
vector (向量)


成员函数
| 函数 | 表述 |
|---|---|
| c.assign(beg,end) c.assign(n,elem) | 将[beg; end)区间中的数据赋值给c。将n个elem的拷贝赋值给c。 |
| c.at(idx) | 传回索引idx所指的数据,如果idx越界,抛出out_of_range。 |
| c.back() | 传回最后一个数据,不检查这个数据是否存在。 |
| c.begin() | 传回迭代器重的可一个数据。 |
| c.capacity() | 返回容器中数据个数。 |
| c.clear() | 移除容器中所有数据。 |
| c.empty() | 判断容器是否为空。 |
| c.end() | 指向迭代器中的最后一个数据地址。 |
| c.erase(pos) c.erase(beg,end) | 删除pos位置的数据,传回下一个数据的位置。删除[beg,end)区间的数据,传回下一个数据的位置。 |
| c.front() | 传回地一个数据。 |
| get_allocator | 使用构造函数返回一个拷贝。 |
| c.insert(pos,elem) c.insert(pos,n,elem) c.insert(pos,beg,end) | 在pos位置插入一个elem拷贝,传回新数据位置。在pos位置插入n个elem数据。无返回值。在pos位置插入在[beg,end)区间的数据。无返回值。 |
| c.max_size() | 返回容器中最大数据的数量。 |
| c.pop_back() | 删除最后一个数据。 |
| c.push_back(elem) | 在尾部加入一个数据。 |
| c.rbegin() | 传回一个逆向队列的第一个数据。 |
| c.rend() | 传回一个逆向队列的最后一个数据的下一个位置。 |
| c.resize(num) | 重新指定队列的长度。 |
| c.reserve() | 保留适当的容量。 |
| c.size() | 返回容器中实际数据的个数。 |
| c1.swap(c2) swap(c1,c2) | 将c1和c2元素互换。同上操作。 |
| vector |
创建一个空的vector。复制一个vector。创建一个vector,含有n个数据,数据均已缺省构造产生。创建一个含有n个elem拷贝的vector。创建一个以[beg;end)区间的vector。销毁所有数据,释放内存。 |
初始化
vector<int> v1;
vector<father> v2;
vector<string> v3;
vector<vector<int> >; //注意空格。这里相当于二维数组int a[n][n];
vector<int> v5 = { 1,2,3,4,5 }; //列表初始化,注意使用的是花括号
vector<string> v6 = { "hi","my","name","is","lee" };
vector<int> v7(5, -1); //初始化为-1,-1,-1,-1,-1。第一个参数是数目,第二个参数是要初始化的值
vector<string> v8(3, "hi");
vector<int> v9(10); //默认初始化为0
vector<int> v10(4); //默认初始化为空字符串
添加元素
请使用push_back加入元素,并且这个元素是被加在数组尾部的。
for (int i = 0; i < 20; i++)
{
v1.push_back(i);
}
访问vector中的元素
for (int i = 0; i < v1.size(); i++)
{
cout << v1[i] << endl;
v1[i] = 100;
cout << v1[i] << endl;
}
当然我们也可以选择使用迭代器来访问元素
vector<string> v6 = { "hi","my","name","is","lee" };
for (vector<string>::iterator iter = v6.begin(); iter != v6.end(); iter++)
{
cout << *iter << endl;
//下面两种方法都都可以检查迭代器是否为空
cout << (*iter).empty() << endl;
cout << iter->empty() << endl;
}
上面是正向迭代,如果我们想从后往前迭代该如何操作?
使用反向迭代器
for (vector<string>::reverse_iterator iter = v6.rbegin(); iter != v6.rend(); iter++)
{
cout << *iter << endl;
}
插入元素
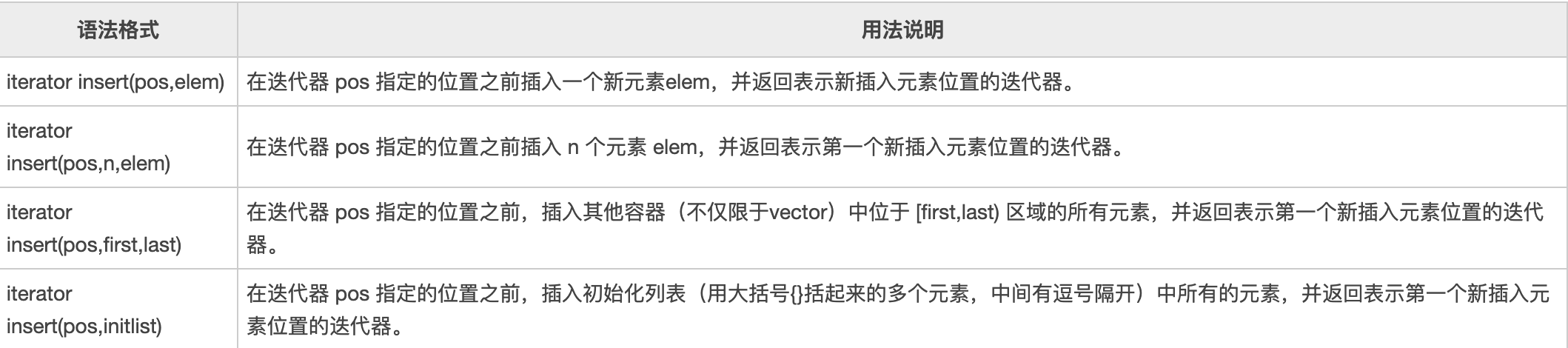
下面的例子,演示了如何使用 insert() 函数向 vector 容器中插入元素。
#include <iostream>
#include <vector>
#include <array>
using namespace std;
int main()
{
std::vector<int> demo{1,2};
//第一种格式用法
demo.insert(demo.begin() + 1, 3);//{1,3,2}
//第二种格式用法
demo.insert(demo.end(), 2, 5);//{1,3,2,5,5}
//第三种格式用法
std::array<int,3>test{ 7,8,9 };
demo.insert(demo.end(), test.begin(), test.end());//{1,3,2,5,5,7,8,9}
//第四种格式用法
demo.insert(demo.end(), { 10,11 });//{1,3,2,5,5,7,8,9,10,11}
for (int i = 0; i < demo.size(); i++) {
cout << demo[i] << " ";
}
return 0;
}
删除元素

如果想删除 vector 容器中指定位置处的元素,可以使用 erase() 成员函数,该函数的语法格式为:
iterator erase (pos);
下面的例子演示了 erase() 函数的具体用法:
#include <vector>
#include <iostream>
using namespace std;
int main()
{
vector<int>demo{ 1,2,3,4,5 };
auto iter = demo.erase(demo.begin() + 1);//删除元素 2
//输出 dmeo 容器新的size
cout << "size is :" << demo.size() << endl;
//输出 demo 容器新的容量
cout << "capacity is :" << demo.capacity() << endl;
for (int i = 0; i < demo.size(); i++) {
cout << demo[i] << " ";
}
//iter迭代器指向元素 3
cout << endl << *iter << endl;
return 0;
}
运行结果为:
size is :4
capacity is :5
1 3 4 5
3
unordered_set容器
是什么
unordered_set 容器,可直译为“无序 set 容器”。即 unordered_set 容器和 set 容器很像,唯一的区别就在于 set 容器会自行对存储的数据进行排序,而 unordered_set 容器不会。
unordered_set的几个特性:
- 不再以键值对的形式存储数据,而是直接存储数据的值
- 容器内部存储的各个元素的值都互不相等,且不能被修改/
- 不会对内部存储的数据进行排序
unordered_set 容器的类模板定义如下:
template < class Key, //容器中存储元素的类型
class Hash = hash<Key>, //确定元素存储位置所用的哈希函数
class Pred = equal_to<Key>, //判断各个元素是否相等所用的函数
class Alloc = allocator<Key> //指定分配器对象的类型
> class unordered_set;
以上 4 个参数中,只有第一个参数没有默认值,这意味着如果我们想创建一个 unordered_set 容器,至少需要手动传递 1 个参数。事实上,在 99% 的实际场景中最多只需要使用前 3 个参数(各自含义如表 1 所示),最后一个参数保持默认值即可。
初始化
创建空的set
unordered_set<int> set1;
拷贝构造
unordered_set<int> set2(set1);
使用迭代器构造
unordered_set<int> set3(set1.begin(), set1.end());
使用数组作为其初值进行构造
unordered_set<int> set4(arr,arr+5);
移动构造
unordered_set<int> set5(move(set2));
使用处置列表进行构造
unordered_set<int> set6 {1,2,10,10};
常用内置函数
empty()函数——判断是否为空
//若容器为空,则返回 true;否则 false
set1.empty();
find()函数——查找
//查找2,找到返回迭代器,失败返回end()
set1.find(2);
count()函数——出现次数
//返回指2出现的次数,0或1
set1.count(2);
insert()函数——插入元素
//插入元素,返回pair<unordered_set<int>::iterator, bool>
set1.insert(3);
//使用initializer_list插入元素
set1.insert({1,2,3});
//指定插入位置,如果位置正确会减少插入时间,返回指向插入元素的迭代器
set1.insert(set1.end(), 4);
//使用范围迭代器插入
set1.insert(set2.begin(), set2.end());
关于insert函数的返回值:
insert()只传入单个参数(待插入元素)
- 会返回一个 pair 对象
- 这个 pair 对象包含一个迭代器,以及一个附加的布尔值用来说明插入是否成功
- 如果元素被插入,返回的迭代器会指向新元素
- 如果没有被插入,迭代器指向阻止插入的元素
auto pr = words.insert("ninety"); // Returns a pair - an iterator & a bool value
insert()传入两个参数(迭代器+待插入元素)
- 可以用一个迭代器作为insert()的第一个参数,它指定了元素被插入的位置
- 在这种情况下,只会返回一个迭代器
auto iter = words.insert (pr.first, "nine"); // 1st arg is a hint. Returns an iterator
insert()传入初始化列表
- 插入初始化表中的元素
- 在这种情况下,什么都没有返回
words.insert({"ten", "seven", "six"}); // Inserting an initializer list
emplace()函数——插入元素(转移构造)
//使用转移构造函数添加新元素3,比insert效率高
set1.emplace(3);
erase()函数——删除元素
//删除操作,成功返回1,失败返回0
set1.erase(1);
//删除操作,成功返回下一个pair的迭代器
set1.erase(set1.find(1));
//删除set1的所有元素,返回指向end的迭代器
set1.erase(set1.begin(), set1.end());
bucket_count()函数——篮子数目
//返回容器中的篮子总数
set1.bucket_count();
bucket_size()函数——篮子中元素数目
//返回1号篮子中的元素数
set1.bucket_size(1);
bucket()函数——在哪个篮子
//元素1在哪一个篮子
set1.bucket(1);
clear()函数——清空
set1.clear();
load_factor()函数——负载因子
//负载因子,返回每个篮子元素的平均数,即size/float(bucket_count);
set1.load_factor();
rehash()函数——设置篮子数目并重新分布
//设置篮子的数量为20,并且重新rehash
set1.rehash(20);
遍历unordered_set
使用迭代器遍历
for(unordered_set<int>::iterator it = set1.begin(); it != set1.end(); ++it)
cout << *it << " ";
C++11新方法
for(int x : set1)
cout << x << " ";
unordered_set容器的成员方法
| 成员方法 | 功能 |
|---|---|
| begin() | 返回指向容器中第一个元素的正向迭代器。 |
| end(); | 返回指向容器中最后一个元素之后位置的正向迭代器。 |
| cbegin() | 和 begin() 功能相同,只不过其返回的是 const 类型的正向迭代器。 |
| cend() | 和 end() 功能相同,只不过其返回的是 const 类型的正向迭代器。 |
| empty() | 若容器为空,则返回 true;否则 false。 |
| size() | 返回当前容器中存有元素的个数。 |
| max_size() | 返回容器所能容纳元素的最大个数,不同的操作系统,其返回值亦不相同。 |
| find(key) | 查找以值为 key 的元素,如果找到,则返回一个指向该元素的正向迭代器;反之,则返回一个指向容器中最后一个元素之后位置的迭代器(如果 end() 方法返回的迭代器)。 |
| count(key) | 在容器中查找值为 key 的元素的个数。 |
| equal_range(key) | 返回一个 pair 对象,其包含 2 个迭代器,用于表明当前容器中值为 key 的元素所在的范围。 |
| emplace() | 向容器中添加新元素,效率比 insert() 方法高。 |
| emplace_hint() | 向容器中添加新元素,效率比 insert() 方法高。 |
| insert() | 向容器中添加新元素。 |
| erase() | 删除指定元素。 |
| clear() | 清空容器,即删除容器中存储的所有元素。 |
| swap() | 交换 2 个 unordered_map 容器存储的元素,前提是必须保证这 2 个容器的类型完全相等。 |
| bucket_count() | 返回当前容器底层存储元素时,使用桶(一个线性链表代表一个桶)的数量。 |
| max_bucket_count() | 返回当前系统中,unordered_map 容器底层最多可以使用多少桶。 |
| bucket_size(n) | 返回第 n 个桶中存储元素的数量。 |
| bucket(key) | 返回值为 key 的元素所在桶的编号。 |
| load_factor() | 返回 unordered_map 容器中当前的负载因子。负载因子,指的是的当前容器中存储元素的数量(size())和使用桶数(bucket_count())的比值,即 load_factor() = size() / bucket_count()。 |
| max_load_factor() | 返回或者设置当前 unordered_map 容器的负载因子。 |
| rehash(n) | 将当前容器底层使用桶的数量设置为 n。 |
| reserve() | 将存储桶的数量(也就是 bucket_count() 方法的返回值)设置为至少容纳count个元(不超过最大负载因子)所需的数量,并重新整理容器。 |
| hash_function() | 返回当前容器使用的哈希函数对象。 |
map容器
map简介
map是STL的一个关联容器,它提供一对一的hash。
第一个可以称为关键字(key),每个关键字只能在map中出现一次;
第二个可能称为该关键字的值(value);
map以模板(泛型)方式实现,可以存储任意类型的数据,包括使用者自定义的数据类型。Map主要用于资料一对一映射(one-to-one)的情況,map內部的实现自建一颗红黑树,这颗树具有对数据自动排序的功能。在map内部所有的数据都是有序的,后边我们会见识到有序的好处。比如一个班级中,每个学生的学号跟他的姓名就存在著一对一映射的关系。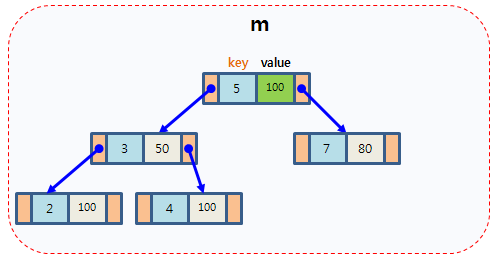
map的功能
自动建立key - value的对应。key 和 value可以是任意你需要的类型,包括自定义类型。
使用map
使用map得包含map类所在的头文件
#include <map> //注意,STL头文件没有扩展名.h
map对象是模板类,需要关键字和存储对象两个模板参数:
std:map<int, string> personnel;
map的构造函数
map共提供了6个构造函数,这块涉及到内存分配器这些东西,略过不表,在下面我们将接触到一些map的构造方法,这里要说下的就是,我们通常用如下方法构造一个map:
map<int, string> mapStudent;
插入元素
// 定义一个map对象
map<int, string> mapStudent;
// 第一种 用insert函數插入pair
mapStudent.insert(pair<int, string>(000, "student_zero"));
// 第二种 用insert函数插入value_type数据
mapStudent.insert(map<int, string>::value_type(001, "student_one"));
// 第三种 用"array"方式插入
mapStudent[123] = "student_first";
mapStudent[456] = "student_second";
查找元素
当所查找的关键key出现时,它返回数据所在对象的位置,如果沒有,返回iter与end函数的值相同。
// find 返回迭代器指向当前查找元素的位置否则返回map::end()位置
iter = mapStudent.find("123");
if(iter != mapStudent.end())
cout<<"Find, the value is"<<iter->second<<endl;
else
cout<<"Do not Find"<<endl;
刪除与清空元素
//迭代器刪除
iter = mapStudent.find("123");
mapStudent.erase(iter);
//用关键字刪除
int n = mapStudent.erase("123"); //如果刪除了會返回1,否則返回0
//用迭代器范围刪除 : 把整个map清空
mapStudent.erase(mapStudent.begin(), mapStudent.end());
//等同于mapStudent.clear()
map的大小
在往map里面插入了数据,我们怎么知道当前已经插入了多少数据呢,可以用size函数,用法如下:
int nSize = mapStudent.size();
map的基本操作函数:
C++ maps是一种关联式容器,包含“关键字/值”对
| 成员方法 | 功能 |
|---|---|
| begin() | 返回指向容器中第一个(注意,是已排好序的第一个)键值对的双向迭代器。如果 map 容器用 const 限定,则该方法返回的是 const 类型的双向迭代器。 |
| end() | 返回指向容器最后一个元素(注意,是已排好序的最后一个)所在位置后一个位置的双向迭代器,通常和 begin() 结合使用。如果 map 容器用 const 限定,则该方法返回的是 const 类型的双向迭代器。 |
| rbegin() | 返回指向最后一个(注意,是已排好序的最后一个)元素的反向双向迭代器。如果 map 容器用 const 限定,则该方法返回的是 const 类型的反向双向迭代器。 |
| rend() | 返回指向第一个(注意,是已排好序的第一个)元素所在位置前一个位置的反向双向迭代器。如果 map 容器用 const 限定,则该方法返回的是 const 类型的反向双向迭代器。 |
| cbegin() | 和 begin() 功能相同,只不过在其基础上,增加了 const 属性,不能用于修改容器内存储的键值对。 |
| cend() | 和 end() 功能相同,只不过在其基础上,增加了 const 属性,不能用于修改容器内存储的键值对。 |
| crbegin() | 和 rbegin() 功能相同,只不过在其基础上,增加了 const 属性,不能用于修改容器内存储的键值对。 |
| crend() | 和 rend() 功能相同,只不过在其基础上,增加了 const 属性,不能用于修改容器内存储的键值对。 |
| find(key) | 在 map 容器中查找键为 key 的键值对,如果成功找到,则返回指向该键值对的双向迭代器;反之,则返回和 end() 方法一样的迭代器。另外,如果 map 容器用 const 限定,则该方法返回的是 const 类型的双向迭代器。 |
| lower_bound(key) | 返回一个指向当前 map 容器中第一个大于或等于 key 的键值对的双向迭代器。如果 map 容器用 const 限定,则该方法返回的是 const 类型的双向迭代器。 |
| upper_bound(key) | 返回一个指向当前 map 容器中第一个大于 key 的键值对的迭代器。如果 map 容器用 const 限定,则该方法返回的是 const 类型的双向迭代器。 |
| equal_range(key) | 该方法返回一个 pair 对象(包含 2 个双向迭代器),其中 pair.first 和 lower_bound() 方法的返回值等价,pair.second 和 upper_bound() 方法的返回值等价。也就是说,该方法将返回一个范围,该范围中包含的键为 key 的键值对(map 容器键值对唯一,因此该范围最多包含一个键值对)。 |
| empty() | 若容器为空,则返回 true;否则 false。 |
| size() | 返回当前 map 容器中存有键值对的个数。 |
| max_size() | 返回 map 容器所能容纳键值对的最大个数,不同的操作系统,其返回值亦不相同。 |
| operator[] | map容器重载了 [] 运算符,只要知道 map 容器中某个键值对的键的值,就可以向获取数组中元素那样,通过键直接获取对应的值。 |
| at(key) | 找到 map 容器中 key 键对应的值,如果找不到,该函数会引发 out_of_range 异常。 |
| insert() | 向 map 容器中插入键值对。 |
| erase() | 删除 map 容器指定位置、指定键(key)值或者指定区域内的键值对。后续章节还会对该方法做重点讲解。 |
| swap() | 交换 2 个 map 容器中存储的键值对,这意味着,操作的 2 个键值对的类型必须相同。 |
| clear() | 清空 map 容器中所有的键值对,即使 map 容器的 size() 为 0。 |
| emplace() | 在当前 map 容器中的指定位置处构造新键值对。其效果和插入键值对一样,但效率更高。 |
| emplace_hint() | 在本质上和 emplace() 在 map 容器中构造新键值对的方式是一样的,不同之处在于,使用者必须为该方法提供一个指示键值对生成位置的迭代器,并作为该方法的第一个参数。 |
| count(key) | 在当前 map 容器中,查找键为 key 的键值对的个数并返回。注意,由于 map 容器中各键值对的键的值是唯一的,因此该函数的返回值最大为 1。 |
queue队列
在C++中只要#include即可使用队列类,其中在面试或笔试中常用的成员函数如下(按照最常用到不常用的顺序)
- push()
- pop()
- size()
- empty()
- front()
- back()
接下来逐一举例说明:
push()
队列中由于是先进先出,push即在队尾插入一个元素,如:
queue<string> q;
q.push("Hello World!");
q.push("China");
cout<<q.front()<<endl;
可以输出:Hello World!
pop()
将队列中最靠前位置的元素拿掉,是没有返回值的void函数。如:
queue<string> q;
q.push("Hello World!");
q.push("China");
q.pop();
cout<<q.front()<<endl;
可以输出:China
原因是Hello World!已经被除掉了。
size()
返回队列中元素的个数,返回值类型为unsigned int。如:
queue<string> q;
cout<<q.size()<<endl;
q.push("Hello World!");
q.push("China");
cout<<q.size()<<endl;
输出两行,分别为0和2,即队列中元素的个数。
empty()
判断队列是否为空的,如果为空则返回true。如:
queue<string> q;
cout<<q.empty()<<endl;
q.push("Hello World!");
q.push("China");
cout<<q.empty()<<endl;
输出为两行,分别是1和0。因为一开始队列是空的,后来插入了两个元素。
front()
返回值为队列中的第一个元素,也就是最早、最先进入队列的元素。注意这里只是返回最早进入的元素,并没有把它剔除出队列。如:
queue<string> q;
q.push("Hello World!");
q.push("China");
cout<<q.front()<<endl;
q.pop();
cout<<q.front()<<endl;
输出值为两行,分别是Hello World!和China。只有在使用了pop以后,队列中的最早进入元素才会被剔除。
back()
返回队列中最后一个元素,也就是最晚进去的元素。如:
queue<string> q;
q.push("Hello World!");
q.push("China");
cout<<q.back()<<endl;
输出值为China,因为它是最后进去的。这里back仅仅是返回最后一个元素,也并没有将该元素从队列剔除掉。
其他的方法不是很常用,就不再研究了。
deque容器
概述
deque(双端队列)是由一段一段的定量连续空间构成,可以向两端发展,因此不论在尾部或头部安插元素都十分迅速。 在中间部分安插元素则比较费时,因为必须移动其它元素。
定义及初始化
使用之前必须加相应容器的头文件:
#include <deque> // deque属于std命名域的,因此需要通过命名限定,例如using std::deque;
定义的实现代码如下:
deque<int> a; // 定义一个int类型的双端队列a
deque<int> a(10); // 定义一个int类型的双端队列a,并设置初始大小为10
deque<int> a(10, 1); // 定义一个int类型的双端队列a,并设置初始大小为10且初始值都为1
deque<int> b(a); // 定义并用双端队列a初始化双端队列b
deque<int> b(a.begin(), a.begin()+3); // 将双端队列a中从第0个到第2个(共3个)作为双端队列b的初始值
除此之外,还可以直接使用数组来初始化向量:
int n[] = { 1, 2, 3, 4, 5 };
// 将数组n的前5个元素作为双端队列a的初值
// 说明:当然不包括arr[4]元素,末尾指针都是指结束元素的下一个元素,
// 这个主要是为了和deque.end()指针统一。
deque<int> a(n, n + 5);
deque<int> a(&n[1], &n[4]); // 将n[1]、n[2]、n[3]作为双端队列a的初值
基本操作函数
容量函数
- 容器大小:
deq.size(); - 容器最大容量:
deq.max_size(); - 更改容器大小:
deq.resize(); - 容器判空:
deq.empty(); - 减少容器大小到满足元素所占存储空间的大小:
deq.shrink_to_fit();
#include <iostream>
#include <deque>
using namespace std;
int main(int argc, char* argv[])
{
deque<int> deq;
for (int i = 0; i<6; i++)
{
deq.push_back(i);
}
cout << deq.size() << endl; // 输出:6
cout << deq.max_size() << endl; // 输出:1073741823
deq.resize(0); // 更改元素大小
cout << deq.size() << endl; // 输出:0
if (deq.empty())
cout << "元素为空" << endl; // 输出:元素为空
return 0;
}
添加函数
- 头部添加元素:
deq.push_front(const T& x); - 末尾添加元素:
deq.push_back(const T& x); - 任意位置插入一个元素:
deq.insert(iterator it, const T& x); - 任意位置插入 n 个相同元素:
deq.insert(iterator it, int n, const T& x); - 插入另一个向量的 [forst,last] 间的数据:
deq.insert(iterator it, iterator first, iterator last);
#include <iostream>
#include <deque>
using namespace std;
int main(int argc, char* argv[])
{
deque<int> deq;
// 头部增加元素
deq.push_front(4);
// 末尾添加元素
deq.push_back(5);
// 任意位置插入一个元素
deque<int>::iterator it = deq.begin();
deq.insert(it, 2);
// 任意位置插入n个相同元素
it = deq.begin(); // 必须要有这句
deq.insert(it, 3, 9);
// 插入另一个向量的[forst,last]间的数据
deque<int> deq2(5,8);
it = deq.begin(); // 必须要有这句
deq.insert(it, deq2.end() - 1, deq2.end());
// 遍历显示
for (it = deq.begin(); it != deq.end(); it++)
cout << *it << " "; // 输出:8 9 9 9 2 4 5
cout << endl;
return 0;
}
删除函数
- 头部删除元素:
deq.pop_front(); - 末尾删除元素:
deq.pop_back(); - 任意位置删除一个元素:
deq.erase(iterator it); - 删除 [first,last] 之间的元素:
deq.erase(iterator first, iterator last); - 清空所有元素:
deq.clear();
#include <iostream>
#include <deque>
using namespace std;
int main(int argc, char* argv[])
{
deque<int> deq;
for (int i = 0; i < 8; i++)
deq.push_back(i);
// 头部删除元素
deq.pop_front();
// 末尾删除元素
deq.pop_back();
// 任意位置删除一个元素
deque<int>::iterator it = deq.begin();
deq.erase(it);
// 删除[first,last]之间的元素
deq.erase(deq.begin(), deq.begin()+1);
// 遍历显示
for (it = deq.begin(); it != deq.end(); it++)
cout << *it << " ";
cout << endl;
// 清空所有元素
deq.clear();
// 遍历显示
for (it = deq.begin(); it != deq.end(); it++)
cout << *it << " "; // 输出:3 4 5 6
cout << endl;
return 0;
}
访问函数
- 下标访问:
deq[1];// 并不会检查是否越界 - at 方法访问:
deq.at(1);// 以上两者的区别就是 at 会检查是否越界,是则抛出 out of range 异常 - 访问第一个元素:
deq.front(); - 访问最后一个元素:
deq.back();
#include <iostream>
#include <deque>
using namespace std;
int main(int argc, char* argv[])
{
deque<int> deq;
for (int i = 0; i < 6; i++)
deq.push_back(i);
// 下标访问
cout << deq[0] << endl; // 输出:0
// at方法访问
cout << deq.at(0) << endl; // 输出:0
// 访问第一个元素
cout << deq.front() << endl; // 输出:0
// 访问最后一个元素
cout << deq.back() << endl; // 输出:5
return 0;
}
其他函数
- 多个元素赋值:
deq.assign(int nSize, const T& x);// 类似于初始化时用数组进行赋值 - 交换两个同类型容器的元素:
swap(deque&);
#include <iostream>
#include <deque>
using namespace std;
int main(int argc, char* argv[])
{
// 多个元素赋值
deque<int> deq;
deq.assign(3, 1);
deque<int> deq2;
deq2.assign(3, 2);
// 交换两个容器的元素
deq.swap(deq2);
// 遍历显示
cout << "deq: ";
for (int i = 0; i < deq.size(); i++)
cout << deq[i] << " "; // 输出:2 2 2
cout << endl;
// 遍历显示
cout << "deq2: ";
for (int i = 0; i < deq2.size(); i++)
cout << deq2[i] << " "; // 输出:1 1 1
cout << endl;
return 0;
}
迭代器与算法
1. 迭代器
- 开始迭代器指针:
deq.begin(); - 末尾迭代器指针:
deq.end();// 指向最后一个元素的下一个位置 - 指向常量的开始迭代器指针:
deq.cbegin();// 意思就是不能通过这个指针来修改所指的内容,但还是可以通过其他方式修改的,而且指针也是可以移动的。 - 指向常量的末尾迭代器指针:
deq.cend(); - 反向迭代器指针,指向最后一个元素:
deq.rbegin(); - 反向迭代器指针,指向第一个元素的前一个元素:
deq.rend();
#include <iostream>
#include <deque>
using namespace std;
int main(int argc, char* argv[])
{
deque<int> deq;
deq.push_back(1);
deq.push_back(2);
deq.push_back(3);
cout << *(deq.begin()) << endl; // 输出:1
cout << *(--deq.end()) << endl; // 输出:3
cout << *(deq.cbegin()) << endl; // 输出:1
cout << *(--deq.cend()) << endl; // 输出:3
cout << *(deq.rbegin()) << endl; // 输出:3
cout << *(--deq.rend()) << endl; // 输出:1
cout << endl;
return 0;
}
2. 算法
- 遍历元素
deque<int>::iterator it;
for (it = deq.begin(); it != deq.end(); it++)
cout << *it << endl;
// 或者
for (int i = 0; i < deq.size(); i++) {
cout << deq.at(i) << endl;
}
- 元素翻转
#include <algorithm>
reverse(deq.begin(), deq.end());
- 元素排序
#include <algorithm>
sort(deq.begin(), deq.end()); // 采用的是从小到大的排序
// 如果想从大到小排序,可以采用先排序后反转的方式,也可以采用下面方法:
// 自定义从大到小的比较器,用来改变排序方式
bool Comp(const int& a, const int& b) {
return a > b;
}
sort(deq.begin(), deq.end(), Comp);
总结
可以看到,deque 与 vector 的用法基本一致,除了以下几处不同:
- deque 没有 capacity() 函数,而 vector 有;
- deque 有 push_front() 和 pop_front() 函数,而 vector 没有;
- deque 没有 data() 函数,而 vector 有。
priority_queue容器(优先队列)
普通的队列是一种先进先出的数据结构,元素在队列尾追加,而从队列头删除。
在优先队列中,元素被赋予优先级。当访问元素时,具有最高优先级的元素最先删除。优先队列具有最高级先出 (first in, largest out)的行为特征。
首先要包含头文件#include<queue>, 他和queue不同的就在于我们可以自定义其中数据的优先级, 让优先级高的排在队列前面,优先出队。
优先队列具有队列的所有特性,包括队列的基本操作,只是在这基础上添加了内部的一个排序,它本质是一个堆实现的。
和队列基本操作相同:
- top 访问队头元素
- empty 队列是否为空
- size 返回队列内元素个数
- push 插入元素到队尾 (并排序)
- emplace 原地构造一个元素并插入队列
- pop 弹出队头元素
- swap 交换内容
定义:priority_queue<Type, Container, Functional>
Type 就是数据类型,Container 就是容器类型(Container必须是用数组实现的容器,比如vector,deque等等,但不能用 list。STL里面默认用的是vector),Functional 就是比较的方式。
当需要用自定义的数据类型时才需要传入这三个参数,使用基本数据类型时,只需要传入数据类型,默认是大顶堆。
一般是:
//升序队列,小顶堆
priority_queue <int,vector<int>,greater<int> > q;
//降序队列,大顶堆
priority_queue <int,vector<int>,less<int> >q;
//greater和less是std实现的两个仿函数(就是使一个类的使用看上去像一个函数。其实现就是类中实现一个operator(),这个类就有了类似函数的行为,就是一个仿函数类了)
基本类型优先队列的例子:
#include<iostream>
#include <queue>
using namespace std;
int main()
{
//对于基础类型 默认是大顶堆
priority_queue<int> a;
//等同于 priority_queue<int, vector<int>, less<int> > a;
// 这里一定要有空格,不然成了右移运算符↓↓
priority_queue<int, vector<int>, greater<int> > c; //这样就是小顶堆
priority_queue<string> b;
for (int i = 0; i < 5; i++)
{
a.push(i);
c.push(i);
}
while (!a.empty())
{
cout << a.top() << ' ';
a.pop();
}
cout << endl;
while (!c.empty())
{
cout << c.top() << ' ';
c.pop();
}
cout << endl;
b.push("abc");
b.push("abcd");
b.push("cbd");
while (!b.empty())
{
cout << b.top() << ' ';
b.pop();
}
cout << endl;
return 0;
}
运行结果:
4 3 2 1 0
0 1 2 3 4
cbd abcd abc
请按任意键继续. . .
用pair做优先队列元素的例子:
规则:pair的比较,先比较第一个元素,第一个相等比较第二个。
#include <iostream>
#include <queue>
#include <vector>
using namespace std;
int main()
{
priority_queue<pair<int, int> > a;
pair<int, int> b(1, 2);
pair<int, int> c(1, 3);
pair<int, int> d(2, 5);
a.push(d);
a.push(c);
a.push(b);
while (!a.empty())
{
cout << a.top().first << ' ' << a.top().second << 'n';
a.pop();
}
}
运行结果:
2 5
1 3
1 2
请按任意键继续. . .
用自定义类型做优先队列元素的例子
#include <iostream>
#include <queue>
using namespace std;
//方法1
struct tmp1 //运算符重载<
{
int x;
tmp1(int a) {x = a;}
bool operator<(const tmp1& a) const
{
return x < a.x; //大顶堆
}
};
//方法2
struct tmp2 //重写仿函数
{
bool operator() (tmp1 a, tmp1 b)
{
return a.x < b.x; //大顶堆
}
};
int main()
{
tmp1 a(1);
tmp1 b(2);
tmp1 c(3);
priority_queue<tmp1> d;
d.push(b);
d.push(c);
d.push(a);
while (!d.empty())
{
cout << d.top().x << 'n';
d.pop();
}
cout << endl;
priority_queue<tmp1, vector<tmp1>, tmp2> f;
f.push(b);
f.push(c);
f.push(a);
while (!f.empty())
{
cout << f.top().x << 'n';
f.pop();
}
}
运行结果:
3
2
1
3
2
1
请按任意键继续. . .
set容器的基本应用
set介绍
set是C++标准库中的一种关联容器。所谓关联容器就是通过键(key)来读取和修改元素。与map关联容器不同,它只是单纯键的集合。
set集合容器实现了红黑树(Red-Black Tree)的平衡二叉检索树的数据结构,在插入元素时,它会自动调整二叉树的排列,把该元素放到适当的位置,以确保每个树根节点的键值大于左子树所有节点的键值,而小于右子树所有节点的键值;另外,还确保根节点左子树的高度与右子树的高度相等,这样,二叉树的高度最小,从而检索速度最快。要注意的是,它不会重复插入相同键值的元素,而采取忽略处理。
set的使用
set模版类的定义在头文件<set>中
set的基本操作:
s.begin() // 返回指向第一个元素的迭代器
s.clear() // 清除所有元素
s.count() // 返回某个值元素的个数
s.empty() // 如果集合为空,返回true(真)
s.end() // 返回指向最后一个元素之后的迭代器,不是最后一个元素
s.equal_range() // 返回集合中与给定值相等的上下限的两个迭代器
s.erase() // 删除集合中的元素
s.find() // 返回一个指向被查找到元素的迭代器
s.get_allocator() // 返回集合的分配器
s.insert() // 在集合中插入元素
s.lower_bound() // 返回指向大于(或等于)某值的第一个元素的迭代器
s.key_comp() // 返回一个用于元素间值比较的函数
s.max_size() // 返回集合能容纳的元素的最大限值
s.rbegin() // 返回指向集合中最后一个元素的反向迭代器
s.rend() // 返回指向集合中第一个元素的反向迭代器
s.size() // 集合中元素的数目
s.swap() // 交换两个集合变量
s.upper_bound() // 返回大于某个值元素的迭代器
s.value_comp() // 返回一个用于比较元素间的值的函数
2.1创建set集合对象
#include<iostream>
#include<set>
using namespace std;
set<int>s
2.2元素的插入
s.insert(1);
s.insert(2);
s.insert(3);
2.3元素的遍历
#include<iostream>
#include<set>
using namespace std;
set<int>s;
int main()
{
s.insert(1);
s.insert(2);
s.insert(3);
set<int>::iterator it;
for(it=s.begin();it!=s.end();it++)
{
cout<<*it<<" ";
}
cout<<endl;
}
2.4元素的查找
#include<set>
using namespace std;
set<int>s;
int main()
{
s.insert(1);
s.insert(2);
s.insert(3);
if(s.find(3)!=s.end())
cout<<"Yes"<<endl;
else
cout<<"No"<<endl;
if(s.count(3))
cout<<"Yes"<<endl;
else
cout<<"No"<<endl;
}
ind()查找元素返回给定值的迭代器,如果没找到则返回 end()。
count() 用来查找 set 中某个某个键值出现的次数。这个函数在 set 并不是很实用,
因为一个键值在 set 只可能出现 0 或 1 次,这样就变成了判断某一键值是否在 set 出现过了
2.5删除元素,容器中元素的个数,清空容器,判空
#include<iostream>
#include<set>
using namespace std;
set<int>s;
int main()
{
s.insert(1);
s.insert(2);
s.insert(3);
s.erase(3);//删除元素
cout<<s.size()<<endl;//容器中元素的个数
s.clear();//清空容器
if(s.empty())//判空,集合为空,返回true(真)
cout<<"Yes"<<endl;
else
cout<<"No"<<endl;
}
2.6排序
法1
//非结构元素
#include<iostream>
#include<set>
using namespace std;
set<int,greater<int> >s;//注意空格
//set<int,less<int> >s;用不到set默认从小到大排序
int main()
{
s.insert(1);
s.insert(3);
s.insert(5);
s.insert(2);
s.insert(4);
set<int>::iterator it=s.begin();
while(it!=s.end())
{
cout<<*it<<" ";
it++;
}
cout<<endl;
}
法2
//非结构体元素
#include <set>
#include <iostream>
using namespace std;
struct myComp
{
bool operator()(const int &a,const int &b)
{
return a>b;//降序
//return a<b;//升序
}
};
int main(int argc, char* argv[])
{
set<int,myComp> s;
s.insert(8);
s.insert(1);
s.insert(12);
s.insert(6);
s.insert(8);
set<int,myComp>::iterator it;
for(it=s.begin();it!=s.end();it++)
{
cout<<*it<<" ";
}
cout<<endl;
return 0;
}
法3
//结构体元素
/*set的insert方法没有insert(a,cmp)这种重载,所以如果要把结构体插入set中,我们就要重载'<'运算符。
set方法在插入的时候也是从小到大的,那么我们重载一下<运算符让它从大到小排序*/
#include<iostream>
#include<algorithm>
#include<set>
using namespace std;
struct node
{
int a;
char b;
//重载"<"操作符,自定义排序规则 (为什么要重载<号呢?看stl_function.h源码)
bool operator < (const node &x) const
{
if(x.a==a)
return b<x.b;//当a值相等按b值从小到大排序
return a>x.a;//当a值不等时按a值从大到小排序
}
};
set<node>s;
int main()
{
set<node>::iterator it;
node w={1,'d'};
node x={1,'c'};
node y={3,'a'};
node z={2,'b'};
s.insert(w);
s.insert(x);
s.insert(y);
s.insert(z);
for(it=s.begin();it!=s.end();it++)
{
cout<<(*it).a<<" "<<(*it).b<<endl;
}
}
multiset
在<set>头文件中,还定义了另一个非常实用的模版类multiset(多重集合)。多重集合与集合的区别在于集合中不能存在相同元素,而多重集合中可以存在。
定义multiset对象的示例代码如下:
multiset<int> s;
multiset<double> ss;
常用库函数
reverse翻转
翻转一个vector:
reverse(a.begin(), a.end());
翻转一个数组,元素存放在下标1 ~ n:
reverse(a + 1, a + n + 1);
unique去重
返回去重(只去掉相邻的相同元素)之后的尾迭代器(或指针),仍然为前闭后开,即这个迭代器是去重之后末尾元素的下一个位置。该函数常用于离散化,利用迭代器(或指针)的减法,可计算出去重后的元素个数。
把一个vector去重:
int m = unique(a.begin(), a.end()) – a.begin();
把一个数组去重,元素存放在下标1 ~ n:
int m = unique(a + 1, a + n + 1) – (a + 1);
random_shuffle随机打乱
用法与reverse相同。
sort
对两个迭代器(或指针)指定的部分进行快速排序。可以在第三个参数传入定义大小比较的函数,或者重载“小于号”运算符。
把一个int数组(元素存放在下标1 ~ n)从大到小排序,传入比较函数:
int a[MAX_SIZE];
bool cmp(int a, int b)
{
return a > b;
}
sort(a + 1, a + n + 1, cmp);
把自定义的结构体vector排序,重载“小于号”运算符:
struct Rec
{
int id, x, y;
};
vector<Rec> a;
bool operator <(const Rec &a, const Rec &b)
{
return a.x < b.x || a.x == b.x && a.y < b.y;
}
sort(a.begin(), a.end());
lower_bound/upper_bound 二分
lower_bound的第三个参数传入一个元素x,在两个迭代器(指针)指定的部分上执行二分查找,返回指向第一个大于等于x的元素的位置的迭代器(指针)。
upper_bound的用法和lower_bound大致相同,唯一的区别是查找第一个大于x的元素。当然,两个迭代器(指针)指定的部分应该是提前排好序的。
在有序int数组(元素存放在下标1 ~ n)中查找大于等于x的最小整数的下标:
int i = lower_bound(a + 1, a + 1 + n, x) - a;
在有序vector
int y = *--upper_bound(a.begin(), a.end(), x);
stack容器(栈)(先入先出)
stack容器适配器支持的成员函数
和其他序列容器相比,stack 是一类存储机制简单、提供成员函数较少的容器。表 1 列出了 stack 容器支持的全部成员函数。
| 成员函数 | 功能 |
|---|---|
| empty() | 当 stack 栈中没有元素时,该成员函数返回 true;反之,返回 false。 |
| size() | 返回 stack 栈中存储元素的个数。 |
| top() | 返回一个栈顶元素的引用,类型为 T&。如果栈为空,程序会报错。 |
| push(const T& val) | 先复制 val,再将 val 副本压入栈顶。这是通过调用底层容器的 push_back() 函数完成的。 |
| push(T&& obj) | 以移动元素的方式将其压入栈顶。这是通过调用底层容器的有右值引用参数的 push_back() 函数完成的。 |
| pop() | 弹出栈顶元素。 |
| emplace(arg...) | arg... 可以是一个参数,也可以是多个参数,但它们都只用于构造一个对象,并在栈顶直接生成该对象,作为新的栈顶元素。 |
| swap(stack |
将两个 stack 适配器中的元素进行互换,需要注意的是,进行互换的 2 个 stack 适配器中存储的元素类型以及底层采用的基础容器类型,都必须相同。 |
c++stack(堆栈)是一个容器的改编,它实现了一个先进后出的数据结构(FILO)
使用该容器时需要包含#include
定义stack对象的示例代码如下:
stack
stack
stack的基本操作有:
1.入栈:如s.push(x);
2.出栈:如 s.pop().注意:出栈操作只是删除栈顶的元素,并不返回该元素。
3.访问栈顶:如s.top();
4.判断栈空:如s.empty().当栈空时返回true。
5.访问栈中的元素个数,如s.size();
下面举一个简单的例子:
#include<iostream>
#include<stack>
using namespace std;
int main(void)
{
stack<double>s;//定义一个栈
for(int i=0;i<10;i++)
s.push(i);
while(!s.empty())
{
printf("%lfn",s.top());
s.pop();
}
cout<<"栈内的元素的个数为:"<<s.size()<<endl;
return 0;
}
bitset容器
头文件
#include <bitset>
指定大小
bitset<1000> bs; // a bitset with 1000 bits
构造函数
bitset(): 每一位都是false。bitset(unsigned long val): 设为val的二进制形式。bitset(const string& str): 设为 01串str。
运算符
operator []: 访问其特定的一位。operator ==/!=: 比较两个bitset内容是否完全一样。operator &/&=/|/| =/^/^=/~: 进行按位与/或/异或/取反操作。bitset只能与bitset进行位运算,若要和整型进行位运算,要先将整型转换为bitset。operator <>/<<=/>>=: 进行二进制左移/右移。operator <>: 流运算符,这意味着你可以通过cin/cout进行输入输出。
成员函数
count(): 返回true的数量。size(): 返回bitset的大小。test(pos): 它和vector中的at()的作用是一样的,和[]运算符的区别就是越界检查。any(): 若存在某一位是true则返回true,否则返回false。none(): 若所有位都是false则返回true,否则返回false。all():C++11,若所有位都是true则返回true,否则返回false。-
set(): 将整个bitset设置成true。set(pos, val = true): 将某一位设置成true/false。
-
reset(): 将整个bitset设置成false。reset(pos): 将某一位设置成false。相当于set(pos, false)。
-
flip(): 翻转每一位。(,相当于异或一个全是 的bitset)flip(pos): 翻转某一位。
to_string(): 返回转换成的字符串表达。to_ulong(): 返回转换成的unsigned long表达 (long在 NT 及 32 位 POSIX 系统下与int一样,在 64 位 POSIX 下与long long一样)。to_ullong():C++11,返回转换成的unsigned long long表达。
一些文档中没有的成员函数:
_Find_first(): 返回bitset第一个true的下标,若没有true则返回bitset的大小。_Find_next(pos): 返回pos后面(下标严格大于pos的位置)第一个true的下标,若pos后面没有true则返回bitset的大小。
list 容器
list 容器,又称双向链表容器
list 容器中各个元素的前后顺序是靠指针来维系的,每个元素都配备了 2 个指针,分别指向它的前一个元素和后一个元素。第一个元素的前向指针总为 null,尾部元素的后向指针也总为 null。
基于这样的存储结构,list 容器具有一些其它容器(array、vector 和 deque)所不具备的优势,即它可以在序列已知的任何位置快速插入或删除元素(时间复杂度为O(1))。并且在 list 容器中移动元素,也比其它容器的效率高。
使用 list 容器的缺点是,它不能像 array 和 vector 那样,通过位置直接访问元素。举个例子,如果要访问 list 容器中的第 6 个元素,它不支持容器对象名[6]这种语法格式,正确的做法是从容器中第一个元素或最后一个元素开始遍历容器,直到找到该位置。
头文件
#include <list>
创建一个没有元素的list容器
list<int> values;
创建一个有十个元素的list容器
list<int> values(10);
创建一个有十个元素的list容器,并为每个元素指定初始值
list<int> values(10, 5);
拷贝创建list容器
list<int> value1(10);
list<int> value2(value1);
拷贝普通数组
int a[] = { 1,2,3,4,5 };
list<int> values(a, a+5);
拷贝其它类型的容器
array<int, 5>arr{ 11,12,13,14,15 };
list<int>values(arr.begin()+2, arr.end());//拷贝arr容器中的{13,14,15}
成员函数
| 成员函数 | 功能 |
|---|---|
| begin() | 返回指向容器中第一个元素的双向迭代器。 |
| end() | 返回指向容器中最后一个元素所在位置的下一个位置的双向迭代器。 |
| rbegin() | 返回指向最后一个元素的反向双向迭代器。 |
| rend() | 返回指向第一个元素所在位置前一个位置的反向双向迭代器。 |
| cbegin() | 和 begin() 功能相同,只不过在其基础上,增加了 const 属性,不能用于修改元素。 |
| cend() | 和 end() 功能相同,只不过在其基础上,增加了 const 属性,不能用于修改元素。 |
| crbegin() | 和 rbegin() 功能相同,只不过在其基础上,增加了 const 属性,不能用于修改元素。 |
| crend() | 和 rend() 功能相同,只不过在其基础上,增加了 const 属性,不能用于修改元素。 |
| empty() | 判断容器中是否有元素,若无元素,则返回 true;反之,返回 false。 |
| size() | 返回当前容器实际包含的元素个数。 |
| max_size() | 返回容器所能包含元素个数的最大值。这通常是一个很大的值,一般是 232-1,所以我们很少会用到这个函数。 |
| front() | 返回第一个元素的引用。 |
| back() | 返回最后一个元素的引用。 |
| assign() | 用新元素替换容器中原有内容。 |
| emplace_front() | 在容器头部生成一个元素。该函数和 push_front() 的功能相同,但效率更高。 |
| push_front() | 在容器头部插入一个元素。 |
| pop_front() | 删除容器头部的一个元素。 |
| emplace_back() | 在容器尾部直接生成一个元素。该函数和 push_back() 的功能相同,但效率更高。 |
| push_back() | 在容器尾部插入一个元素。 |
| pop_back() | 删除容器尾部的一个元素。 |
| emplace() | 在容器中的指定位置插入元素。该函数和 insert() 功能相同,但效率更高。 |
| insert() | 在容器中的指定位置插入元素。 |
| erase() | 删除容器中一个或某区域内的元素。 |
| swap() | 交换两个容器中的元素,必须保证这两个容器中存储的元素类型是相同的。 |
| resize() | 调整容器的大小。 |
| clear() | 删除容器存储的所有元素。 |
| splice() | 将一个 list 容器中的元素插入到另一个容器的指定位置。 |
| remove(val) | 删除容器中所有等于 val 的元素。 |
| remove_if() | 删除容器中满足条件的元素。 |
| unique() | 删除容器中相邻的重复元素,只保留一个。 |
| merge() | 合并两个事先已排好序的 list 容器,并且合并之后的 list 容器依然是有序的。 |
| sort() | 通过更改容器中元素的位置,将它们进行排序。 |
| reverse() | 反转容器中元素的顺序。 |
原文链接: https://www.cnblogs.com/liangqianxing/p/17044045.html
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/311162
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!