
1.定义
图(Graph)是由顶点的有穷非空集合和顶点之间边的集合组成的,通常表示为 (G(V,E)),其中,G 表示一个图,V 是图 G 中顶点的集合,E 是图 G 中边的集合。
在图的定义中,需要注意以下几个点:
- 图中的数据元素称之为顶点(Vertex);
- 在图结构中,不允许没有顶点;
- 在图中,任意两个顶点之间都可能有关系,顶点之间的逻辑关系用边来表示,边集可以是空的;
1.1 有向图
若从顶点 (v_i) 到 (v_j) 的边有方向,则称这条边为有向边,也称为弧。如果图中任意两个顶点之间的边都是有向边,则称该图为有向图。
有向图和树的区别是,有向图不需要指定一个根节点,并且一个节点到另一个节点之间可能存在有好几条(或者没有)路径。有向图是由一个有限的称为顶点(vertices)的集合以及一个有限的连接没对顶点的有向弧或者有向边的集合构成的,其示意图如下:
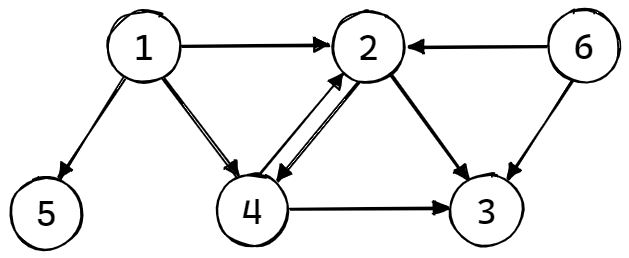

我们称箭头的起始端为出向边,称箭头的末端为入向边。一个顶点出向边的个数称为出度,入向边的个数则称为入度。
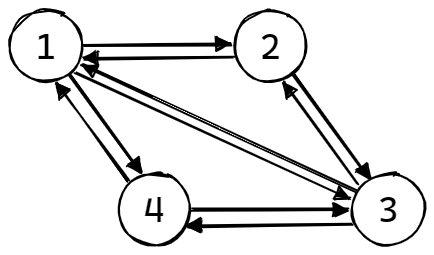
在有向图中,如果任意两个顶点之间都存在方向互为相反的两条弧,则称该图为有向完全图。含有 n 个顶点的有向完全图有 (n*(n-1)) 条边,如下图所示:
1.2 无向图
若从顶点 (v_i) 到 (v_j) 的边没有方向,则称这条边为无向边。如果图中任意两个顶点之间的边都是无向边,则称该图为无向图。
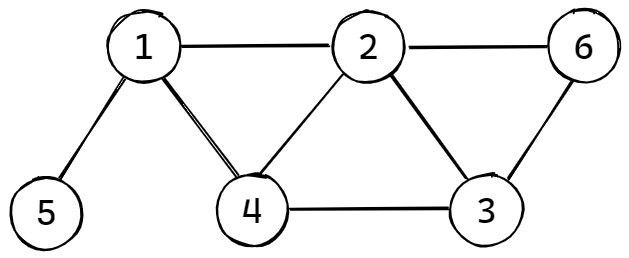
无向图与有向图的区别如下:
- 无向图的边没有出向边和入向边的区分;
- 无向图的顶点没有到达自己顶点位置的边;
在无向图中,一个顶点的边的个数称之为度。
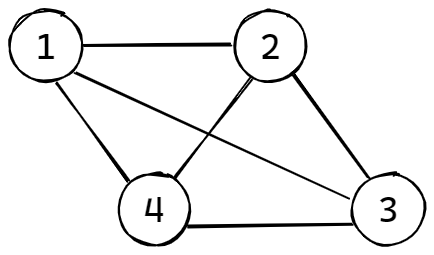
在无向图中,如果任意两个顶点之间都存在边,则称该图为无向完全图,含有 n 个顶点的无向完全图有 ((n*(n-1))/2) 条边,如下图所示:
2.图的存储结构
2.1 邻接矩阵
将有向图中所有的顶点编号为 (1,2,...,n),邻接矩阵就是一个 nxn 的矩阵,如果节点 j 邻接于节点 i(即存在一条有向边从节点 i 指向节点 j),则矩阵中第 i 行第 j 列的元素为 1,否则为 0,其转换过程如下图所示:
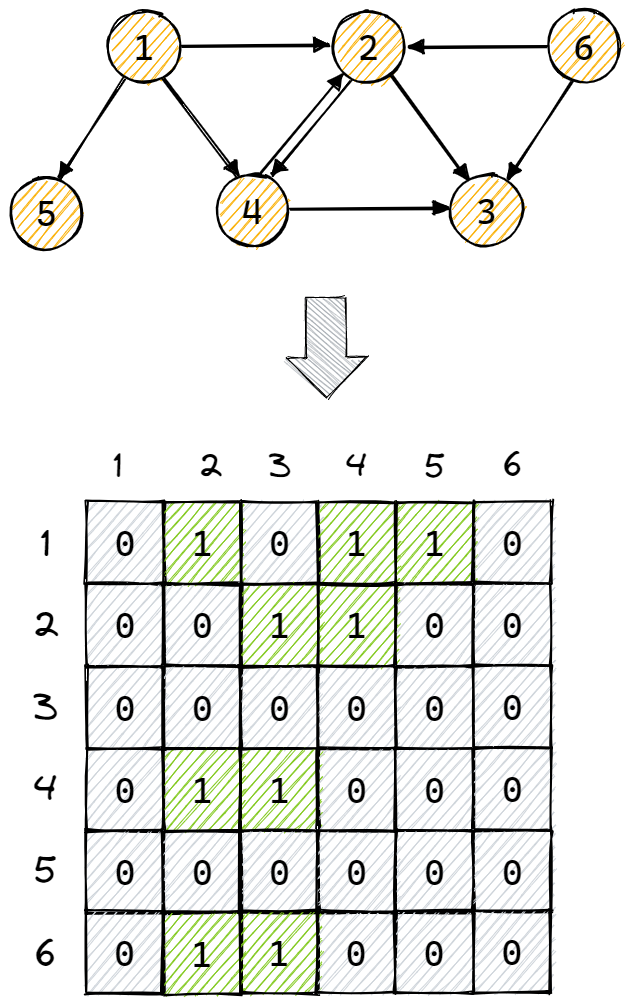
从矩阵中可以看到,横向中 1 的个数即表示该顶点的出度,而竖向中 1 的个数则表示该顶点的入度。
注意,对于带权有向图,在邻接矩阵表示的时候,顶点 i 到顶点 j 的 1 就被 "权值" 所替换。
对于有向图的邻接矩阵而言,如果邻接矩阵是一个稀疏矩阵的话,存储的效率太低,即其空间利用率低。
2.2 邻接表
将有向图表示为一个数组或向量 (v[1],v[2]...v[n]),其中每个元素对应有向图的一个节点,每个 (v[i]) 存储相应顶点中的数据,以及一个包含所有邻接于该顶点的顶点编号的链表,其转换过程如下图所示:
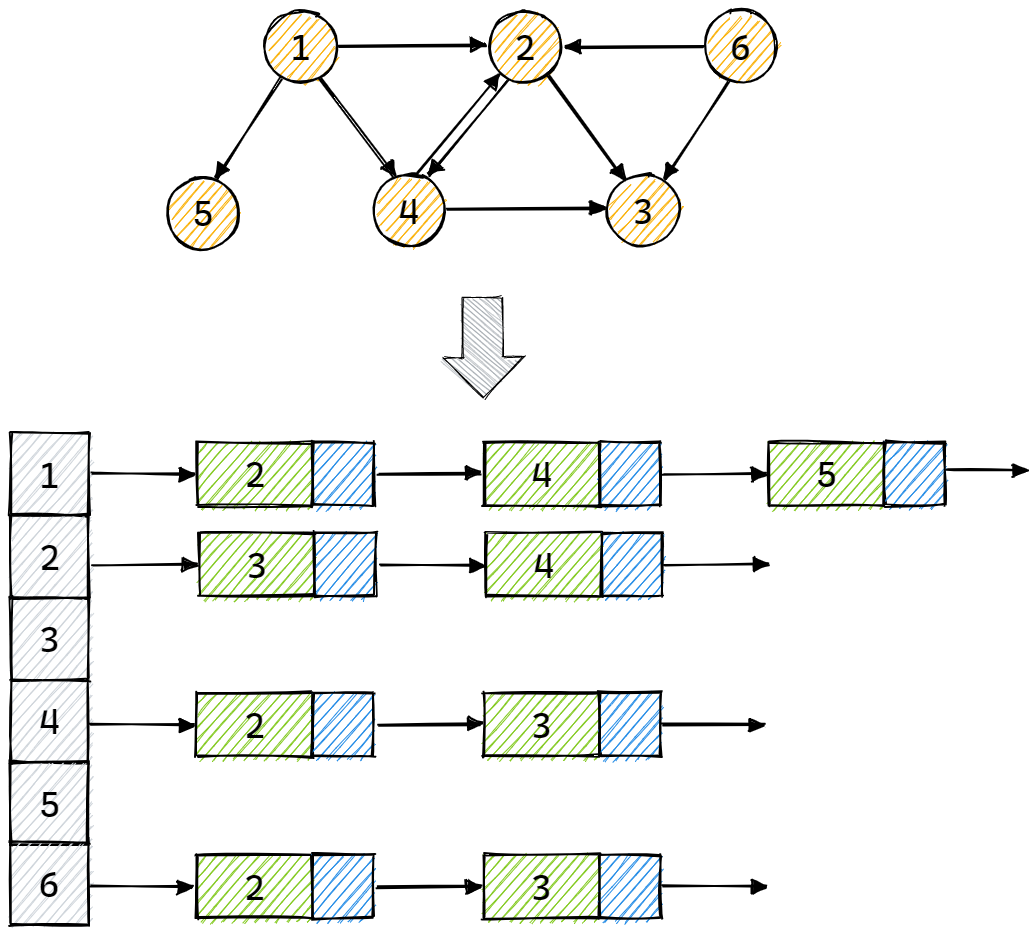
注意,邻接表只描述了顶点的出度,如果需要描述顶点的入度,则需要使用逆邻接表。
2.3 十字链表
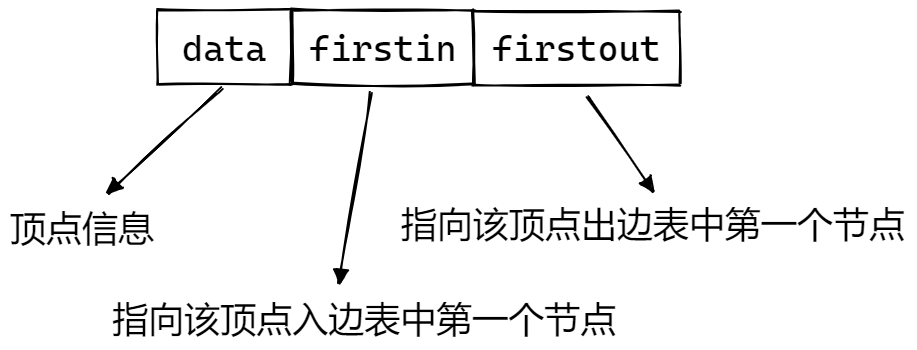
首先,十字链表中含有两种结构,一个是顶点,一个是节点,顶点的结构如下图所示:
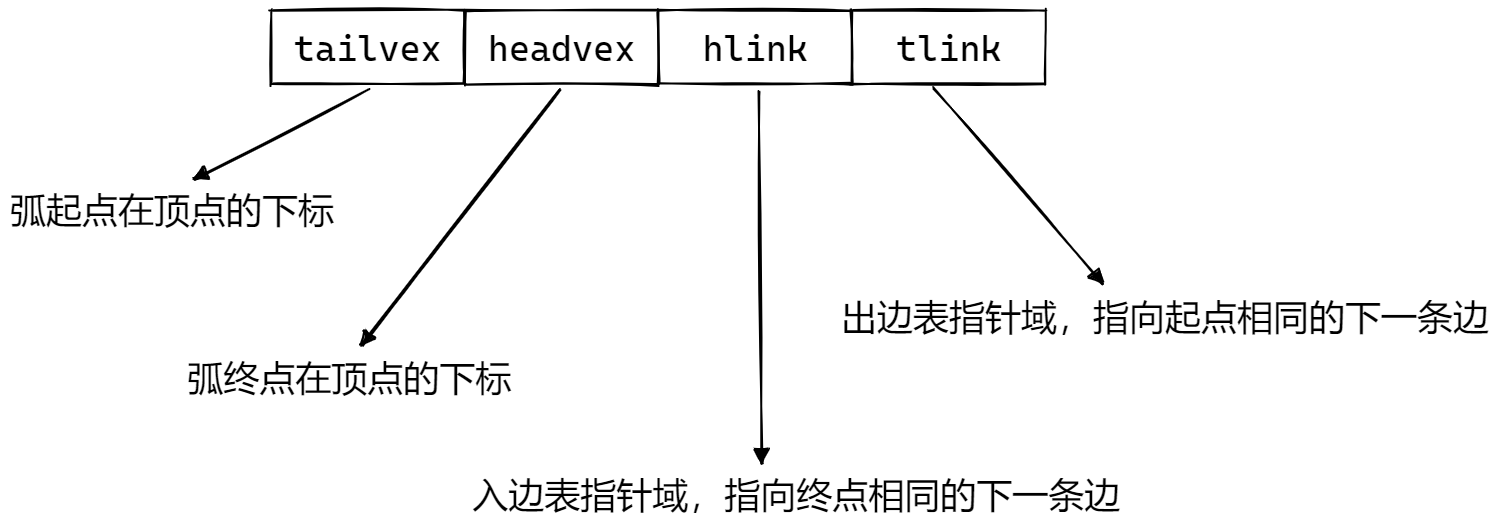
节点的结构则如下图所示:
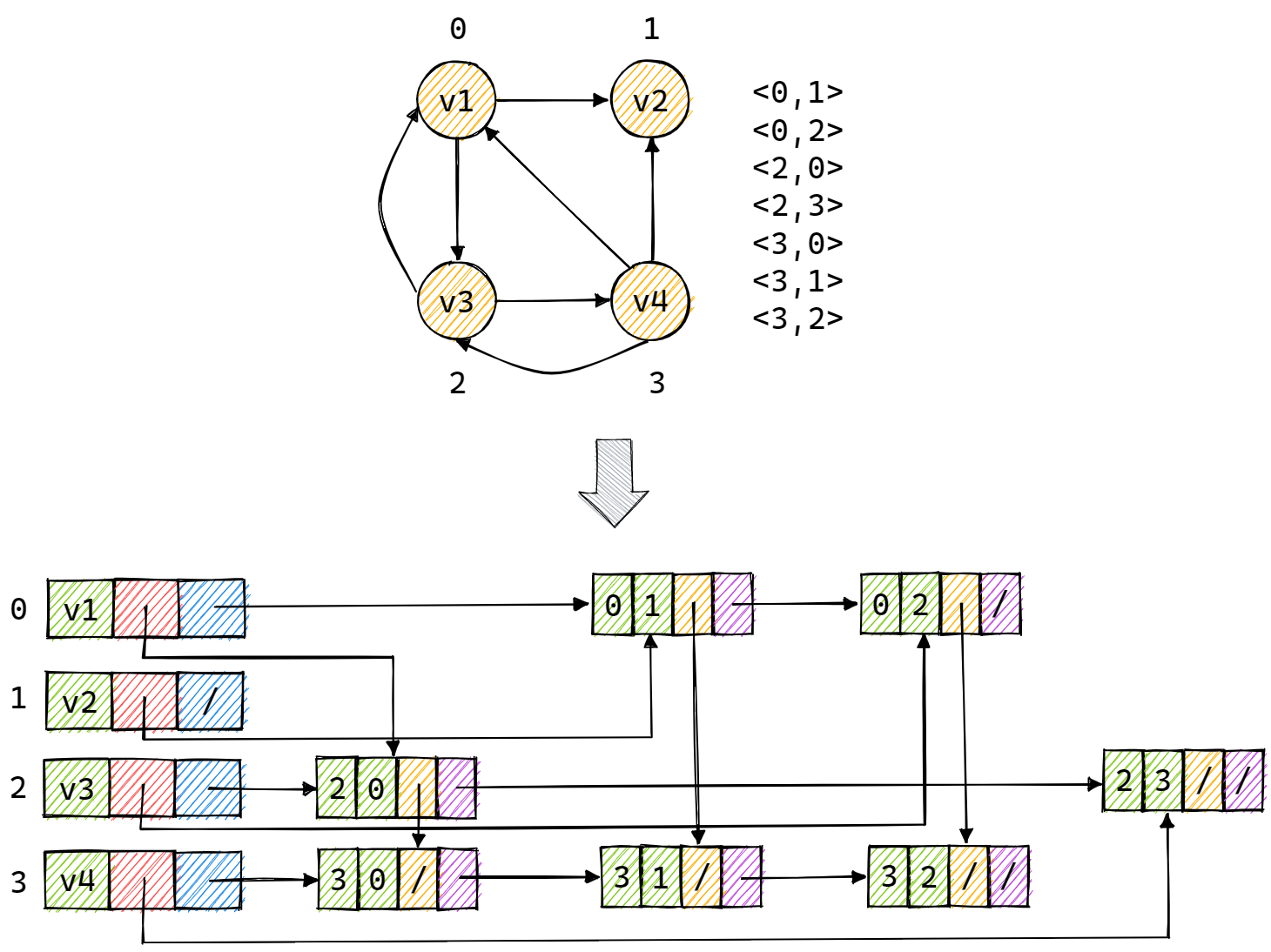
那么,将一个有向图转化为十字链表的过程如下图所示:
2.4 邻接多重表
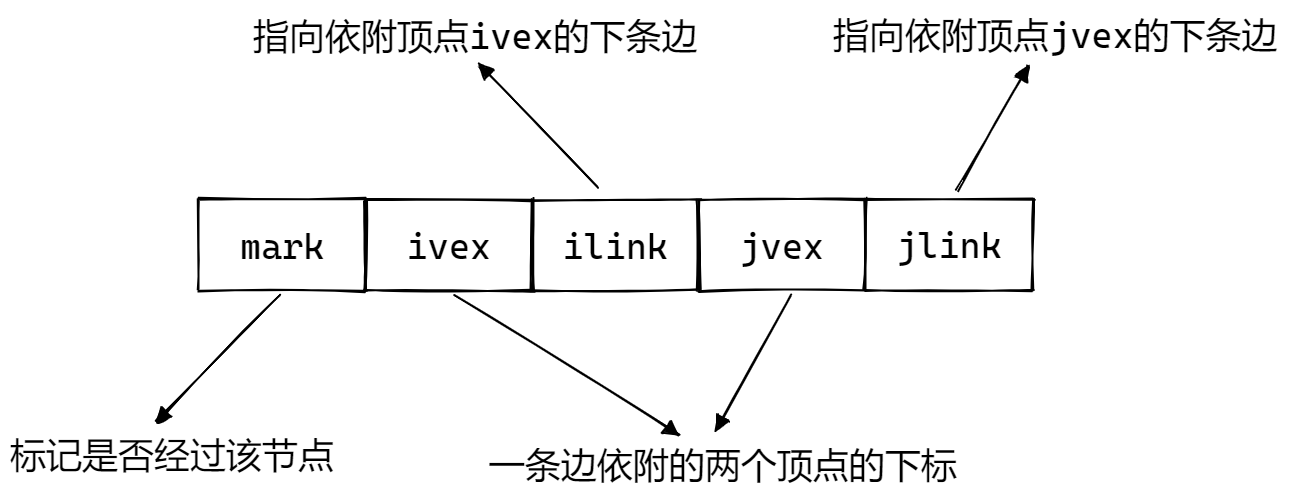
在邻接多重表中,其节点的结构如下图所示:
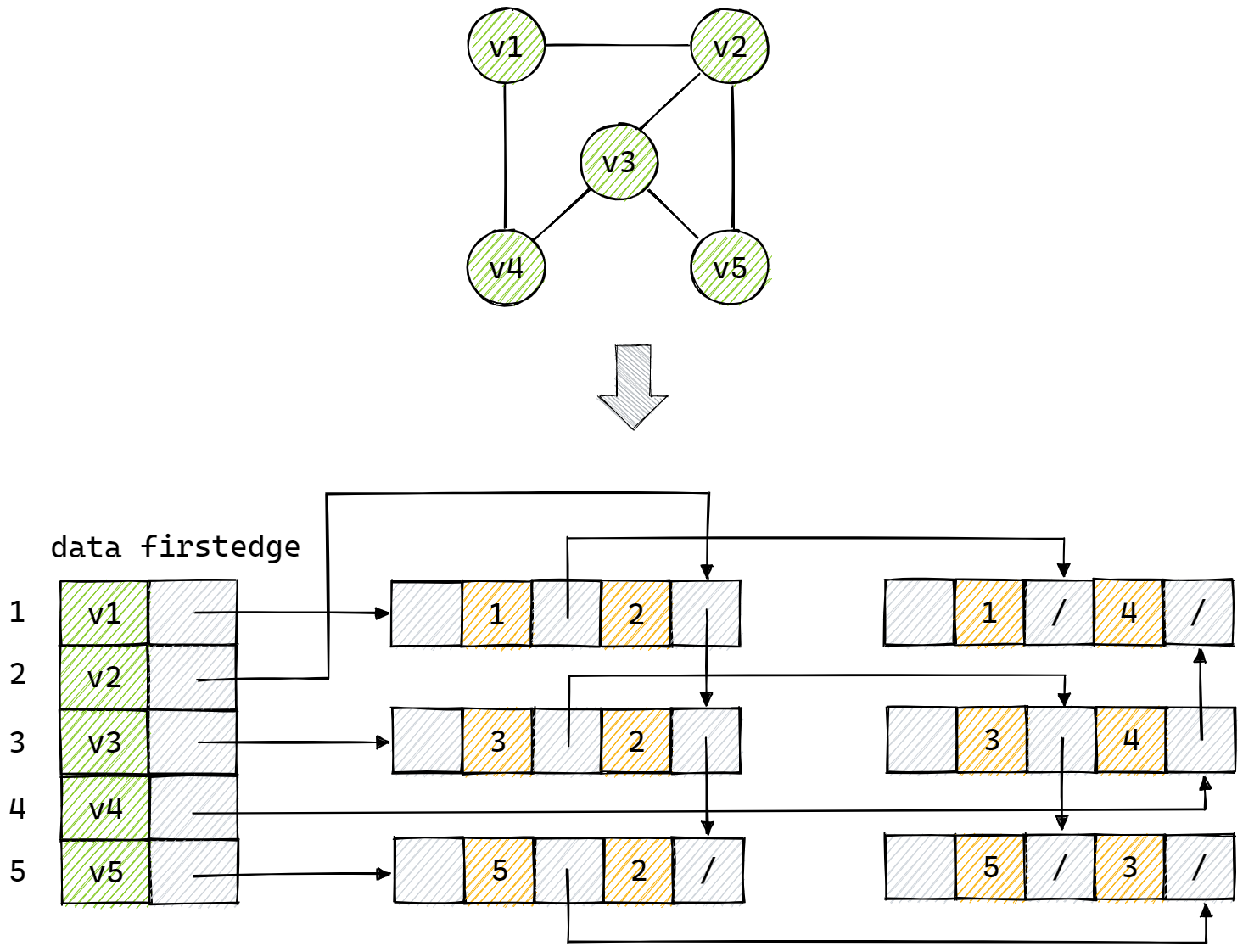
那么,将一个无向图转化为邻接多重表的过程如下图所示:
3.代码实现
3.1 构建邻接表
邻接表节点的定义如下:
struct Vertic {
Vertic(string data)
: data_(data) { }
string data_; // 存储顶点的信息
list<int> adjList_; // 邻接链表的结构
};
构建邻接表的代码如下,其从文件中读取图的节点信息,并将其转化为邻接表:
void Digraph::readFile(const string& filePath) {
FILE* pf = fopen(filePath.c_str(), "r");
if (pf == nullptr) {
throw filePath + " not exist!";
}
// 占用第0号位置
vertics.emplace_back("");
while (!feof(pf)) {
char line[1024] = { 0 };
fgets(line, 1024, pf);
// 增加一个节点信息
string linestr(line);
vertics.emplace_back(linestr.substr(0, linestr.size() - 1));
fgets(line, 1024, pf);
char* vertic_no = strtok(line, ",");
while (vertic_no != nullptr) {
int vex = atoi(vertic_no);
if (vex > 0) {
vertics.back().adjList_.emplace_back(vex);
}
vertic_no = strtok(nullptr, ",");
}
}
}
信息文件内容如下:
A
2,4,5
B
6
C
2,4
D
3,8
E
8
F
7,9
G
2,3
H
0
I
8
3.2 深度优先遍历
深度优先遍历的代码实现如下:
void Digraph::dfs() {
vector<bool> visited(vertics.size(), false);
dfs(1, visited);
cout << endl;
}
void Digraph::dfs(int start, vector<bool>& visited) {
if (visited[start]) return;
cout << vertics[start].data_ << " ";
visited[start] = true;
// 递归遍历下一层节点
for (auto& no : vertics[start].adjList_) {
dfs(no, visited);
}
}
3.3 广度优先遍历
广度优先遍历的代码实现如下:
void Digraph::bfs() {
vector<bool> visited(vertics.size(), false);
queue<int> que;
que.push(1);
visited[1] = true;
while (!que.empty()) {
int cur_no = que.front();
que.pop();
cout << vertics[cur_no].data_ << " ";
for (auto& no : vertics[cur_no].adjList_) {
if (!visited[no]) {
que.push(no);
visited[no] = true;
}
}
}
}
原文链接: https://www.cnblogs.com/tuilk/p/17132725.html
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/318925
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!