
指针
1. 指针种类
*一维指针 **(multiply)二维或多维指针 [*]指针数组 (*)[]数组指针 lpfn函数指针 void*指针函数
2. 一维指针
2.1 概念
用来存放内存地址的变量
2.2 用途
2.2.1 访问内存
所有数据类型都有相应的指针
char wchar int int64
1 2 4 8
//以上是各数据类型的有效字节,实际系统给的4个字节(32bits下)
2.2.2 游历内存
2.2.3 传参
-
下层函数(main)的内存需要被上层函数(如Swap_2)所修改,需要传递一维指针
注意:此处的下层和上层实际指的在栈中的位置,main函数在下方,Swap_1函数在上方
//数值交换在该函数的栈区进行,当函数已执行完,该栈区函数就消亡了 int v1 = 3; int v2 = 4; Swap_1(v1, v2); _tprintf(_T("v1:%d v2:%drn"), v1,v2);//没有改变 Swap_2(&v1, &v2); _tprintf(_T("v1:%d v2:%drn"), v1, v2);//改变 void Swap_1(int ParameterData1, int ParameterData2)//数值交换 { int v1 = ParameterData1; ParameterData1 = ParameterData2; ParameterData2 = v1; } void Swap_2(int *ParameterData1, int* ParameterData2)//地址交换 { int v1 = *ParameterData1; *ParameterData1 = *ParameterData2; *ParameterData2 = v1; } -
节约参数列表(只需要传首地址,不用传每个元素)
int v10[] = { 1,2,12,4,5 }; Sub_1(v10, sizeof(v10) / sizeof(int)); void Sub_1(const int*ArrayAddress, int ArrayLength)//注意在参数列表指针前加一个const,防止函数内改变原数组数据,降低风险 { int i = 0; for (i = 0; i < ArrayLength; i++) { _tprintf(_T("%drn"), ArrayAddress[i]); } ArrayAddress[0] = 101;//在前面有const的情况下此句就会报错 }
2.2.4 动态分配数据结构
int Number = 0;
cout << "Input Number To Apply a Array" << end;
cin >> Number;
int *v1 = new int[Number];
//对它进行其他操作之后delete掉
delete v1;
2.3 注意事项
2.3.1 所有指针的大小
所有指针的有效字节是四个字节(32bits)或八个字节(64bits)
此时v2++相当于地址加一个sizeof(int) 即4字节,v3++就相当于地址加上一个sizeof(int*) 即加上指针的字节,即4或8
v2和数据类型有关,v3和系统位数有关
int v1 = 10;
int *v2 = &v1;//此时v2++相当于地址加一个sizeof(int) 即4字节
int **v3 = &v2;//而v3++就相当于地址加上一个sizeof(int*) 即加上指针的字节,即4或8
_tprintf(_T("%prn"), v2);//输出一个地址 如 0x12345678
v2++;
_tprintf(_T("%prn"), v2);//输出一个地址 如 0x1234568C
_tprintf(_T("%prn"), v3);//输出一个地址 如 0x12345688
v3++;
_tprintf(_T("%prn"), v3);//输出一个地址 如 0x1234569C(32bits) 或 0x123456A0(64bits)
2.3.2 一维指针的区别
区别主要在于解星号,如char*解星号,若存在 0x123456ff,解星号即从最低的 ff(即一个字节)开始
unsigned int v1 = 257; //十六进制为 0x0101
unsigned char *v2 = (unsigned char*)&v1;
wchar_t *v3 = (wchar_t*)&v1;
_tprintf(_T("%drn"), *v2);//结果为1
_tprintf(_T("%drn"), *v3);//结果为257
指针解星号访问数据与自身的数据类型大小息息相关 dereference操作(解星号)
2.3.3 指针的算术运算++ --
v2=v1++;//v2=v1;v1=v1+1;
v2=++v1;//v1=v1+1;v2=v1;
特别的,对于如下
v1=1;v2=0;
v2=(++v1)+(v1++)+(++v1);//v1能算出来,v2不能算出来
原因是编译器的编译原理不一样结果就不一样
指针加法公式:
指针变量 += 数值 ⇔ 指针变量地址数据 +=(sizeof( 指针类型 ) * 数值)
2.3.4 一维指针和一维数组的关系
一维数组的数组名字可以当成一维指针进行使用
//int v1[6]; 则v1[5]相当于v1+sizeof(int)*5;
void sub_1()
{
int i = 0;
int v1[] = { 1,2,3,4,7,10,-1 };//栈区数组stack array
int *v2 = v1;//一维数组名可以当一维指针用,但它自身不能改变,即可以进行v1+1,但不能进行v1++,会报错
for (i = 0; i < sizeof(v1) / sizeof(int); ++i)
{
_tprintf(_T("%drn"), v1[i]);
_tprintf(_T("%drn"), *(v1+i));//[]==*()
_tprintf(_T("%drn"), *(v2+i));
_tprintf(_T("%drn"), *v2);
v2++;//v2本身作为一个指针可以改变自身实现遍历
}
}
2.3.5 多维指针数组的数组名和一维指针的关系
多维数组不能直接等于一维指针,需要进行强制类型转换,这是语法问题
int i;
int v1[] = { 0,3,5,7,1,4 };//对于一维数组,循环遍历
for (i = 0; i < sizeof(v1) / sizeof(int); i++)
{
_tprintf(_T("%drn"), v1[i]);
}
int v2[2][3][2] = { 2,3,5,76,4,32,1,8,0,6,3,9 };//对于多维数组,一般可能会想到使用多个for循环嵌套,但是应考虑到栈区数组内存空间的连续性
int *v3 = (int*)v2;//使用强制类型转换使多维数组名v2能够转化为一个指针v3
for (i = 0; i < sizeof(v2) / sizeof(int); i++)//此时应sizeof原数组
{
_tprintf(_T("%drn"), v3[i]);//[]*()
}
2.4 指针用法举例
2.4.1 一维数组名和二维数组名的强转
int v1[] = { 1,2,3,4 };
int *v2 = v1;//这样是可以的
int v3[2][3] = { 1,2,3,4,5,6 };
int *v4 = v3;//不可以
int(*v4)[3] = v3;//v3可以当成数组的指针来用
2.4.2 强制转换
//进行强制转换的话,如int *v5=(int*)0xA;这样地址虽然是存在的,但是里面没有东西,程序很有可能崩溃
int *v5 = (int*)v3;//可以,这样v3里是有东西的,不会崩溃
//通过强制转换,还可以使int存char型数据:
int v6 = "hell";//这样是会报错的,因为语法不允许,注意int最多只能存四个字符,类似于char v1[4],如果硬要使int存char型数据,也可以采用下面的办法
int v6 = 0;
*((char*)&v6 + 0) = 'H';
*((char*)&v6 + 1) = 'e';
*((char*)&v6 + 2) = 'l';
*((char*)&v6 + 3) = 'l';//有点类似于大指针存小数据,注意在将其输出后将改过的数据改回去
//若将单引号里的改为中文,则一个int型最多只能存两个字,此时应将前面的char*改为WCHAR*,或者使用strcpy拷贝字符
2.4.3 一维数组名为一维指针
int v1[] = { 1,2,3,4 };
int *v2 = v1;
int *v2 = &v1;//报错,语法问题,实际上上下这两句并没有区别,对v1取地址还是地址,但其实v1本身就是地址
_tprintf(_T("%prn"), v1);
_tprintf(_T("%prn"), &v1);//两个输出的是一样的
2.4.4 以下v1v2定义方式和v3的区别,如果是char型呢
int v1 = 10;
int v2 = 20;
int v3[2] = { 10,20 };
_tprintf(_T("%drn"), (&v2)[1]);//可以通过这样来访问到v1,此时输出 10
//v1v2和v3没有太大区别,他们的内存在小编译器里都是连续的
char v1 = 1;
char v2 = 2;
char v3[2] = { 1,2 };
_tprintf(_T("%drn"), (&v2)[4]);//对于char型而言,系统实际上分配的是四个字节,但是规定只能访问一个字节,所以应改为4才能访问到v1
//此时v1和v2是不连续的
2.4.5 冒泡排序bubble Sort
//一个普通的冒泡排序算法
int v1[] = { 1,2,3,4,7,8,1000,-1 };
int v2 = 0;
int i = 0;
int j = 0;
for (i = 0; i < sizeof(v1) / sizeof(int) - 1; i++)//-1适当提高效率
{
for (j = i + 1; j < sizeof(v1) / sizeof(int); j++)
{
if (v1[i] > v1[j])
{
v2 = v1[i];
v1[i] = v1[j];
v1[j] = v2;
}
}
}
for(i=0;i<sizeof(v1)/sizeof(int);i++)
{
_tprintf(_T("%drn"), v1[i]);
}
//多维数组的冒泡排序
int v3[2][3][2] = { 2,3,5,76,4,32,1,8,0,6,3,9 };
int *v4 = (int*)v3;//强制转换
for (i = 0; i < sizeof(v3) / sizeof(int) - 1; i++)//-1适当提高效率
{
for (j = i + 1; j < sizeof(v3) / sizeof(int); j++)
{
if (v4[i] > v4[j])
{
v2 = v4[i];
v4[i] = v4[j];
v4[j] = v2;
}
}
}
for (i = 0; i < sizeof(v1) / sizeof(int); i++)//进行输出
{
_tprintf(_T("%drn"), v4[i]);
}
2.4.6 大数据被小指针访问(只能通过强制转换)
int v1 = 257;
//char*v2 = (char*)&v1;这样的结果为1
WCHAR*v2 = (WCHAR*)&v1;//改成比char字节大的数据类型都可
_tprintf(_T("%drn"), *v2);
2.4.7 小数据被大指针访问(要将其他内存初始化为0)
char v3 = 1;
int *v4 = (int*)&v3;
*((char*)v4 + 1) = 0;
*((char*)v4 + 2) = 0;
*((char*)v4 + 3) = 0;//需要借助小指针将其他内存初始化为0,因为栈区内存默认为0xcc,heap是cd
_tprintf(_T("%drn"), *v4);
*((char*)v4 + 1) = 0xCC;
*((char*)v4 + 2) = 0xCC;
*((char*)v4 + 3) = 0xCC;//最后要将它改回来,避免程序崩溃
3. 二维指针
3.1 二维数组(栈和堆)
在栈数组里,*(*(v1+i)+j)这种形式实际上只解一次星号;而堆数组的二维数组,((v1+i)+j)解两次
int i = 0;
int v1[2][3] = { 1,2,3,4,-1,5 };
int **v5 = NULL;
v5 = new int*[2];
for ( i = 0; i < 2; i++)
{
v5[i] = new int[3];
}
for (i = 0; i < 2; i++)
{
for (int j = 0; j < 3; j++)
{
v5[i][j] = v1[i][j];
}
}
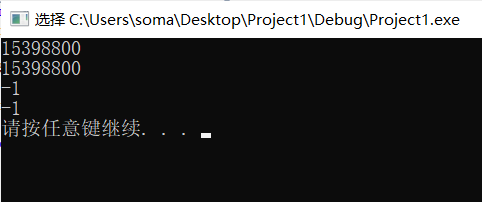
_tprintf(_T("%drn"), v1);
_tprintf(_T("%drn"), *v1);
_tprintf(_T("%drn"), *((v1 + 1) + 1));
_tprintf(_T("%drn"), *((v5 + 1) + 1));
//如果强转:
int**v2=(int**)v1;
tprintf(_T("%drn"), *(*(v2 + 1) + 1));//会报错
//大多数时候使用堆的二维数组,有一种情况可以使用栈数组:定义姓名的时候char v1[3][20];//三个姓名,每个最多20个字节

3.2 二维指针的作用
3.2.1 传参
int *v3 = NULL;
sub_2(&v3, 3);
int i = 0;
for (i = 0; i < 3; i++)
{
v3[i] = 1 + i;
}
void sub_2(int**ParameterData1, int ParameterData2)
{
*ParameterData1 = new int[ParameterData2];
}
3.2.2 堆数组
int **v1 = NULL;
v1=new int*[2];
int i = 0;
for (i = 0; i < 2; i++)
{
v1[i] = new int[3];
}
for (i = 0; i < 2; i++)
{
delete v1[i];
}
delete v1;

3.2.3 注意事项
-
子函数堆内存在主函数中继续使用,需要二维指针
如果是在主函数动态申请,那么就是一维指针申请new内存
如果在子函数中申请堆内存,仍想在主函数中继续使用,就需要取地址的地址
-
和一维指针类比:
一维:普通变量需要跨作用域,那么就取地址。
二维:堆内存要跨作用域访问,就取地址的地址。
4. 指针和地址的区别
不同点:
| 指针 | 地址 |
|---|---|
| 变量,保存变量地址 | 常量,内存标号 |
| 可修改,再次保存其他变量地址 | 不可修改 |
| 可以对其执行取地址操作 | 不可执行取地址操作 |
| 包含对保存地址的解释信息 | 仅有地址值无法解释数据 |
共同点:
| 指针 | 地址 |
|---|---|
| 取出指向地址内存的数据 | 取出地址对于内存的数据 |
| 对地址偏移后,取出数据 | 偏移后取出数据,自身不变 |
| 求两个地址的差 | 求两个地址的差 |
原文链接: https://www.cnblogs.com/XiuzhuKirakira/p/17083991.html
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍;
也有高质量的技术群,里面有嵌入式、搜广推等BAT大佬

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/383637
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!