
8.5 Slim读/写锁(SRWLock)——轻量级的读写锁
(1)SRWLock锁的目的
①允许读者线程同一时刻访问共享资源(因为不存在破坏数据的风险)
②写者线程应独占资源的访问权,任何其他线程(含写入的线程)要等这个写者线程访问完才能获得资源。
(2)SRWlock锁的使用方法
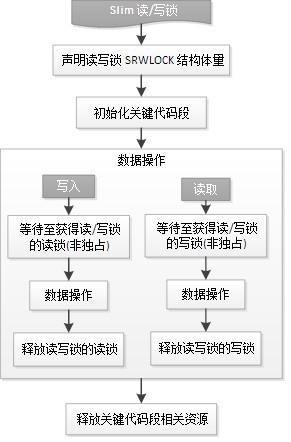

①初始化SRWLOCK结构体 InitializeSRWLock(PSRWLOCK pSRWLock);
②写者线程调用AcquireSRWLockExclusive(pSRWLock);以排它方式访问
读者线程调用AcquireSRWLockShared以共享方式访问
③访问完毕后,写者线程调用ReleaseSRWLockExclusive解锁。读者线程要调用ReleaseSRWLockShared解锁
④注意SRWLock不需要删除和销毁,所以不用Delete之类的,系统会自动清理。
(3)SRWLock锁的共享规则:
①若当前锁的状态是“写”(即某个线程已经获得排它锁),这时其他线程,不管是申请读或写锁的线程,都会被阻塞在AcquireSRWLock*函数中。读锁或写锁等待计数加1。
②若当前锁的状态是“读”(即某个(些)线程已经获得了共享锁)。
A、如果新的线程申请写锁,则此时它将被挂起,锁的写等待计数加1。直至当前正在读锁的线程全部结束,然后系统会唤醒正在等待写的线程,即申请排他锁要在没有任何其他锁的时候才能返回。
B、如果新的线程申请读锁,若此时没有写线程正在等待,则允许读锁进入而不会被阻塞。如果有写锁正在等待,则写锁优先得到锁,新线程进入等待,读锁计数加1(这样做的目的是让写锁有机会进入)。
(4)SRWLock与临界区的不同
①不存在TryEnter(Shared/Exclusive)SRWLock之类的函数;如果锁己经被占用,那么调用AcquireSRWLock(Shared/Exclusive)会阻塞调用线程。(如排它写入时,锁会被独占)(课本这说法已不适用了,在Win7以后系统提供了TryAcquireSRWLock(Exclusive/Shared)等函数,可以实现这需求了)
②不能递归获得SRWLock,即一个线程不能为了多次写入资源而多次锁定资源,再多次调用ReleaseSRWLock*来释放锁。
【SRWLock程序】

#include <windows.h> #include <tchar.h> #include <locale.h> #include <time.h> ////////////////////////////////////////////////////////////////////////// const int g_iThreadCnt = 20; int g_iGlobalValue = 0; ////////////////////////////////////////////////////////////////////////// SRWLOCK g_sl = { 0 }; ////////////////////////////////////////////////////////////////////////// DWORD WINAPI ReadThread(PVOID pParam); DWORD WINAPI WriteThread(PVOID pParam); ////////////////////////////////////////////////////////////////////////// int _tmain() { _tsetlocale(LC_ALL, _T("chs")); srand((unsigned int)time(NULL)); //读写锁只需初始化,不需要手动释放,系统会自行处理 InitializeSRWLock(&g_sl); HANDLE aThread[g_iThreadCnt]; DWORD dwThreadId = 0; SYSTEM_INFO si = { 0 }; GetSystemInfo(&si); for (int i = 0; i < g_iThreadCnt;i++){ if (0 == rand()%2) aThread[i] = CreateThread(NULL, 0, (LPTHREAD_START_ROUTINE)WriteThread, NULL, CREATE_SUSPENDED,&dwThreadId); else aThread[i] = CreateThread(NULL, 0, (LPTHREAD_START_ROUTINE)ReadThread, NULL, CREATE_SUSPENDED, &dwThreadId); SetThreadAffinityMask(aThread[i],1<<(i % si.dwNumberOfProcessors)); ResumeThread(aThread[i]); } //等待所有线程结束 WaitForMultipleObjects(g_iThreadCnt,aThread,TRUE,INFINITE); for (int i = 0; i < g_iThreadCnt;i++){ CloseHandle(aThread[i]); } _tsystem(_T("PAUSE")); return 0; } //////////////////////////////////////////////////////////////////////////// ////不加保护的读写 //DWORD WINAPI ReadThread(PVOID pParam) //{ // _tprintf(_T("Timestamp[%u]:Thread[ID:0x%x]读取全局变量值为%dn"), // GetTickCount(),GetCurrentThreadId(),g_iGlobalValue); // return 0; //} // //////////////////////////////////////////////////////////////////////////// //DWORD WINAPI WriteThread(PVOID pParam) //{ // // for (int i = 0; i <= 4321; i++){ // g_iGlobalValue = i; // //模拟一个时间较长的处理过程 // for (int j = 0; j < 1000; j++); // } // // //我们的要求是写入的最后数值应该为4321,全局变量未被保护 // //其中线程可能读取0-4321的中间值,这不是我们想要的结果! // _tprintf(_T("Timestamp[%u]:Thread[ID:0x%x]写入数据值为%dn"), // GetTickCount(), GetCurrentThreadId(), g_iGlobalValue); // return 0; //} ////////////////////////////////////////////////////////////////////////// DWORD WINAPI ReadThread(PVOID pParam) { //以共享的访问读 __try{ AcquireSRWLockShared(&g_sl); //读出来的全局变量要么是0,要么是4321。不可能有其他值 //当读线程第1个被调度时,会读到0.但一旦写线程被调度,以后所有的 //读取的值都会是4321 _tprintf(_T("Timestamp[%u]:Thread[ID:0x%X]读取全局变量值为%dn"), GetTickCount(), GetCurrentThreadId(), g_iGlobalValue); } __finally{ ReleaseSRWLockShared(&g_sl); } return 0; } ////////////////////////////////////////////////////////////////////////// DWORD WINAPI WriteThread(PVOID pParam) { //写时以排它的方式 __try{ AcquireSRWLockExclusive(&g_sl); for (int i = 0; i <= 4321; i++){ g_iGlobalValue = i; SwitchToThread(); //故意切换到其他线程,很明显 //在这个循环的期间,因排它方式 //所以其它访问锁的线程会被挂起 //从而无法读或写。 } //我们的要求是写入的最后数值应该为4321,全局变量未被保护 //其中线程可能读取0-4321的中间值,这不是我们想要的结果! _tprintf(_T("Timestamp[%u]:Thread[ID:0x%X]写入数据值为%dn"), GetTickCount(), GetCurrentThreadId(), g_iGlobalValue); } __finally{ ReleaseSRWLockExclusive(&g_sl); } return 0; }
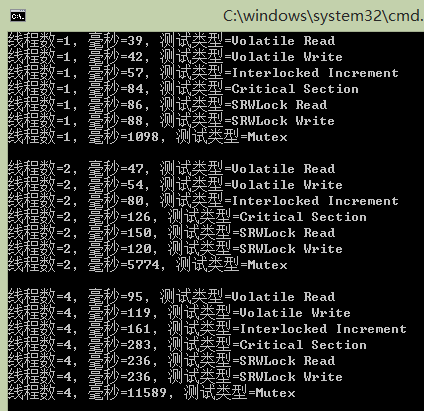
(5)SRWLock锁与其他锁的比较——实验:对同一个全局变量加不同类型锁,同时让每个线程进行1000000次读写性能的比较(时间单位为ms)
|
线程数 |
Volatile 读取 |
Volatile 写入 |
InterLocked 递增 |
临界区 |
SRWLock 共享 |
SRWLock 排它 |
互斥量 Mutex |
|
1 |
39 |
42 |
57 |
84 |
86 |
88 |
1098 |
|
2 |
42 |
54 |
80 |
126 |
150 |
120 |
5774 |
|
4 |
95 |
119 |
161 |
283 |
236 |
236 |
11589 |
①InterLockedIncrement比Volatile读写慢是因为CPU必须锁定内存,但InterLocked函数只能同步一些简单的整型变量。
②临界区与SRWLock锁效率差不多,但建议用SRWLock代替临界区,因为该锁允许多个线程同时读取,对那些只需要读取共享资源线程来说,这提高了吞吐量
③内核对象的性能最差,这是因为等待、释放互斥量需要在用户模式与内核模式之间切换。
④如果考虑性能,首先应该尝试不要共享数据,然后依次是Volatile读写、InterLock函数、SRWLock锁、临界区。当这些条件都不满足时,再使用内核对象。
【UserSyncCompare程序】比较不同类型锁的性能
/*********************************************************************** Module: UserSyncCompare.cpp Notices: Copyright(c) 2008 Jeffrey Richter & Christophe Nasarre ***********************************************************************/ #include "../../CommonFiles/CmnHdr.h" #include <windows.h> #include <stdio.h> #include <tchar.h> #include <locale.h> ////////////////////////////////////////////////////////////////////////// // 晶振计时类,基于主板晶振频率的时间戳计数器的时间类(见第7章) class CStopWatch { public: CStopWatch() { QueryPerformanceFrequency(&m_liPerfFreq); Start(); } void Start() { QueryPerformanceCounter(&m_liPerfStart); } //返回计算自调用Start()函数以来的毫秒数 __int64 Now() const { LARGE_INTEGER liPerfNow; QueryPerformanceCounter(&liPerfNow); return(((liPerfNow.QuadPart - m_liPerfStart.QuadPart) * 1000) / m_liPerfFreq.QuadPart); } private: LARGE_INTEGER m_liPerfFreq; // Counts per second LARGE_INTEGER m_liPerfStart; // Starting count }; ////////////////////////////////////////////////////////////////////////// DWORD g_nIterations = 1000000; //叠代次数 typedef void(CALLBACK* OPERATIONFUNC)(); DWORD WINAPI ThreadInterationFunction(PVOID operationFunc){ OPERATIONFUNC op = (OPERATIONFUNC)operationFunc; for (DWORD iteration = 0; iteration < g_nIterations;iteration++){ op(); } return 0; } ////////////////////////////////////////////////////////////////////////// //MeasureConcurrentOperation函数 //功能:测试一组并行线程的性能 //参数:szOperationName——操作的名称 // nThreads——测试线程的数量 // ofnOperationFunc——具体以哪种方式读、写操作的函数 void MeasureConcurrentOperation(TCHAR* szOperationName,DWORD nThreads, OPERATIONFUNC opfOperationFunc) { HANDLE* phThreads = new HANDLE[nThreads]; //将当前线程的优先级提到“高” SetThreadPriority(GetCurrentThread(), THREAD_PRIORITY_HIGHEST); for (DWORD i = 0; i < nThreads;i++){ phThreads[i] = CreateThread(NULL, 0, ThreadInterationFunction, //线程函数 opfOperationFunc,//线程函数的参数(是个函数指针) 0, //立即运行 NULL); } SetThreadPriority(GetCurrentThread(), THREAD_PRIORITY_NORMAL); CStopWatch watch; //等待所有线程结束 WaitForMultipleObjects(nThreads, phThreads, TRUE, INFINITE); __int64 elapsedTime = watch.Now(); _tprintf(_T("线程数=%u,毫秒=%u,测试类型=%sn"), nThreads,(DWORD)elapsedTime,szOperationName); //别忘了关闭所有的线程句柄,并删除线程数组 for (DWORD i = 0; i < nThreads; i++){ CloseHandle(phThreads[i]); } delete phThreads; } ////////////////////////////////////////////////////////////////////////// //测试列表: //1、不加同步锁,对整型volatile变量直接读取 //2、使用InterlockedIncrement对整型变量进行写操作 //3、使用临界区对整型volatile变量进行读取 //4、使用SRWLock锁对整型volatile变量进行读写操作 //5、使用互斥对象Mutex对整型volatile变量进行读取操作 volatile LONG gv_value = 0; //1、直接读写volatile型的整型变量 //'lValue':是个局部变量,己初始化,但未被引用,编译器 //会出现警告,可禁用该警告 #pragma warning(disable:4189) void WINAPI VolatileReadCallBack() { LONG lValue = gv_value; } #pragma warning(default:4189) void WINAPI VolatileWriteCallBack() { gv_value = 0; } //2、使用InterlockedIncrement对整型变量进行写操作 void WINAPI InterlockedIncrementCallBack() { InterlockedIncrement(&gv_value); } //3、使用临界区对整型volatile变量进行读取 CRITICAL_SECTION g_cs; void WINAPI CriticalSectionCallBack() { EnterCriticalSection(&g_cs); gv_value = 0; LeaveCriticalSection(&g_cs); } //4、使用SRWLock锁对整型volatile变量进行读写操作 SRWLOCK g_srwLock; void WINAPI SRWLockReadCallBack() { AcquireSRWLockShared(&g_srwLock); gv_value = 0; ReleaseSRWLockShared(&g_srwLock); } void WINAPI SRWLockWriteCallBack() { AcquireSRWLockExclusive(&g_srwLock); gv_value = 0; ReleaseSRWLockExclusive(&g_srwLock); } //5、使用互斥对象Mutex对整型volatile变量进行读取操作 HANDLE g_hMutex; void WINAPI MutexCallBack() { WaitForSingleObject(g_hMutex, INFINITE); gv_value = 0; ReleaseMutex(g_hMutex); } ////////////////////////////////////////////////////////////////////////// int _tmain() { _tsetlocale(LC_ALL, _T("chs")); //分别测试当线程总数为1、2、4时各种锁切换所花费的时间 for (int nThreads = 1; nThreads <= 4;nThreads *= 2){ //1、直接读写 MeasureConcurrentOperation(_T("Volatile Read"), nThreads, VolatileReadCallBack); MeasureConcurrentOperation(_T("Volatile Write"), nThreads, VolatileWriteCallBack); //2、InterlockedIncrement MeasureConcurrentOperation(_T("Interlocked Increment"), nThreads, InterlockedIncrementCallBack); //3、临界区: InitializeCriticalSection(&g_cs);//初始化临界区 MeasureConcurrentOperation(_T("Critical Section"), nThreads, CriticalSectionCallBack); DeleteCriticalSection(&g_cs); //4、SRWLock锁: InitializeSRWLock(&g_srwLock);//初始化SRWLock锁,注意不需要释放,系统会自行回收 MeasureConcurrentOperation(_T("SRWLock Read"), nThreads, SRWLockReadCallBack); MeasureConcurrentOperation(_T("SRWLock Write"), nThreads, SRWLockWriteCallBack); //5、互斥对象: g_hMutex = CreateMutex(NULL, false, NULL);//准备互斥对象 MeasureConcurrentOperation(_T("Mutex"), nThreads, MutexCallBack); CloseHandle(g_hMutex); _tprintf(_T("n")); } return 0; }
原文链接: https://www.cnblogs.com/5iedu/p/4727734.html
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍;
也有高质量的技术群,里面有嵌入式、搜广推等BAT大佬

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/394666
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!