
树状数组
树状数组是一种简洁高效的数据结构。它可以优化前缀和和差分操作。
树状数组和线段树具有相似的功能,但他俩毕竟还有一些区别:树状数组能有的操作,线段树一定有;线段树有的操作,树状数组不一定有。但是树状数组的代码要比线段树短,思维更清晰,速度也更快,在解决一些单点修改的问题时,树状数组是不二之选。
工作原理
下面这张图展示了树状数组的工作原理:


这个结构和线段树有些类似:用一个大节点表示一些小节点的信息,进行查询的时候只需要查询一些大节点而不是所有的小节点。
其中,(c_1,c_3,c_5,c_7) 就是 (a_1,a_3,a_5,a_7)
从图中可以看出:(c_2) 管理的是 (a_1,a_2) ;(c_4) 管理的是 (a_1,a_2,a_3,a_4);(c_6) 管理的是 (a_5,a_6);(c_8) 管理的是全部 8 个数。
如果我们要计算数组 a 的区间和,比如说我要计算 (a_{51} sim a_{91}) 的区间和,可以采用类似于倍增的思想。
用法及操作
我们如何知道 (c_i) 管理数组 (a) 中的哪个区间呢?这时,我们引入一个函数 -- lowbit
int lowbit(int x) {
return x & (-x);
}
它的具体含义是,对于 x 的二进制表示,返回最低位的 1 的位置。因为我们知道 int 的编码表示,-x 就是 x 的编码取反加 1,所以从右到左,一直到第一个 1 为止,编码是不改变的。所以 lowbit 可以返回最低位的 1。
所以,我们可以把一个数理解为若干个 lowbit 相加(其实就是二进制分解),这样就比较好理解树状数组中的一些计算。
同时,lowbit(x) 等于 x 所管控的 a 的数组的个数。也就是说,(c_i) 代表的区间是 ([i - text{lowbit(i) + 1, i}])
所以,就可以写出
求和
int getsum(int x) { // a[1]..a[x]的和
int ans = 0;
while (x >= 1) {
ans = ans + c[x];
x = x - lowbit(x);
}
return ans;
}
加或减去某个数
void add(int x, int k) {
while (x <= n) { // 不能越界
c[x] = c[x] + k;
x = x + lowbit(x);
}
}
区间加 & 区间求和
若维护序列 a 的差分数组 b,此时我们对 a 的一个前缀 r 求和,即 (sumlimits_{i = 1}^{r} a_i) ,由差分数组的定义得到 (a_i = sumlimits_{j = 1}^{i}b_j) ,我们对于这两个式子进行推导:
&sumlimits_{i = 1}^{r}a_i \
&= sumlimits_{i=1}^{r}sumlimits_{j=1}^{i}b_j \
&= sumlimits_{i=1}^{r}b_i times (r-i+1) \
&= sumlimits_{i=1}^{r}b_i times (r+1) - sumlimits_{i=1}^{r}b_i times i
end{aligned}
]
所以我们发现,区间求和可以由两个前缀和相减得到。因此我们需要两个树状数组分别维护 (sum b_i) 和 (sum itimes b_i) ,这样我们就可以实现区间求和。
int t1[MAXN], t2[MAXN], n;
inline int lowbit(int x) { return x & (-x); }
void add(int k, int v) {
int v1 = k * v;
while (k <= n) {
t1[k] += v, t2[k] += v1;
k += lowbit(k);
}
}
int getsum(int *t, int k) {
int ret = 0;
while (k) {
ret += t[k];
k -= lowbit(k);
}
return ret;
}
void add1(int l, int r, int v) {
add(l, v), add(r + 1, -v); // 将区间加差分为两个前缀加
}
long long getsum1(int l, int r) {
return (r + 1ll) * getsum(t1, r) - 1ll * l * getsum(t1, l - 1) -
(getsum(t2, r) - getsum(t2, l - 1));
}
(O(log n)) 查询第 k 小/大元素lit
我们在这里只讨论第 k 小问题,第 k 大可以转化为第 k 小问题。
参考「可持久化线段树」中关于求区间第 k 小的思想。将所有数字看成一个可重集合,即定义数组 a 表示值为 i 的元素在整个序列中出现了 (a_i) 次。找第 k 小就是找到最小的 x ,恰好满足 (sumlimits_{i = 1}^{x}geq k)
因此可以想到算法:如果已经找到 x 满足 (sumlimits_{i=1}^{x} a_i < k) ,考虑能不能让 x 继续增加,使其仍然满足这个条件。找到最大的 x 后,x + 1 就是所要的值。在树状数组中,节点是根据 2 的幂划分的,每次可以扩展 2 的幂的长度。令 sum 表示当前的 x 所代表的前缀和,有如下算法找到最大的 x :
- 求出 (deph = lfloor log_2nrfloor)
- 计算 (t = sumlimits_{i=x+1}^{x+2^{depth}}a_i)
- 如果 (sum + t < k) ,则此时扩展成功,将 (2^{depth}) 加到 x 上,否则扩展失败,不对 x 进行操作
- 将 (depth) 减一,回到步骤 2 ,直到 depth 为 0
// 权值树状数组查询第k小
int kth(int k) {
int cnt = 0, ret = 0;
for (int i = log2(n); ~i; --i) { // i 与上文 depth 含义相同
ret += 1 << i; // 尝试扩展
if (ret >= n || cnt + t[ret] >= k) // 如果扩展失败
ret -= 1 << i;
else
cnt += t[ret]; // 扩展成功后 要更新之前求和的值
}
return ret + 1;
}
时间戳优化
对付多组数据很常见的技巧。如果每次输入新数据时,都暴力清空树状数组,就可能会造成超时。因此使用 tag 标记,存储当前节点上次使用时间(即最近一次是被第几组数据使用)。每次操作时判断这个位置 tag 中的时间和当前时间是否相同,就可以判断这个位置应该是 0 还是数组内的值。
// 时间戳优化
int tag[MAXN], t[MAXN], Tag;
void reset() { ++Tag; }
void add(int k, int v) {
while (k <= n) {
if (tag[k] != Tag) t[k] = 0;
t[k] += v, tag[k] = Tag;
k += lowbit(k);
}
}
int getsum(int k) {
int ret = 0;
while (k) {
if (tag[k] == Tag) ret += t[k];
k -= lowbit(k);
}
return ret;
}
例题
[P1908 逆序对](P1908 逆序对 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn))
对于求解逆序对个数,我们可以采用归并排序的方法,也可以采用树状数组的方法。
其中对于树状数组的方法,我们可以以权值为关键或者以输入顺序为关键来排序求解。
以权值为关键词由权值大到小进行排序,然后构建一个树状数组,每次将当下点在原数组中的位置及以后加 1。然后输出查询原位置的前缀和的值,因为此时查出来的值是在前面的,并且权值大于大的所有数中的,也就是当前点的逆序对的个数。
#include <bits/stdc++.h>
using namespace std;
const int N = 5e5 + 5;
typedef long long ll;
int n, tot, c[N];
ll t[N], vis[N];
struct Node {
int x, pos;
friend bool operator < (Node x, Node y) {
return x.x != y.x ? x.x > y.x : x.pos < y.pos;
}
}a[N];
inline int read() {
int x = 0, f = 1;
char c = getchar();
while (!isdigit(c)) {
if (c == '-') f = -1;
c = getchar();
}
while (isdigit(c)) x = x * 10 + c - '0', c = getchar();
return x * f;
}
inline int lowbit(int x) {
return x & (-x);
}
inline void add(int x, int k) {
while (x <= n) {
t[x] += k;
x += lowbit(x);
}
}
inline ll query(int x) {
ll Ans = 0;
while (x) {
Ans += t[x];
x -= lowbit(x);
}
return Ans;
}
int main() {
n = read();
for (int i = 1; i <= n; ++i) {
a[i].x = read();
a[i].pos = i;
}
sort(a + 1, a + 1 + n);
for (int i = 1; i <= n; ++i) {
if (a[i].x == a[i - 1].x) c[i] = tot;
else c[i] = ++tot;
}
//for (int i = 1; i <= n; ++i) cout << c[i] << " ";
ll Ans = 0;
for (int i = 1; i <= n; ++i) {
Ans += 1ll * (query(a[i].pos - 1) - vis[c[i]]);
add(a[i].pos, 1);
++vis[c[i]];
}
printf("%lldn", Ans);
//system("pause");
return 0;
}
另一种方法就是按照原顺序来,每一次树状数组更新它在数组中相对大小的位置加 1。
求解时,得到的是相对位置小于自己并且在自己前面的数的个数。但是我们知道在自己前面一共有多少个数,所以一减,就得到了在自己前面并且大于自己的数的个数。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const int N = 5e5 + 5;
int n, cnt, c[N];
ll t[N], ans;
struct Node {
int num, a;
friend bool operator < (Node x, Node y) {
return x.a < y.a;
}
}a[N];
inline int read() {
int x = 0, f = 1;
char c = getchar();
while (!isdigit(c)) {
if (c == '-') f = -1;
c = getchar();
}
while (isdigit(c)) x = x * 10 + c - '0', c = getchar();
return x * f;
}
inline int lowbit(int x) {
return x & (-x);
}
inline void add(int x, int k) {
while (x <= n) {
t[x] += k;
x += lowbit(x);
}
return ;
}
inline ll query(int x) {
ll ans = 0;
while (x) {
ans += t[x];
x -= lowbit(x);
}
return ans;
}
int main() {
n = read();
for (int i = 1; i <= n; ++i)
a[i].a = read(), a[i].num = i;
sort(a + 1, a + 1 + n);
for (int i = 1; i <= n; ++i) {
if (a[i].a != a[i - 1].a) c[a[i].num] = ++cnt;
else c[a[i].num] = cnt;
}
for (int i = 1; i <= n; ++i) {
add(c[i], 1);
ans = ans + i - query(c[i]);
}
printf("%lldn", ans);
return 0;
}
[P3605 [USACO17JAN]Promotion Counting P]([P3605 USACO17JAN]Promotion Counting P - 洛谷 | 计算机科学教育新生态 (luogu.com.cn))
可以理解此问题是树上的逆序对个数的求解。
有一棵树,每一个节点都有一个自己的权值,并且所有权值互不相同,求每一个点子树中权值大于自己的个数。
Sol1
一种思路是,dfn 表示每个点的 dfs 序,size[x] 表示 x 的子树的大小。那么在 dfs 序上表示,x 到它的子树是一段连续的区间 ([text{dfn[x]}, text{dfn[x] + size[x] - 1}])
所以我们可以按权值由大到小,对于 n 个节点进行排序。维护一个树状数组,对于节点 i,每一次将 dfn[i] 及以上的树状数组点值加 1。
每一个点的答案就是 query(dfn[x] + size[x] - 1) - query(dfn[x])
#include <bits/stdc++.h>
using namespace std;
const int N = 5e5 + 5;
typedef long long ll;
int n, tot, c[N];
ll t[N], vis[N];
struct Node {
int x, pos;
friend bool operator < (Node x, Node y) {
return x.x != y.x ? x.x > y.x : x.pos < y.pos;
}
}a[N];
inline int read() {
int x = 0, f = 1;
char c = getchar();
while (!isdigit(c)) {
if (c == '-') f = -1;
c = getchar();
}
while (isdigit(c)) x = x * 10 + c - '0', c = getchar();
return x * f;
}
inline int lowbit(int x) {
return x & (-x);
}
inline void add(int x, int k) {
while (x <= n) {
t[x] += k;
x += lowbit(x);
}
}
inline ll query(int x) {
ll Ans = 0;
while (x) {
Ans += t[x];
x -= lowbit(x);
}
return Ans;
}
int main() {
n = read();
for (int i = 1; i <= n; ++i) {
a[i].x = read();
a[i].pos = i;
}
sort(a + 1, a + 1 + n);
for (int i = 1; i <= n; ++i) {
if (a[i].x == a[i - 1].x) c[i] = tot;
else c[i] = ++tot;
}
//for (int i = 1; i <= n; ++i) cout << c[i] << " ";
ll Ans = 0;
for (int i = 1; i <= n; ++i) {
Ans += 1ll * (query(a[i].pos - 1) - vis[c[i]]);
add(a[i].pos, 1);
++vis[c[i]];
}
printf("%lldn", Ans);
//system("pause");
return 0;
}
Sol2
另一种思路是我们在 dfs 的时候就进行答案的统计。
对于一个节点 x,在统计它的子树之前,先减去之前树状数组中已有的大于它的权值的数的个数。
然后在 dfs 后加上 加了 x 的下属后比 x 权值大的数个数,就是最终答案了。
#include <bits/stdc++.h>
using namespace std;
const int N = 1e5 + 5;
int n, cnt, t[N], c[N], head[N], ans[N];
int store[N];
struct Edge {
int to, nxt;
}e[N << 1];
struct Node {
int x, pos;
friend bool operator < (Node x, Node y) {
return x.x < y.x;
}
}a[N];
inline int read() {
int x = 0, f = 1;
char c = getchar();
while (!isdigit(c)) {
if (c == '-') f = -1;
c = getchar();
}
while (isdigit(c)) x = x * 10 + c - '0', c = getchar();
return x * f;
}
inline void add_edge(int x, int y) {
e[++cnt].to = y;
e[cnt].nxt = head[x];
head[x] = cnt;
}
inline int lowbit(int x) {
return x & (-x);
}
inline void add(int x, int k) {
while (x <= n) {
t[x] += k;
x += lowbit(x);
}
}
inline int query(int x) {
int Ans = 0;
while (x) {
Ans += t[x];
x -= lowbit(x);
}
return Ans;
}
inline void dfs(int x) {
ans[x] -= query(n) - query(c[x]);
add(c[x], 1);
for (int i = head[x]; i ; i = e[i].nxt) {
int to = e[i].to;
dfs(to);
}
ans[x] += query(n) - query(c[x]);
}
int main() {
n = read();
for (int i = 1; i <= n; ++i) {
a[i].x = read();
a[i].pos = i;
}
sort(a + 1, a + 1 + n);
for (int i = 1; i <= n; ++i)
c[a[i].pos] = i;
//for (int i = 1; i<= n; ++i) cout << c[i] << " ";
//cout<< endl;
int x;
for (int i = 2; i <= n; ++i) {
x = read();
add_edge(x, i);
}
dfs(1);
for (int i = 1; i <= n; ++i) printf("%dn", ans[i]);
system("pause");
return 0;
}
收获:灵活变通,消除影响不一定在数据中真的消除,可以在代数意义上消除。
我们没有办法直接去对于树状数组已有的值进行操作,但是我们可以换个思路,我们在代数统计答案的时候去解决之前树状数组已有值的影响。
[P1972 [SDOI2009] HH的项链]([P1972 SDOI2009] HH的项链 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn))
n 个区间,m 个询问。每一次询问给出 L 和 R,输出 L 到 R 中不同颜色的个数。
一道很经典的题目了。
首先,如果我们在线做,需要一种方法针对每一次询问大概 (log) 级别地得到答案。嗯感觉上如果是针对颜色种数的话,好像没有那么好处理。
所以我们想一下有没有离线的做法,利用某些使得查询有序的性质,简化问题。
我们考虑一个区间 L 到 R,如果一个颜色出现了两次,第一次或者说第二次是相对没有意义的。如果我们只保留最后一次出现的颜色,之前出现的我们视作 0 或者说没有颜色,那么我们对于这个区间求和就是正确答案了。
顺着这个思路,我们应该对于询问做什么处理?如果我们保留最后出现的颜色,那么应该不难想到我们把询问排一下序,按照询问的 R。
此时,我们应该是在处理询问的时候,去更新我们的项链颜色。
涉及到区间求和(就是直接求颜色种数),我们考虑树状数组。树状数组维护什么?我们在下标 i 第一次遇到这个颜色的时候就 add(i, 1),因为我们是对右边界排序的,所以说,越右边的颜色就可以代表此类在别的位置的颜色。所以我们有一个 vis 数组记录这一颜色的位置,再一次遇到的时候就 add(vis[x], -1), add(i, 1)。
这样我们就可以解决这个问题了。
#include <bits/stdc++.h>
using namespace std;
const int N = 1e6 + 5;
int n, m, a[N], t[N], vis[N], ans[N];
struct Question {
int l, r, pos;
friend bool operator < (Question x, Question y) {
return x.r == y.r ? x.l < y.l : x.r < y.r;
}
}q[N];
inline int read() {
int x = 0, f = 1;
char c = getchar();
while (!isdigit(c)) {
if (c == '-') f = -1;
c = getchar();
}
while (isdigit(c)) x = x * 10 + c - '0', c = getchar();
return x * f;
}
inline int lowbit(int x) {
return x & (-x);
}
inline void add(int x, int k) {
while (x <= n) {
t[x] += k;
x += lowbit(x);
}
}
inline int query(int x) {
int Ans = 0;
while (x) {
Ans += t[x];
x -= lowbit(x);
}
return Ans;
}
int main() {
n = read();
for (int i = 1; i <= n; ++i) a[i] = read();
m = read();
for (int i = 1; i <= m; ++i) {
q[i].l = read();
q[i].r = read();
q[i].pos = i;
}
sort(q + 1, q + m + 1);
int nxt = 1;
for (int i = 1; i <= m; ++i) {
for (int j = nxt; j <= q[i].r; ++j) {
if (vis[a[j]]) add(vis[a[j]], -1);
add(j, 1);
vis[a[j]] = j;
}
nxt = q[i].r + 1;
ans[q[i].pos] = query(q[i].r) - query(q[i].l - 1);
}
for (int i = 1; i <= m; ++i) printf("%dn", ans[i]);
return 0;
}
[P4113 [HEOI2012]采花]([P4113 HEOI2012]采花 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn))
HH 的项链升级版,一样的思路。
一样的思路,就是多了几个判断。
#include <bits/stdc++.h>
using namespace std;
const int N = 2e6 + 5;
int n, m, c, a[N], t[N], vis[N], ans[N], pos[N];
struct Question {
int l, r, pos;
friend bool operator < (Question a, Question b) {
return a.r == b.r ? a.l < b.l : a.r < b.r;
}
}q[N];
inline int read() {
int x = 0, f = 1;
char c = getchar();
while (!isdigit(c)) {
if (c == '-') f = -1;
c = getchar();
}
while (isdigit(c)) x = x * 10 + c - '0', c = getchar();
return x * f;
}
inline int lowbit(int x) {
return x & (-x);
}
inline void add(int x, int k) {
while (x <= n) {
t[x] += k;
x += lowbit(x);
}
}
inline int query(int x) {
int Ans = 0;
while (x) {
Ans += t[x];
x -= lowbit(x);
}
return Ans;
}
int main() {
n = read(), c = read(), m = read();
for (int i = 1; i <= n; ++i) a[i] = read();
for (int i = 1; i <= m; ++i) {
q[i].l = read(), q[i].r = read();
q[i].pos = i;
}
for (int i = 1; i <= n; ++i) vis[i] = pos[a[i]], pos[a[i]] = i;
sort(q + 1, q + 1 + m);
int nxt = 1;
for (int i = 1; i <= m; ++i) {
for (int j = nxt; j <= q[i].r; ++j) {
if (vis[j]) add(vis[j], 1);
if (vis[j] && vis[vis[j]]) add(vis[vis[j]], -1);
}
nxt = q[i].r + 1;
ans[q[i].pos] = query(q[i].r) - query(q[i].l - 1);
}
for (int i = 1; i <= m; ++i) printf("%dn", ans[i]);
system("pause");
return 0;
}
二维树状数组
在一维的时候,我们在进行单点操作的时候,考虑的是修改了这个位置后会有多少个位置被影响到。显然,我们可以通过 (i += i & (-i)) 的方法逆推原本位置被树状数组管理的区间。
对于二维树状数组,我们的操作实际上是一模一样的。但是如果一维树状数组维护的是一个一维的数列,那么二维树状数组就是维护了一个一个二维的矩阵了。
我们现在考虑的是这个位置修改后,会影响到几个矩阵内的值。当然,上面已经提到过,二维树状数组其实是一个树状数组套树状数组,也就是每个节点都是一个树状数组,因此,我们在进行修改操作的时候,对于第一维的树状数组,我们要考虑修改这个位置的树状数组会影响到多少个位置的树状数组,进入到第二维时考虑的就是这个位置修改后会影响到多少个位置。可以发现,这样的操作后其实就是修改了一个一个的小矩形了,总的单次修改的时间复杂度为 O(lognlogm)
void add(int x, int y, int k) {
while (x <= n) {
int ty = y;
while (ty <= m) t[x][ty] += k, ty += lowbit(ty);
x += lowbit(x);
}
}
那么对于区间查询呢?也是一样的道理。就是查询前缀和。
int query(int x, int y) {
int ans = 0;
while (x) {
int ty = y;
while (ty) {
ans += t[x][ty];
ty -= lowbit(ty);
}
x += lowbit(x);
}
}
对于二维树状数组的区间修改,单点查询问题
我们考虑二维差分实现区间修改。回想前缀和的公式 (sum_i = sum_{i-1} + a_i) ,同样的,对于二维,我们有 (sum_{i, j} = sum_{i - 1, j} + sum_{i, j - 1} - sum_{i-1,j-1} + a_{i,j}) 。我们令其中 (a_{i,j}) 表示原数值代替 sum,b 表示差分数组代替 a,得到 (a_{i,j} = a_{i-1,j} + a_{i,j-1} -a_{i-1,j-1} + b_{i,j}) 。两边同时求和累加得到
&sumlimits_{i=1}^{x}sumlimits_{j=1}^{y} a_{i,j} \
&= sumlimits_{i=1}^{x-1}sumlimits_{j=1}^{y} a_{i,j} + sumlimits_{i=1}^{x}sumlimits_{j=1}^{y-1}a_{i,j} - sumlimits_{i=1}^{x-1}sumlimits_{j=1}^{y-1} a_{i,j} + sumlimits_{i=1}^{x}sumlimits_{j=1}^{y} b_{i, j} \
&Leftrightarrow a_{x,y} = sumlimits_{i=1}^{x}sumlimits_{j=1}^{y} b_{i, j}
end{aligned}
]
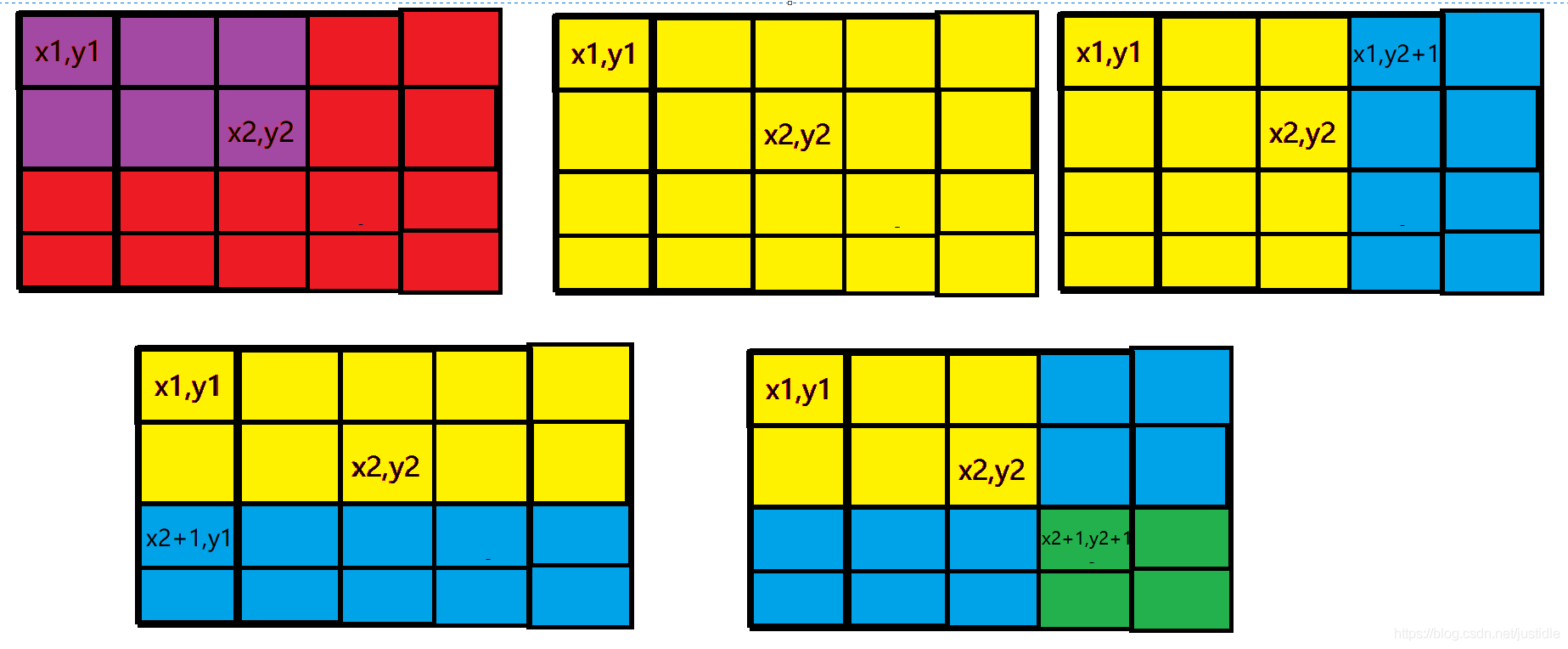
如果我们要修改的区间是以 x1,y1 为左上角,x2,y2 为右下角的一块矩形。那么我们修改了 x1,y1 后将有黄色区域的所有点的值收到影响。所以我们再修改 x1,y2+1 和 x2+1,y1 来抵消影响,同样的由容斥原理,所以再修改 x2+1,y2+1 。
对于二维树状数组的区间修改,区间求和
我们同样的,我们考虑求和贡献。
我们设 (T_{i,j}) 表示由 ((1, 1)) 到 ((i,j)) 这一部分矩形的和。那么 (T_{x,y} = sumlimits_{i=1}^{x}sumlimits_{j=1}^{y}sumlimits_{k=1}^{i}sumlimits_{p=1}^{j} b_{k, p})
考虑每一个 (b_{i, j}) 产生的贡献,如图:
这样的话,每一个 (b_{i, j}) 对于红色阴影部分的所有方块有贡献。所以原式等价于 (T_{x, y} = sumlimits_{i=1}^{x}sumlimits_{j=1}^{y} (n - i + 1)(m - j + 1) b_{i, j} = sumlimits_{i = 1}^{x}sumlimits_{j=1}^{y} (mn+m+n+1-(m+1)i-(n+1)j+ij)b_{i, j})
所以我们需要维护 (ib_{i,j}, jb_{i, j}, ijb_{i, j})
[P4514 上帝造题的七分钟](P4514 上帝造题的七分钟 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn))
就是树状数组二维区间修改区间查询的板子
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const int N = 2050;
int n, m;
struct BIT {
int t[N][N];
inline int lowbit(int x) {
return x & (-x);
}
inline void add(int x, int y, int k) {
while (x <= n) {
int ty = y;
while (ty <= m) {
t[x][ty] += k;
ty += lowbit(ty);
}
x += lowbit(x);
}
}
inline int query(int x, int y) {
int ans = 0;
while (x) {
int ty = y;
while (ty) {
ans += t[x][ty];
ty -= lowbit(ty);
}
x -= lowbit(x);
}
return ans;
}
}A1, A2, A3, A4;
inline int read() {
int x = 0, f = 1;
char c = getchar();
while (!isdigit(c)) {
if (c == '-') f = -1;
c = getchar();
}
while (isdigit(c)) x = x * 10 + c - '0', c = getchar();
return x * f;
}
inline ll query(int x, int y) {
return 1ll * (x + 1) * (y + 1) * A1.query(x, y) - 1ll * (y + 1) * A2.query(x, y) - 1ll * (x + 1) * A3.query(x, y) + 1ll * A4.query(x, y);
}
inline void Add(int x1, int y1, ll k) {
A1.add(x1, y1, k);
A2.add(x1, y1, x1 * k);
A3.add(x1, y1, y1 * k);
A4.add(x1, y1, x1 * y1 * k);
}
int main() {
char c;
scanf("%c%d%d", &c, &n, &m);
int x1, x2, y1, y2;
ll k;
while (cin >> c) {
if (c == 'L') {
x1 = read(), y1 = read();
x2 = read(), y2 = read();
k = read();
Add(x2 + 1, y2 + 1, k);
Add(x2 + 1, y1, -k);
Add(x1, y2 + 1, -k);
Add(x1, y1, k);
} else {
x1 = read(), y1 = read();
x2 = read(), y2 = read();
printf("%dn", query(x2, y2) - query(x1 - 1, y2) - query(x2, y1 - 1) + query(x1 - 1, y1 - 1));
}
}
return 0;
}
这种结构体的树状数组写法可以使得我们在写函数的时候统一形式。也算比较好用的一个技巧。
原文链接: https://www.cnblogs.com/Miraclys/p/17047658.html
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/311525
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!