
Speedup Techniques Utilized in Modern SAT Solvers −An Analysis in the MIRA Environment
Lewis M.D.T., Schubert T., Becker B.W. (2005) Speedup Techniques Utilized in Modern SAT Solvers. In: Bacchus F., Walsh T. (eds) Theory and Applications of Satisfiability Testing. SAT 2005. Lecture Notes in Computer Science, vol 3569. Springer, Berlin, Heidelberg
第一次提出 IQS思想,并结合应用到ECDB算法之中 (Early Conflict Detection BCP)
Abstract
| This paper describes and compares features and techniques modern SAT solvers utilize to maximize performance. Here we focus on: Implication Queue Sorting (IQS) combined with Early Conflict Detection Based BCP (ECDB); and a modified decision heuristic based on the combination of Variable State Independent Decaying Sum (VSIDS), Berkmin, and Siege’s Variable Move to Front (VMTF). These features were implemented and compared within the framework of the MIRA SAT solver. The efficient implementation and analysis of these features are presented and the speedup and robustness each feature provides is demonstrated. Finally, with everything enabled (ECDB with IQS and advanced decision heuristics), MIRA was able to consistently outperform zChaff and even Forklift on the benchmarks provided, solving 37 out of 111 industrial benchmarks compared to zChaff’s 21 and Forklift’s 28. |
|
译文:本文描述和比较了现代SAT求解器用来最大化性能的特性和技术。
|
| 译文:这些特性是在MIRA SAT求解器的框架内实现和比较的。译文:给出了这些特性的有效实现和分析,并演示了每个特性所提供的加速和鲁棒性。 |
| 译文:最后,在所有功能都被激活的情况下(具有蕴含队列排序和高级决策启发式的ECDB), MIRA能够在所提供的基准测试中始终超过zChaff甚至Forklift,在111个工业基准测试中解决了37个,而zChaff是21个,Forklift是28个。 |
1 Introduction
|
SAT solvers have advanced considerably since the days of the original Davis-Putnam (DP) algorithm [5,6]. While the underlying algorithm has not changed, improvements in its implementation have made it practical. SAT solvers are now commonly used in industrial fields such as EDA. Such features as Early Conflict Detection BCP (ECDB) [4], Conflict Analysis [7], watched literals [1,21], advanced decision heuristics, and others are what have made SAT solvers practical. Now, while these techniques are powerful, they must all be used together in unison, increasing the complexity of modern SAT solvers. This paper tries to clarify and explain many of the features found in modern SAT solvers while including features only found in our MIRA solver such as the novel Implication Queue Sorting (IQS). 译文:本文试图阐明和解释在现代SAT求解器中发现的许多特征,同时包括仅在我们的MIRA求解器中发现的特征,如新的隐含队列排序(IQS)。 |
| The next section focuses on IQS followed by a section on ECDB. Section 4 will discuss the novel hybrid decision heuristic used in MIRA and how random restarts can be used. Section 5 covers conflict analysis and conflict clause database management. After presenting the parts of a solver, a comparison of MIRA and other solvers on Industrial and Handmade benchmarks are given. Lastly, this paper assumes the reader has a good understanding of the inner workings of a SAT solver and it therefore will not present an overview of current SAT solvers. An overview can be found in [16]. |
2 Implication Queue Sorting and the Start of ECDB
|
Before discussing IQS and ECDB directly, it is important to understand some of the reasons for using it. The idea behind ECDB is to find good conflicts while reducing the work the BCP procedure must do in order to find them. However, in most solvers the BCP procedure checks many clauses that will rarely or never lead to a conflict. This is inefficient and slows down the solver. 译文:在直接讨论IQS和ECDB之前,了解使用它的一些原因是很重要的。ECDB背后的想法是找到好的冲突,同时减少BCP过程为了找到它们而必须做的工作。然而,在大多数解决方案中,BCP过程检查许多很少或永远不会导致冲突的子句。这是低效的,并且会降低求解器的速度。 |
|
Normally, the BCP starts by checking all clauses that contain the current decision variable as a watched literal. As it checks these clauses, it will normally find many implications that it will add to the implication queue. When it is done checking the current decision variable it will move on and check the first implication in the implication queue. The problem with this method is that the BCP procedure will check many implications that are unrelated to the current search space. So, to try and reduce the number of implications the BCP must process, MIRA introduces Implication Queue Sorting (IQS). Simply put, the BCP procedure in MIRA uses a heuristic to select which implications to check first from the implication queue. This is in contrast to other solvers which process the implication queue in chronological order. This results in a significant speedup. 译文:BCP首先检查所有包含当前决策变量的子句,这些子句作为被观察的文字。译文:在检查这些子句时,它通常会发现许多蕴含文字并将它们添加到蕴含队列队列之中。译文:检查完当前决策变量后,它将继续检查蕴含队列中的第一个蕴含文字。译文:这种方法的问题是,BCP过程将检查许多与当前搜索空间无关的蕴含文字。 译文:MIRA引入了隐含队列排序(IQS)。简单地说,MIRA中的BCP过程使用启发式从隐含队列中选择首先检查的隐含。这与其他按时间顺序处理隐含队列的解决方案形成了对比。这将导致显著的加速。 |
| However, to realize this speedup, IQS must be implemented efficiently as it is an operation that is performed frequently. Implications are added and removed from the queue often, the queue can grow quite large (100’s of implications), and is reset after every conflict. In MIRA, a reverse VSIDS algorithm is used when selecting the implication to check next.译文:在选择下一步要检查的含义时,使用反向VSIDS算法。 Instead of taking the literal with highest score, MIRA selects the literal whose complement(补语) has the highest score (using the same VSIDS counters as the decision heuristic). 译文:MIRA没有选择得分最高的文字,而是选择其补语得分最高的文字。The idea is that as soon as the BCP starts, the solver is now trying to find a conflict, not solve the problem.译文:这种想法是,一旦BCP启动,解决者就会试图找到冲突,而不是解决问题。 |
| ???没有讲Implication Queue Sorting (IQS)是增么回事?难道只是从传播队列中选一个文字来传播吗?哪一个会与当前的求解空间相关呢?其余的传播文字为什么是与当前求解空间不相关呢? |
  |
| MIRA uses five separate queues to efficiently implement this heuristic as shown above. Implications are added to each queue depending on their score. (score是?如何计算出来的?)。If an implication has a score of 2, it is inserted into queue 2. The counter variable is then incremented to keep track of the number of implications in that queue. This is true for scores 0 to 3. If the score is higher, it is put into queue 4. Using this queue system, it is easy to insert (only one comparison is needed), reset (reset the length of each queue to 0), or select. Selecting from the queues is simple, as the solver takes a literal from the highest nonempty queue. For queues 0 to 3 it can pick any literal, however, if it chooses queue 4, the solver must search the entire queue for the best choice. |
| The aforementioned queue system was developed after observing MIRA on multiple benchmarks. About 90% of the implications added to MIRA’s implication queue have a score of 0. This is significant, because it means that 90% of the implications checked by the BCP procedure have not created or participated in a conflict recently. Note, in MIRA the VSIDS counters are even incremented when a variable is looked at when creating the implication graph. So, if the implication queue contains 100 literals, 90 of them will probably have nothing to do with the current search space. The remaining 10 nonzero score literals are more interesting, and the solver searches these implications first. Queues 1-3 normally take care of approximately 8-9% of the implications, leaving only 0.5-2% of the literals, which are put into the 4th queue. The 4th queue must be searched in a linear manner. Also, when using full ECDB, there is no need for an implication queue for literals with a score of zero as these implications are already in the decision stack and can be checked in chronological order. |
|
译文:上述队列系统是在多个基准测试中观察MIRA后开发的。 译文:添加到MIRA蕴含队列的蕴含文字中,大约90%的蕴含文字得分为0。这是很重要的,因为这意味着通过BCP程序检查的影响中有90%最近没有制造或参与冲突。 译文:注意,在MIRA中,当创建蕴含图时查看变量时,VSIDS计数器甚至会增加。因此,如果隐含队列包含100个字量,其中90个字量可能与当前搜索空间无关。 译文:剩下的10个非零分数更有趣,求解器首先搜索这些含义。队列1-3通常负责大约8-9%的影响,只留下0.5-2%的文字,它们被放到第4个队列中。 译文:必须以线性方式搜索第4个队列。此外,在使用全ECDB时,不需要为得分为零的文字设置隐含队列,因为这些隐含已经在决策堆栈中,可以按时间顺序检查。 |
| 决策堆栈? 如何知道蕴含文字对应的得分?5个queue中的文字是同一层传播结束之后统计计分后加入进去的吗?最终使用那一个?还是陆陆续续都被使用到?——???考脑筋啊! |
| An implication queue can contain multiple conflicts, some more helpful than others. Certain solvers [8] search for multiple conflicts, recording one or multiple conflict clauses. Since MIRA checks implications that are more relevant to the current search space first (relevant as their scores are higher), it should in theory find conflicts that are more related to the current search space. Also, by choosing the implication this way, we are trying to unsatisfy clauses. This helps the BCP procedure find more unit clauses, causing the implication queue to grow faster, aiding ECDB while also giving the IQS algorithm more literals to choose from. |
|
译文:一个隐含队列可以包含多个冲突,有些冲突比其他冲突更有用。译文:某些解决程序[8]搜索多个冲突,记录一个或多个冲突子句。 译文:因为MIRA首先检查与当前搜索空间更相关的蕴含文字(相对计分高的蕴含文字),理论上,它应该可以找到与当前搜索空间更相关的冲突。译文:同时,通过这样选择蕴含文字,我们试图不满足子句。 译文:这有助于BCP过程找到更多的单元子句,从而使隐含队列增长更快,帮助ECDB,同时也给IQS算法提供更多的文字选择。 |
|
The overhead required to implement IQS is quite low. Using the data structure above, literals can be added in constant time. After a conflict, the queues can also be reset in constant time by just resetting the length counter. Approximately 98% of the implications can be added, searched for, and removed in constant time. It is only with the small last group that a linear search must be performed. During testing, this method only searched 1.46 implications on average to decide which literal should be checked by the BCP. This equates to approximately zero overhead, and all functions relating to IQS require only 1% of the computation time (Gprof) which is an insignificant increase when compared to a solver without IQS, as they still need to add and remove literals from an implication queue. |
|
译文:实现蕴含文字排序所需的开销相当低。译文:使用上面的数据结构,可以在常量时间内添加文字。在冲突之后,也可以通过重置长度计数器在常量时间内重置队列。译文:只对最后一组进行线性搜索。 译文:在测试期间,该方法平均只搜索1.46个蕴含文字,以决定BCP应该检查哪个文字。这大约等于零开销,并且所有与IQS(蕴含文字排序)相关的函数只需要1%的计算时间(Gprof),这与没有IQS的求解器相比,增加的时间微不足道。译文:因为它们仍然需要从隐含队列中添加和删除文字。 |
| 没有讲清楚IQS!!! |
3 MIRA and Early Conflict Detection BCP
| To try and reduce the work of the BCP, MIRA introduced ECDB. Certain parts of ECDB have been implemented in other solvers(哪些求解器依据使用了?), but MIRA was the first with a comprehensive implementation. MIRA still uses many of the ideas that zChaff introduced relating to fast BCP and watched literal lists. Building on the ideas from zChaff, MIRA introduced a smarter BCP that detects conflicts sooner by utilizing more of the information available to it when it evaluates a clause, thereby reducing the total number of evaluated clauses. The first part of ECDB was IQS and was described above. The following section will give a quick overview of ECDB. |
|
译文:ECDB的某些部分已经在其他解决方案中实现,但是MIRA是第一个具有全面实现的解决方案。那些求解器依据使用了? 译文:MIRA仍然使用zChaff介绍的关于快速BCP和观察文字列表的许多想法。 译文:基于zChaff的想法,MIRA引入了一个更智能的BCP,它在评估子句时利用更多可用信息,从而更快地检测冲突,从而减少了评估子句的总数。 译文:ECDB的第一部分是IQS(蕴含队列排序),上面已经描述过了。下一节将简要介绍ECDB。 |
3.1 Full ECDB |
|
The ECDB procedure is still similar to zChaff when it traverses the watched literal list of the current decision variable. However, as discussed above, MIRA does not go chronologically through the implication queue like zChaff does, using IQS instead. 译文:ECDB过程在遍历当前决策变量的观察文字列表时仍然类似于zChaff。 译文:然而,如上所述,MIRA并不像zChaff那样按时间顺序排查隐含队列,而是使用IQS。 |
|
Full ECDB also tries to utilize all the information in the implication queue. It does this by using the implication queue during the entire process when evaluating a clause: choosing a new second watched literal; finding conflicts; or new implications. By not ignoring the implication queue during the evaluation of each clause as zChaff does, the BCP procedure can make better decisions when changing watched literals. MIRA will not replace a watched literal with a literal that is falsely defined in the implication queue. This then avoids a re-evaluation of the clause in the near future. Also, in the same manner, the implication queue can aid in the evaluation of a clause detecting unit clauses earlier. This, with the help of IQS, increases the growth rate of the implication queue further aiding the ECDB procedure. This all leads to Full ECDB’s ability to detect conflicts sooner. Details of the implementation and analysis of this ECDB procedure without IQS is discussed in [4]. 译文:Full ECDB还尝试利用隐含队列中的所有信息。 译文:它通过在计算子句的整个过程中使用隐含队列来做到这一点:选择第二个被观察的字元;寻找冲突;或新的蕴含文字。 译文:通过不像zChaff那样在求每个子句时忽略隐含队列,BCP过程可以在更改所观察的文字时做出更好的决定。 译文:MIRA不会用含义队列中定义错误的文字替换被观察的文字。这样就避免了在不久的将来对子句的重新评价。 译文:此外,以同样的方式,隐含队列可以帮助在前面的子句检测单元子句的评估。 译文:在IQS的帮助下,这将提高隐含队列的增长率,进一步帮助ECDB过程。这些都使得ECDB能够更快地检测冲突。 译文:在[4]中详细讨论了该ECDB过程的实现和分析。 |
3.2 Other BCP Features |
| MIRA’s ECDB procedure contains other optimizations. It has a regular ECDB procedure for handling all clauses except single literal clauses. MIRA assigns the literals in these type of clauses to decision level 0 and then restarts. This simplifies the regular ECDB procedure as it can assume every clause has at least 2 literals. |
| 译文:它有一个常规的ECDB过程来处理除单个字面子句之外的所有子句。译文:MIRA将这些子句类型中的文字赋给决策级别0,然后重新启动。译文:这简化了常规的ECDB过程,因为它可以假定每个子句至少有两个字量。 |
| MIRA also contains a second BCP for handling binary clauses that are contained in the original problem. This is done because a Binary BCP procedure consists only of arrays of implications that are forced by a certain decision. These arrays can be processed very fast and efficiently. The Binary BCP is also run first before the regular BCP in order to populate the decision stack with short forcing clauses. This should in theory aid the creation of shorter conflict clauses. This type of optimization is also done in other solvers (e.g. jerusat [12], zChaff 2004 [8]). |
| 译文:MIRA还包含第二个BCP,用于处理原始问题中包含的二进制子句。译文:之所以这样做,是因为二进制BCP过程只包含由特定决策强制执行的含义数组。译文:这些阵列可以被非常快速和有效地处理。译文:二进制BCP也会在常规BCP之前先运行,以便用简短的强制子句填充决策堆栈。译文:这在理论上应该有助于创建更短的冲突条款。译文:这种类型的优化也可以在其他求解器中实现。 |
4 Decision Heuristic and Restarts
|
The next area where MIRA differs from zChaff is related to decision making. MIRA contains 2 decision strategies, but 3 different heuristics. 译文:MIRA包含2种决策策略,但有3种不同的启发式。This is normal as many solvers use multiple decision strategies to improve performance [8,14,15,16]. MIRA’s first decision strategy is a combination of VSIDS [1] and Berkmin [2]. When VSIDS returns a decision with a score of 0, the Berkmin algorithm is used. 译文:当VSIDS返回一个得分为0的决策时,使用Berkmin算法。This is opposite to zChaff as we observed that a large number of decisions made by VSIDS have a score of 0, especially if the counters are reduced frequently. Decisions made with variables with a score of zero are not that helpful. The second decision strategy MIRA uses is VMTF [3]. In MIRA, to further increase the robustness of this strategy, literals that are part of the conflict analysis but do not appear in a conflict clause are moved up in the list by a constant amount, and not to the top like conflict clause literals. 译文:在MIRA中,为了进一步增强该策略的健壮性,作为冲突分析的一部分但没有出现在冲突子句中的文字将在列表中以固定数量上移,而不是像冲突子句文字那样移到顶部。MIRA switches decision strategies every few restarts, normally making thousands of decisions before switching decision strategies. 译文:在MIRA中,为了进一步增强该策略的健壮性,作为冲突分析的一部分但没有出现在冲突子句中的文字将在列表中以固定数量上移,而不是像冲突子句文字那样移到顶部。 |
| 决策策略三点变化:(1)VSIDS+Berkmin计分;(2)参与冲突生成的变元迁移,其中在学习子句中文字移到最前端,路径中途的文字被做固定数量的上移;(3)频繁切换决策变元选择策略; |
5 Conflict Analysis and Clause Deletion
| The conflict analysis algorithm that is used in MIRA is implemented differently than that of zChaff’s in order to handle MIRA’s implication queue, but the results for a give implication graph are the same. 译文:但给出的隐含图的结果是相同的。Both algorithms generate conflict clauses based on the first UIP. The first UIP conflict analysis is well explained in [18]. For a more in-depth look at MIRA’s conflict resolution procedure refer to [4]. |
| While a conflict resolution procedure is an essential part of any modern SAT solver, if left unchecked, the clauses it produces will eventually overwhelm the BCP procedure. MIRA uses a clause aging method which is similar to Berkmin. |
6 Results and Comparisons
| MIRA_V2 was written in C++ and compared against zChaff version 2004.11.15. This comparison was run on an AMD Opteron 2GHz with 4GB of RAM. Benchmarks were selected from the SAT 2004 competition [17]. As there is no source or executable available for Forklift [20], its results were taken directly from the SAT 2004 competition. The machine used there was an Intel 2.4GHz Pentium 4. |
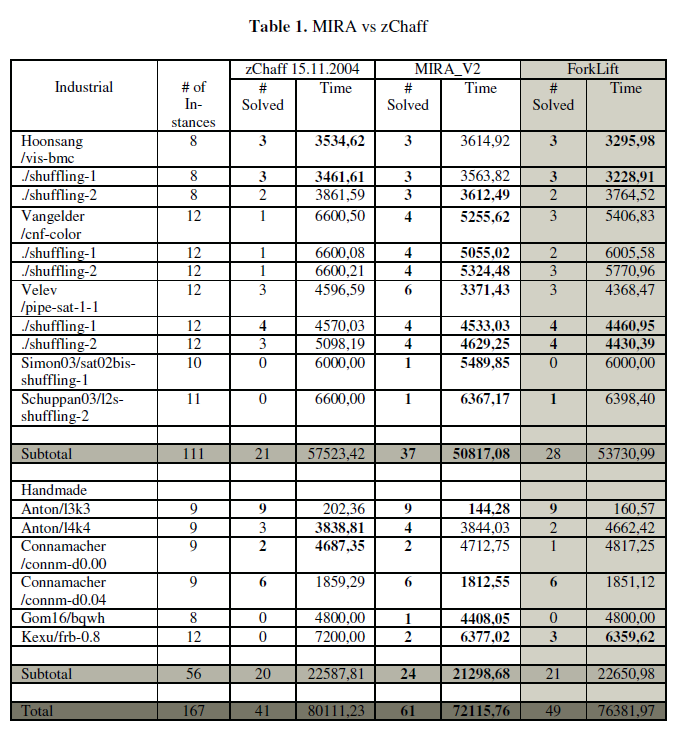 |
| First, Table 1 starts with the more interesting Industrial benchmarks followed by Handmade benchmarks. In the Industrial category MIRA significantly beats zChaff and is more robust and consistent when relating to shuffling.译文:在工业领域,MIRA明显优于zChaff,在洗牌方面更加稳健和一致。 Forklift’s performance is slightly better, matching MIRA’s performance in 5 categories with the same number of problems solved. On problem sets where Forklift tied MIRA on problems solved it was normally slightly faster time wise. However, when it comes to total Industrial problems solved, Forklift is slower. Note again that Forklift was run on a different machine. However, our machine and the Intel machine should produce similar results. As for Handmade benchmarks, MIRA does better than either of the other two solvers, losing to Forklift only once. |
| 对照图表解释说明 |
 |
| Table 2 then shows a feature comparison of MIRA. The benchmarks used for this table are the Industrial benchmarks from Table 1. The results of this table were made by disabling one feature from MIRA at a time to see the impact each feature has on performance. The first column is the reference MIRA version with everything enabled solving 37 problems. The next column is with only random restarts disabled and everything else enabled. As can be seen, random restarts help significantly. The No IQS column is MIRA without IQS, and only without it. Next, with the Binary BCP disabled all clauses are processed with the normal BCP procedure slowing things down. The last two columns compare the two decision strategies. When only VSIDS or VMTF is enabled, there are no second decision strategies or implication queue strategies, only the default VSIDS or VMTF is used. First, MIRA’s performance using only VSIDS is very similar to that of zChaff with respect to the number of problems solved. MIRA’s performance with VMTF is very similar to that of Forklift. The point of this table is to show that without all the features enabled, it is very hard to solve over 30 instances. To solve the hard instances, all features must be enabled. |
7 Conclusion
| This paper presented advanced techniques used in current SAT solvers. It showcased novel ideas developed that allowed MIRA to achieve the performance and robustness that it does. The ideas presented here when used in unison can allow a SAT solver to achieve significant speedup. This was clearly shown in Section 7 when comparing MIRA to other modern solvers. Lastly, this paper was written to try and lower the barrier to entry for new solvers by explaining what current solvers do, hopefully allowing more solvers to be more competitive, and thereby advancing the entire field. |
|
译文:本文介绍了当前SAT求解器的先进技术。译文:这里提出的想法,当使用一致时,可以允许一个SAT求解器实现显著的加速。 译文:在第7节中将MIRA与其他现代求解器进行比较时,这一点得到了清楚的说明。最后,本文试图通过解释当前求解器的作用来降低新求解器的进入壁垒,希望能让更多的求解器更具竞争力,从而推动整个领域的发展 |
References
1. M. W. Moskewicz, C. F. Madigan, Y. Zhao, L. Zhang, and S. Malik, "Chaff: Engineering an Efficient SAT Solver", Proceedings of the 38th DAC, July 2001. 2.
2..E. Goldberg and Y. Novikov, "BerkMin: a Fast and Robust Sat-Solver", DATE 2002, Paris, France, March 2002, pp. 142-149.
3. R. Lawrence, “Efficient Algorithms for Clause-Learning SAT Solvers”, Master’s thesis, Simon Fraser University, February 2004.
4. M. Lewis, T. Schubert, and B. Becker, “Early Conflict Detection Based BCP for SAT Solving”, SAT 2004, May 2004.
5. M. Davis, and H. Putnam, “A Computing Procedure for Quantification Theory”, Journal of the ACM, Vol. 7, Number 3, pp. 201-215, July 1960.
6. M. Davis, G. Logemann, and D. Loveland, “A Machine Program for Theorem-Proving”, Communications of the ACM, vol. 5, pp 394-397, 1962.
7. J. P. Marques-Silva,K. A. Sakallah, "GRASP: A Search Algorithm for Propositional Satisfiability", IEEE Transactions on Computers, Vol. 48, pp. 506-521, 1999.
8. Z. Fu, Y. Mahajan, S. Malik, “New Features of the SAT’04 Version of zChaff”, SAT 2004 Competition: Solver Descriptions, May 2004.
9. A. Biere, “The Evolution from Limmat to Nanosat”, Technical Report 444, Dept. of Computer Science, ETH Zürich, 2004.
10. A. Biere, Limmat Solver, http://www.inf.ethz.ch/personal/biere/projects/limmat/
11. A. Van Gelder, “Generalizations of Watched Literals for Backtracking Search”, 2001.
12. A. Nadel, “The Jerusat SAT Solver” Master’s thesis, Hebrew University of Jerusalem, 2002.
13. I. Lynce, J. and Marques-Silva, "Efficient Data Structures for Fast SAT Solvers", 2001.
14. J. Alfredsson, “The SAT Solver Oepir”, SAT 2004 Competition: Solver Descriptions, 2004.
15. Niklas Eén, Satzoo, http://www.cs.chalmers.se/~een/Satzoo/
16. N. Eén, and N. Sörensson, "An Extensible SAT-solver", SAT 2003, May 5-8 2003.
17. SAT2004, www.satlive.org
18. L. Zhang, C. F. Madigan, M. H. Moskewicz, and S. Malik, "Efficient Conflict Driven Learning in a Boolean Satisfiability Solver", ICCAD 2001.
19. H. Kautz, E. Horvitz, Y. Ruan, C. Gomes, and B. Selman, “Dynamic Restart Policies”. The Eighteenth National Conference on Artificial Intelligence, 2002.
20. E.Goldberg, Y.Novikov, http://eigold.tripod.com/BerkMin.html
21. L. Zhang, and S. Malik, "Cache Performance of SAT Solvers: A Case Study for Efficient Implementation of Algorithms", SAT 2003, May 5-8 2003.
原文链接: https://www.cnblogs.com/yuweng1689/p/13151774.html
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍;
也有高质量的技术群,里面有嵌入式、搜广推等BAT大佬

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/356882
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!