
本文参考: https://blog.csdn.net/luoshixian099/article/details/50217655
https://blog.csdn.net/fandq1223/article/details/53175964
本文包括以下几个部分:
RANSAC定义
RANSAC原理
RANSAC过程
RANSAC应用
1. 定义
RANSAC是“RANdom SAmple Consensus(随机抽样一致)”的缩写。原本是用于数据处理的一种经典算法,其作用是在大量噪声情况下,提取物体中特定的成分。它可以从一组包含“局外点”的观测数据集中,通过迭代方式估计数学模型的参数, 可以改善最小二乘法在有异常数据时拟合的缺陷。它是一种不确定的算法——它有一定的概率得出一个合理的结果;为了提高概率必须提高迭代次数。
RANSAC的基本假设是:
(1)数据由“局内点”组成,例如:数据的分布可以用一些模型参数来解释;
(2)“局外点”是不能适应该模型的数据;
(3)除此之外的数据属于噪声。
局外点产生的原因有:噪声的极值;错误的测量方法;对数据的错误假设。
RANSAC也做了以下假设:给定一组(通常很小的)局内点,存在一个可以估计模型参数的过程;而该模型能够解释或者适用于局内点。
2.原理
OpenCV中滤除误匹配对采用RANSAC算法寻找一个最佳单应性矩阵H,矩阵大小为3×3。RANSAC目的是找到最优的参数矩阵使得满足该矩阵的数据点个数最多,通常令h33=1来归一化矩阵。由于单应性矩阵有8个未知参数,至少需要8个线性方程求解,对应到点位置信息上,一组点对可以列出两个方程,则至少包含4组匹配点对。
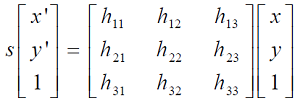

其中(x,y)表示目标图像角点位置,(x',y')为场景图像角点位置,s为尺度参数。
RANSAC算法从匹配数据集中随机抽出4个样本并保证这4个样本之间不共线,计算出单应性矩阵,然后利用这个模型测试所有数据,并计算满足这个模型数据点的个数与投影误差(即代价函数),若此模型为最优模型,则对应的代价函数最小。
3.RANSAC过程
通俗化描述算法过程:
实际上这个算法就是从一堆数据里挑出自己最心仪的数据。所谓心仪当然是有个标准(目标的形式:满足直线方程?满足圆方程?以及能容忍的误差e)。平面中确定一条直线需要2点,确定一个圆则需要3点。随机采样算法,其实就和小女生找男朋友差不多。
- 从人群中随便找个男生,看看他条件怎么样,然后和他谈恋爱,(平面中随机找两个点,拟合一条直线,并计算在容忍误差e中有多少点满足这条直线)
- 第二天,再重新找个男生,看看他条件怎么样,和男朋友比比,如果更好就换新的(重新随机选两点,拟合直线,看看这条直线是不是能容忍更多的点,如果是则记此直线为结果)
- 第三天,重复第二天的行为(循环迭代)
- 终于到了某个年龄,和现在的男朋友结婚(迭代结束,记录当前结果)
显然,如果一个女生按照上面的方法找男朋友,最后一定会嫁一个好的(我们会得到心仪的分割结果)。只要这个模型在直观上存在,该算法就一定有机会把它找到。优点是噪声可以分布的任意广,噪声可以远大于模型信息。
这个算法有两个缺点,第一,必须先指定一个合适的容忍误差e。第二,必须指定迭代次数作为收敛条件。
正规化描述算法过程:
1. 随机从数据集中随机抽出4个样本数据 (此4个样本之间不能共线),计算出变换矩阵H,记为模型M;
2. 计算数据集中所有数据与模型M的投影误差,若误差小于阈值,加入内点集 I ;
3. 如果当前内点集 I 元素个数大于最优内点集 I_best , 则更新 I_best = I,同时更新迭代次数k ;
4. 如果迭代次数大于k,则退出 ; 否则迭代次数加1,并重复上述步骤;
注:
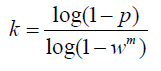
迭代次数k在不大于最大迭代次数的情况下,是在不断更新而不是固定的;其中,p为置信度,一般取0.995;w为"内点"的比例 ; m为计算模型所需要的最少样本数=4;
4. 应用
RANSAC算法筛选SIFT特征匹配
RANSAC 拟合直线(https://lixin97.com/2019/04/10/RANSAC/)
import numpy as np
import matplotlib.pyplot as plt
import random
import math
# 数据量。
SIZE = 50
# 产生数据。np.linspace 返回一个一维数组,SIZE指定数组长度。
# 数组最小值是0,最大值是10。所有元素间隔相等。
X = np.linspace(0, 10, SIZE)
Y = 3 * X + 10
fig = plt.figure()
# 画图区域分成1行1列。选择第一块区域。
ax1 = fig.add_subplot(1,1, 1)
# 标题
ax1.set_title("RANSAC")
# 让散点图的数据更加随机并且添加一些噪声。
random_x = []
random_y = []
# 添加直线随机噪声
for i in range(SIZE):
random_x.append(X[i] + random.uniform(-0.5, 0.5))
random_y.append(Y[i] + random.uniform(-0.5, 0.5))
# 添加随机噪声
for i in range(SIZE):
random_x.append(random.uniform(0,10))
random_y.append(random.uniform(10,40))
RANDOM_X = np.array(random_x) # 散点图的横轴。
RANDOM_Y = np.array(random_y) # 散点图的纵轴。
# 画散点图。
ax1.scatter(RANDOM_X, RANDOM_Y)
# 横轴名称。
ax1.set_xlabel("x")
# 纵轴名称。
ax1.set_ylabel("y")
# 使用RANSAC算法估算模型
# 迭代最大次数,每次得到更好的估计会优化iters的数值
iters = 100000
# 数据和模型之间可接受的差值
sigma = 0.25
# 最好模型的参数估计和内点数目
best_a = 0
best_b = 0
pretotal = 0
# 希望的得到正确模型的概率
P = 0.99
for i in range(iters):
# 随机在数据中红选出两个点去求解模型
sample_index = random.sample(range(SIZE * 2),2)
x_1 = RANDOM_X[sample_index[0]]
x_2 = RANDOM_X[sample_index[1]]
y_1 = RANDOM_Y[sample_index[0]]
y_2 = RANDOM_Y[sample_index[1]]
# y = ax + b 求解出a,b
a = (y_2 - y_1) / (x_2 - x_1)
b = y_1 - a * x_1
# 算出内点数目
total_inlier = 0
for index in range(SIZE * 2):
y_estimate = a * RANDOM_X[index] + b
if abs(y_estimate - RANDOM_Y[index]) < sigma:
total_inlier = total_inlier + 1
# 判断当前的模型是否比之前估算的模型好
if total_inlier > pretotal:
iters = math.log(1 - P) / math.log(1 - pow(total_inlier / (SIZE * 2), 2))
pretotal = total_inlier
best_a = a
best_b = b
# 判断是否当前模型已经符合超过一半的点
if total_inlier > SIZE:
break
# 用我们得到的最佳估计画图
Y = best_a * RANDOM_X + best_b
# 直线图
ax1.plot(RANDOM_X, Y)
text = "best_a = " + str(best_a) + "nbest_b = " + str(best_b)
plt.text(5,10, text,
fontdict={'size': 8, 'color': 'r'})
plt.show()
原文链接: https://www.cnblogs.com/E-Dreamer-Blogs/p/13064351.html
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍;
也有高质量的技术群,里面有嵌入式、搜广推等BAT大佬

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/363537
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!