
目标识别的选择性搜索
Selective Search for Object Recognition
论文地址:
https://ivi.fnwi.uva.nl/isis/publications/bibtexbrowser.php?key=UijlingsIJCV2013&bib=all.bib
代码地址:https://github.com/belltailjp/selective_search_py
一.论文解析
摘要
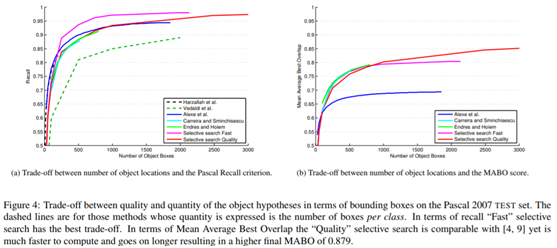
本文讨论了在目标识别中生成可能的目标位置的问题。引入了选择性搜索,结合了穷举搜索和分割的优点。像分割一样,使用图像结构来指导采样过程。像穷举搜索一样,目标是捕获所有可能的目标位置。不再使用单一的技术来生成可能的目标位置,而是使搜索多样化,并使用各种互补的图像分割来处理尽可能多的图像条件。选择性搜索结果是一组数据驱动的、与类无关的、高质量的位置,在10097个位置产生99%的召回率和0.879的平均最佳重叠。与穷举搜索相比,位置数目的减少使得能够使用更强的机器学习技术和更强的外观模型进行对象识别。在本文中,证明了选择性搜索能够使用强大的单词袋模型进行识别。选择性搜索软件是公开提供的。
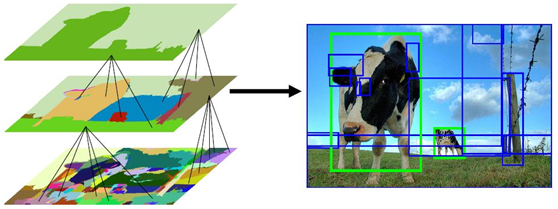

1. 基本原理和贡献
很长一段时间以来,人一直在寻找物体的轮廓,然后才对其进行辨认。这就产生了分割,目标是通过一种通用算法对图像进行独特的分割,即图像中所有对象轮廓都有一个部分。在过去的几年里,对这一课题的研究取得了巨大的进展[3,6,13,26]。但图像本质上是分层的:
在图1a中,沙拉和调羹放在沙拉碗中,然后放在桌子上。此外,根据上下文的不同,本图中的术语表只能指木材或包括表中的所有内容。
因此,图像的性质和对象类别的不同用途都是层次性的。这就禁止了对象的唯一分区,除了最特殊的用途之外。因此,对于大多数任务来说,在一个分段中使用多个尺度是必要的。最自然的解决方法是使用分层分区,如Arbelaez等人所做的那样[3]。
此外,分割应该是分层的,使用单一策略分割的通用解决方案可能根本不存在。一个区域为什么要归在一起,有许多相互矛盾的原因:
在图1b中,猫可以用颜色分开,但质地是一样的。相反,在图1c中,变色龙的颜色与其周围的叶子相似,但其纹理不同。
最后,在图1d中,车轮在颜色和质地上与汽车有着天壤之别,但却被汽车所包围。因此,单个视觉特征无法解决分割的模糊性。
最后,还有一个更根本的问题。具有非常不同特征的区域,例如毛衣上的脸,只有在确定手上的物体是人之后,才能组合成一个物体。因此,如果没有事先的识别,很难确定一张脸和一件毛衣是一个物体的一部分[29]。
这导致了与传统方法相反的情况:通过识别对象来进行本地化。最近这种物体识别方法在不到十年的时间里取得了巨大的进步[8,12,16,35]。通过从示例中学习的外观模型,执行穷举搜索,其中检查图像中的每个位置,以确保不会遗漏任何潜在的对象位置[8、12、16、35]。
然而,穷尽式搜索本身有几个缺点。搜索每个可能的位置在计算上都是不可行的。必须通过使用规则的网格、固定的比例和固定的纵横比来减少搜索空间。在大多数情况下,访问的地点仍然很多,以至于需要实施其他限制。该方法简化了分类器的结构,并且需要快速建立外观模型。此外,均匀采样会产生许多盒子,很明显不支持对象。而不是盲目地使用穷举搜索的抽样地点,一个关键问题是:可以通过数据驱动的分析来控制抽样吗?
在本文中,目标是结合分割和穷举搜索的直觉,提出一个数据驱动的选择性搜索。受自底向上分割的启发,目标是利用图像的结构来生成目标位置。受详尽搜索的启发,目标是捕获所有可能的目标位置。
因此,目标不是使用单一的采样技术,而是使采样技术多样化,以尽可能多地考虑图像条件。具体来说,使用基于数据驱动的分组策略,通过使用各种互补分组准则和具有不同不变性的各种互补颜色空间来增加多样性。通过组合这些互补分区的位置来获得位置集。目标是生成一个独立于类的、数据驱动的、有选择的搜索策略,该策略生成一小组高质量的对象位置。
选择性搜索的应用领域是目标识别。因此,在最常用的数据集上对此进行评估,Pascal VOC检测挑战由20个对象类组成。这个数据集的大小为选择性搜索产生了计算约束。此外,使用这个数据集意味着位置的质量主要是根据边界框来评估的。然而,选择性搜索同样适用于区域,也适用于“草”等概念。
本文提出了一种目标识别的选择性搜索方法。主要研究问题是:
(1) 什么样的多样化策略可以作为选择性搜索策略来适应分割?
(2) 选择性搜索在图像中创建一组小的高质量位置的效果如何?
(3) 可以使用选择性搜索来使用更强大的分类器和外观模型来进行对象识别吗?

2. 研究内容
选择性搜索
在这一节中,详细介绍了目标识别的选择性搜索算法,并提出了各种多样的策略来处理尽可能多的图像条件。选择性搜索算法需要考虑以下设计因素:
捕获所有尺寸范围
对象可以在图像中以任何比例出现。此外,一些对象的边界比其他对象的边界更不清晰。因此,在选择性搜索中,必须考虑所有对象比例,如图2所示。最自然的方法是使用分层算法。
多元化
没有一个单一的最优策略可以将区域组合在一起。如图1所示,区域可以形成一个对象,因为只有颜色,只有纹理,或因为部分是封闭的。此外,诸如阴影和光的颜色等照明条件可能影响区域形成对象的方式。因此,希望有一套不同的策略来处理所有的情况,而不是一个在大多数情况下都很有效的单一策略。
计算速度快
选择性搜索的目标是产生一组可能的目标位置,用于实际的目标识别框架。这个集合的创建不应该成为计算瓶颈,因此算法应该相当快。

本文利用选择性搜索产生的位置进行目标识别。本节详细介绍了对象识别框架。
在目标识别中,两类特征占主导地位:
定向梯度直方图(HOG)[8]和单词袋[7,27]。Felzenszwalb等人将HOG与基于部分的模型结合起来已经证明是成功的 [12] 。然而,由于使用穷举搜索,从计算角度来看,HOG特征与线性分类器结合是唯一可行的选择。
相比之下,选择性搜索能够使用更昂贵和潜在更强大的功能。因此,使用单词包进行对象识别[16,17,34]。然而,使用比[16,17,34]更强大(和昂贵)的实现,通过使用各种颜色筛选描述符[32]和更精细的空间金字塔分割[18]。具体地说,在单个尺度(σ=1.2)上对每个像素的描述符进行采样。利用文献[32]中的软件,提取了SIFT[21]和两个对检测图像结构最敏感的颜色SIFT[31]和RGBSIFT[32]。使用4000大小的视觉码本和4层空间金字塔,使用1x1、2x2、3x3和4x4分区。
这使得特征向量的总长度为360000。在图像分类中,已经使用了这种大小的特征[25,37]。由于空间金字塔比构成HOG描述符的单元产生更粗糙的空间细分,因此特征包含的关于对象的特定空间布局的信息更少。因此,HOG更适合于刚性对象,而特征更适合于可变形对象类型。
作为分类器,使用了一个支持向量机和一个直方图相交核,使用Shogun工具箱[28]。为了应用训练好的分类器,使用了快速、近似的分类策略[22],这对[30]中的袋装词很有效。
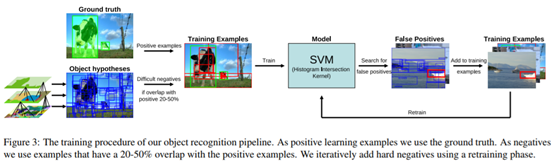
训练程序如图3所示。最初的正面例子由所有地面真值对象窗口组成。作为最初的负面例子,选择性搜索生成的所有对象位置中选择与正面例子重叠20%到50%的位置。为了避免近似重复的负数示例,如果负数示例与另一负数的重叠超过70%,则将其排除。为了使每类的初始负片数保持在20000个以下,随机地将一半的负样本投给汽车、猫、狗和人。直觉上,这组例子可以被看作是困难的否定,接近于积极的例子。
这意味着接近于决策边界,因此很可能成为支持向量,即使考虑了全组否定。事实上,发现这种训练例子的选择给出了相当好的初始分类模型。然后进入一个再训练阶段,迭代地添加硬的否定例子(例如[12]):使用选择性搜索生成的位置将学习到的模型应用到训练集。对于每一张负面图片,都会加上得分最高的位置。由于初始训练集已经产生了好的模型,模型只在两次迭代中收敛。
对于测试集,最终模型将应用于选择性搜索生成的所有位置。窗口按分类器得分排序,与得分较高的窗口重叠超过30%的窗口被视为接近重复项并被删除。
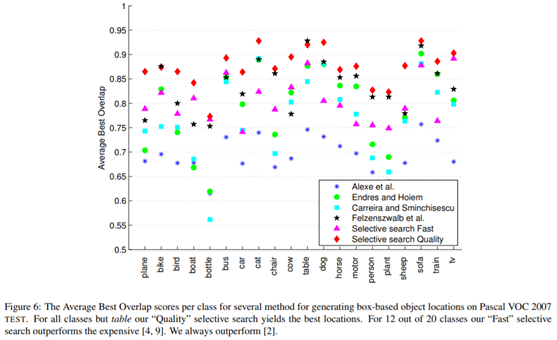
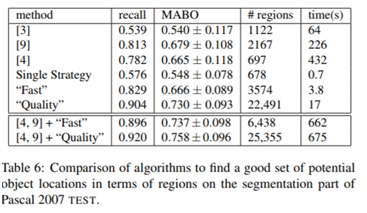
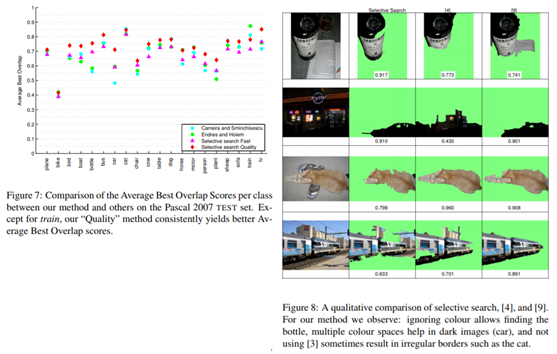
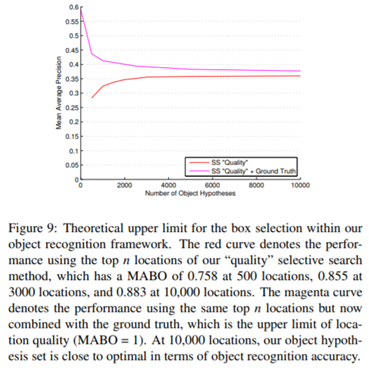
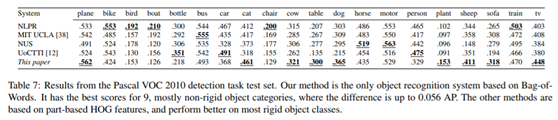
3. 评估测试

二.代码解析
代码地址:https://github.com/belltailjp/selective_search_py
参考代码和实验地址:http://disi.unitn.it/~uijlings/MyHomepage/index.php#page=projects1
概述
这是选择性搜索的python实现[1][2]。
选择搜索作为目标检测/识别流水线的预处理。
发现可能包含来自输入图像的任何对象的区域,而不管其大小和位置如何,这使得检测器只能集中于此类“预期”区域。
因此,可以配置计算效率更高的检测器,或者使用比传统穷举搜索方案更丰富的特征表示和分类方法[3]。
前提条件
- CMake (>= 2.8)
- GCC (>= 4.8.2)
- Python (>= 3.4.3)
- 有关所需的软件包,请参见
requirements.txt - Boost (>= 1.58.0) 使用python支持构建
- Boost.NumPy
- 如果编译报错,请参见 belltailjp/Boost.NumPy)
此外,这只在x64 Linux环境下测试。
准备工作
此实现包含几个C++代码,其封装用于生成初始值的高效基于图形的图像分割[4 ]。作为一个python模块工作,所以首先构建。
% git clone https://github.com/belltailjp/selective_search_py.git
% cd selective_search_py
% wget http://cs.brown.edu/~pff/segment/segment.zip; unzip segment.zip; rm segment.zip
% cmake .
% make
然后将看到一个共享segment.so在目录里。将其保存在主Python脚本的同一目录中,或者保存在LD_LIBRARY_PATH中描述的可引用位置。
演示
交互显示可能包含对象的区域
show candidate demo允许交互查看选择性搜索的结果。
% ./demo_showcandidates.py image.jpg
showcandidate图形用户界面示例
可以在屏幕左侧选择任何参数组合。然后单击“运行”按钮并等待一段时间。将在右侧看到生成的区域。
通过更改底部的滑块,可以增加/减少候选区域的数量。向左滑动的滑块越多,显示的区域越自信,如下所示:
显示候选GUI示例更多区域
显示图像分割层次结构
ShowHierarchy演示为迭代中的每个步骤可视化彩色区域图像。
% ./demo_showhierarchy.py image.jpg --k 500 --feature color texture --color rgb
图像分割层次可视化
如果要查看与输入图像合成的标签,请指定特定的alpha值。
% ./demo_showhierarchy.py image.jpg --k 500 --feature color texture --color rgb --alpha 0.6
概况
该方法的算法在原稿的期刊版([1])中有详细描述。对于多元化策略,本次实施支持按照原论文的建议,改变以下参数。
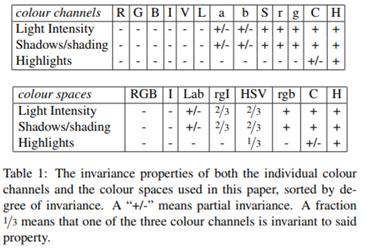
色空间
RGB、Lab、rgI、HSV、归一化RGB和色调
当前不支持颜色不变性的C[5]。
相似性度量
纹理、颜色、填充和大小
初始分割参数k
作为初始(细粒度)分段,此实现使用[4]。k是该方法的参数之一。
可以为每个策略提供任何组合。
如何集成到代码中
如果只想将此实现用作黑盒,则只需要导入选择性搜索模块。
from selective_search import *
img = skimage.io.imread('image.png')
regions = selective_search(img)
for v, (i0, j0, i1, j1) in regions:
然后可以得到一个按分数升序排序的列表区域。得分较高的区域(列表的后一个元素)被视为“非预期”区域,因此可以根据需要将其过滤掉。
要更改参数,只需列出每个多元化战略的价值。注意,必须作为一个列表给出。selective_search返回生成的区域的单个列表,其中包含selective search结果的每个组合。这个结果也被排序。
regions = selective_search(img,
color_spaces = ['rgb', 'hsv'], #color space. should be lower case.
ks = [50, 150, 300], #k.
feature_masks = [(0, 0, 1, 1)]) #indicates whether S/C/T/F similarity is used, respectively.
测试
此实现包含使用PyTest的自动化单元测试。
要执行完整测试,请键入:
% py.test
许可证
这个实现在是公开的。见LICENSE.txt更多细节。
然而,对于选择性搜索方法本身,原论文的作者至今没有提及。
References
[1] J. R. R. Uijlings et al., Selective Search for Object Recognition, IJCV, 2013
[2] Koen van de Sande et al.,
Segmentation As Selective Search for Object Recognition, ICCV, 2011
[3] R. Girshick et al., Rich Feature Hierarchies for Accurate
Object Detection and Semantic Segmentation, CVPR, 2014
[4] P. Felzenszwalb et al., Efficient Graph-Based Image
Segmentation, IJCV, 2004
[5] J. M. Geusebroek et al., Color
invariance, TPAMI, 2001
原文链接: https://www.cnblogs.com/wujianming-110117/p/13152570.html
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍;
也有高质量的技术群,里面有嵌入式、搜广推等BAT大佬

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/356576
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!