
KMP理解起来有些困难,所以说,要理解,最重要的地方就是(largeboxed{画图})!!
参照:KMP算法详解
名字来源
(Knuth(D.E.Knuth)&Morris(J.H.Morris)&Pratt(V.R.Pratt))发明KMP算法,因此称作KMP
没错,就是这样,我都不认识
看看这个题(From:Luogu)
题目描述:
给出两个字符串(s_1)和(s_2),若(s_1)的区间([l,r])子串与(s_2)完全相同,则称(s_2)在(s_1)中出现了,其出现位置为(l)。
现在请你求出(s_2)在(s_1)中所有出现的位置。
定义一个字符串(s)的 border 为(s)的一个非(s)本身的子串(t)满足(t既是)s(的前缀,又是)s的后缀
对于(s_2),你还需要求出对于其每个前缀(s')的最长 border (t')的长度
这题,朴素暴力?
期望复杂度(O(n+m))
但是有的毒瘤良心出题人会给你卡成(O(nm))
TLE必不可少
有些地方失配了,暴力的算法会到下一位继续从头开始匹配,而有些是明显不用匹配的
怎么处理呢?
KMP闪亮登场
(KMP)算法:可以实现复杂度为O(m+n)
如何简化了时间复杂度呢?
这个算法充分利用了目标字符串s_2的性质(比如里面部分字符串的重复性,即使不存在重复字段,在比较时,实现最大的移动量)
放一张图来展示(KMP)算法的精髓(来自某本书里):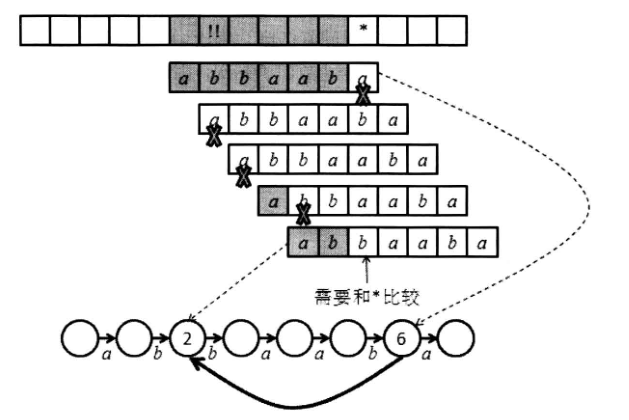

假定在匹配的过程中正在比较文本串(T)((T)为(ababaabbaabbaabab))*位置的字符和模板串(P)((P)为(abbaaba))的最后一个字符,发现二者不同(称为失配)
这时,朴素算法会把模板串右移一位,重新比较(abbaaba)的第一个字符和文本串!!位置的字符。
我们已经知道灰色部分就是(abbaab),可以直接利用模板串本身的特性判断出右移一位一定不是匹配
同理,右移两位或者三位也不行,但是右移四位是有可能的
这个时候,需要比较*处的字符和(abbaaba)的第三个字符
我们创建一个(next)数组,其中(next_i)表示的是前(i)的字符组成的这个子串最长的相同前缀后缀的长度!
例如字符串(ababa)的相同前缀后缀有(aba)和(a),那么其中最长的就是(aba)
至于为什么要选最长的相同前缀后缀,其实是一个贪心的思想
我们要跳(next)数组,必须要保证不能错过任何一个可以匹配的位置,并且跳跃的距离要尽量大
假若我们随便选取一个相同前缀后缀,那么会错过一些地方
--------------------------------------------------------------------分割线--------------------------------------------------------------------------
所以,(P)的(next)数组如下((i)表示当前的位置):

那么如何用(next)数组去匹配呢?
我们再用i表示当前A串要匹配的位置(即还未匹配),j表示当前B串匹配的位置(同样也是还未匹配)
首先从头开始匹配,直到失配
然后再直接将(j)跳转到(next[j])的位置
相信都能写出代码了qwq
然后给出一份代码:
inline void find(char P[],char T[]){
getnext();
j=0; //当前结点编号,初始为0号结点
for(int i=0;i<n;++i){ //文本串当前指针
while(j>0&&P[j]!=T[i]) j=nxt[j]; //如果不匹配,则将利用kmp数组往回跳直到匹配
if(P[j]==T[i]) ++j; //匹配成功就把对应位置++
if(j==m){printf("%dn",i-m+2);j=nxt[j];} //找到了,输出位置,然后继续
}
}
然后就是计算(next)数组
就比如说(P)为(ababax),求(next_5和next_6)
此时我们已经求出了(next_4=2),所以很明显(next[1,2]=next[3,4])
然后,我们又知道了(next_3=next_5),所以,(next[1,3]==next[3,5]),(next_5=next_4+1)
那么(next_6)呢?
显然它不能由(next_5)转移过来,因为(next_3)不等于(next_6)
接着便看能不能由(next[next_5])转移过来,但是也不行
然后是(next[next[next_5]])……套娃
最后推到(next_1)也不行,所以(next_6=0)
神似(find())函数,其实就是(P)和(P)自我匹配的过程
最后给出代码:
inline void getnext(){
nxt[0]=nxt[1]=0; //边界初始化
j=0;
for(int i=1;i<m;++i){ //自己匹配自己
while(j>0&&P[i]!=P[j]) j=nxt[j]; //找到最长的前后缀重叠长度
nxt[i+1]=P[i]==P[j]?++j:0; //不相等的情况,即无前缀能与后缀重叠,直接赋值位0(注意是给下一位,因为匹配的是下一位失配的情况)
}
}
注意:
1.(next_0)和(next_1)都是1
2.这是一个从前往后的推导(类似于dp)
3.若以某一位结尾的子串不存在相同的前缀和后缀,这个位的F置为0
应该解释的很清楚了吧qwq
下面放上完整代码:
#include "bits/stdc++.h"
using namespace std;
const int N=1000005;
char T[N],P[N];
int nxt[N];
int m,n,j;
inline void getnext(){
nxt[0]=nxt[1]=0; //边界初始化
j=0;
for(int i=1;i<m;++i){ //自己匹配自己
while(j>0&&P[i]!=P[j]) j=nxt[j]; //找到最长的前后缀重叠长度
nxt[i+1]=P[i]==P[j]?++j:0; //不相等的情况,即无前缀能与后缀重叠,直接赋值位0(注意是给下一位,因为匹配的是下一位失配的情况)
}
}
inline void find(){
getnext();
j=0; //当前结点编号,初始为0号结点
for(int i=0;i<n;++i){ //文本串当前指针
while(j>0&&P[j]!=T[i]) j=nxt[j]; //如果不匹配,则将利用kmp数组往回跳直到匹配
if(P[j]==T[i]) ++j; //匹配成功就把对应位置++
if(j==m){printf("%dn",i-m+2);j=nxt[j];} //找到了,输出位置,然后继续
}
}
int main(){
scanf("%s %s",T,P);
m=strlen(P),n=strlen(T);
find();
for(int i=1;i<=m;++i) cout<<nxt[i]<<' ';
return 0;
}
习题:Loj103
原文链接: https://www.cnblogs.com/into-qwq/p/13179559.html
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍;
也有高质量的技术群,里面有嵌入式、搜广推等BAT大佬

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/360052
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!