
另一篇好文地址 c++性能优化--tcmalloc https://blog.51cto.com/9291927/2568961?source=dra
gperf官方介绍https://gperftools.github.io/gperftools/tcmalloc.html
前言
TCMalloc 是 Google 开发的内存分配器,在不少项目中都有使用,例如在 Golang 中就使用了类似的算法进行内存分配。它具有现代化内存分配器的基本特征:对抗内存碎片、在多核处理器能够 scale。据称,它的内存分配速度是 glibc2.3 中实现的 malloc的数倍。
之所以学习 TCMalloc,是因为在学习 Golang 内存管理的时候,发现 Golang 竟然就用了鼎鼎大名的 TCMalloc,而在此之前虽然也对内存管理有过一些浅薄的了解,但一直没有机会深入。因此借此机会再巩固一下内存管理的知识。
在学习 TCMalloc 的过程中看过不少文章,但程序员写出来的文章常常以代码分析居多,可读性不是那么高。我之前也喜欢写一些源码分析之类的文章,但渐渐发觉从源码出发虽然能够探究实现的细节,但这些东西更适合作为自己的学习笔记,如果要讲给别人,还是用一些更加可读的方式比较好。因此,这篇文章主要以看图说话为主,是为图解。
如何分配定长记录?
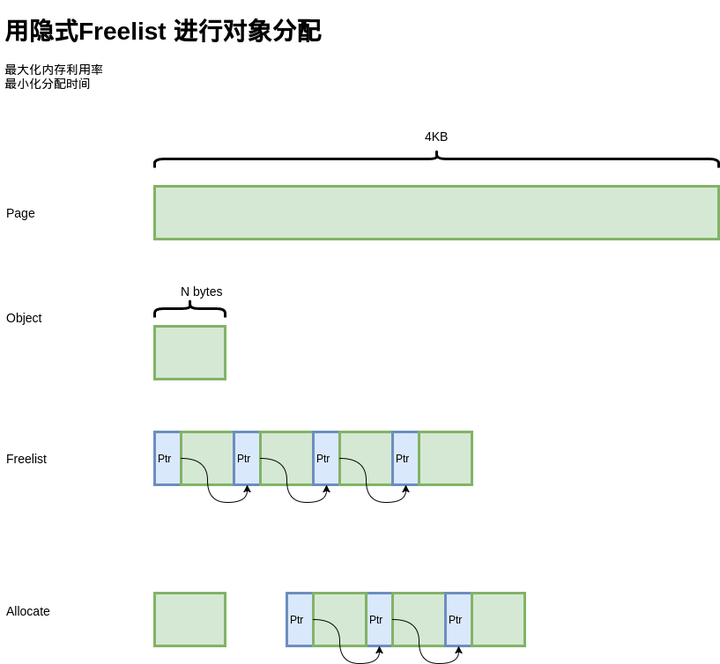
首先是基本问题,如何分配定长记录?例如,我们有一个 Page 的内存,大小为 4KB,现在要以 N 字节为单位进行分配。为了简化问题,就以 16 字节为单位进行分配。
解法有很多,比如,bitmap。4KB / 16 / 8 = 32, 用 32 字节做 bitmap即可,实现也相当简单。
出于最大化内存利用率的目的,我们使用另一种经典的方式,freelist。将 4KB 的内存划分为 16 字节的单元,每个单元的前8个字节作为节点指针,指向下一个单元。初始化的时候把所有指针指向下一个单元;分配时,从链表头分配一个对象出去;释放时,插入到链表。
由于链表指针直接分配在待分配内存中,因此不需要额外的内存开销,而且分配速度也是相当快。
如何分配变长记录?
定长记录的问题很简单,但如何分配变长记录的。对此,我们把问题化归成对多种定长记录的分配问题。
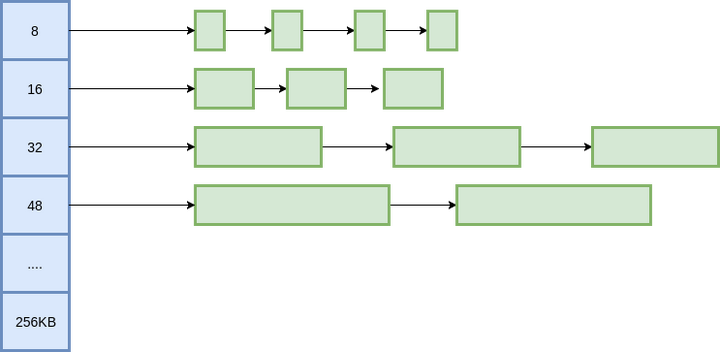
我们把所有的变长记录进行“取整”,例如分配7字节,就分配8字节,31字节分配32字节,得到多种规格的定长记录。这里带来了内部内存碎片的问题,即分配出去的空间不会被完全利用,有一定浪费。为了减少内部碎片,分配规则按照 8, 16, 32, 48, 64, 80这样子来。注意到,这里并不是简单地使用2的幂级数,因为按照2的幂级数,内存碎片会相当严重,分配65字节,实际会分配128字节,接近50%的内存碎片。而按照这里的分配规格,只会分配80字节,一定程度上减轻了问题。
大的对象如何分配?
上面讲的是基于 Page,分配小于Page的对象,但是如果分配的对象大于一个 Page,我们就需要用多个 Page 来分配了:
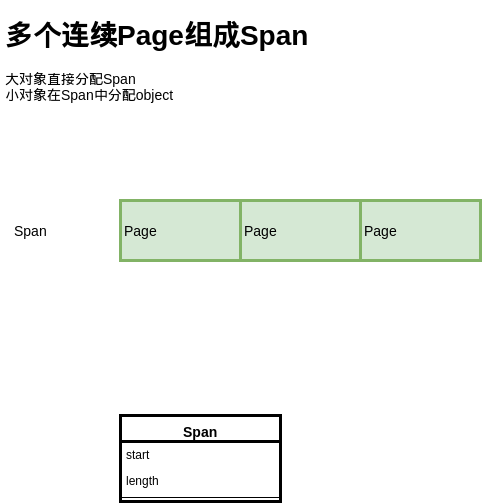
这里提出了 Span 的概念,也就是多个连续的 Page 会组成一个 Span,在 Span 中记录起始 Page 的编号,以及 Page 数量。
分配对象时,大的对象直接分配 Span,小的对象从 Span 中分配。
Span如何分配?
对于 Span的管理,我们可以如法炮制:
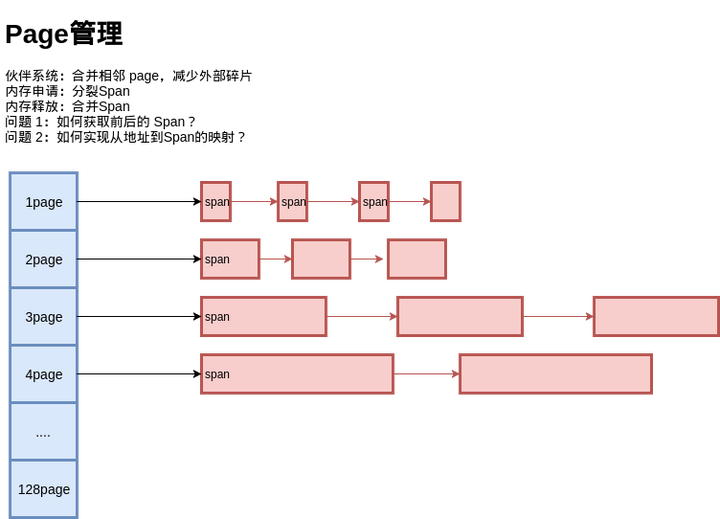
还是用多种定长 Page 来实现变长 Page 的分配,初始时只有 128 Page 的 Span,如果要分配 1 个 Page 的 Span,就把这个 Span 分裂成两个,1 + 127,把127再记录下来。对于 Span 的回收,需要考虑Span的合并问题,否则在分配回收多次之后,就只剩下很小的 Span 了,也就是带来了外部碎片 问题。
为此,释放 Span 时,需要将前后的空闲 Span 进行合并,当然,前提是它们的 Page 要连续。
问题来了,如何知道前后的 Span 在哪里?
从Page到Span
由于 Span 中记录了起始 Page,也就是知道了从 Span 到 Page 的映射,那么我们只要知道从 Page 到 Span 的映射,就可以知道前后的Span 是什么了。
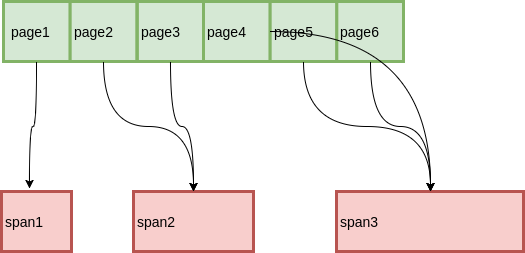
最简单的一种方式,用一个数组记录每个Page所属的 Span,而数组索引就是 Page ID。这种方式虽然简洁明了,但是在 Page 比较少的时候会有很大的空间浪费。
为此,我们可以使用 RadixTree 这种数据结构,用较少的空间开销,和不错的速度来完成这件事:
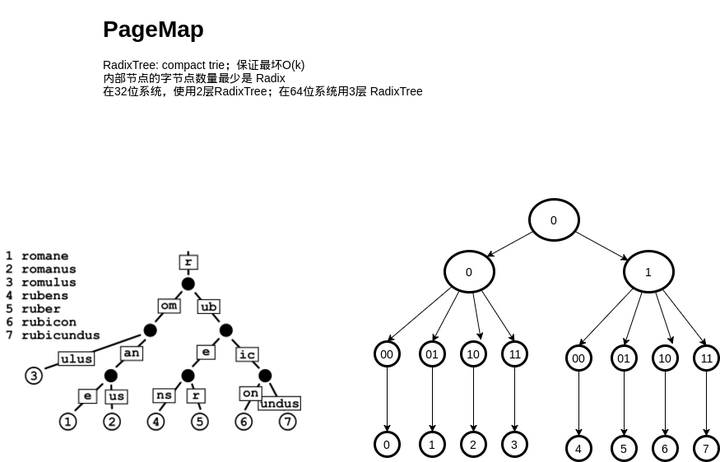
乍一看可能有点懵,这个跟 RadixTree 能扯上关系吗?可以把 RadixTree 理解成压缩过的前缀树(trie),所谓压缩,就是在一条路径上的节点都只有一个子节点,就把这条路径合并到父节点去,因此内部节点最少会有 Radix 个字节点。具体的分析可以参考一下 wikipedia 。
实现时,可以通过一定的空间换来时间,也就是减少层数,比如说3层。每层都是一个数组,用一个地址的前 1/3 的bit 索引数组,剩下的 bit 对下一层进行寻址。实际的寻址也可以非常快。
PageHeap
到这里,我们已经实现了 PageHeap,对所有 Page进行管理:
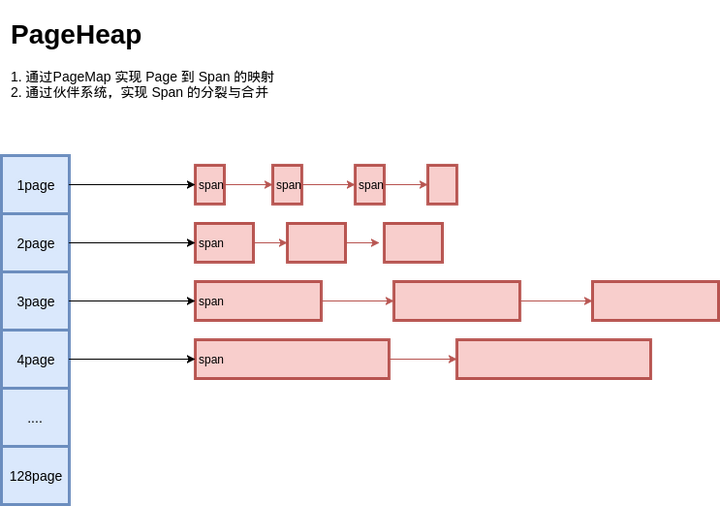
全局对象分配
既然有了基于 Page 的对象分配,和Page本身的管理,我们把它们串起来就可以得到一个简单的内存分配器了:
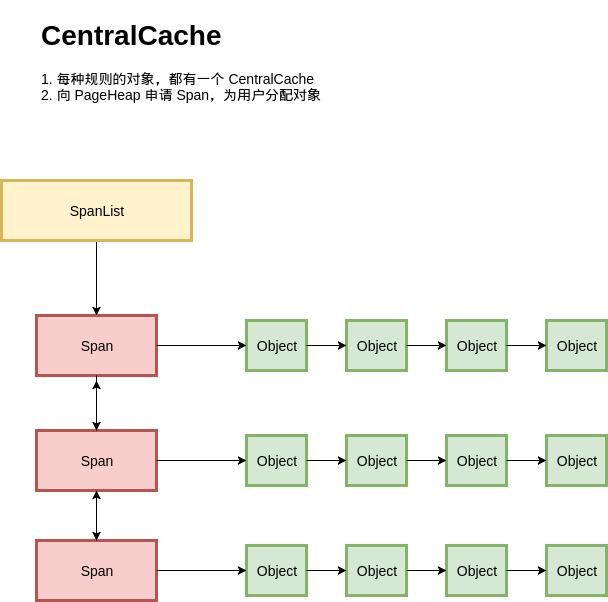
按照我们之前设计的,每种规格的对象,都从不同的 Span 进行分配;每种规则的对象都有一个独立的内存分配单元:CentralCache。在一个CentralCache 内存,我们用链表把所有 Span 组织起来,每次需要分配时就找一个 Span 从中分配一个 Object;当没有空闲的 Span 时,就从 PageHeap 申请 Span。
看起来基本满足功能,但是这里有一个严重的问题,在多线程的场景下,所有线程都从CentralCache 分配的话,竞争可能相当激烈。
ThreadCache
到这里 ThreadCache 便呼之欲出了:
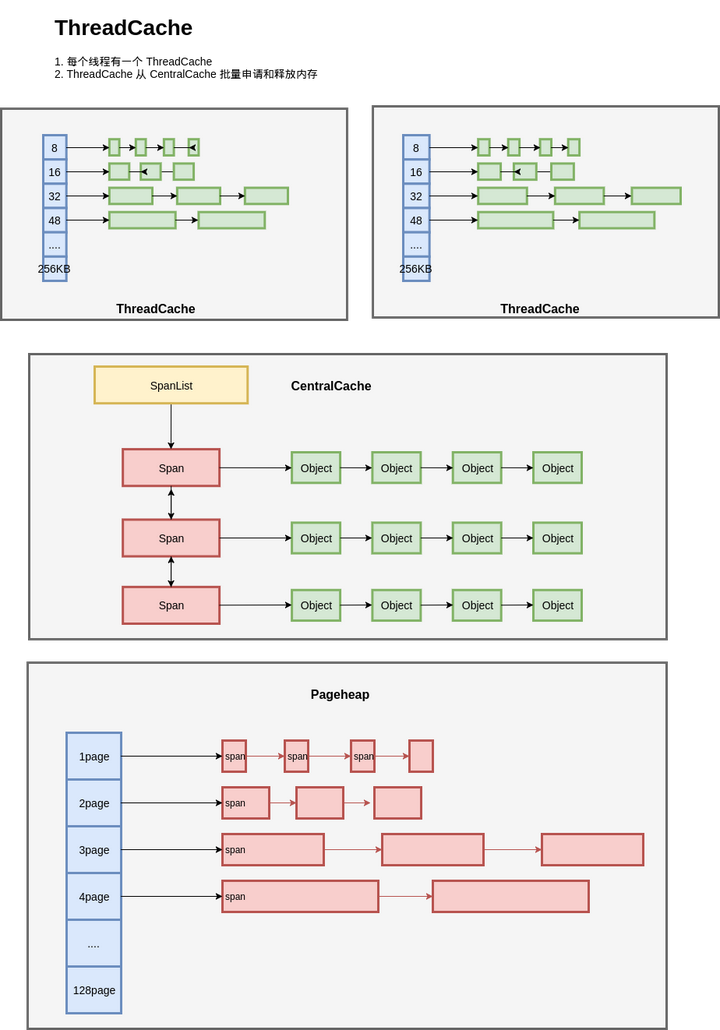
每个线程都一个线程局部的 ThreadCache,按照不同的规格,维护了对象的链表;如果ThreadCache 的对象不够了,就从 CentralCache 进行批量分配;如果 CentralCache 依然没有,就从PageHeap申请Span;如果 PageHeap没有合适的 Page,就只能从操作系统申请了。
在释放内存的时候,ThreadCache依然遵循批量释放的策略,对象积累到一定程度就释放给 CentralCache;CentralCache发现一个 Span的内存完全释放了,就可以把这个 Span 归还给 PageHeap;PageHeap发现一批连续的Page都释放了,就可以归还给操作系统。
至此,TCMalloc 的大体结构便呈现在我们眼前了。
原文https://zhuanlan.zhihu.com/p/29216091
另附文
tcmalloc浅析
总体结构
在tcmalloc内存管理的体系之中,一共有三个层次:ThreadCache、CentralCache、PageHeap,如上图所示。
分配内存和释放内存的时候都是按从前到后的顺序,在各个层次中去进行尝试。基本思想是:前面的层次分配内存失败,则从下一层分配一批补充上来;前面的层次释放了过多的内存,则回收一批到下一层次。
这几个层次从前到后,主要有这么几方面的变化:
- 线程私有性:ThreadCache,顾名思义,是每个线程一份的。理想情况下,每个线程的内存需求都在自己的ThreadCache里面完成,线程之间不需要竞争,非常高效。而CentralCache和PageHeap则是全局的;
- 内存分配粒度:在tcmalloc里面,有两种粒度的内存,object和span。span是连续page的内存,而object则是由span切成的小块。object的尺寸被预设了一些规格(class),比如16字节、32字节、等等,同一个span切出来的object都是相同的规格。object不大于256K,超大的内存将直接分配span来使用。ThreadCache和CentralCache都是管理object,而PageHeap管理的是span。
ThreadCache
比较简单,最主要的逻辑是维护一组FreeList,针对每一种class的object;
CentralCache
里面有多个CentralFreeList,针对每一种class的object。
CentralFreeList并不像ThreadCache那样直接维护object的链表,而是维护span的链表,每个span下面再挂一个由这个span切分出来的object的链。这样做便于在span内的object是否都已经free的情况下,将span整体回收给PageHeap(span.refcount_记录了被分配出去的object个数)。但是这样一来,每个回收回来的object都需要寻找自己所属的span,然后才能挂进freelist,过程会比较耗时。
所以CentralFreeList里面还搞了一个cache(tc_slots_),回收回来的一批object先往cache里面塞,塞不下了再回收进span的objects链。分配object给ThreadCache时也是先尝试在cache里面拿,没了再去span里面分配。
多少个object算做是一批?这都是预定义好的(称作batch_size,比如32个),不同的class可能有不同的值。ThreadCache向CentralCache分配和回收object时,都尽量以batch_size为一个批次。而为了cache的简单高效,如果批次个数不等于batch_size,则会绕过cache。
另外,CentralFreeList里的span链表其实是有两个:nonempty_和empty_,根据span的objects链是否有空闲,放入对应链表。这样就避免了在分配时去判断span是否为空,只需要在由空变非空、或者由非空变空时移动一下span。
PageHeap
维护了两个很重要的东西:page到span的映射关系,和空闲span的伙伴系统。
当应用free()一个地址的时候,怎么知道该把它对应的object放回哪里去呢?tcmalloc里面并没有针对object的控制结构,要解决这个问题,page到span的映射关系至关重要。地址值经过地址对齐,很容易知道它属于哪一个page。再通过page到span的映射关系就能知道object应该放到哪里。span.sizeclass记录了span被切分成的object属于哪一个class,那么属于这个span的object在free时就应该放到ThreadCache对应class的FreeList上面去;如果object需要放回CentralCache,直接把它挂到对应span的objects链表上即可。
page到span的映射关系通过radix tree来实现,逻辑上可以把它理解为一个大数组,以page的值作为偏移,就能访问到page所对应的节点。这个节点上面其实就是一个指针,指向这个page所对应的span(注意,可能有多个page指向同一个span,因为span的尺寸可能不止一个page)。
为减少查询radix tree的开销,PageHeap还维护了一个最近最常使用的若干个page到class(span.sizeclass)的对应关系cache。为了保持cache的效率,cache只提供64K个固定坑位,旧的对应关系会被新来的对应关系替换掉。
空闲span的伙伴系统为上层提供span的分配与回收。当需要的span没有空闲时,可以把更大尺寸的span拆小(如果大的span都没有了,则需要重新找kernel分配);当span回收时,又需要判断相邻的span是否空闲,以便将它们组合。判断相邻span还是要用到radix tree,radix tree就像一个大数组,很容易取到当前span前后相邻的span。
span的尺寸有从1个page到255个page的所有规格,所以span总是可以按任意尺寸进行拆分和组合(当然是page粒度的)。大于255个page的span单独归为一类,不作细分。
伙伴系统的freelist其实是有两个链,normal和returned,以区别活跃跟不活跃的内存。PageHeap并不会将内存释放给kernel,因为它们之间的交互都是针对一批连续page的,要想回收到整批的page,可能性很小。在PageHeap里面,多余的内存会放到returned里面去,跟normal做一下隔离。这样一来,normal的内存总是优先被使用,kernel倾向于一直保留它们。而returned的内存则不常被使用,kernel在内存不够的时候会优先将它们swap掉。
其实不用returned也能完成这样的事情,因为normal是个链表,每次分配回收总是作用在链表头上,那么链表内的span本身就按从热到冷的顺序排序了。链表尾部的span如果长期不被使用,不管是否移动到returned链,kernel都会倾向于将它们swap掉。不过,span进入returned时,tcmalloc还附加了一个操作,madvise(MADV_DONTNEED),试图告诉kernel这个内存已经不用了(kernel具体会怎么做,那就是另外一回事了)。
所以,在伙伴系统中分配span时,会有三个过程:优先在normal链中分配、尝试未果则在returned链中分配、还搞不定就向kernel去申请新的内存。
在PageHeap里面,还有一个PageHeapAllocator,专门用于分配各种控制结构的内存,比如span、ThreadCache、等。可见,在tcmalloc里面控制结构与object是分离的。而object自身并不需要额外的控制结构,当它被分配时,它的所有内存空间都服务于使用者;而当它空闲时,它的第一个8Byte空间被当作链表指针,链在各种freelist里面。
分配回收过程
再通过malloc和free两个过程把上述逻辑串起来看一看:
alloc
- 根据分配size,判断是小块内存还是大块内存(256K为界);
- 小块内存:
- 通过size得到对应的class;
- 先尝试在ThreadCache.list_[class]的FreeList里面分配,分配成功则直接返回;
- 尝试在CentralCache里面分配batch_size个object,其中一个用于返回,其他的都加进ThreadCache.list_[class];
- 拿到class对应的CentralFreeList;
- 尝试在CentralFreeList.tc_slots_[]里面分配(CentralFreeList.used_slots_是空闲slot游标);
- 尝试在CentralFreeList.nonempty_里面分配,尽量分配batch_size个object。但最后只要分配了多于一个object,即可返回;
- 如果CentralFreeList.nonempty_为空,则要向PageHeap去申请一个span。对应的class申请的span应该包含多少个连续page,这个也是预设好的。拿到span之后将其拆分成N个object,然后返回前面所需要的object;
- PageHeap先从伙伴系统对应npages的span链表里面查找空闲的span(优先查normal链、然后returned链),有则直接返回;
- 在更大npages的span里面查找空闲的span(优先查normal链、然后returned链),有则将其拆小,并返回所需要的span;
- 向kernel申请若干个page的内存(可能大于npage),返回所需要的span,其他的span放回伙伴系统;
- 大块内存:
- 直接向PageHeap去申请一个刚好大于等于请求size的span。申请过程与小块内存走到这一步时的过程一致;
free
- 通过释放的ptr,在PageHeap维护的映射关系中,找到对应span的class(先尝试在cache里面找,没有再查radix tree,然后插入cache。cache里面自动淘汰老的项)。class为0代表ptr指向的是大块内存;
- 小块内存:
- 将ptr指向的内存释放到ThreadCache.list_[class]里面;
- 如果ThreadCache.list_[class]长度超过阈值(FreeList.length_>=FreeList.max_length_),或者ThreadCache的容量超过阈值(ThreadCache.size_>=ThreadCache.max_size_),则触发回收过程。两种情况分别针对class对应的FreeList,和ThreadCache下面的所有FreeList进行回收(具体的策略后续再讨论);
- object被回收到CentralCache里面class对应的CentralFreeList上。先尝试batch_size个object的整块回收,CentralFreeList会试图将其释放到自己的cache里面去(tc_slots_);
- 如果cache装满,或者凑不满batch_size个整数的object,则单个回收,回收进其对应的span.objects。这个回收过程不必拿着object在CentralFreeList的span链表中逐个去寻找自己对应的span,而是通过PageHeap中的对应关系直接找到span;
- 如果span下面的object都已经回收了(refcount_减为0),则进一步将其释放回PageHeap;
- 在radix tree中找到span之前和这后的span,如果它们空闲且也在normal链上,则进行合并;
- PageHeap将多余的span回收到其对应的returned链上,然后继续考虑span之间的合并(要求span都在returned链上)(具体策略后续再讨论);
- 大块内存:
- ptr对应的直接就是一个span,直接将其释放回PageHeap即可;
回收策略
tcmalloc的主要数据结构基本上就是这些了。上面讨论的时候,有一个细节一直没深入:每一个层次在空闲量达到一定阈值的时候,会向下做一次释放。那么这个阈值该怎么定呢?
CentralCache => PageHeap
span从CentralCache回收到PageHeap的过程比较简单,只要一个span里面的object都空闲了,就将它回收到PageHeap;
normal => returned
在PageHeap中,span从normal链表回收到returned链表的过程则略复杂一些:
考虑到这个过程是很偏避的一个逻辑,span是否移到returned链表对整体性能而言差别并不会太大,所以尽量lazy。基本思路是,每当PageHeap回收到N个page的span时(这个过程中可能伴随着相当数目的span分配),触发一次normal到returned的回收,只回收一个span。
这个N值初始化为1G内存的page数,每次回收span到returned链之后,可能还会增加N值,但是最大不超过4G。
触发回收的过程也比较简单,每次进来轮询伙伴系统中的一个normal链表,将链尾的span回收即可。
这里面没有判断normal链是否应该被回收,如果回收了不该回收的span,后续的分配过程会把span从returned链里面捞回来。否则span将长期呆在returned链里面。
ThreadCache => CentralCache
ThreadCache是tcmalloc的核心,它里面的FreeList长度控制还是比较复杂的。
前面提到过,FreeList长度超过限额和ThreadCache容量超过限额,这两种情况下会触发object回收。考虑到应用程序的多样性,这两个限额不能是定死的,必需得自适应:有些线程对内存的需求可能远多于其他一些线程、有些线程可能总是在分配内存而另一些线程则总是释放内存(生产者消费者)、等等。
先来看ThreadCache的容量限额,其思想是:为每一个ThreadCache初始化一个比较小的限额,然后每当ThreadCache由于cache超限而触发object到CentralCache的回收时,就增大该ThreadCache的限额。有限额增大,就应该有限额回收。tcmalloc预设了一个所有ThreadCache的总容量,当ThreadCache需要增大容量时,如果总容量尚有余额,则使用这些余额。否则需要增大的容量就从其他线程的ThreadCache里面去收刮(具体从收刮哪个线程的容量,简单采用了轮询的方式)。这样一来,只需要在ThreadCache内存回收时做一些简单的处理,就能实现ThreadCache的容量的自适应:内存需求大的线程总是收刮别人的容量,而内存需求低的线程则总是被收刮。当然,收刮与被收刮并不是无节制的,会有一个最大值最小值的限制,比如128字节~4M。
到达ThreadCache的容量限额时,会对它下面的每一个FreeList进行回收,回收的数目是该Freelist.lowator_的一半。什么是lowator_呢?就是该Freelist在ThreadCache超限的两次回收周期之间内,FreeList的最小长度。也就是说,在上一个周期中,FreeList里面有lowator_个object是从未被用到的。通过这一历史信息,可以预估在下一次回收到来时,可能也有lowator_个object可能不会被用到。不过保守一点,只回收lowator_的一半。
回收过程其实只是对每一个FreeList的保守回收,回收完成之后ThreadCache的容量可能还会继续高于限额,不过随着这次回收,ThreadCache的容量限额也会被抬高。
下一个问题是单个FreeList的限额,tcmalloc采用慢启动策略,每个FreeList初始时长度限额为1。在限额为1~batch_size之间时,为慢启动状态。此时,不管是alloc遇到空FreeList、还是free遇到长度超限,都给限额加1。这样做可以给不常用或者使用很规律的object确定一个合适的限额,而如果object的使用抖动较大的话,应该给它一个更大的buffer。
如果限额增加达到batch_size,则慢启动状态结束。此时,如果alloc遇到空FreeList,限额会按batch_size的整数倍进行扩展。而如果free超限,则限额将按照batch_size的整数倍进行缩减。
alloc遇到空FreeList(说明FreeList的限额达不到线程的分配需求),应该不断增加限额,这个好理解。那么free超限的情况下,为什么慢启动状态下要增加限额,非慢启动状态则要减少限额呢?如果free总是超限,说明线程对object的free要多于alloc,线程之间对该object的分配回收很可能是不对称的。那么作为专职回收的那个线程,没必要给他留大的限额,因为它的分配需求很少。而慢启动状态下超限还给限额做加1递增,一方面可以应对抖动,另一方面递增限额的目的是使之能够达到batch_size(如果free确实远多于alloc话),从而在回收object时可以按batch_size批量回收。
FreeList限额超限的处理比较简单,直接回收batch_size个object即可(不足batch_size个,则有多少回收多少)。可见,处于慢启动状态下的FreeList限额超限,将导致FreeList被清空。
原文链接: https://www.cnblogs.com/wangshaowei/p/14287125.html
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍;
也有高质量的技术群,里面有嵌入式、搜广推等BAT大佬


原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/391074
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!