
文章目录
相机作为视觉传感器,是机器人、监视、太空探索、社交媒体、工业自动化、甚至娱乐业等多个领域的组成部分。在许多应用中,必须知道相机的参数才能将其有效地用作视觉传感器。在这篇文章中,你将了解相机标定所涉及的步骤及其意义。我们还共享C++和Python中的代码以及棋盘模式的示例图像。
1 什么是相机标定?
相机参数的估计过程称为相机标定。这意味着我们拥有关于相机的所有信息(参数或系数),这些信息用于确定真实世界中的3D点与其在该标定相机捕获的图像中的相应2D投影(像素)之间的精确关系。通常这意味着恢复两种参数。
- 内部参数相机/镜头系统。例如透镜的焦距、光学中心和径向畸变系数。
- 外部参数这是指相机相对于某些世界坐标系的方位(旋转和平移)。
在下图中,使用几何标定估计的透镜参数来消除图像失真。
![[OpenCV实战]38 基于OpenCV的相机标定](https://www.ccppcoding.com/wp-content/uploads/aHR0cHM6Ly93d3cubGVhcm5vcGVuY3YuY29tL3dwLWNvbnRlbnQvdXBsb2Fkcy8yMDE5LzExL2dlb21ldHJpYy1jYWxpYnJhdGlvbi03Njh4Mjg2LmpwZw.png)
![[OpenCV实战]38 基于OpenCV的相机标定](https://www.ccppcoding.com/wp-content/themes/justnews/themer/assets/images/lazy.png)
2 图像形成几何学
要理解标定的过程,我们首先需要了解成像几何。我们将从几何的角度来解释图像的形成。具体来说,我们将讨论三维点如何在图像平面上投影的数学问题。也就是说,你所需要知道的就是矩阵乘法。
2.1 设定
为了容易理解这个问题,假设你在房间里安装了一台照相机。给定三维点P在这个房间里,我们想要找到这个3D点的像素坐标(u,v)在相机拍摄的图像中。在这个设置中有三个坐标系在起作用。我们来解释一下(解释涉及光学知识看不懂不影响可跳过)。
2.1.1 世界坐标系
![[OpenCV实战]38 基于OpenCV的相机标定](https://www.ccppcoding.com/wp-content/uploads/aHR0cHM6Ly93d3cubGVhcm5vcGVuY3YuY29tL3dwLWNvbnRlbnQvdXBsb2Fkcy8yMDIwLzAyL3dvcmxkLWNvb3JkaW5hdGVzLWFuZC1jYW1lcmEtY29vcmRpbmF0ZXMucG5n.png)
由上图可以看到世界坐标系和相机坐标系是通过旋转和平移联系起来的。这六个参数(3个用于旋转,3个用于平移)称为相机的外部参数。
要定义房间中点的位置,我们首先需要为这个房间定义一个坐标系。它需要做两件事:
- 原点:我们可以随意地把房间的一角作为原点。(0,0,0).
- X,Y,Z轴:我们还可以沿着地板上的二维定义房间的X轴和Y轴,沿着垂直墙定义房间的Z轴。
利用上面的方法,我们可以通过测量空间内任意点沿X、Y和Z轴与原点的距离来找到它的三维坐标。这个与房间相连的坐标系称为世界坐标系。在图1中,它使用橙色轴显示。我们将使用粗体字体表示轴,用普通字体表示点的坐标。
让我们考虑一下这个房间的P点。在世界坐标系中,P的坐标只需沿三个轴测量该点距原点的距离,就可以找到该点的X、Y和Z坐标。
2.1.2 相机坐标系
现在,让我们把相机放在这个房间里。这个房间的图像将用这个相机拍摄,因此,我们感兴趣的是连接到这个相机上的三维坐标系。如果我们将相机放在房间的原点,并使其X、Y和Z轴与房间的xyz轴对齐,则两个坐标系将是等同的。
然而,这是一个荒谬的限制。我们想把相机放在房间里的任何地方,它应该可以在任何地方看到。在这种情况下,我们需要找出三维房间(即世界)坐标和三维相机坐标之间的关系。
假设我们的相机位于房间中的任意位置(
t
X
t_X
tX,
t
Y
t_Y
tY,
t
Z
t_Z
tZ)。用技术术语来说,我们可以用((
t
X
t_X
tX,
t
Y
t_Y
tY,
t
Z
t_Z
tZ)相对于世界坐标来转换相机坐标。相机也可能朝着任意的方向看。换句话说,我们可以说相机是相对于世界坐标系旋转的。
3D中的旋转是用三个参数捕捉的——你可以把这三个参数看作yaw, pitch, roll。也可以将其视为三维中的轴(两个参数)和围绕该轴的角度旋转(一个参数)。
然而,将旋转编码为3×3矩阵往往是便于数学操作的。现在,您可能会认为,3×3矩阵有9个元素,因此有9个参数,但是旋转只有3个参数。这就是为什么任意3×3矩阵都不是旋转矩阵的原因。不谈细节,让我们现在只知道,一个旋转矩阵只有三个自由度,即使它有9个元素。
回到我们原来的问题。世界坐标和相机坐标由旋转矩阵 R 和一个三元平移矢量 t 关联。
那是什么意思?
这意味着在世界坐标系中具有坐标值(
X
w
X_w
Xw,
Y
w
Y_w
Yw,
Z
w
Z_w
Zw)的点P在相机坐标系中将具有不同的坐标值(
X
c
X_c
Xc,
Y
c
Y_c
Yc,
Z
c
Z_c
Zc)。我们用红色表示相机坐标系。这两个坐标值与下面的方程有关。
![[OpenCV实战]38 基于OpenCV的相机标定](https://www.ccppcoding.com/wp-content/uploads/aHR0cHM6Ly93d3cubGVhcm5vcGVuY3YuY29tL3dwLWNvbnRlbnQvcWwtY2FjaGUvcXVpY2tsYXRleC5jb20tMmU1NWVmMGFmMmY0YmIzOWZlMzdkOGQ3MWNkMGExNmRfbDMucG5n.png)
请注意,将旋转表示为一个矩阵可以让我们用简单的矩阵乘法来进行旋转,而不是像yaw, pitch, roll等其他表示中所需的繁琐的符号操作。我希望这能帮助你理解为什么我们把旋转表示为矩阵。有时,上面的表达式是以更紧凑的形式写成的。将3×1平移向量作为一列附加在3×3旋转矩阵的末尾,得到一个3×4矩阵,称为外参矩阵。
![[OpenCV实战]38 基于OpenCV的相机标定](https://www.ccppcoding.com/wp-content/uploads/aHR0cHM6Ly93d3cubGVhcm5vcGVuY3YuY29tL3dwLWNvbnRlbnQvcWwtY2FjaGUvcXVpY2tsYXRleC5jb20tNGUzYzY1NjI3YmU3ZTRmOGRkNDY3ZjE1NmNhNjhhNzFfbDMucG5n.png)
其中,外参矩阵 P 是由下式给出:
![[OpenCV实战]38 基于OpenCV的相机标定](https://www.ccppcoding.com/wp-content/uploads/aHR0cHM6Ly93d3cubGVhcm5vcGVuY3YuY29tL3dwLWNvbnRlbnQvcWwtY2FjaGUvcXVpY2tsYXRleC5jb20tODI1Njg5Y2YxN2Q2YTVmN2RmM2JhZDI4NWJkNDBjZjNfbDMucG5n.png)
在射影几何学中,我们经常用一个有趣的坐标即齐次坐标表示,在坐标上附加一个额外的维度。笛卡尔坐标系中的三维点(X,Y,Z)可以在齐次坐标系中写成(X,Y,Z,1)。更广泛地说,齐次坐标中(X, Y, Z, W)点与笛卡尔坐标中的点(
X
W
X_W
XW,
Y
W
Y_W
YW,
Z
W
Z_W
ZW)相同。齐次坐标允许我们用有限的数字来表示无限量。例如,无穷远处的点可以在齐次坐标系中表示为(1,1,1,0)。你可能会注意到我们在外参矩阵中使用了齐次坐标来表示世界坐标
2.1.3 图像坐标系
![[OpenCV实战]38 基于OpenCV的相机标定](https://www.ccppcoding.com/wp-content/uploads/aHR0cHM6Ly93d3cubGVhcm5vcGVuY3YuY29tL3dwLWNvbnRlbnQvdXBsb2Fkcy8yMDIwLzAyL3dvcmxkLWNhbWVyYS1pbWFnZS1jb29yZGluYXRlcy5wbmc.png)
点P在图像平面上的投影如上图所示。一旦我们通过对点世界坐标应用旋转和平移来获得相机三维坐标系中的点,我们就可以将该点投影到图像平面上以获得该点在图像中的位置。
在上面的图像中,我们看到的是一个点P,在相机坐标系中有坐标(
X
c
X_c
Xc,
Y
c
Y_c
Yc,
Z
c
Z_c
Zc)。只是提醒一下,如果我们不知道这个点在相机坐标系中的坐标,我们可以使用外参矩阵变换它的世界坐标,从而使用外参矩阵获得相机坐标系中的坐标。上图显示了简单针孔相机的相机投影。
光学中心(针孔)用
O
c
O_c
Oc表示,实际上在像面上形成点的倒像。为了数学上的方便,我们简单地做所有的计算,就好像图像平面在光学中心的前面一样,因为从传感器读出的图像可以轻微地旋转180度来补偿反转。实际上,这是不需要的。它甚至更简单:一个真正的相机传感器只是按照相反的顺序(从右到左)从最下面一行读出,然后从下到上读取每一行。通过这种方法,图像自动垂直形成,左右顺序正确。因此在实践中,不再需要旋转图像。
图像平面放置在距离光学中心f(焦距)的位置。
利用高中几何(相似三角形),可以显示出三维点(
X
c
X_c
Xc,
Y
c
Y_c
Yc,
Z
c
Z_c
Zc)的投影图像(x,y)由下式获得:
![[OpenCV实战]38 基于OpenCV的相机标定](https://www.ccppcoding.com/wp-content/uploads/aHR0cHM6Ly93d3cubGVhcm5vcGVuY3YuY29tL3dwLWNvbnRlbnQvcWwtY2FjaGUvcXVpY2tsYXRleC5jb20tYTY2ZjgwNjliN2QzOGRiNDIwOWVlM2VjYTAzMjBhMWVfbDMucG5n.png)
这两个方程可以用矩阵形式重写如下:
![[OpenCV实战]38 基于OpenCV的相机标定](https://www.ccppcoding.com/wp-content/uploads/aHR0cHM6Ly93d3cubGVhcm5vcGVuY3YuY29tL3dwLWNvbnRlbnQvcWwtY2FjaGUvcXVpY2tsYXRleC5jb20tMDU1NjhkZWYyYzllODc2ZTgzZGE4NmM5YThkOGYxNWNfbDMucG5n.png)
矩阵K如下所示,称为内参矩阵并包含相机的内在参数。
![[OpenCV实战]38 基于OpenCV的相机标定](https://www.ccppcoding.com/wp-content/uploads/aHR0cHM6Ly93d3cubGVhcm5vcGVuY3YuY29tL3dwLWNvbnRlbnQvcWwtY2FjaGUvcXVpY2tsYXRleC5jb20tN2NmNDY3NzQ2NzM4NjFiN2E0ZGExYjdkZjY5NjI3OTdfbDMucG5n.png)
上述简单矩阵只显示焦距。然而,图像传感器中的像素可能不是方形的,因此我们可能有两个不同的焦距。f_x和f_y。光学中心(c_x, c_y)相机的中心可能与图像坐标系的中心不重合。
此外,相机传感器的x轴和y轴之间可能有一个小的倾斜
γ
gamma
γ。考虑到以上所有因素,相机矩阵可以重新编写为:
![[OpenCV实战]38 基于OpenCV的相机标定](https://www.ccppcoding.com/wp-content/uploads/aHR0cHM6Ly93d3cubGVhcm5vcGVuY3YuY29tL3dwLWNvbnRlbnQvcWwtY2FjaGUvcXVpY2tsYXRleC5jb20tYTA0OGRhODJhNjJmZDc4MGIxOWI5N2I1MTc1NTFkNzBfbDMucG5n.png)
下图显示了当图像像素坐标系的原点位于左上角时更真实的场景。内参相机矩阵需要考虑主点的位置、轴的倾斜以及沿不同轴的潜在不同焦距。
![[OpenCV实战]38 基于OpenCV的相机标定](https://www.ccppcoding.com/wp-content/uploads/aHR0cHM6Ly93d3cubGVhcm5vcGVuY3YuY29tL3dwLWNvbnRlbnQvdXBsb2Fkcy8yMDIwLzAyL2NhbWVyYS1wcm9qZWN0aW9uLTNELXRvLTJELnBuZw.png)
然而,在上述等式中,x和y像素坐标相对于图像的中心。但是,在处理图像时,原点位于图像的左上角。
我们用(u,v)表示图像坐标。则有下式:
![[OpenCV实战]38 基于OpenCV的相机标定](https://www.ccppcoding.com/wp-content/uploads/aHR0cHM6Ly93d3cubGVhcm5vcGVuY3YuY29tL3dwLWNvbnRlbnQvcWwtY2FjaGUvcXVpY2tsYXRleC5jb20tMThlMzNlN2ViNTFhMGE1MWNhNGQ3ODg4MThlNTAwYmRfbDMucG5n.png)
其中:
![[OpenCV实战]38 基于OpenCV的相机标定](https://www.ccppcoding.com/wp-content/uploads/aHR0cHM6Ly93d3cubGVhcm5vcGVuY3YuY29tL3dwLWNvbnRlbnQvcWwtY2FjaGUvcXVpY2tsYXRleC5jb20tN2U0MjBjMzllMWIwZmFkZDQwZWU3MmI2NjJjYzM3NzFfbDMucG5n.png)
2.2 图像形成方法总结
将世界坐标系中的三维点投影到相机像素坐标上,有以下步骤:
- 利用由两个坐标系之间的旋转和平移组成的外部矩阵,将三维点从世界坐标转换为相机坐标。
- 在相机坐标系中,利用相机内部焦距、光心等参数构成的内部矩阵将新的三维点投影到图像平面上。
3 基于OpenCV的相机标定原理
3.1 相机标定相关参数
正如上章中所解释的,要找到三维点在图像平面上的投影,我们首先需要使用外部参数(R和t)将点从世界坐标系转换为相机坐标系。接下来,使用相机的内部参数,我们将点投影到图像平面上。
将世界坐标系中的三维点(
X
w
X_w
Xw,
Y
w
Y_w
Yw,
Z
w
Z_w
Zw)与其在图像坐标系中的投影(u,v)相关的方程式如下所示:
![[OpenCV实战]38 基于OpenCV的相机标定](https://www.ccppcoding.com/wp-content/uploads/aHR0cHM6Ly93d3cubGVhcm5vcGVuY3YuY29tL3dwLWNvbnRlbnQvcWwtY2FjaGUvcXVpY2tsYXRleC5jb20tZWM1M2EzN2Y4MGZiY2EzNjA0YzVmYzg5ZDgwM2I4MzdfbDMucG5n.png)
其中如下图所示,***P***是一个由两部分组成的3×4投影矩阵。包含内在参数的内参矩阵(K)和由3×3旋转矩阵***R***和3×1平移向量***t***组合而成的外参矩阵)。
![[OpenCV实战]38 基于OpenCV的相机标定](https://www.ccppcoding.com/wp-content/uploads/aHR0cHM6Ly93d3cubGVhcm5vcGVuY3YuY29tL3dwLWNvbnRlbnQvcWwtY2FjaGUvcXVpY2tsYXRleC5jb20tMTRhMWZkYTM2M2Y5MDM1OGM0ODEzMTA2YzYxZDQzNDVfbDMucG5n.png)
如前文所述,内参矩阵K是上三角矩阵
![[OpenCV实战]38 基于OpenCV的相机标定](https://www.ccppcoding.com/wp-content/uploads/aHR0cHM6Ly93d3cubGVhcm5vcGVuY3YuY29tL3dwLWNvbnRlbnQvcWwtY2FjaGUvcXVpY2tsYXRleC5jb20tZTg4OWNmYWZhYzJkM2E1ZDI2OGQyZGZiODA2MzU5NmFfbDMucG5n.png)
其中:
-
f
x
f_x
fx,f
y
f_y
fy是x和y焦距(是的,它们通常是相同的)。 c
x
c_x
cx,c
y
c_y
cy是图像平面上光学中心的x和y坐标。使用图像的中心通常是一个足够好的近似。γ
gamma
γ是轴之间的倾斜度。通常是0。
3.2 相机标定的目标
标定过程的目标是使用一组已知的三维点(
X
w
X_w
Xw,
Y
w
Y_w
Yw,
Z
w
Z_w
Zw)及其对应的图像坐标(u、v),找到3×3矩阵K、3×3旋转矩阵R、3×1平移向量T。当我们得到相机的内部和外部参数值时,相机就被称为标定相机。总之,相机标定算法具有以下输入和输出:
- 输入:具有已知二维图像坐标和三维世界坐标的点的图像集合。
- 输出:3×3相机内参矩阵,每幅图像的旋转和平移。
注意OpenCV中,相机内部矩阵不包含倾斜参数。所以矩阵的形式是:
![[OpenCV实战]38 基于OpenCV的相机标定](https://www.ccppcoding.com/wp-content/uploads/aHR0cHM6Ly93d3cubGVhcm5vcGVuY3YuY29tL3dwLWNvbnRlbnQvcWwtY2FjaGUvcXVpY2tsYXRleC5jb20tZDI5MjdiODQxZjllNTVkNWE2MGE5ZWY0NjZhMTRiZWJfbDMucG5n.png)
3.3 不同类型的相机标定方法
以下是主要的相机标定方法:
- 校正:当我们完全控制成像过程时,执行校准的最佳方法是从不同的视角捕获一个物体或已知尺寸模式的多个图像。我们将在这篇文章中学习的基于棋盘的方法属于这一类。我们也可以使用已知尺寸的圆形图案,而不是棋盘格图案。
- 几何线索:有时我们在场景中有其他的几何线索,如直线和消失点,可以用来标定。
- 基于深度学习的:当我们对成像设置的控制非常小(例如,我们有场景的单个图像)时,仍然可以使用基于深度学习的方法获取相机的校准信息。
4 相机标定示例步骤
标定示例过程用下面给出的流程图来解释。
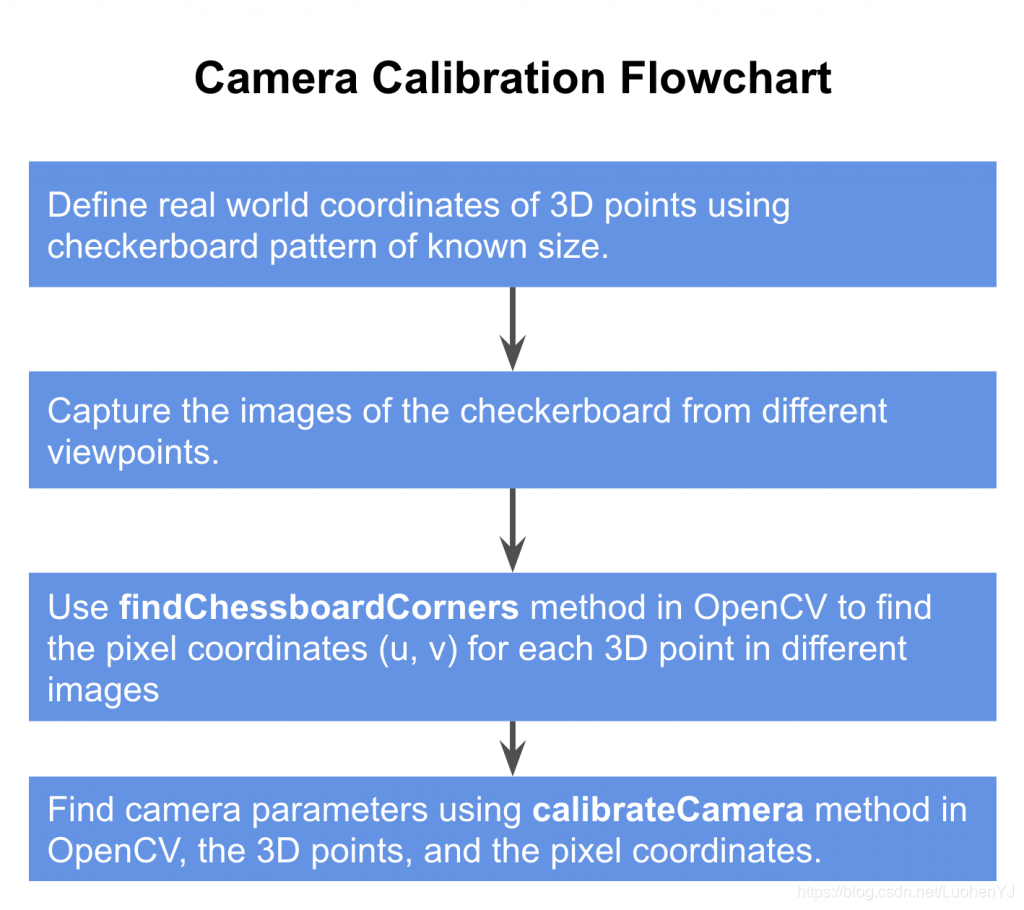
- 使用棋盘格模式定义真实世界坐标;
- 从不同的角度捕获棋盘的多个图像;
- 查找棋盘的2D坐标;
- 校准相机
我们来看看这些步骤。
4.1 使用棋盘格模式定义真实世界坐标
世界坐标系:我们的世界坐标是由以下这个棋盘格图案固定的,这个棋盘格图案附着在房间的墙上。我们的三维点是棋盘中正方形的角。上面的任何一角都可以选择到世界坐标系的原点。
X
w
X_w
Xw和
Y
w
Y_w
Yw轴沿墙,并且
Z
w
Z_w
Zw垂直于墙。因此,棋盘上的所有点都在XY平面上(即
Z
w
Z_w
Zw=0)。
![[OpenCV实战]38 基于OpenCV的相机标定](https://www.ccppcoding.com/wp-content/uploads/aHR0cHM6Ly93d3cubGVhcm5vcGVuY3YuY29tL3dwLWNvbnRlbnQvdXBsb2Fkcy8yMDIwLzAyL2ltYWdlXzIuanBn.png)
在标定过程中,我们通过一组已知的3D点(
X
w
X_w
Xw,
Y
w
Y_w
Yw,
Z
w
Z_w
Zw)和它们在图像中对应的像素位置(u,v)来计算相机参数。
对于三维点,我们在许多不同的方向拍摄具有已知尺寸的棋盘格图案。世界坐标被附加到棋盘上,因为所有的角点都在一个平面上,所以我们可以任意选择
Z
w
Z_w
Zw。因为每个点的
Z
w
Z_w
Zw都是0。
由于点在棋盘中的间距相等,(
X
w
X_w
Xw,
Y
w
Y_w
Yw)每个3D点的坐标很容易定义,方法是将一个点作为参考点(0,0),并定义相对于该参考点的剩余坐标。
绘制检测到的棋盘角后的结果如下图所示:

为什么棋盘格模式在校准中应用如此广泛?
棋盘图案是独特的,易于检测的图像。不仅如此,棋盘格上正方形的角点非常适合定位它们,因为它们在两个方向上都有尖锐的梯度。此外,这些角也与它们位于棋盘格线的交点有关。所有这些事实都被用来在棋盘格模式中可靠地定位正方形的角点。
4.2 从不同的角度捕获棋盘的多个图像
接下来,我们保持棋盘格静止,通过移动相机拍摄棋盘格的多个图像。或者,我们也可以保持相机恒定,在不同方向拍摄棋盘格图案。这两种情况在数学上是相似的。拍摄效果如下图所示:

4.3 查找棋盘的2D坐标
我们现在有多个棋盘的图像。我们还知道棋盘上的点在世界坐标系中的三维位置。最后一件事是图像中这些棋盘格角点的二维像素位置。
4.3.1 查找棋盘角点
OpenCV提供了一个名为findChessboardCorners的内置函数,该函数查找棋盘并返回角点的坐标。让我们看看下面代码块中的用法。
C++
bool findChessboardCorners(InputArray image, Size patternSize, OutputArray corners, int flags = CALIB_CB_ADAPTIVE_THRESH + CALIB_CB_NORMALIZE_IMAGE )
Python
retval, corners = cv2.findChessboardCorners(image, patternSize, flags)
主要参数如下:
| 参数 | 含义 |
|---|---|
| image | 棋盘源图像。它必须是8位灰度或彩色图像 |
| patternSize | 每个棋盘行和列的内角点数 ( patternSize = cvSize (points_per_row, points_per_colum) = cvSize(columns,rows)) |
| corners | 检测到的角点的输出数组 |
| flags | 各种操作标志。只有当事情不顺利的时候你才需要担心这些。使用默认值 |
输出是真是假取决于是否检测到角点。
4.3.2 优化棋盘角点
好的校准都是为了精确。为了获得良好的效果,获得亚像素级精度的角点位置非常重要。
OpenCV的cornersubix函数接收原始图像和角点的位置,并在原始位置的一个小邻域内寻找最佳角点位置。算法本质上是迭代的,因此我们需要指定终止条件(例如迭代次数和/或精度)。
C++
void cornerSubPix(InputArray image, InputOutputArray corners, Size winSize, Size zeroZone, TermCriteria criteria)
Python
cv2.cornerSubPix(image, corners, winSize, zeroZone, criteria)
主要参数如下:
| 参数 | 含义 |
|---|---|
| image | 输入图像 |
| corners | 输入角的初始坐标和为输出提供的精确坐标 |
| WinSize | 搜索窗口边长的一半 |
| zeroZone | 搜索区域中间零区大小的一半,在该零区上不进行下式求和。它有时用于避免自相关矩阵的可能奇点。(-1,-1)的值表示没有这样的大小 |
| criteria | 角点精化迭代过程的终止准则。也就是说,在criteria.maxCount迭代之后或在某些迭代中角位置移动小于criteria.epsilon时,角位置求精过程停止 |
4.4 校准相机
校准的最后一步是将世界坐标系中的3D点及其在所有图像中的2D位置传递给OpenCV的caliberecamera方法。该实现基于Zhang Zhengyou的一篇论文。数学有点复杂,需要有线性代数背景。让我们看一下calibrateCamera:
C++
double calibrateCamera(InputArrayOfArrays objectPoints, InputArrayOfArrays imagePoints, Size imageSize, InputOutputArray cameraMatrix, InputOutputArray distCoeffs, OutputArrayOfArrays rvecs, OutputArrayOfArrays tvecs)
Python
retval, cameraMatrix, distCoeffs, rvecs, tvecs = cv2.calibrateCamera(objectPoints, imagePoints, imageSize)
主要参数如下:
| 参数 | 含义 |
|---|---|
| objectPoints | 三维图像点的矢量 |
| imagePoints | 二维图像点的矢量 |
| imageSize | 图像大小 |
| cameraMatrix | 内参矩阵 |
| distCoeffs | 透镜畸变系数 |
| rvecs | 用于表达旋转的3×1矢量。矢量的方向指定旋转轴,矢量的大小指定旋转角度 |
| tvecs | 用于表达位移的3×1矢量,与rvecs类似 |
5 结果与代码
实际上就是输出内参矩阵和一系列系数。所有代码见:
https://github.com/luohenyueji/OpenCV-Practical-Exercise
C++
#include <opencv2/opencv.hpp>
#include <stdio.h>
#include <iostream>
using namespace std;
using namespace cv;
// Defining the dimensions of checkerboard
// 定义棋盘格的尺寸
int CHECKERBOARD[2]{ 6,9 };
int main()
{
// Creating vector to store vectors of 3D points for each checkerboard image
// 创建矢量以存储每个棋盘图像的三维点矢量
std::vector<std::vector<cv::Point3f> > objpoints;
// Creating vector to store vectors of 2D points for each checkerboard image
// 创建矢量以存储每个棋盘图像的二维点矢量
std::vector<std::vector<cv::Point2f> > imgpoints;
// Defining the world coordinates for 3D points
// 为三维点定义世界坐标系
std::vector<cv::Point3f> objp;
for (int i{ 0 }; i < CHECKERBOARD[1]; i++)
{
for (int j{ 0 }; j < CHECKERBOARD[0]; j++)
{
objp.push_back(cv::Point3f(j, i, 0));
}
}
// Extracting path of individual image stored in a given directory
// 提取存储在给定目录中的单个图像的路径
std::vector<cv::String> images;
// Path of the folder containing checkerboard images
// 包含棋盘图像的文件夹的路径
std::string path = "./images/*.jpg";
// 使用glob函数读取所有图像的路径
cv::glob(path, images);
cv::Mat frame, gray;
// vector to store the pixel coordinates of detected checker board corners
// 存储检测到的棋盘转角像素坐标的矢量
std::vector<cv::Point2f> corner_pts;
bool success;
// Looping over all the images in the directory
// 循环读取图像
for (int i{ 0 }; i < images.size(); i++)
{
frame = cv::imread(images[i]);
if (frame.empty())
{
continue;
}
if (i == 40)
{
int b = 1;
}
cout << "the current image is " << i << "th" << endl;
cv::cvtColor(frame, gray, cv::COLOR_BGR2GRAY);
// Finding checker board corners
// 寻找角点
// If desired number of corners are found in the image then success = true
// 如果在图像中找到所需数量的角,则success = true
// opencv4以下版本,flag参数为CV_CALIB_CB_ADAPTIVE_THRESH | CV_CALIB_CB_FAST_CHECK | CV_CALIB_CB_NORMALIZE_IMAGE
success = cv::findChessboardCorners(gray, cv::Size(CHECKERBOARD[0], CHECKERBOARD[1]), corner_pts, CALIB_CB_ADAPTIVE_THRESH | CALIB_CB_FAST_CHECK | CALIB_CB_NORMALIZE_IMAGE);
/*
* If desired number of corner are detected,
* we refine the pixel coordinates and display
* them on the images of checker board
*/
// 如果检测到所需数量的角点,我们将细化像素坐标并将其显示在棋盘图像上
if (success)
{
// 如果是OpenCV4以下版本,第一个参数为CV_TERMCRIT_EPS | CV_TERMCRIT_ITER
cv::TermCriteria criteria(TermCriteria::EPS | TermCriteria::Type::MAX_ITER, 30, 0.001);
// refining pixel coordinates for given 2d points.
// 为给定的二维点细化像素坐标
cv::cornerSubPix(gray, corner_pts, cv::Size(11, 11), cv::Size(-1, -1), criteria);
// Displaying the detected corner points on the checker board
// 在棋盘上显示检测到的角点
cv::drawChessboardCorners(frame, cv::Size(CHECKERBOARD[0], CHECKERBOARD[1]), corner_pts, success);
objpoints.push_back(objp);
imgpoints.push_back(corner_pts);
}
//cv::imshow("Image", frame);
//cv::waitKey(0);
}
cv::destroyAllWindows();
cv::Mat cameraMatrix, distCoeffs, R, T;
/*
* Performing camera calibration by
* passing the value of known 3D points (objpoints)
* and corresponding pixel coordinates of the
* detected corners (imgpoints)
*/
// 通过传递已知3D点(objpoints)的值和检测到的角点(imgpoints)的相应像素坐标来执行相机校准
cv::calibrateCamera(objpoints, imgpoints, cv::Size(gray.rows, gray.cols), cameraMatrix, distCoeffs, R, T);
// 内参矩阵
std::cout << "cameraMatrix : " << cameraMatrix << std::endl;
// 透镜畸变系数
std::cout << "distCoeffs : " << distCoeffs << std::endl;
// rvecs
std::cout << "Rotation vector : " << R << std::endl;
// tvecs
std::cout << "Translation vector : " << T << std::endl;
return 0;
}
Python
#!/usr/bin/env python
import cv2
import numpy as np
import glob
# Defining the dimensions of checkerboard
CHECKERBOARD = (6,9)
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30, 0.001)
# Creating vector to store vectors of 3D points for each checkerboard image
objpoints = []
# Creating vector to store vectors of 2D points for each checkerboard image
imgpoints = []
# Defining the world coordinates for 3D points
objp = np.zeros((1, CHECKERBOARD[0]*CHECKERBOARD[1], 3), np.float32)
objp[0,:,:2] = np.mgrid[0:CHECKERBOARD[0], 0:CHECKERBOARD[1]].T.reshape(-1, 2)
prev_img_shape = None
# Extracting path of individual image stored in a given directory
images = glob.glob('./images/*.jpg')
for fname in images:
img = cv2.imread(fname)
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
# Find the chess board corners
# If desired number of corners are found in the image then ret = true
ret, corners = cv2.findChessboardCorners(gray, CHECKERBOARD, cv2.CALIB_CB_ADAPTIVE_THRESH+
cv2.CALIB_CB_FAST_CHECK+cv2.CALIB_CB_NORMALIZE_IMAGE)
"""
If desired number of corner are detected,
we refine the pixel coordinates and display
them on the images of checker board
"""
if ret == True:
objpoints.append(objp)
# refining pixel coordinates for given 2d points.
corners2 = cv2.cornerSubPix(gray,corners,(11,11),(-1,-1),criteria)
imgpoints.append(corners2)
# Draw and display the corners
img = cv2.drawChessboardCorners(img, CHECKERBOARD, corners2,ret)
#cv2.imshow('img',img)
#cv2.waitKey(0)
cv2.destroyAllWindows()
h,w = img.shape[:2]
"""
Performing camera calibration by
passing the value of known 3D points (objpoints)
and corresponding pixel coordinates of the
detected corners (imgpoints)
"""
ret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(objpoints, imgpoints, gray.shape[::-1],None,None)
print("Camera matrix : n")
print(mtx)
print("dist : n")
print(dist)
print("rvecs : n")
print(rvecs)
print("tvecs : n")
print(tvecs)
6 参考
https://www.learnopencv.com/geometry-of-image-formation/
https://www.learnopencv.com/camera-calibration-using-opencv/
原文链接: https://www.cnblogs.com/luohenyueji/p/16970281.html
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍;
也有高质量的技术群,里面有嵌入式、搜广推等BAT大佬
![[OpenCV实战]38 基于OpenCV的相机标定](https://www.ccppcoding.com/wp-content/uploads/2023020407005197.bmp)
原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/371619
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!