
https://www.luogu.com.cn/blog/greenlcat/solution-p1600
https://www.cnblogs.com/bingdada/p/7744200.html
https://blog.csdn.net/weixin_30911809/article/details/101790074
前前后后认认真真看了三篇博客才终于明白了大概
醉了,醉了
1.这是全局桶的方法
//搞不明白哪里要差分? //桶用来装该深度的点对 对应的 点的贡献 #include<bits/stdc++.h> const int N=3e5+11; using namespace std; int n,m,cnt,head[N],w[N],fa[N]; int son[N],sz[N],dep[N],ans[N]; int num[N],top[N],bucket[N*3]; vector<int> v1[N],v2[N],v3[N]; struct Edge{int nxt,to;}edge[N<<1]; int read(){ int x=0,f=1;char ch=getchar(); while(!isdigit(ch)){if(ch=='-')f=-f;ch=getchar();} while(isdigit(ch)){x=x*10+ch-48;ch=getchar();} return x*f; } void ins(int x,int y){ edge[++cnt].nxt=head[x]; edge[cnt].to=y;head[x]=cnt; } void dfs1(int x,int fat){//父亲、深度、子树大小、重儿子 for(int i=head[x];i;i=edge[i].nxt){ int y=edge[i].to; if(y==fat) continue; fa[y]=x;dep[y]=dep[x]+1; dfs1(y,x);sz[x]+=sz[y]; if(sz[y]>sz[son[x]]) son[x]=y; }++sz[x]; } void dfs2(int x,int topx){//轻重链剖分 top[x]=topx; if(!son[x]) return ; dfs2(son[x],topx); for(int i=head[x];i;i=edge[i].nxt){ int y=edge[i].to; if(y==fa[x]||y==son[x]) continue; dfs2(y,y); } } int Lca(int x,int y){//求lca while(top[x]!=top[y]){ if(dep[top[x]]<dep[top[y]]) swap(x,y); x=fa[top[x]]; }return dep[x]<dep[y]?x:y; } int dis(int x,int y){//两个点路径长度 return dep[x]+dep[y]-(dep[Lca(x,y)]<<1); } void calc1(int x){ int pre=bucket[dep[x]+w[x]+N]; for(int i=head[x];i;i=edge[i].nxt){ int y=edge[i].to; if(y==fa[x]) continue; calc1(y); } bucket[dep[x]+N]+=num[x]; ans[x]+=bucket[dep[x]+w[x]+N]-pre; for(int i=0;i<v1[x].size();i++)//离开以x为根的子树就没有意义了 --bucket[dep[v1[x][i]]+N]; } void calc2(int x){ int pre=bucket[w[x]-dep[x]+N]; for(int i=head[x];i;i=edge[i].nxt){ int y=edge[i].to; if(y==fa[x]) continue; calc2(y); } for(int i=0;i<v3[x].size();i++) ++bucket[dis(x,v3[x][i])-dep[x]+N]; ans[x]+=bucket[w[x]-dep[x]+N]-pre; for(int i=0;i<v2[x].size();i++) --bucket[v2[x][i]+N]; } signed main(){ n=read(),m=read(); for(int i=1;i<n;i++){ int x=read(),y=read(); ins(x,y),ins(y,x); } for(int i=1;i<=n;i++) w[i]=read(); dfs1(1,0);dfs2(1,1); for(int i=1;i<=m;i++){ int x=read(),y=read(); num[x]++; int lca=Lca(x,y); v1[lca].push_back(x); v2[lca].push_back(dis(x,y)-dep[y]); v3[y].push_back(x); if(dep[lca]+w[lca]==dep[x]) --ans[lca]; } calc1(1);calc2(1); for(int i=1;i<=n;i++) printf("%d ",ans[i]); return 0; }
//对于链 1 - 2 - 3 - 4 - 5 - 6 - 7 排序+二分查找
a[i][1]表示从i点出发向右走的路径个数
a[i][0]表示从i点出发向左走的路径个数
枚举每个点j, j - w[j] , j + w[j], 所到达的点, 将数组a的值加进来
例如
1 - 2 - 3 - 4 - 5 - 6 - 7
1 - 5
1 - 7
7 - 2
a[1][1] = 2, a[7][0] = 1
对于4号点,w[4] = 3, 4 - w[4] = 1, 累加a[1][1], 4 + w[4] = 7, 累加a[7][0],
则4点在w[4]这个时刻可以观察到3名人员
//对于一树而言,且起点都是1节点,我们不妨把1作为树的根结点
1
/
2 3
/ /
10 4 5 6
/ /
11 7 8 12
/
9
那么对于i号节点,w[i]必须=dep[i] 才能被观察到,答案就是满足w[i] == dep[i]条件的i的子树
(包含自己)中终点的个数(标记所有的终点), dfs:o(n)
//对于一棵树而言,终点都是1
比如对于节点3而言,w[3] = 2, 7-1, 9-1, 5-1, 7-1, 11-1,是路径,则满足条件的只有子树中的7和8节点,
11节点不做贡献,累加a[7]+a[8] = 2 + 1.
预处理,每一个起点节点的路径条数a[i], 统计子树中是起点且深度为dep[j] + w[j]个数(标记所有起点)。
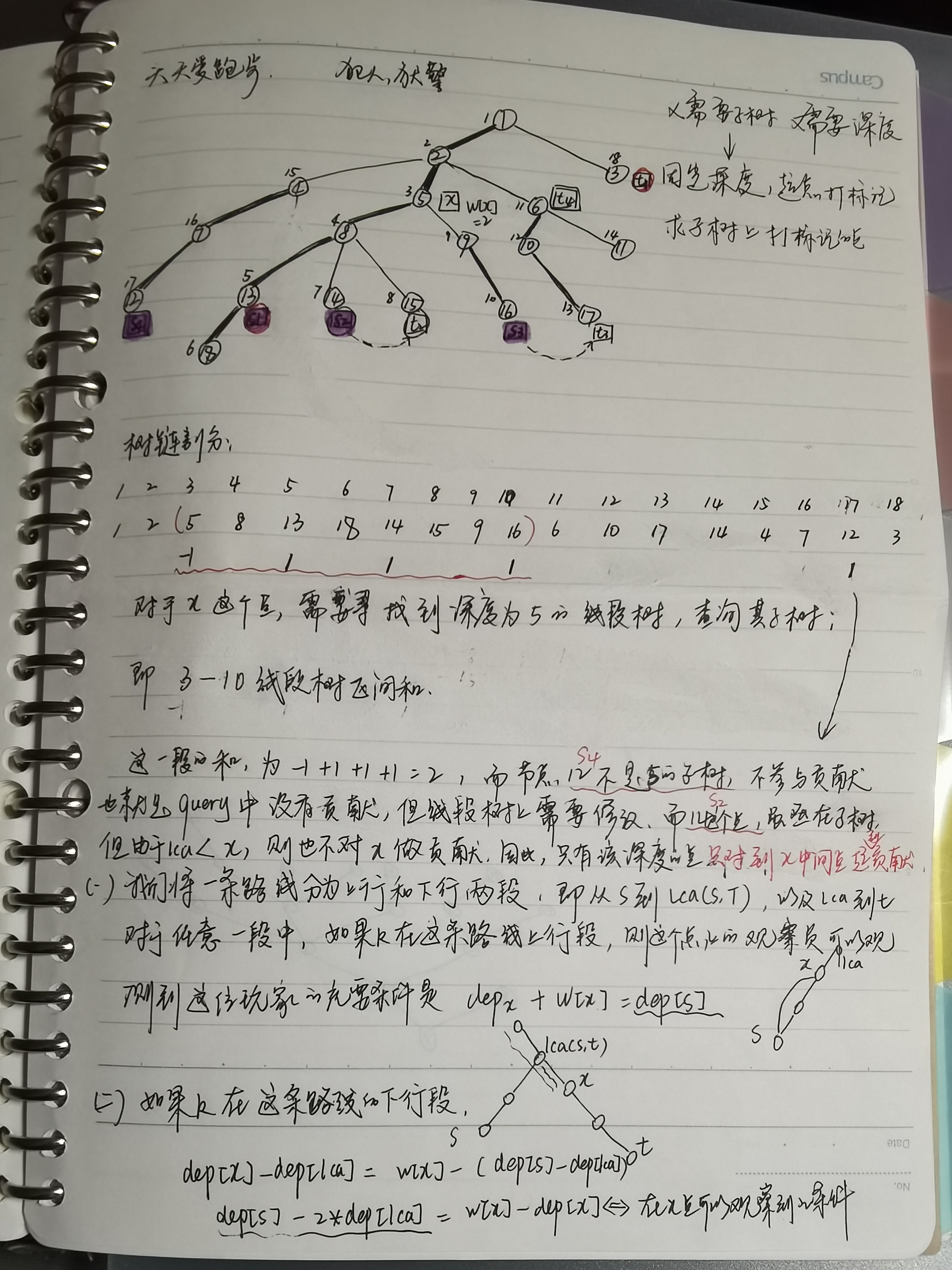

2.这是在每一个深度建立一棵线段树,线段树使用动态开点,思想:树链剖分+差分
#include<iostream> #include<cstdio> #include<cmath> #include<cstring> #include<algorithm> #include<queue> const int mxn = 6e6+5; using namespace std; int cnt,hd[mxn],n,m,tot,_dfn,w[mxn],rt[mxn],ans[mxn],dfn[mxn],fa[mxn],size[mxn],dep[mxn],son[mxn],top[mxn]; struct Edge{ int to,nxt; }edge[mxn]; struct A{ int s, t, lca; }a[mxn]; void add(int u, int v){ cnt++; edge[cnt].to = v; edge[cnt].nxt = hd[u]; hd[u] = cnt; } void dfs1(int u, int ff){ fa[u] = ff, size[u] = 1, dep[u] = dep[ff] + 1; int mx = 0; for(int i = hd[u]; i; i = edge[i].nxt){ int v = edge[i].to; if(v == fa[u]) continue; dfs1(v, u); size[u] += size[v]; if(size[v] > mx) mx = size[v], son[u]= v; } } void dfs2(int u, int tp){ top[u] = tp; dfn[u] = ++_dfn; if(!son[u]) return; dfs2(son[u],top[u]); for(int i = hd[u]; i ; i = edge[i].nxt){ int v = edge[i].to; if(v == fa[u] || v == son[u]) continue; dfs2(v, v); } } struct Node{ int lc,rc,s; }tr[mxn]; void update(int &nod, int l, int r, int k, int val) { if (!k) return;//起点的fa就为0,不参与线段树的修改,如果不这么做,则会寻找到1这个节点,类似于二分查找 if (!nod) nod = ++ tot; if(l == r){ tr[nod].s += val;//this is "+=" return ; } if (l == r) return; int mid = (l + r) >> 1; if (k <= mid) update(tr[nod].lc, l, mid, k, val); else update(tr[nod].rc, mid + 1, r, k, val); tr[nod].s = tr[tr[nod].lc].s + tr[tr[nod].rc].s; } int query(int nod, int l,int r, int ql, int qr){ if(!nod) return 0; if(ql <= l && qr >= r) return tr[nod].s; int mid = (l + r)>>1, res = 0; if(ql <= mid) res += query(tr[nod].lc, l, mid, ql, qr); if(qr > mid) res += query(tr[nod].rc, mid+1, r, ql, qr); return res; } int LCA(int u, int v){ while(top[u] != top[v]){ if(dep[top[u]] < dep[top[v]]) swap(u,v); u = fa[top[u]]; } if(dep[u] < dep[v]) return u; else return v; } int main(){ scanf("%d%d",&n,&m); for(int i = 1,u,v; i <= n-1; i++){ scanf("%d%d",&u,&v); add(u,v); add(v,u); } dfs1(1,0); dfs2(1,1); for(int i = 1; i <= n; i++) scanf("%d",&w[i]); for(int i = 1; i <= m; i++){ scanf("%d",&a[i].s); scanf("%d",&a[i].t); a[i].lca = LCA(a[i].s, a[i].t); } //dep[s]-dep[i] == w[i] up line //dep[i] + w[i] = dep[s] for(int i = 1; i <= m; i++){//类似差分 update(rt[dep[a[i].s]], 1, n, dfn[a[i].s], 1); // cout<<dfn[fa[a[i].lca]]<<endl; update(rt[dep[a[i].s]], 1, n, dfn[fa[a[i].lca]], -1);//巧 // cout<<"hhh2: "<<query(rt[dep[a[i].s]], 1, n, 1, 1)<<endl; } for(int i = 1; i <= n; i++){ ans[i] += query(rt[dep[i] + w[i]], 1, n, dfn[i], size[i] + dfn[i]-1); } tot = 0;memset(tr,0,sizeof tr); memset(rt,0,sizeof rt); //dep[s] + dep[t] - 2*dep[lca] - w[i] = dep[t] - dep[i] down line //dep[s] - 2*dep[lca] + 2 * n = w[i] - dep[i] + 2 * n for(int i = 1; i <= m; i++){ int root = dep[a[i].s] - 2 * dep[a[i].lca] + 2 * n; update(rt[root],1,n,dfn[a[i].t],1); update(rt[root],1,n,dfn[a[i].lca],-1); } for(int i = 1; i <= n; i++) ans[i] += query(rt[ w[i] - dep[i] + 2 * n], 1, n, dfn[i], size[i] + dfn[i] -1); for(int i = 1; i <= n; i++) printf("%d ",ans[i]); return 0; }
题意:给一棵树和 m条路径,树上每个点有一个值 Wi 。问对于每一个点,询问有多少条路径的第 Wi+1个点是这个点。n,m⩽1e5
假设当前路径为s->t,显然我们可以预处理出lca
我们考虑对于每一个节点建立一个权值线段树,以dep为下标,每个节点保存数值i的出现次数,其实我们只需要叶子结点上的信息
用树上差分把链的信息转化为点
现在对于s->lca的路径,只需要在s处的线段树让dep[s]+1,然后每个点统计答案时查询dep[x]+w[x]出现了几次即可
对于lca->t的路径,我们想办法把s关于lca翻上去,在在每个点统计dep=dep[x]-w[x]的点有几个
注意翻上去后d可能变为负的,所以要整体平移一下值域,都加上n即可(其实不平移应该也可以)
```
#include <cstdio>
#include <cctype>
#include <iostream>
#include <algorithm>
using namespace std;
#define rint register int
#define il inline
const int N=3e5+5;
il int read(int x=0,int f=1,char ch='0')
{
while(!isdigit(ch=getchar())) if(ch=='-') f=-1;
while(isdigit(ch)) x=x*10+ch-'0',ch=getchar();
return f*x;
}
int n,m,w[N];
int head[N],ver[N<<1],nxt[N<<1],tot;
il void add(int x,int y){ ver[++tot]=y; nxt[tot]=head[x]; head[x]=tot; }
int dep[N],top[N],son[N],siz[N],fa[N];
void dfs1(int x,int ff)
{
fa[x]=ff; dep[x]=dep[ff]+1; siz[x]=1;
for(rint i=head[x];i;i=nxt[i])
{
int y=ver[i]; if(y==ff) continue;
dfs1(y,x); siz[x]+=siz[y];
if(siz[y]>siz[son[x]]) son[x]=y;
}
}
void dfs2(int x,int topf)
{
top[x]=topf;
if(!son[x]) return ;
dfs2(son[x],topf);
for(rint i=head[x];i;i=nxt[i])
{
int y=ver[i]; if(y==fa[x]||y==son[x]) continue;
dfs2(y,y);
}
}
il int LCA(int x,int y)
{
while(top[x]!=top[y])
{
if(dep[top[x]]<dep[top[y]]) swap(x,y);
x=fa[top[x]];
}
return dep[x]>dep[y] ? y : x;
}
const int M=N*55;
int root[N],lc[M],rc[M],val[M],num;
void update(int &x,int l,int r,int v,int d)
{
if(!x) x=++num;
if(l==r) return (void)(val[x]+=d);
int mid=l+r>>1;
if(v<=mid) update(lc[x],l,mid,v,d);
else update(rc[x],mid+1,r,v,d);
}
int query(int x,int l,int r,int p)
{
if(!x) return 0;
if(l==r) return val[x];
int mid=l+r>>1;
if(p<=mid) return query(lc[x],l,mid,p);
else return query(rc[x],mid+1,r,p);
}
int merge(int a,int b,int l,int r)
{
if(!a || !b) return a+b;
if(l==r)
val[a]+=val[b];
else
{
int mid=l+r>>1;
lc[a]=merge(lc[a],lc[b],l,mid);
rc[a]=merge(rc[a],rc[b],mid+1,r);
}
return a;
}
int ans[N];
void dfs(int x)
{
for(rint i=head[x];i;i=nxt[i])
{
int y=ver[i]; if(y==fa[x]) continue;
dfs(y);
root[x]=merge(root[x],root[y],1,n<<1);
}
if(w[x] && n+dep[x]+w[x]<=2*n)//注意要判断没有越界
ans[x]+=query(root[x],1,n<<1,n+dep[x]+w[x]);
ans[x]+=query(root[x],1,n<<1,n+dep[x]-w[x]);
}
int main()
{
n=read(); m=read();
for(rint i=1,x,y;i<n;++i) x=read(),y=read(),add(x,y),add(y,x);
dfs1(1,0); dfs2(1,1);
for(rint i=1;i<=n;++i) w[i]=read();
for(rint i=1;i<=m;++i)
{
int x=read(),y=read(); int lca=LCA(x,y);
update(root[x],1,n<<1,n+dep[x],1);
update(root[y],1,n<<1,n+dep[lca]*2-dep[x],1);
update(root[lca],1,n<<1,n+dep[x],-1);
update(root[fa[lca]],1,n<<1,n+dep[lca]*2-dep[x],-1);
}
dfs(1);
for(rint i=1;i<=n;++i)
printf("%d ",ans[i]);
return 0;
}```
原文链接: https://www.cnblogs.com/caterpillor/p/13179676.html
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍;
也有高质量的技术群,里面有嵌入式、搜广推等BAT大佬

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/357966
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!