
一、转换函数Conversion function(video2)
一个类型的对象,使用转换函数可以转换为另一种类型的对象。
例如一个分数,理应该可以转换为一个double数,我们用以下转换函数来实现:
class Fraction { public: //构造函数,输入分子和分母 Fraction(int num, int den = 1) :m_num(num), m_den(den) {} //转换函数,不需要返回值,因为定义的就是转为double的函数,返回值是固定的 //因为该函数并未修改m_num和m_den的值,所以加上const operator double() const { //这里需要先把m_num和m_den转换为double,否则除法的结果是一个整数 return (double)m_num / (double)m_den; } private: int m_num; int m_den; };
调用:
Fraction f(10, 3); double dvi = 4.5 + f; cout << dvi << endl;
转换后的类型不一定要是基本类型,只要是编译器编译到这里的时候认得的类型都可以,例如string或自己定义的类型。
二、单参数构造函数(video3)
class Fraction { public: //该构造函数的den参数有默认值,这就形成了单参数构造函数 Fraction(int num, int den = 1) :m_num(num), m_den(den) {} Fraction operator +(const Fraction& f) { //完成Fraction之间的加法,并返回 return Fraction(this->m_num*f.m_den + this->m_den*f.m_num, this->m_den*f.m_den); } int get_num() const { return m_num; } int get_den() const { return m_den; } private: int m_num; int m_den; }; inline ostream& operator<<(ostream& os,const Fraction& f) { os << f.get_num(); os << "/"; os << f.get_den(); return os; }
调用:
Fraction f(10, 3); //当Fraction对象加一个int时,编译器会自动将4转换为4/1的Fraction对象 Fraction dvi = f + 4 ; cout << dvi << endl; //输出3/22
三、单参数构造函数搭配转换函数的问题(报错)(video3)
class Fraction { public: //该构造函数的den参数有默认值,这就形成了单参数构造函数 Fraction(int num, int den = 1) :m_num(num), m_den(den) {} //Fraction转double的转换函数 operator double() const { return (double)m_num / (double)m_den; } Fraction operator +(const Fraction& f) { //完成Fraction之间的加法,并返回 return Fraction(this->m_num*f.m_den + this->m_den*f.m_num, this->m_den*f.m_den); } int get_num() const { return m_num; } int get_den() const { return m_den; } private: int m_num; int m_den; }; inline ostream& operator<<(ostream& os,const Fraction& f) { os << f.get_num(); os << "/"; os << f.get_den(); return os; }
此时,Fraction类的定义中,同时存在单参数构造函数和转换函数。当调用以下代码时(报错):
Fraction f(10, 3); //当Fraction对象加一个int时,编译器会自动将4转换为4/1的Fraction对象 Fraction dvi = f + 4 ; cout << dvi << endl;
Fraction dvi = f + 4;会报错。因为编译器认为,可以把f转换为double,也可以把4转换为Fraction。当把4转换为Fraction时,这条路能走通。但是把f转换为double时,做完加法后,无法将得到的double类型的dvi转换为Fraction,所以报错。
同样的,这样调用也会报错,与上面的过程相反。
Fraction f(10, 3); //当Fraction对象加一个int时,编译器会自动将4转换为4/1的Fraction对象 double dvi = f + 4 ; cout << dvi << endl;
四、使用explicit关键字(video3)
explicit关键字意为“明确的”。很大几率用在构造函数前面,指明该构造函数只做构造函数使用,让编译器不要自动去调用它。
class Fraction { public: //该构造函数的den参数有默认值,这就形成了单参数构造函数 explicit Fraction(int num, int den = 1) :m_num(num), m_den(den) {} //Fraction转double的转换函数 operator double() const { return (double)m_num / (double)m_den; } Fraction operator +(const Fraction& f) { //完成Fraction之间的加法,并返回 return Fraction(this->m_num*f.m_den + this->m_den*f.m_num, this->m_den*f.m_den); } int get_num() const { return m_num; } int get_den() const { return m_den; } private: int m_num; int m_den; }; inline ostream& operator<<(ostream& os,const Fraction& f) { os << f.get_num(); os << "/"; os << f.get_den(); return os; }
在构造函数前使用了explicit关键字,也就相当于把前面例子里编译器面对的两条路减少为一条,这就没有冲突了。程序就能正确运行,但只能将f转换为double进行运算。
Fraction f(10, 3); //当Fraction对象加一个int时,编译器会自动将4转换为4/1的Fraction对象 double dvi = f + 4 ; cout << dvi << endl; //输出7.3333
总结:explicit很少使用,90%的几率都使用在构造函数之前,用作控制编译器的自动行为,减少从中带来的莫名错误。
五、Pointer-like类(关于智能指针)(video4)
Pointer-like class 即做出来的对象,像一个指针。例如智能指针就是其中一种。在这种类中,一定包含一个普通的指针。
template<class T> class shared_ptr { public: T& operator*() const { return *px; } T* operator->() const { return px; } //构造函数 shared_ptr(T* p):px(p) {} private: T* px; }; //测试类,将其对象指针包装成shared_ptr智能指针 class Test { public: void mytest() { printf("testing...n"); } };
调用:
Test a; shared_ptr<Test> ptr(&a); ptr->mytest();
注意T& operator*() const;和T* operator->() const;两个操作符重载函数,其中“*”的重载函数很好理解,就是取指针指向地址的数据。但是“->”符号的重载不太好理解,这是因为在C++中,->这个符号比较特殊,这个符号除了第一次作用在shared_ptr对象上,返回原始指针px,还会继续作用在px上,用来调用函数mytest。但好在重载这个符号,基本就是这种固定写法。
六、Pointer-like类(关于迭代器)(video4)
迭代器类型的Pointer-like和智能指针的Pointer-like有一定的区别。
作为迭代器,他将一个对象(结构体或类产生的对象)的指针包装为一个迭代器(类指针对象),例如链表的某个节点指针,这样,在他的内部重载多个操作符,比如“*”、“->”、“++”、“--”、“==”、“!=”等,分别对应链表节点之间的取值、调用、右移、左移、判断等于、判断不等于。
链表的基本结构图:
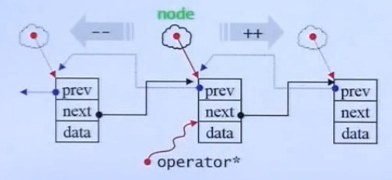

迭代器中“*”和“->”的重载:

图中所示,迭代器中的“*”,返回的是某个node中的data,而不是这个node(这些实现都是根据用户需求来实现)。
迭代器中的“->”返回的是data的指针,因为operator*()就是调用“*”的重载函数,返回data数据,前面再使用“&”来取地址,则就是data的指针。从而可以达到使用“->”来完成data->func_name()的目的。
举一反三,其他的符号重载也是根据用户需求来做相应的操作。
七、Function-like类(video5)
像函数一样的类,意思就是将一个类定义为可以接受“()”这个操作符的东西。
能接受“()”的东西,就是一个函数或仿函数。
template<class T> class Identity { public: //重载()操作符,使该类衍生的对象可以像函数一样调用 T& operator()(T& x) { return x; } }; class Test { public: void mytest() { printf("testing...n"); } };
调用:
int a1 = 5; Identity<int> iden_i; int a2 = iden_i(a1); cout << a2 << endl; Test t1; Identity<Test> iden_t; Test t2 = iden_t(t1); t2.mytest();
八、成员模板(video7)
template<class T1,class T2> class Pair { public: T1 first; T2 second; //普通构造 Pair() :first(T1()), second(T2()) {} Pair(const T1& a,const T2& b):first(a),second(b){} //成员模板 template<class U1,class U2> Pair(const Pair<U1, U2>& p) : first(p.first),second(p.second) {} }; //Base1理解为鱼类 class Base1 {}; //derived1理解为鲫鱼 class derived1 :public Base1 {}; //Base2理解为鸟类 class Base2 {}; //derived2理解为麻雀 class derived2 :public Base2 {};
调用:
Pair<derived1, derived2> p; //将p,即鲫鱼和麻雀组成的Pair作为参数传入Pair的构造函数 //形成的p2里面,first是鱼类,second是鸟类。但是他们的具体内容是鲫鱼和麻雀 Pair<Base1, Base2> p2(p);
将成员模板引申到前面所讲的只能指针,即可实现父类指针指向子类对象的效果。
因为普通的指针都可以指向自己子类的对象,那么作为这个指针的封装(智能指针),那必须能够指向子类对象。所以,可以模板T1就是父类类型,U1就是子类类型。实现如下:
template<class T> class shared_ptr { public: T& operator*() const { return *px; } T* operator->() const { return px; } shared_ptr(T* p):px(p) {} //成员模板 template<class U> explicit shared_ptr(U* p) : px(p) {} private: T* px; }; //测试类,将其对象指针包装成shared_ptr智能指针 class Test { public: virtual void mytest() { printf("testing...n"); } }; class Test2 :public Test { void mytest() { printf("testing2...n"); } };
调用:
Test2 t2; shared_ptr<Test> ptr(&t2); //实际上里面的成员属性px是Test类型的,但是保存的却是Test2类型数据 ptr->mytest(); //输出testing2..
九、模板特化(Specialization特殊化)(video10)
模板特化和泛化是反义的。我们使用的普通模板化指模板泛化,而特化就是指在泛化的基础上,有一些特殊的类型做特殊处理,例如:
//这个是Hash类的泛化定义 template<class T> class Hash { public: void operator()(T in)const { cout << in << endl; } }; //这个是Hash类对于int类型的特化定义 template<> class Hash<int> { public: void operator()(int in)const { cout << "Int:"<<in<< endl; } }; //这个是Hash类对于Double类型的特化定义 template<> class Hash<double> { public: void operator()(double in)const { cout << "Double:" << in << endl; } };
调用:
//int类型调用的是int类型的特化 Hash<int> hash_int; hash_int(50); //double类型调用的是double类型的特化 Hash<double> hash_db; hash_db(88.8); //float类型调用的是泛化情况下的构造方法 Hash<float> hash_fl; hash_fl(77.7);
十、偏特化(局部特化)(video10)
偏特化是在全特化的基础上发展来的,全特化就是上面所述的例子,只有一个泛化类型T。而偏特化就是指有多个泛化类型,例如:
//多类型模板泛化 template<class T1,class T2,class T3> class Hash2 { public: void operator()(T1 in1,T2 in2,T3 in3)const { cout <<"泛化"<< endl; } }; //前两个固定为int和double,偏泛化 template<class T3> class Hash2<int,double, T3> { public: void operator()(int in1,double in2,T3 in3)const { cout << "偏特化"<<endl; } };
调用:
//泛化 Hash2<float, double, float> hash_fdf; hash_fdf(5.0, 6.6, 7.7); //输出 泛化 //偏特化 Hash2<int,double,float> hash_idf; hash_idf(5,6.6,7.7); //输出 偏泛化
十一、范围的偏特化
本来是全泛化,假设为template<class T>,我们想单独拿出任意类型的指针来偏特化。
template<class T> class A { public: void operator()(T t)const { cout << "泛化" << endl; } }; template<class T> class A<T*> { public: void operator()(T* tp)const { cout << "范围偏特化" << endl; } };
调用:
int num = 5; int *p_num = # A<int> a1; A<int*> a2; a1(num); //输出泛化 a2(p_num); //输出范围偏特化
十二、模板的模板参数(video12)
模板的参数就是指template<typename T>中的T,他可以是任意类型。
但是当T也是一个模板时,就叫模板的模板参数。
template<class T> class Test{}; template<typename T,template<typename CT> class C> class XC { private: //C可以是List,该list需要一个模板参数CT,可以是任何类型,这里使用T的类型 C<T> c; };
调用:
//实际上xc中的c的类型为Test<int> XC<int, Test> xc;
当然,像vector等类型拥有多于1个的模板参数,所以以上代码中的C不能是vector。如果要实现vector作为XC的第二个模板,那么需要指明vector的两个模板参数:
template<class T> class Test{}; template< class T1,class T2, template<class CT1, class CT2> class C> class XC { private: //C可以是List,该list需要一个模板参数CT,可以是任何类型,这里使用T的类型 C<T1,T2> c; };
调用:
//实际上xc中的c的类型为vector<int,std::allocator<int>> XC<int, std::allocator<int>,vector> xc;
模板的模板参数,还需要和另一种形式区分开:
template<class T, class Sequence = deque<T>> //这种不是模板的模板参数
Sequence的默认值deque<T>实际上已经指明了Sequence的类型时deque,只是因为deque还有一个模板参数而已。
它和上面讲的不一样,上面讲的 template<class CT1, class CT2> class C,相当于Sequence<T>,Sequence和T都是待指定的模板参数。所以还是有本质区别的。
十三、不定模板参数(C++2.0新特性)(video14)
//用于当args...里没有参数的时候调用,避免报错 void leo_print() { //Do Nothing } //数量不定模板参数 template<class T, class ... Types> void leo_print(const T& firstArg, const Types& ... args) { cout << firstArg << endl; //递归调用leo_print,每次打印下一个参数 //自动将args...里的多个参数分为1+n个 leo_print(args...); }
调用:
leo_print(64, 5.5, "gogogo", 90, 377);
十四、auto关键字(C++2.0新特性)(video14)
auto关键字的作用在于,让编译器自动帮你推导需要的类型。这是一个语法糖,仅仅是让写代码更加方便。
例如:
list<int> c; c.push_back(11); c.push_back(22); c.push_back(33); //普通写法,自定指定类型 list<int>::iterator ite; ite = find(c.begin(), c.end(), 33); //auto写法,编译器从右边的find返回值推导其变量类型 auto ite = find(c.begin(), c.end(), string("leo")); //错误写法 auto ite; //光从这句话,编译器没法推导他的类型 ite = find(c.begin(), c.end(), string("hello3"));
十五、基于range的for循环(C++2.0新特性)(video14)
list<int> c; c.push_back(11); c.push_back(22); c.push_back(33); //遍历一个容器里的元素 for (int i : c) { cout << i << endl; } //除了遍历传统的容器,还能遍历{...}形式的数据 //{}中的数据要和i的类型符合 for (int i : {1,2,3,4,5,6,7,8,9,10}){ cout << i << endl; } //使用auto自己推导遍历元素的类型 for (auto i : c) { cout << i <<endl; }
上面过程,遍历到的数据都是拷贝给“i”的,不会影响容器中的数据。
//pass by reference,直接作用于容器元素本身 for (auto& i : c) { i *= 3; }
十六、引用reference(video15)

1.x是一个int类型的变量,大小为4bytes。
2.p是一个指针变量,保存的是x的地址,在32bit计算机中,指针的大小为4bytes。
3.r是x的引用,可以认为r就是x,x就是r,
4.当r=x2时,相当于也是x=x2。
5.r2是r的引用,也即是x的引用。现在r、r2、x都是一体。
6.使用sizeof()来看引用r和变量x的大小,返回的数值是一样的。
7.对引用r和变量x取地址,返回的地址也都是一样的。
从实现的角度来看,引用的底层都是通过指针来实现的。但是从逻辑的角度来看,引用又不是指针,我们看到引用,就要像看到变量本身一样,例如一个int类型变量,其引用也应该看成整数。
引用就是一个变量的别名,引用就是那个变量。引用一旦创建,就不能再代表其他变量了。如果此时再将某个变量赋值给这个引用,相当于赋值给引用代表的变量。参照前面第4点。
所以,对引用最好的理解方式,就是认为引用就是变量,不用关心为什么,编译器给我们制造了一个假象,就像一个人有大名和小名一样。你对引用做的任何操作,就相当于对变量本身做操作。
double imag(const double& im){} double imag(const double im){}
上述两句代码不能并存,因为他们的签名(signature)是相同的,signature就是[ imag(const double im) ----- ]这一段,‘----’表示可能存在的const关键字等。(const是作为签名的一部分的)
为什么不能并存,因为这两个函数虽然传参数的方式不同,一个传引用,一个传值。但对于调用来说,是一样的imag(im),这样对于编译器来说,它不知道该调用哪一个,所以不能并存(重载)。
十七、对象模型Object Model(video17)
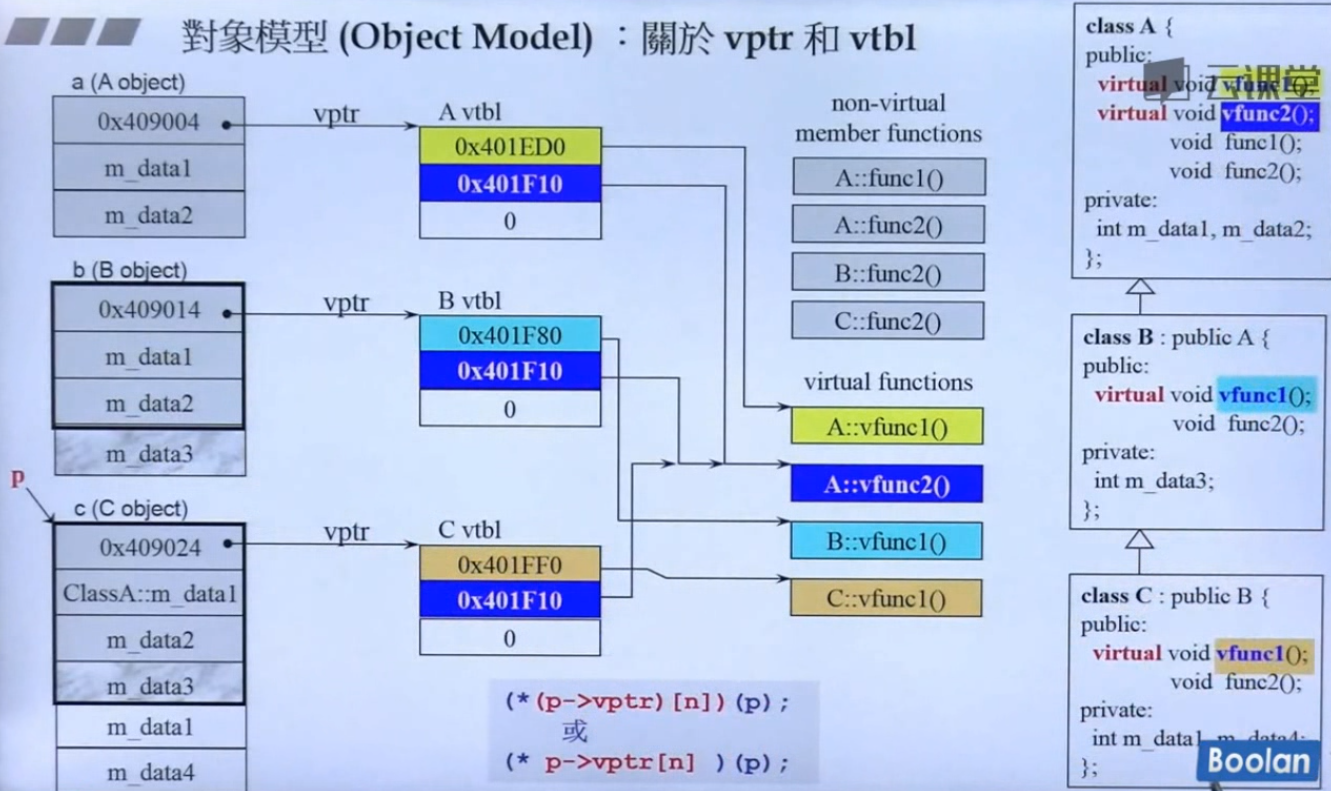
图中最右边是A,B,C三个类的继承关系。
最左边是对象a,b,c的内存占用情况。
当类中存在虚函数的时候(不管有几个虚函数),对象的内存占用都会多出4bytes,这个空间存放了一个指向虚表(Virtual table:vtbl)的指针(Virtual Pointer:vptr)。虚表里放的都是函数指针。
从这张图中可以看出:
1.父类有虚函数,子类必定有虚函数(因为子类会继承父类的所有数据,包含虚表指针)。如果子类有对其进行override,那么父类和子类所指向的同名虚函数是不同的,例如A中的vfunc1()虚函数,B将其进行override,C又再次override,所以各自一份不同的函数体。分别颜色为浅黄、浅蓝、深黄。
2.子类继承了父类的虚函数,但没有进行override,例如A中的vfunc2(),B和C都没对其进行override,所以大家的虚表里指向的都是同一份函数代码。
3.非虚函数不存在override,各自的非虚函数,都各自拥有,即使名字一样,但函数都是不相干的。子类只是继承了父类非虚函数的调用权而已(子类和父类有同名的非虚函数,子类可以使用调用权调用父类的函数)。
调用函数的流程:
当C* p = new C();的指针p(图中左边的红色p)去调用C的vfunc1()时,流程是 虚指针->虚表->vfunc1()地址,这叫动态绑定。C语言中对函数的调用,是编译器使用call XXX直接调用函数,那个叫静态绑定。如下图所示:

这是通过p指针找到vptr,然后通过*vptr取到虚表,然后选择虚表中第n个函数指针,再通过函数指针加()来调用函数。是用C语言实现的一个正确调用流程。
如何在虚表中确定需要调用的虚函数是第几个(选择n),就是在定义虚函数时,编译器会看定义的顺序,例如A类中vfunc1是第0个,vfunc2是第1个。
什么时候编译器使用动态绑定,三个条件(也是多态的条件):
1.函数由指针调用。
2.指针向上转型(up cast),父类指针指向子类对象。
3.调用的是虚函数。
十八、多态的例子(video17)
延续十六节里面的三个类,我们假设A代表平行四边形,B代表长方形,C代表正方形。他们的继承关系就是C->B->A。
当我们要在一个容器中存放不同的对象时,由于容器中存放元素的大小和类型都必须一致,所以我们只能存放不同对象的指针,而且指针类型还必须一致,我们只能选择父类A的指针A*。
假设容器中存放了a,b,c三个对象的指针,但这三个指针都是存放的父类指针,也就是A*。那么,当我们要分别画出他们的时候,可以从该容器中取出这些指针,然后调用draw()函数。虽然都使用的是父类的指针,但是a,b,c三个对象内存中存放的虚指针指向的虚表是各自不同的,虚表中所保存的draw()函数地址对应的函数也是各自分别实现的。所以最终可以成功画出自己的图形。这种使用父类指针调用子类的个性化方法,就实现了多态。如图所示:
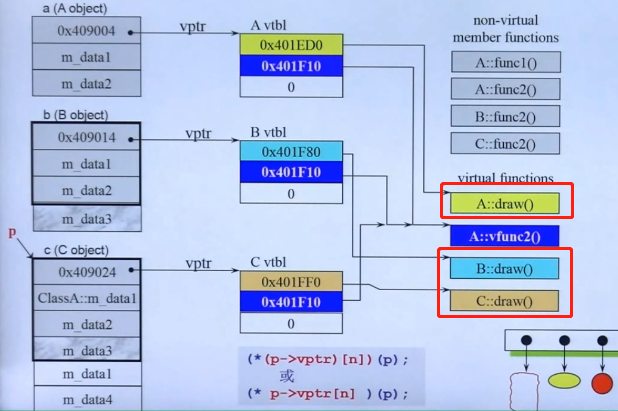
这就是多态。。多态。。多态。。多态。。多态。。。。
十九、this指针(video18)
什么是this指针:通过一个对象来调用成员函数,那个对象的地址就是this指针,就是这么简单。
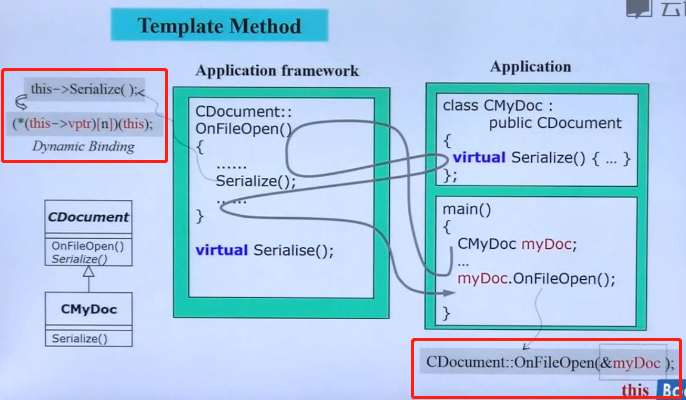
如上图所示,我们使用子类对象myDoc来调用OnFileOpen()。OnFileOpen()函数是父类的非虚函数,但是myDoc的指针会被编译器以隐式的方式传入OnFileOpen(),这个指针就是this指针,OnFileOpen()函数中的步骤运行到需要调用Serialize()函数时,因为Serialize()函数是一个虚函数,并且子类CMyDoc对其进行了override,所以编译器去调用Serialize()时,是使用的this->Serialize()。
注意图中左上角的红框,this指针指向的是myDoc对象,该对象里有虚指针,虚指针指向的虚表中有属于CMyDoc子类的Serialize()虚函数。所以最终调用的是子类的Serialize()。
二十、动态绑定和静态绑定(video19)
静态绑定:
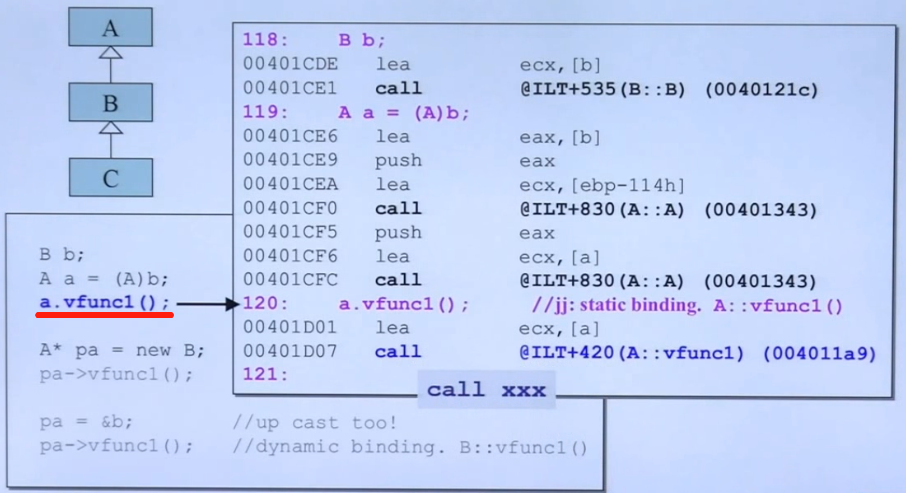
如上图所示,对象b被强转为A类对象,那么由a来调用vfunc1()就是静态绑定,因为它不满足动态绑定的三个条件(见十六节)的第一个,需要由指针来调用虚函数,并且指针是父类指针。
图右边的紫色是编译器注释以及候老师的注释,说明调用的是A类的A::vfunc1()虚函数,使用的是call xxx的静态绑定形式。
动态绑定:

如图所示,pa为A类指针,指向新new出来的B类对象,满足第一个条件:是指针,满足第二个条件:向上转型。然后使用pa调用vfunc1(),满足第三个条件:调用虚函数。所以是动态绑定。
取对象b的地址,并赋值给指针pa,b是类B的对象,而pa是A类的指针,所以满足前两个条件:指针以及向上转型。然后再使用pa指针调用vfunc1(),满足第三个条件:调用虚函数。所以也是使用的动态绑定。
二十一、const关键字(video19)
const的使用情况:
1.放在成员函数的小括号之后,函数本体的前面:例如int test() const { reutrn this->img; }
这种情况下,const表示这个成员函数保证不去修改类的成员变量,只做访问等操作。
注意:这个位置加const,只发生在类的成员函数上,全局函数不能加const。(因为这个const保证不修改数据,是有保证对象的,保证的对象就是该类的一个常量对象,即使用const修饰的该类对象,见后续说明)。
2.放在变量的前面:例如const A a;
这种情况下,const表示修饰的变量(基础变量或对象等)是不能修改的(如果是对象,就不能修改他内部的成员变量)。
以上两种情况就可以搭配起来使用:
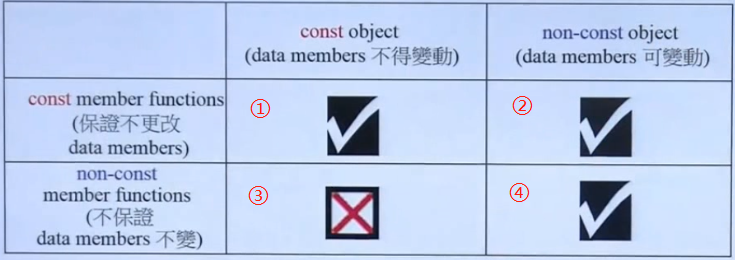
分为四种情况:
①.对象是const,成员函数也是const,能够完美搭配。因为对象是不能修改的,而该函数又保证不修改数据,一拍即合。
②.对象是non-const,成员函数是const。也是能够配合的。因为对象可以接受修改,也可以接受不修改,而函数保证不修改,没毛病。
③.对象是const,成员函数是non-const,不能搭配。因为对象不允许修改数据,但是函数不保证,无法协调。
④.对象是non-const,成员函数也是non-const,能搭配。因为对象不限制修改数据,函数也不保证,那就随便吧。
侯老师经验:在设计类的时候,考虑一共要设计几个函数,每个函数叫什么名字的时候,心里就应该知道那些函数是绝对不会修改数据的,那么这些函数就必须加上const。否者,如果其他人使用你设计的类,定义了一个const类型的对象,却因为你没有指明const关键字而无法调用一个可能名为print的输出函数(输出函数肯定不用修改数据,只是做访问和打印而已)。
二十二、const成员函数和non-const成员函数共存(video19)
在一个类中存在两个同名、同参数的函数,但一个有const标记,一个没有。例如标准库中的basic_string类(其实就是我们使用的string类的底层类),对方括号“[]”进行重载的函数就存在两个:

第一个成员函数有const标记,该函数是提供给常量字符串调用“[]”时使用的,例如打印index=2位置的字符,返回index=2的字符数据。
第二个成员函数没有const标记,该函数是提供给非常量字符串调用“[]”时使用的,例如修改index=2位置的字符,返回index=2的字符引用,引用就可供读取,也可以修改。
第二个函数需要考虑COW(copy on write)的情况,因为标准库实现string使用了相同数据共享的技术,也就是多个字符串如果数据相同,那么内部指向的可能是同一份数据,当有某一个字符串要修改数据时,才单独提供一份给它修改,而其他字符串不受影响,还是保持共享数据状态,这就叫COW,也就是说要写或修改时进行复制(一份数据)。(docker容器技术也是采用的COW思想)
注意一下调用准则:

二十三、new和delete(video20)
在C++编程一里面我们知道new和delete分解的动作:
new分解为三步:
1.分配内存(底层是malloc(size),内存大小为sizeof(class_name))
2.转换内存指针的类型为class_name*,原本为void*
3.用该指针调用构造函数,p->Foo::Foo();
delete分解为两步:
1.使用传入的指针调用析构函数p->~Foo();
2.释放对象占用的内存空间(底层是free())
我们可以重载全局的new和delete(但一定要小心,影响很大):

我们也可以重载类成员new和delete(只影响该类):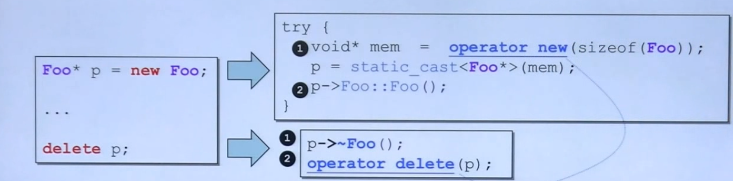

一般重载成员new和delete,主要是做内存池。
重载成员Array new和Array delete:

注意:array new的时候,分配的内存大小为sizeof(Foo)*N + 4,这里的4个byte,只在N个Foo对象内存的前面,有一个int类型的数,里面的值为N,用于标记有几个Foo对象。如下图:
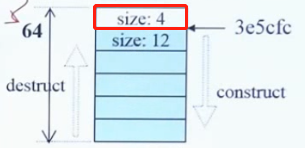
红框处就是一个int所占用的空间,里面的值为N(假设N=5),一个Foo对象为12bytes,那么总共分配内存大小为12*5+4=64。
二十四、new、delete重载示例(video22)

为了不然程序崩掉,重载的new和delete需要真正的去分配内存和释放内存,底层采用的是malloc和free。如果不想使用已重载的new和delete,可以使用::new class_name;来强制使用全局new,::delete pf;强制使用全局delete。
二十五*、重载特殊的placement new和delete(video23)
我们可以重载多个版本的new和delete,每个不同的new和delete的参数列不同。例如:
class Foo { public: Foo() {} Foo(int) {} //这个是普通的new重载,只有一个默认参数 void * operator new (size_t size) { return malloc(size); } //下面三个都是placement new重载 void * operator new(size_t size, void * start) { return start; } void * operator new (size_t size, long extra) { return malloc(size + extra); } void * operator new(size_t size, long extra, char init) { return malloc(size + extra); } };
如何使用这些new呢?
void * p = 0; //普通new Foo * f1 = new Foo(); //额外带一个void*参数的new Foo * f2 = new(p) Foo; //额外带一个long参数的new Foo * f3 = new(300) Foo; //额外带一个long和一个char参数的new Foo * f4 = new(300, 'a') Foo;
(以下部分作为了解:)
对于delete来说,我们当然也可以重载多个placement delete,但是注意一点,除了默认的那个delete,其余几个特殊的delete都不会被调用,他们被调用的唯一可能是,当对应的placement new分配内存后,调用构造函数抛出异常的时候,才会去调用对应的placement delete。例如:
//对应普通的new,size_t是默认参数(可选的) void operator delete(void * ,size_t){} //对应operator new(size_t size, void * start) void operator delete(void *, void*){} //对应operator new (size_t size, long extra) void operator delete(void *, long) {} //对应operator new(size_t size, long extra, char init) void operator delete(void *, long, char) {}
delete的时候默认都是调用第一个普通的,后面几个特殊的,只有在上述条件下才会被调用(不一定?根据编译器不同可能会有变化)。
二十六*、placement new重载在标准库string中的应用(video24)

如上图所示,在标准库的basic_string(就是string的底层)中,有一个内部结构体Rep,标准库针对Rep做了placement new的重载,额外添加了一个size_t的参数,在Rep *p = new(extra) Rep;中,传入了一个参数extra,这个参数表示在Rep初始化的过程中除了分配自身大小的空间,还额外分配了一个大小为extra的空间。basic_string就是利用这块额外的空间来存放实际的字符串数据,而且利用Rep对象来执行COW的控制,也就是控制有多少个string共享同一份数据。
原文链接: https://www.cnblogs.com/leokale-zz/p/11090627.html
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/297683
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!