1) 时间轮算法(Timing_Wheel)最早出现在Linux kernel 2.6中 相比与前两者 显然效率更高
下文将会对一个轮子和五个轮子的两种时间轮进行分析并附上使用两种时间轮分别处理Server上的非活动连接 附上源码解析(C++实现)
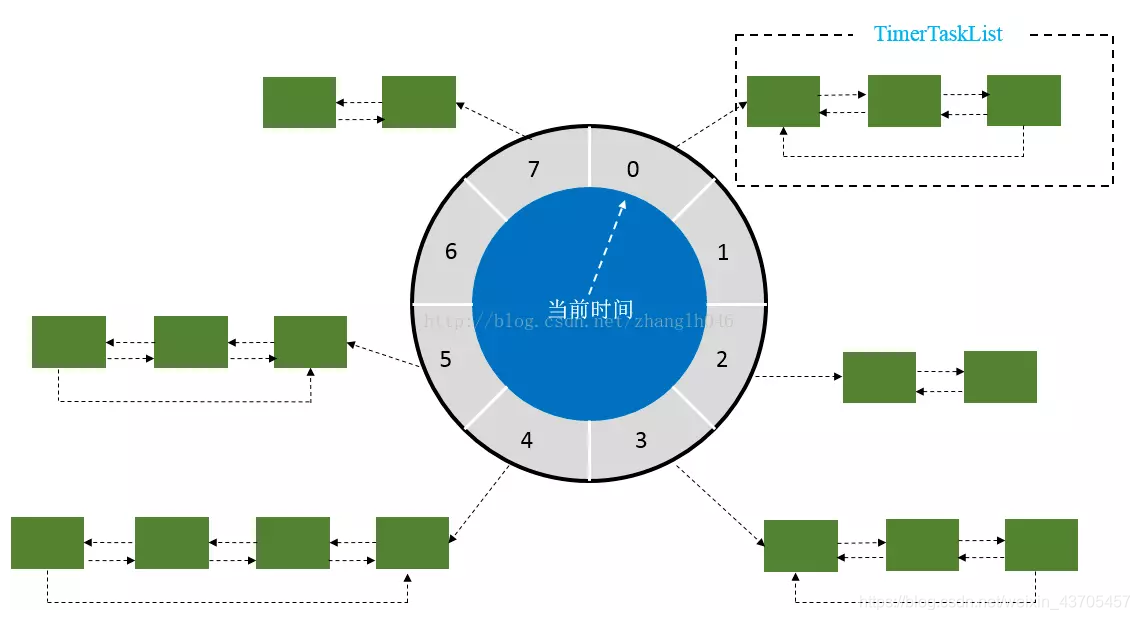

一个轮子的时间轮就如上图所描述 我们可以看到那个指针就指向了当前的槽 而槽中存储的则是一条链表 假设一个 心博时间为 si(slot interval) 一个时间轮共有N个槽 所以一个时间轮运转一周的时间则为 N*si
难道我们只能设置定时时间为这么长吗 其实也不是 我们可以选择在每一个链表的节点元素中维护一个圈数 当指针指向这条链表的时候 其中所有元素所维护的圈数可能并不相同 但其定时时间肯定是相差N*si的整数倍 我们只需要删掉其中圈数为零的元素 圈数不为零的元素我们只需要将其维护的圈数减一 指针再转过一圈以后就会删掉这个元素
那么我们该如何插入元素呢 换句话说 元素该插入到哪一个槽呢 我们设将插入的槽为ts(timer slot) 指针指向cs 给定时间为si 即有下式
ts = (cs + ( ti / si ) ) % N;
其中维护的圈数就是( ti / si )
这种时间轮最大的问题就是精度不够 要想提高精度就要使得si足够小 但是要减小si 在同等计时时间下单个时间轮就会变的很占内存 而且考虑一个问题 就是当计时的时间长到超出时间轮的极限时间 我们为了使其有效所采用的方法就是给每个元素维护一个圈数 但是有可能会出现计时时间恰好是接近于时间轮的一圈整数倍 如果这样的数据过多 就会导致元素分配不平衡 每一个心博时间遍历链表时都会导致多余的遍历 即圈数减1的时候 这种情况类似于操作系统中的抖动。
下面是一个利用单个时间轮处理Web_Server中非活动连接的应用 大概的思路就是把每一个连接的套接字加入时间轮 当发送消息时更新这个套接字在时间轮中位置 每个心博时间后操作指针指向槽上的链表 对于圈数大于0的圈数减一 圈数等于零的话断开连接 其实比较麻烦的是更新 因为我的实现中使用的是STL库中的链表 所以我们需要对于每一个连接返回其fd对应的迭代器 这样list的迭代器在增删后不会失效 所以我们可以放心操作
namespace Time_Wheel{
const int BUFFER_SIZE = 64;
class tw_timer;
struct client_date{
using itr = std::list<std::shared_ptr<tw_timer>>::iterator;
struct sockaddr_in address;
int socked;
char buf[BUFFER_SIZE];
itr ptr;
bool operator=(const client_date&) = delete; //不希望拷贝
};
class tw_timer{//定时器
public:
tw_timer(int rot,int ts):rotation(rot),time_solt(ts){}
public:
int rotation;//这个定时器还需要多少圈才生效
int time_solt;//当前定时器所属于时间轮的槽数
void (*cb_func)(std::shared_ptr<client_date>);
std::shared_ptr<client_date> cd = nullptr;
};
class time_wheel{
using itr = std::list<std::shared_ptr<tw_timer>>::iterator;
public:
time_wheel():vec(N),cur_slot(0){}
itr add_timer(int timeout){//参数为超时时间
if(timeout < 0){
throw std::exception();
}
std::size_t ticks = 0;
if(timeout < SI){
ticks = 1;
}else{
ticks = timeout / SI;
}
int rotation = timeout / N;//多少圈后被触发
int ts = (cur_slot + (ticks % N)) %N;//所在槽
auto timer = std::make_shared<tw_timer>(rotation,ts);
vec[ts].emplace_back(timer);
return --(vec[ts].end());//返回一个迭代器
}
void del_timer(itr tmp){ //传一个迭代器进来
int ts = tmp->get()->time_solt;
vec[ts].erase(tmp);
}
void tick(){
auto first_node = vec[cur_slot].front();
std::cout << "Current solt is " << cur_slot << std::endl;
if(vec[cur_slot].empty()){
cur_slot = (cur_slot + 1) % N;
return;
}
for(auto x = vec[cur_slot].begin();!vec[cur_slot].empty() || x == vec[cur_slot].end();x++){
if(x->get()->rotation > 1){
x->get()->rotation -= 1;
}else{ //定时器已经到期
x->get()->cb_func(x->get()->cd); //执行回调函数
vec[cur_slot].erase(x);
}
}
cur_slot = (cur_slot + 1) % N;
}
private:
enum{SI = 2,N = 60};//N为时间轮槽数 SI为一个心博时间 SI应该与信号发送间隔相同
std::vector<std::list<std::shared_ptr<tw_timer>>>vec;
int cur_slot; //当前时间槽
};
}
这个例子(完成的时间太长,代码有点丑陋)中我的接口并没有封装的很好 所以需要用户代码中自行处理迭代器 在五轮中我会进行改进 但这个例子中我们大体可以看出时间轮的实现思路
下面来是五个轮子的时间轮的介绍
首先我们来看一张图(感谢百度)

其他的不重要 我们要看的就是上面的那几个轮子 只是多个轮子的时间轮和这个很像就是刻度最小的轮子转一圈 更高一级的轮子转一格 以此类推
我们可以用一个数组或者容器来表示轮子 其实其中的进位倒也不难实现 但是比较麻烦 有一个更加简单巧妙的方法就是用一个uint32_t的整数来表示时间轮
| 6bit | 6bit | 6bit | 6bit | 8bit |
111111 111111 111111 111111 11111111
大概就是上面这样的实现 我们可以利用几个宏函数得到每一轮子上的值 从而去加相应槽上的定时器节点 用一个整数代表时间轮还有一个好处就是天然的进位
下面是几个宏函数
// 第1个轮占的位数
#define TVR_BITS 8
// 第1个轮的长度
#define TVR_SIZE (1 << TVR_BITS)
// 第n个轮占的位数
#define TVN_BITS 6
// 第n个轮的长度
#define TVN_SIZE (1 << TVN_BITS)
// 掩码
#define TVR_MASK (TVR_SIZE - 1)
#define TVN_MASK (TVN_SIZE - 1)
// 第1个圈的当前指针位置
#define FIRST_INDEX(v) ((v) & TVR_MASK)
// 后面第n个圈的当前指针位置
#define NTH_INDEX(v, n) (((v) >> (TVR_BITS + (n) * TVN_BITS)) & TVN_MASK)
通过上面这几个宏函数我们可以准确的得到每一个轮上我们需要的槽数,那五个轮子的定时器究竟是如何达到提升效率的呢 我们可以意识到一个问题就是在最小刻度的时间轮上的数据一定会被删除 而放在高刻度时间轮上每个槽上的链表中的数据是低刻度时间轮上的全部数据 这样意味着我们对同一个数据操作的次数不会超过全部的时间轮数 在大量的数据下显然是有显著的效率提升 下面是一个利用五个轮子的时间轮关闭非活动连接的例子 其中最需要注意的就是TW_Add() 和TW_Tick()这两个函数 一般情况下我们是在时间轮中放一个回调函数 这个demo中感觉没有必要就只是放了一个fd而已 其实都可 具体实现还是要看所针对的情况
Timing_Wheel.h
#ifndef TIMINGWHEEL_H_
#define TIMINGWHEEL_H_
//高精度时间轮适合的场景是需要大量不等的定时任务 这样可以使每个时间槽上的链表长度显著减少 提高效率 但涉及到移动链表
//单个时间轮其实在定时任务差别不大 加大时间轮的槽数 可以使得分配平均 在这个场景下效率同样不低
#include<list>
#include<iostream>
#include<vector>
#include<memory>
#include<stdexcept>
#include<unordered_map>
#define TVR_BITS 8
#define TVR_SIZE (1 << TVR_BITS)
#define TVN_BITS 6
#define TVN_SIZE (1 << TVN_BITS)
#define TVR_MASK (TVR_SIZE - 1)
#define TVN_MASK (TVN_SIZE - 1)
#define FIRST_INDEX(v) ((v) & TVR_MASK)
#define NTH_INDEX(v, n) (((v) >> (TVR_BITS + (n) * TVN_BITS)) & TVN_MASK)
class TimerWheel{
class timernode{
public:
explicit timernode(uint16_t solt , int fd_, uint32_t ex) :
time_solt(solt), fd(fd_), expire(ex){}
int Return_fd() const noexcept {return fd;}
uint32_t Return_expire() const noexcept {return expire;}
int Return_solt() const noexcept {return static_cast<int>(time_solt);}
int Return_wheel() const noexcept {return static_cast<int>(time_wheel);}
void Set_Wheel(uint8_t sw) noexcept {time_wheel = sw;}
private:
uint16_t time_solt;//槽数
uint8_t time_wheel;//轮数
int fd;//socket套接字
uint32_t expire; //到期时间
};
using itr = std::list<std::shared_ptr<timernode>>::iterator;
using TVN_ = std::list<std::shared_ptr<timernode>>[256];
using TVR_ = std::list<std::shared_ptr<timernode>>[64];
public:
TimerWheel() : currenttime(0){}
//提供给外界的接口
void TW_Add(int fd, int ticks = 2);//得到一个连接时加入 设置一个滴答时间为2
void TW_Tick(); //放在信号接收函数中
void TW_Update(int fd);//一个链接发送消息时更新
private:
std::unordered_map<int, itr> mp;
void _TW_Add_(int fd, int ex);
uint32_t currenttime;
TVN_ tvroot;
TVR_ tv[4];
};
void TimerWheel::TW_Add(int fd, int ticks){//传入fd 与 定时时间
if(ticks < 0) throw std::invalid_argument("'Timer_Wheel::TW_Add' : error parameter.");
int ex = currenttime + ticks;
_TW_Add_(fd, ex);
}
void TimerWheel::_TW_Add_(int fd, int ex){
if(mp.find(fd) != mp.end()) throw std::invalid_argument("'TimerWheel::_TW_Add_ error parameter.'");
uint32_t ex_ = static_cast<uint32_t>(ex);
uint32_t idx = ex_ - currenttime;
auto ptr = std::make_shared<timernode>(FIRST_INDEX(ex_),fd, ex_);
if(idx < TVR_SIZE){
ptr->Set_Wheel(0);
tvroot[FIRST_INDEX(ex_)].emplace_back(std::move(ptr));
std::cout << fd << " : " << tvroot[FIRST_INDEX(ex_)].size() << std::endl;
mp[fd] = --(tvroot[FIRST_INDEX(ex_)].end());
} else {
uint64_t sz;
for(int i = 0; i < 4; ++i){
sz = (1ULL << (TVR_BITS + (i+1) * TVN_BITS));
if(idx < sz){
idx = NTH_INDEX(ex, i);
tv[i][idx].emplace_back(std::move(ptr));
mp[fd] = --(tv[i][idx].end());;
ptr->Set_Wheel(i + 1);
break;
}
}
}
}
void TimerWheel::TW_Tick(){
++currenttime;
uint32_t currtick = currenttime;
int index = (currtick & TVR_MASK);
if(index == 0){
int i = 0;
int idx = 0;
do{
idx = NTH_INDEX(currenttime, i);
for(auto x : tv[i][idx]){
TW_Add(x->Return_fd(), static_cast<int>(currenttime - x->Return_expire()));
}
tv[i][idx].erase(tv[i][idx].begin(), tv[i][idx].end());
}while (idx == 0 && ++i < 4);
}
for(auto x : tvroot[index]){
int fd = x->Return_fd();
std::cout << fd << " have killed.\n";
//这个时候可以任意操作 不过在这里应该是close
}
tvroot[index].erase(tvroot[index].begin(),tvroot[index].end());
}
void TimerWheel::TW_Update(int fd){ //当一个连接发送数据时 更新这个时间轮
TW_Add(fd);
int solt = (*mp[fd])->Return_solt();
int wheel = (*mp[fd])->Return_wheel();
if(!solt){
tvroot[wheel].erase(mp[fd]);
}else{
tv[solt - 1][wheel].erase(mp[fd]);
}
}
#undef TVR_BITS
#undef TVR_SIZE
#undef TVN_BITS
#undef TVN_SIZE
#undef TVR_MASK
#undef TVN_MASK
#undef FIRST_INDEX
#undef NTH_INDEX
#endif
以上是一个封装好的利用五个轮的时间轮来处理非活动连接的demo 其中的精髓其实就在于在TW_Add() 和 TW_Tick()中对于时间轮的操作 看懂关于这个知识点就ok了
原文链接: https://www.cnblogs.com/lizhaolong/p/16437374.html
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍;
也有高质量的技术群,里面有嵌入式、搜广推等BAT大佬

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/395787
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!