
作用:单文本串多模式串匹配。
前置知识:trie树。
AC自动机可以看作是在字典树上做 KMP,但并不是把 KMP 算法放到树上来,而是用了一种和 KMP 类似的思想,即在字典树上匹配文本串的时候如果失配,就跳到 (fail) 指针所指的节点,所以学AC自动机没必要精通 KMP。
拿例题来讲:给定 (n) 个模式串和 (1) 个文本串,求有多少个模式串在文本串里出现过。
那么要先构造一个字典树将上述字符串存储,代码如下:
class Trie{
public:
int ch[N][26],mk[N],cnt;
Trie(){cnt=1;}
void insert(char*s){
int n=strlen(s+1),x=1;
for(int i=1;i<=n;i++){
int c=s[i]-'a'+1;
if(!ch[x][c]) ch[x][c]=++cnt;
x=ch[x][c];
}
mk[x]++;//以该节点为结尾的模式串数
}
};
比如有这些模式串:
(texttt{kony})
(texttt{wen})
(texttt{emm})
(texttt{kib})
那么构造成的字典树会长这样:


AC自动机就是在字典树的基础上,对于每个节点 (x),增加一个指针 (fail[x]),如上文所述,用来在失配时跳转指针,这样如果匹配失败就不需要回溯了。
如上图,根节点的子节点,即第一层的的节点 (x),应该有 (fail[x]=1),即如果在第一个字符失配,就从头开始再找(如下图,黄色箭头表示 (fail[]))。
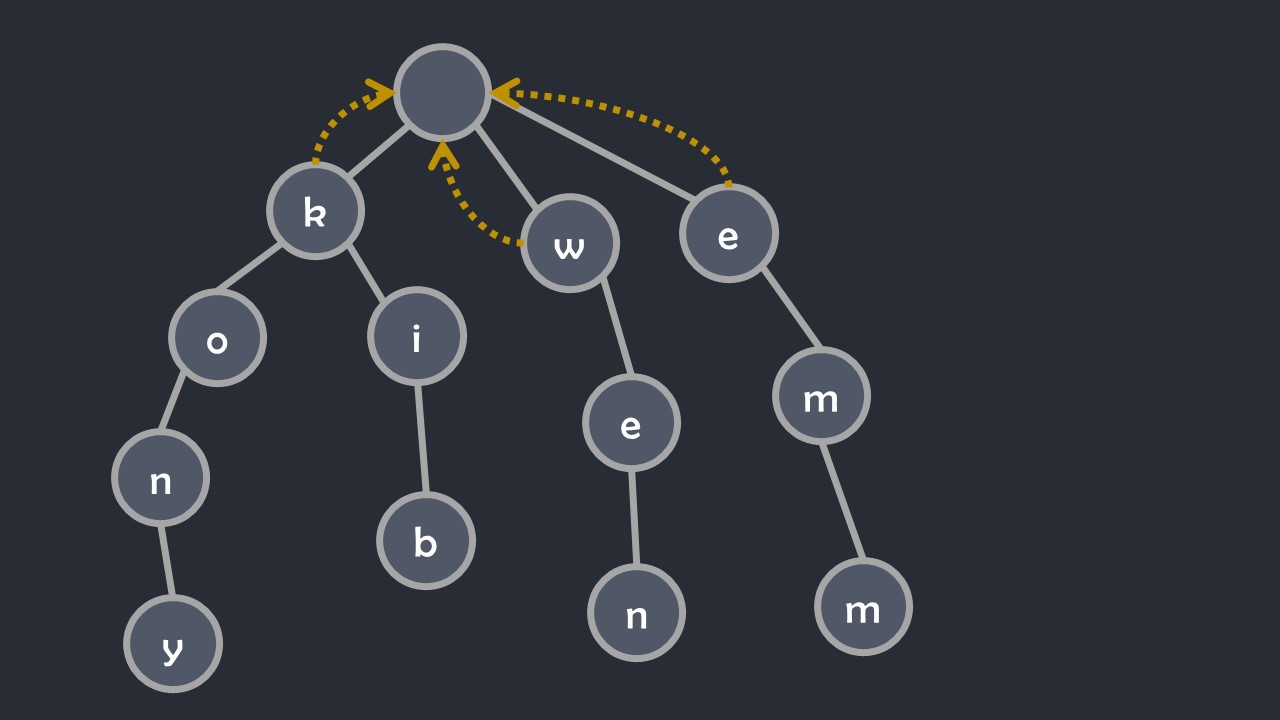
如果节点 (x) 没有子节点 (ch[x][c]),那么 (ch[x][c]=ch[fail[x]][c]),相当于由于没有该字符子节点而失配(末尾符失配),自动跳转 (fail)(如下图,紫色箭头表示 (ch[][]))。
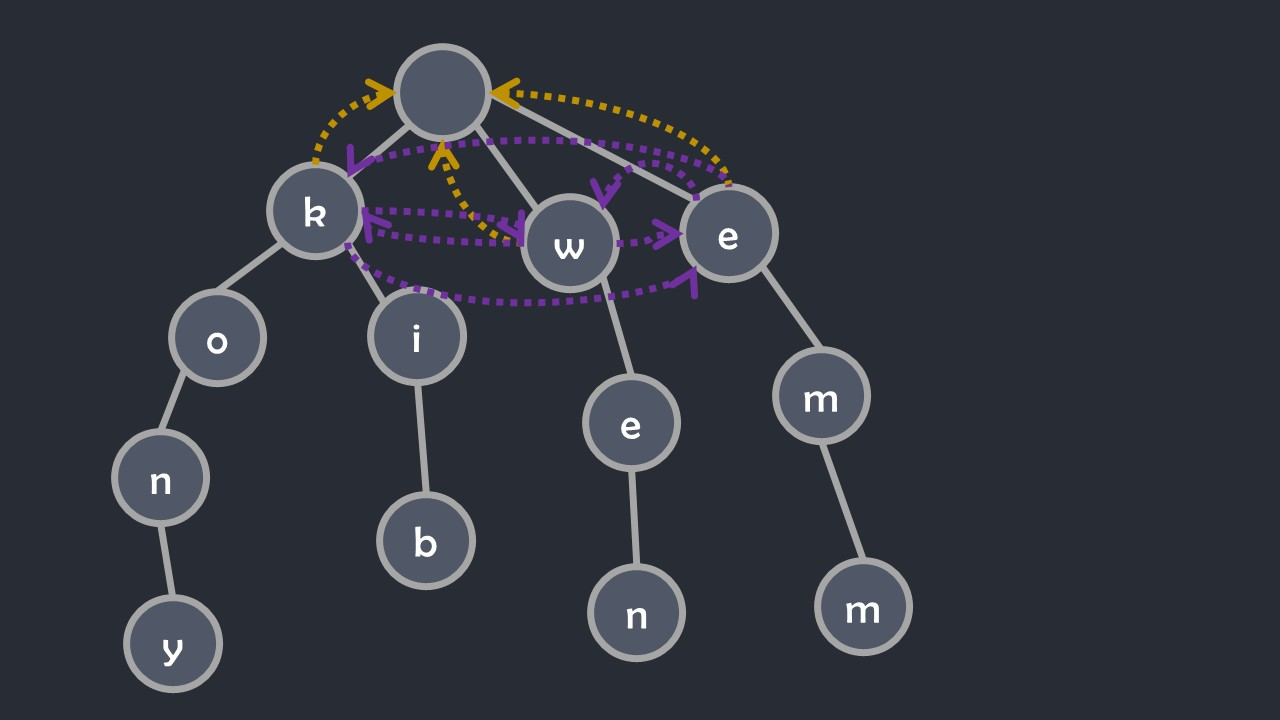
为了简化问题,后文图中不加末尾符失配紫色指针。
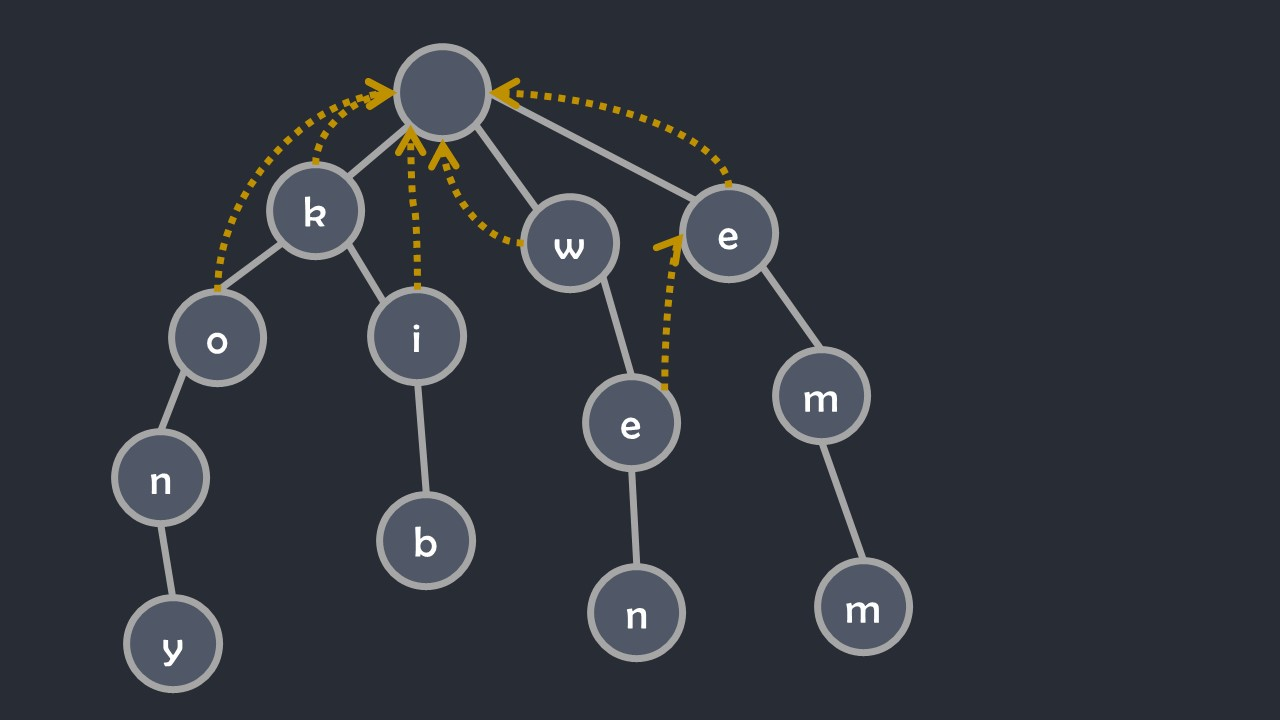
按 (bfs) 序遍历字典树。如果节点 (x) 有子节点 (ch[x][c]),那么 (fail[ch[x][c]]=ch[fail[x]][c]),即如果失配就跳到最相邻已经遍历过的字符为 (c) 的节点中。如果目前还没有发现字符为 (c) 的节点,就令 (fail[ch[x][c]]=1)。如下图:
这是构造AC自动机 (fail[]) 数组的代码:
void build(){
for(int i=1;i<=26;i++) ch[0][i]=1;//把1节点的子节点同样操作
queue<int> q;while(q.size()) q.pop();q.push(1);//☆
while(q.size()){//按bfs序求fail 指针
int x=q.front();q.pop();
for(int i=1;i<=26;i++)
if(ch[x][i]) fail[ch[x][i]]=ch[fail[x]][i],q.push(ch[x][i]);//☆
else ch[x][i]=ch[fail[x]][i];//☆
}
}
最后构造好 (fail) 指针以后的字典树就是AC自动机,长这样:
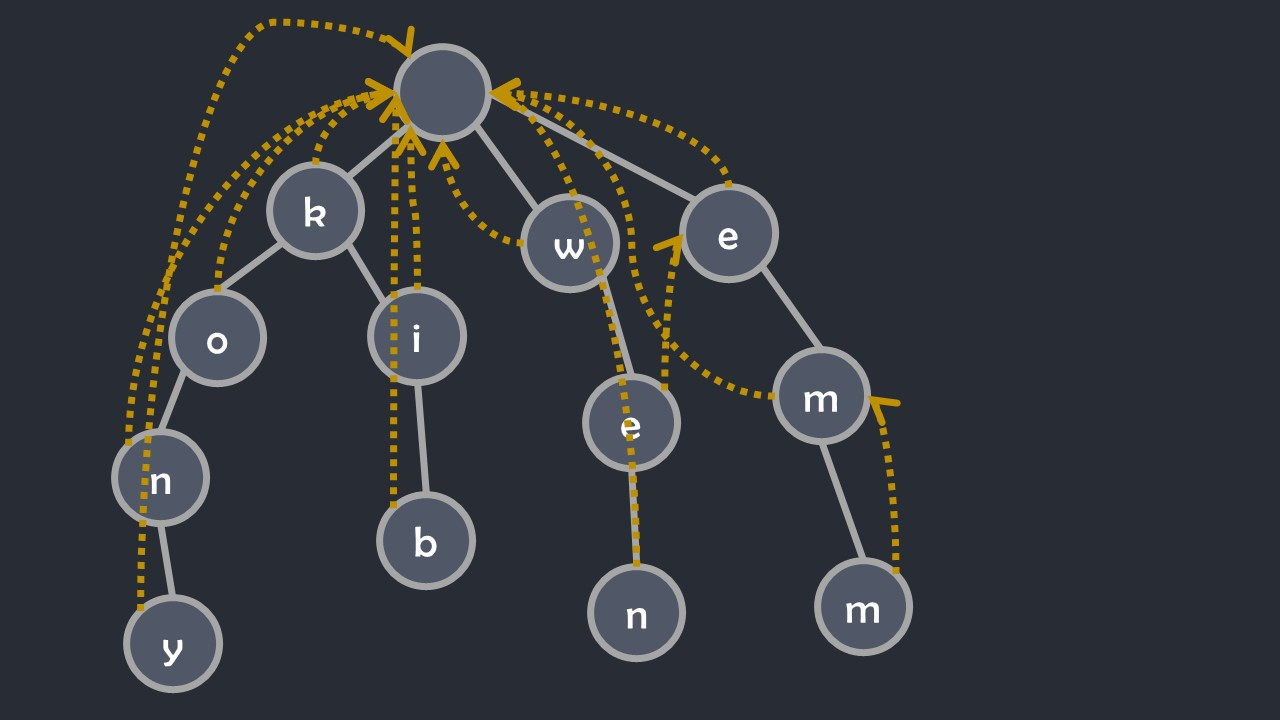
然后就是重点了——应用 (fail) 查找有几个模式串在文本串中出现。代码如下:
int fapp(char*s){
int n=strlen(s+1),x=1,res=0;
for(int i=1;i<=n;i++){
x=ch[x][s[i]-'a'+1];
for(int j=x;j&&mk[j]!=-1;j=fail[j])//mk置为-1防止重复计算
res+=mk[j],mk[j]=-1;
}
return res;
}
这时候你会很惊骇:这哪是失配跳转啊,这分明就是指针乱飞!其实仔细想的话,其实是指针在整个AC自动机间穿梭(说了等于没说),由于之前的紫色箭头 (ch[][]) 指针,指针表面上顺着字典树走的同时,也在自动末尾符失配跳转,即单前字典树节点如果没有某个字符子节点,就会自动跳到有该字符的节点上或者根节点。而后面那句 (fail) 指针跳转的 (texttt{for}) 循环,就求出了单前节点到根节点所连成的字符串的后缀的出现次数。
然后如上一波猛如犇的操作以后,答案——模式串在文本串中出现的次数就出现了。如果你懂了,蒟蒻就放代码了:
#include <bits/stdc++.h>
using namespace std;
const int N=1e6+10;
class Trie{
public:
int ch[N][26],mk[N],cnt;
Trie(){cnt=1;}
void insert(char*s){
int n=strlen(s+1),x=1;
for(int i=1;i<=n;i++){
int c=s[i]-'a'+1;
if(!ch[x][c]) ch[x][c]=++cnt;
x=ch[x][c];
}
mk[x]++;
}
};
class Acam:public Trie{//Class 继承
public:
int fail[N];
void build(){
for(int i=1;i<=26;i++) ch[0][i]=1;
queue<int> q;while(q.size()) q.pop();q.push(1);
while(q.size()){
int x=q.front();q.pop();
for(int i=1;i<=26;i++)
if(ch[x][i]) fail[ch[x][i]]=ch[fail[x]][i],q.push(ch[x][i]);
else ch[x][i]=ch[fail[x]][i];
}
}
int fapp(char*s){
int n=strlen(s+1),x=1,res=0;
for(int i=1;i<=n;i++){
x=ch[x][s[i]-'a'+1];
for(int j=x;j&&mk[j]!=-1;j=fail[j])
res+=mk[j],mk[j]=-1;
}
return res;
}
}m;
int num;
char s[N];
int main(){
scanf("%d",&num);
for(int i=1;i<=num;i++)
scanf("%s",s+1),m.insert(s);
m.build();
scanf("%s",s+1);
printf("%dn",m.fapp(s));
return 0;
}
可是如果字符串一多,字典树一大,那么那个重要的语句:
for(int j=x;j&&mk[j]!=-1;j=fail[j])
res+=mk[j],mk[j]=-1;
反而会造成时间超限,如这道例题:
洛谷P5357 【模板】AC自动机(二次加强版)
如果你直接按上面的代码改改,会 (texttt{TLE75分})。
是时候优化如上穿梭指针语句了,那么怎么优化呢?我们发现如果把 (fail[]) 看成一些边,就会构成一个 (texttt{DAG}) ,而答案更新又是按照 (fail[]) 数组跳指针的,这时我们必须有想到一个算法的直觉:拓扑排序。
因为不跳 (fail) 了,所以就不需要 (mk[x]) 数组标记以 (x) 节点为结尾的字符串数了。因为要拓扑排序,所以记录每个字符串编号 (i) 的终止节点 (en[i])。所以 (texttt{insert()}) 函数长这样:
void insert(char*s,int x){
int n=strlen(s+1),p=1;
for(int i=1;i<=n;i++){
int c=s[i]-'a'+1;
if(!ch[p][c]) ch[p][c]=++cnt;
p=ch[p][c];
}
en[x]=p;
}
然后AC自动机的 (fail) 构造函数不变,因为要拓扑求答案,所以对于每个字符,只需要在该字符结尾的最长串加上标记即可。所以 (texttt{fapp()}) 求答案函数要变成这样:
void fapp(char*s){
int n=strlen(s+1),p=1;
for(int i=1;i<=n;i++)
//mk[p=ch[p][s[i]-'a'+1]]++; 这么写对萌新不友好
p=ch[p][s[i]-'a'+1],mk[p]++;
}
然后按 (fail) 指针加反边:
for(int i=2;i<=m.cnt;i++) g[m.fa[i]].push_back(i);
然后拓扑求答案即可:
void dfs(int x){
for(auto to:g[x]) dfs(to),m.mk[x]+=m.mk[to];
}
最后对于每个字符串编号 (i),(mk[en[i]]) 就是该模式字符串在文本串中出现的次数。如果你都懂了,那么蒟蒻就放代码了:
#include <bits/stdc++.h>
using namespace std;
const int N=2e5+10,T=2e6+10;
class Trie{
public:
int cnt,ch[N][30],en[N],mk[N];
Trie(){cnt=1;}
void insert(char*s,int x){
int n=strlen(s+1),p=1;
for(int i=1;i<=n;i++){
int c=s[i]-'a'+1;
if(!ch[p][c]) ch[p][c]=++cnt;
p=ch[p][c];
}
en[x]=p;
}
};
class Acam:public Trie{
public:
int fa[N];
void build(){
for(int i=1;i<=26;i++) ch[0][i]=1;
queue<int> q;while(q.size()) q.pop();q.push(1);
while(q.size()){
int x=q.front();q.pop();
for(int i=1;i<=26;i++)
if(ch[x][i]) fa[ch[x][i]]=ch[fa[x]][i],q.push(ch[x][i]);
else ch[x][i]=ch[fa[x]][i];
}
}
void fapp(char*s){
int n=strlen(s+1),p=1;
for(int i=1;i<=n;i++)
mk[p=ch[p][s[i]-'a'+1]]++;
}
}m;
int n;
char s[T];
vector<int> g[N];
void dfs(int x){
for(auto to:g[x]) dfs(to),m.mk[x]+=m.mk[to];
}
int main(){
scanf("%d",&n);
for(int i=1;i<=n;i++) scanf("%s",s+1),m.insert(s,i);
m.build(),scanf("%s",s+1),m.fapp(s);
for(int i=2;i<=m.cnt;i++) g[m.fa[i]].push_back(i);
dfs(1);
for(int i=1;i<=n;i++) printf("%dn",m.mk[m.en[i]]);
return 0;
}
祝大家学习愉快!
原文链接: https://www.cnblogs.com/George1123/p/12441203.html
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍;
也有高质量的技术群,里面有嵌入式、搜广推等BAT大佬

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/371829
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!